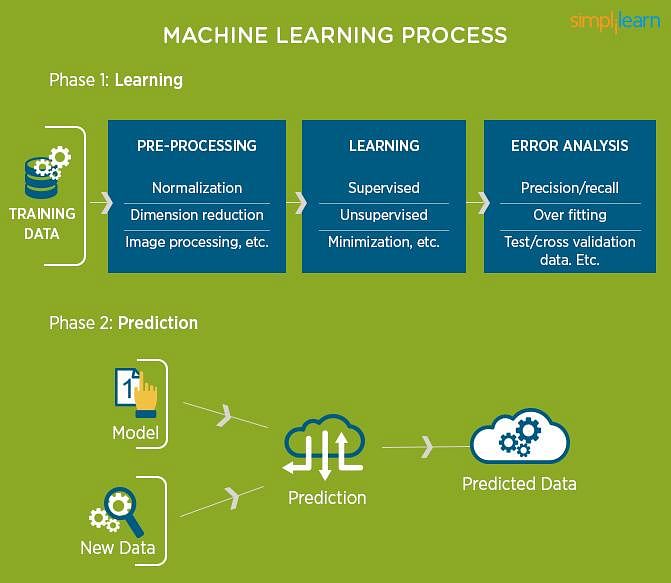
How does Machine Learning build a Linear Regression model?
Requirements
Some knowledge of programming in any language is essential.
Description
Machine Learning is becoming ubiquitous across all industries. Already many applications have been identified which use Machine Learning now. Few examples include Spam Detection, Face Recognition, Emotion Analysis, Object Detection, Credit Card Fraud Detection, Weather Prediction, and the list is almost endless. More new applications are being identified by different industries almost everyday.
It is not just about applying superior technology for traditional problems when we apply Machine Learning. It is also about business sense since applying Machine Learning, we can make experiments and applications much more economical.
This course is a result of a discussion among my Project Team from our cohort in IIT, Kanpur learning Cyber Security. We have embarked to create a product for Malware Detection using Machine Learning. While all of us are getting grips on Malware Analysis, the team needed some inputs of Machine Learning. To fill the gap, I conducted some sessions with our Project Team members on Machine Learning. This course is a collection of the recording of these sessions.
This course discusses what are Machine Learning Algorithms. We discuss Random Forest Algorithm and Linear Regression as examples to understand what are models in Machine Learning. We see how to implement such models using Python. During the discussion on the development of the Machine Learning models, we discuss the various steps like Data Preprocessing, Normalisation, Scaling, etc. We touch upon the basics of Neural Network and take a slight deep dive into Regression. The course includes discussion on concepts like what is overfitting, what is hyper-parameter tuning, etc.
This course tries to give an idea for what it takes to create a product which uses Machine Learning. I believe that the discussions can get one started to apply Machine Learning to many problems.
Introduction to Machine Learning and linear regression from scratch
Predicting Boston house price with Regression !!
Requirements
Yes, A basic knowledge in Python 3 is preferred.
Description
We have covered-
What is Machine Learning and how does it works?
Machine Learning concept such as Train Test Split, Machine Learning Models, Model Evaluation are also covered.
Linear Regression Concept with simple regression model using Scikit Learn Library.
What are the types of Regressions?
Case Study-Boston house price prediction-predicts the price of houses in Boston using a machine learning algorithm called Linear Regression. To train our machine learning model ,we will be using scikit-learn’s boston dataset.
Analyse and visualize data using Linear Regression.
Plot the graph of results of Linear Regression to visually analyze the results.
Linear regression is starting point for a data science this course focus is on making your foundation strong for deep learning and machine learning algorithms.
End of the course you will be able to code your own regression algorithm from scratch.
After completing this course you will be able to:
Interpret and Explain machine learning models which are treated as a black-box
Create an accurate Linear Regression model in python and visually analyze it
Select the best features for a business problem
Remove outliers and variable transformations for better performance
Confidently solve and explain regression problems This course will give you a very solid foundation in machine learning. You will be able to use the concepts of this course in other machine learning models.
elow you’ll find descriptions of and links to some basic and powerful machine-learning algorithms, including:
Attention Mechanisms & Memory Networks
Bayes Theorem & Naive Bayes Classifiers
Decision Trees
Eigenvectors, Eigenvalues and Machine Learning
Evolutionary & Genetic Algorithms
Expert Systems/Rules Engines/Symbolic Reasoning
Generative Adversarial Networks (GANs)
Graph Analytics and ML
Linear Regression
Logistic Regression
LSTMs and Recurrent Neural Networks
Markov Chain Monte Carlo Methods (MCMC)
Neural Networks
Random Forests
Reinforcement Learning
Word2vec, Neural Embeddings and NLP
Machine learning algorithms are programs (math and logic) that adjust themselves to perform better as they are exposed to more data. The “learning” part of machine learning means that those programs change how they process data over time, much as humans change how they process data by learning. So a machine-learning algorithm is a program with a specific way to adjusting its own parameters, given feedback on its previous performance in making predictions about a dataset.
Linear regression is simple, which makes it a great place to start thinking about algorithms more generally. Here it is:
ŷ = a * x + b
Read aloud, you’d say “y-hat equals a times x plus b.”
y-hat is the output, or guess made by the algorithm, the dependent variable.
a is the coefficient. It’s also the slope of the line that expresses the relationship between x and y-hat.
x is the input, the given or independent variable.
b is the intercept, where the line crosses the y axis.
Linear regression expresses a linear relationship between the input x and the output y; that is, for every change in x, y-hat will change by the same amount no matter how far along the line you are. The x is transformed by the same a and b at every point.
Linear regression with only one input variable is called Simple Linear Regression. With more than one input variable, it is called Multiple Linear Regression. An example of Simple Linear Regression would be attempting to predict a house price based on the square footage of the house and nothing more.
house_price_estimate = a * square_footage + b
Multiple Linear Regression would take other variables into account, such as the distance between the house and a good public school, the age of the house, etc.
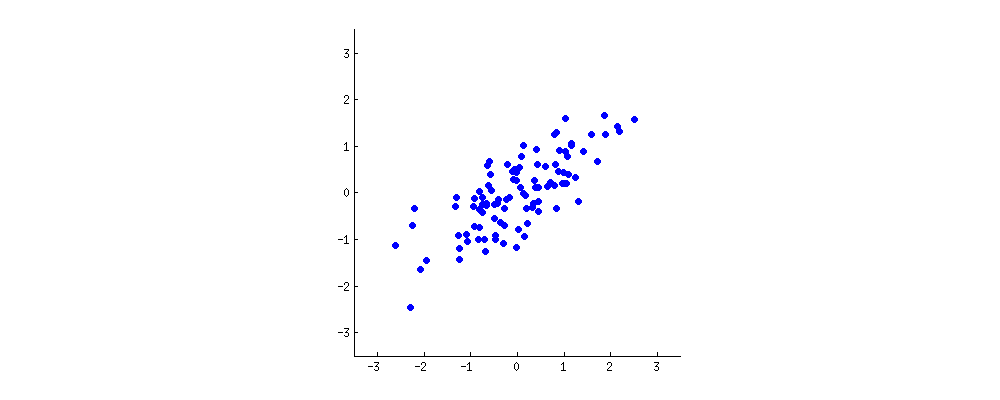
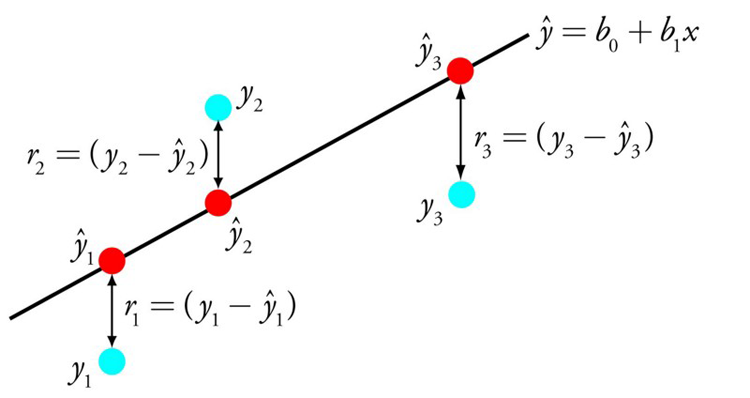
The reason why we’re dealing with y-hat, an estimate about the real value of y, is because linear regression is a formula used to estimate real values, and error is inevitable. Linear regression is often used to “fit” a scatter plot of given x-y pairs. A good fit minimizes the error between y-hat and the actual y; that is, choosing the right a and b will minimize the sum of the differences between each y and its respective y-hat.
That scatter plot of data points may look like a baguette – long in one direction and short in another – in which case linear regression may achieve a fit. (If the data points look like a meandering river, a straight line is probably not the right function to use to make predictions.)
Testing one line after another against the data points of the scatter plot, and automatically correcting it in order to minimize the sum of differences between the line and the points, could be thought of as machine learning in its simplest form.
Apply AI to Business Simulations »
Logistic Regression
Let’s analyze the name first. Logistic regression is not really regression, not in the sense of linear regression, which predicts continuous numerical values. (And it has nothing to do with logistics. 😉
Logistic regression does not do that. It’s actually a binomial classifier that acts like a light switch. A light switch essentially has two states, on and off. Logistic regression takes input data and classifies it as category or not_category, on or off expressed as 1 or 0, based on the strength of the input’s signal. So it’s a light switch for signal that you find in the data. If you want to mix the metaphor, it’s actually more like a transistor, since it both amplifies and gates the signal. More on that here.
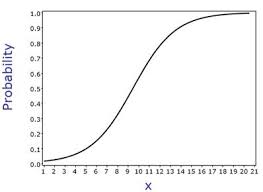
Logistic regression takes input data and squishes it, so that no matter what the range of the input is, it will be compressed into the space between 1 and 0. Notice, in the image below, no matter how large the input x becomes, the output y cannot exceed 1, which it asymptotically approaches, and no matter low x is, y cannot fall below 0. That’s how logistic regression compresses input data into a range between 0 and 1, through this s-shaped, sigmoidal transform.
Decision Tree
Decision, or decide, stems from the Latin decidere, which itself is the combination of “de” (off) and “caedere” (to cut). So decision is about the cutting off of possibilities. Decision trees can be used to classify data, and they cut off possibilities of what a given instance of data might be by examining a data point’s features. Is it bigger than a bread box? Well, then it’s not a marble. Is it alive? Well, then it’s not a bicycle. Think of a decision as a game of 20 questions that an algorithm is asking about the data point under examination.
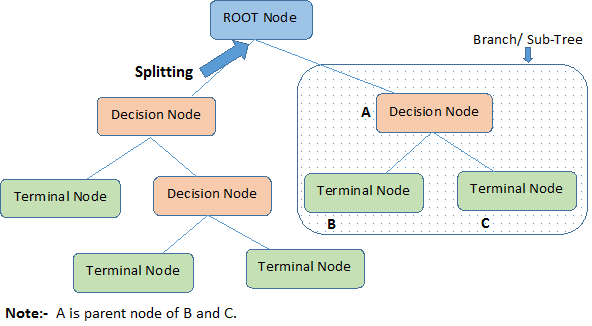
A decision tree is a series of nodes, a directional graph that starts at the base with a single node and extends to the many leaf nodes that represent the categories that the tree can classify. Another way to think of a decision tree is as a flow chart, where the flow starts at the root node and ends with a decision made at the leaves. It is a decision-support tool. It uses a tree-like graph to show the predictions that result from a series of feature-based splits.
Here are some useful terms for describing a decision tree:
Root Node: A root node is at the beginning of a tree. It represents entire population being analyzed. From the root node, the population is divided according to various features, and those sub-groups are split in turn at each decision node under the root node.
Splitting: It is a process of dividing a node into two or more sub-nodes.
Decision Node: When a sub-node splits into further sub-nodes, it’s a decision node.
Leaf Node or Terminal Node: Nodes that do not split are called leaf or terminal nodes.
Pruning: Removing the sub-nodes of a parent node is called pruning. A tree is grown through splitting and shrunk through pruning.
Branch or Sub-Tree: A sub-section of decision tree is called branch or a sub-tree, just as a portion of a graph is called a sub-graph.
Parent Node and Child Node: These are relative terms. Any node that falls under another node is a child node or sub-node, and any node which precedes those child nodes is called a parent node.
Decision trees are a popular algorithm for several reasons:
Explanatory Power: The output of decision trees is interpretable. It can be understood by people without analytical or mathematical backgrounds. It does not require any statistical knowledge to interpret them.
Exploratory data analysis: Decision trees can enable analysts to identify significant variables and important relations between two or more variables, helping to surface the signal contained by many input variables.
Minimal data cleaning: Because decision trees are resilient to outliers and missing values, they require less data cleaning than some other algorithms.
Any data type: Decision trees can make classifications based on both numerical and categorical variables.
Non-parametric: A decision tree is a non-parametric algorithm, as opposed to neural networks, which process input data transformed into a tensor, via tensor multiplication using large number of coefficients, known as parameters.
Disadvantages
Overfitting: Over fitting is a common flaw of decision trees. Setting constraints on model parameters and making the model simpler through pruning are two ways to regularize a decision tree.
Predicting continuous variables: While decision trees can ingest continuous numerical input, they are not a practical way to predict such values, since decision-tree predictions must be separated into discrete categories, which results in a loss of information when applying the model to continuous values.
Heavy feature engineering: The flip side of a decision tree’s explanatory power is that it requires heavy feature engineering. When dealing with unstructured data or data with latent factors, this makes decision trees sub-optimal. Neural networks are clearly superior in this regard.
Random Forest
Random forests are made of many decision trees. They are ensembles of decision trees, each decision tree created by using a subset of the attributes used to classify a given population (they are sub-trees, see above). Those decision trees vote on how to classify a given instance of input data, and the random forest bootstraps those votes to choose the best prediction. This is done to prevent overfitting, a common flaw of decision trees.
A random forest is a supervised classification algorithm. It creates a forest (many decision trees) and orders their nodes and splits randomly. The more trees in the forest, the better the results it can produce.
If you input a training dataset with targets and features into the decision tree, it will formulate some set of rules that can be used to perform predictions.
Example: You want to predict whether a visitor to your e-commerce Web site will enjoy a mystery novel. First, collect information about past books they’ve read and liked. Metadata about the novels will be the input; e.g. number of pages, author, publication date, which series it’s part of if any. The decision tree contains rules that apply to those features; for example, some readers like very long books and some don’t. Inputting metadata about new novels will result in a prediction regarding whether or not the Web site visitor in question would like that novel. Arranging the nodes and defining the rules relies on information gain and Gini-index calculations. With random forests, finding the root node and splitting the feature nodes is done randomly.
Machine learning (ML) can do everything from analyzing X-rays to predicting stock market prices to recommending binge-worthy television shows. With such a wide range of applications, it’s not surprising that the global machine learning market is projected to grow from $21.7 billion in 2022 to $209.91 billion by 2029, according to Fortune Business Insights.
At the core of machine learning are algorithms, which are trained to become the machine learning models used to power some of the most impactful innovations in the world today.
In this article, you’ll learn about 10 of the most popular machine learning algorithms that you’ll want to know, and explore the different learning styles used to turn machine learning algorithms into functioning machine learning models.
10 machine learning algorithms to know
In simple terms, a machine learning algorithm is like a recipe that allows computers to learn and make predictions from data. Instead of explicitly telling the computer what to do, we provide it with a large amount of data and let it discover patterns, relationships, and insights on its own.
From classification to regression, here are 10 algorithms you need to know in the field of machine learning:
1. Linear regression
Linear regression is a supervised learning algorithm used for predicting and forecasting values that fall within a continuous range, such as sales numbers or housing prices. It is a technique derived from statistics and is commonly used to establish a relationship between an input variable (X) and an output variable (Y) that can be represented by a straight line.
In simple terms, linear regression takes a set of data points with known input and output values and finds the line that best fits those points. This line, known as the “regression line,” serves as a predictive model. By using this line, we can estimate or predict the output value (Y) for a given input value (X).
Linear regression is primarily used for predictive modeling rather than categorization. It is useful when we want to understand how changes in the input variable affect the output variable. By analyzing the slope and intercept of the regression line, we can gain insights into the relationship between the variables and make predictions based on this understanding.
2. Logistic regression
Logistic regression, also known as “logit regression,” is a supervised learning algorithm primarily used for binary classification tasks. It is commonly employed when we want to determine whether an input belongs to one class or another, such as deciding whether an image is a cat or not a cat.
Logistic regression predicts the probability that an input can be categorized into a single primary class. However, in practice, it is commonly used to group outputs into two categories: the primary class and not the primary class. To accomplish this, logistic regression creates a threshold or boundary for binary classification. For example, any output value between 0 and 0.49 might be classified as one group, while values between 0.50 and 1.00 would be classified as the other group.
Consequently, logistic regression is typically used for binary categorization rather than predictive modeling. It enables us to assign input data to one of two classes based on the probability estimate and a defined threshold. This makes logistic regression a powerful tool for tasks such as image recognition, spam email detection, or medical diagnosis where we need to categorize data into distinct classes.
3. Naive Bayes
Naive Bayes is a set of supervised learning algorithms used to create predictive models for binary or multi-classification tasks. It is based on Bayes’ Theorem and operates on conditional probabilities, which estimate the likelihood of a classification based on the combined factors while assuming independence between them.
Let’s consider a program that identifies plants using a Naive Bayes algorithm. The algorithm takes into account specific factors such as perceived size, color, and shape to categorize images of plants. Although each of these factors is considered independently, the algorithm combines them to assess the probability of an object being a particular plant.
Naive Bayes leverages the assumption of independence among the factors, which simplifies the calculations and allows the algorithm to work efficiently with large datasets. It is particularly well-suited for tasks like document classification, email spam filtering, sentiment analysis, and many other applications where the factors can be considered separately but still contribute to the overall classification.
4. Decision tree
A decision tree is a supervised learning algorithm used for classification and predictive modeling tasks. It resembles a flowchart, starting with a root node that asks a specific question about the data. Based on the answer, the data is directed down different branches to subsequent internal nodes, which ask further questions and guide the data to subsequent branches. This process continues until the data reaches an end node, also known as a leaf node, where no further branching occurs.
Decision tree algorithms are popular in machine learning because they can handle complex datasets with ease and simplicity. The algorithm’s structure makes it straightforward to understand and interpret the decision-making process. By asking a sequence of questions and following the corresponding branches, decision trees enable us to classify or predict outcomes based on the data’s characteristics.
This simplicity and interpretability make decision trees valuable for various applications in machine learning, especially when dealing with complex datasets.
5. Random forest
A random forest algorithm is an ensemble of decision trees used for classification and predictive modeling. Instead of relying on a single decision tree, a random forest combines the predictions from multiple decision trees to make more accurate predictions.
In a random forest, numerous decision tree algorithms (sometimes hundreds or even thousands) are individually trained using different random samples from the training dataset. This sampling method is called “bagging.” Each decision tree is trained independently on its respective random sample.
Once trained, the random forest takes the same data and feeds it into each decision tree. Each tree produces a prediction, and the random forest tallies the results. The most common prediction among all the decision trees is then selected as the final prediction for the dataset.
Random forests address a common issue called “overfitting” that can occur with individual decision trees. Overfitting happens when a decision tree becomes too closely aligned with its training data, making it less accurate when presented with new data.
6. K-nearest neighbor (KNN)
K-nearest neighbor (KNN) is a supervised learning algorithm commonly used for classification and predictive modeling tasks. The name “K-nearest neighbor” reflects the algorithm’s approach of classifying an output based on its proximity to other data points on a graph.
Let’s say we have a dataset with labeled points, some marked as blue and others as red. When we want to classify a new data point, KNN looks at its nearest neighbors in the graph. The “K” in KNN refers to the number of nearest neighbors considered. For example, if K is set to 5, the algorithm looks at the 5 closest points to the new data point.
Based on the majority of the labels among the K nearest neighbors, the algorithm assigns a classification to the new data point. For instance, if most of the nearest neighbors are blue points, the algorithm classifies the new point as belonging to the blue group.
Additionally, KNN can also be used for prediction tasks. Instead of assigning a class label, KNN can estimate the value of an unknown data point based on the average or median of its K nearest neighbors.
7. K-means
K-means is an unsupervised learning algorithm commonly used for clustering and pattern recognition tasks. It aims to group data points based on their proximity to one another. Similar to K-nearest neighbor (KNN), K-means utilizes the concept of proximity to identify patterns or clusters in the data.
Each of the clusters is defined by a centroid, a real or imaginary center point for the cluster. K-means is useful on large data sets, especially for clustering, though it can falter when handling outliers.
K-means is particularly useful for large datasets and can provide insights into the inherent structure of the data by grouping similar points together. It has applications in various fields such as customer segmentation, image compression, and anomaly detection.
8. Support vector machine (SVM)
A support vector machine (SVM) is a supervised learning algorithm commonly used for classification and predictive modeling tasks. SVM algorithms are popular because they are reliable and can work well even with a small amount of data. SVM algorithms work by creating a decision boundary called a “hyperplane.” In two-dimensional space, this hyperplane is like a line that separates two sets of labeled data.
The goal of SVM is to find the best possible decision boundary by maximizing the margin between the two sets of labeled data. It looks for the widest gap or space between the classes. Any new data point that falls on either side of this decision boundary is classified based on the labels in the training dataset.
It’s important to note that hyperplanes can take on different shapes when plotted in three-dimensional space, allowing SVM to handle more complex patterns and relationships in the data.
9. Apriori
Apriori is an unsupervised learning algorithm used for predictive modeling, particularly in the field of association rule mining.
The Apriori algorithm was initially proposed in the early 1990s as a way to discover association rules between item sets. It is commonly used in pattern recognition and prediction tasks, such as understanding a consumer’s likelihood of purchasing one product after buying another.
The Apriori algorithm works by examining transactional data stored in a relational database. It identifies frequent itemsets, which are combinations of items that often occur together in transactions. These itemsets are then used to generate association rules. For example, if customers frequently buy product A and product B together, an association rule can be generated to suggest that purchasing A increases the likelihood of buying B.
By applying the Apriori algorithm, analysts can uncover valuable insights from transactional data, enabling them to make predictions or recommendations based on observed patterns of itemset associations.
10. Gradient boosting
Gradient boosting algorithms employ an ensemble method, which means they create a series of “weak” models that are iteratively improved upon to form a strong predictive model. The iterative process gradually reduces the errors made by the models, leading to the generation of an optimal and accurate final model.
The algorithm starts with a simple, naive model that may make basic assumptions, such as classifying data based on whether it is above or below the mean. This initial model serves as a starting point.
In each iteration, the algorithm builds a new model that focuses on correcting the mistakes made by the previous models. It identifies the patterns or relationships that the previous models struggled to capture and incorporates them into the new model.
Gradient boosting is effective in handling complex problems and large datasets. It can capture intricate patterns and dependencies that may be missed by a single model. By combining the predictions from multiple models, gradient boosting produces a powerful predictive model.
Get started in machine learning
With Machine Learning from DeepLearning.AI on Coursera, you’ll have the opportunity to learn essential machine learning concepts and techniques from industry experts. Develop the skills to build and deploy machine learning models, analyze data, and make informed decisions through hands-on projects and interactive exercises. Not only will you build confidence in applying machine learning in various domains, you could also open doors to exciting career opportunities in data science.
Over the course of an hour, an unsolicited email skips your inbox and goes straight to spam, a car next to you auto-stops when a pedestrian runs in front of it, and an ad for the product you were thinking about yesterday pops up on your social media feed. What do these events all have in common? It’s artificial intelligence that has guided all these decisions. And the force behind them all is machine-learning algorithms that use data to predict outcomes.
Now, before we look at how machine learning aids data analysis, let’s explore the fundamentals of each.
What is Machine Learning?
Machine learning is the science of designing algorithms that learn on their own from data and adapt without human correction. As we feed data to these algorithms, they build their own logic and, as a result, create solutions relevant to aspects of our world as diverse as fraud detection, web searches, tumor classification, and price prediction.
In deep learning, a subset of machine learning, programs discover intricate concepts by building them out of simpler ones. These algorithms work by exposing multilayered (hence “deep”) neural networks to vast amounts of data. Applications for machine learning, such as natural language processing, dramatically improve performance through the use of deep learning.
What is Data Analysis?
Data analysis involves manipulating, transforming, and visualizing data in order to infer meaningful insights from the results. Individuals, businesses,and even governments often take direction based on these insights.
Data analysts might predict customer behavior, stock prices, or insurance claims by using basic linear regression. They might create homogeneous clusters using classification and regression trees (CART), or they might gain some impact insight by using graphs to visualize a financial technology company’s portfolio.
Until the final decades of the 20th century, human analysts were irreplaceable when it came to finding patterns in data. Today, they’re still essential when it comes to feeding the right kind of data to learning algorithms and inferring meaning from algorithmic output, but machines can and do perform much of the analytical work itself.
Why Machine Learning is Useful in Data Analysis
Machine learning constitutes model-building automation for data analysis. When we assign machines tasks like classification, clustering, and anomaly detection — tasks at the core of data analysis — we are employing machine learning.
We can design self-improving learning algorithms that take data as input and offer statistical inferences. Without relying on hard-coded programming, the algorithms make decisions whenever they detect a change in pattern.
Before we look at specific data analysis problems, let’s discuss some terminology used to categorize different types of machine-learning algorithms. First, we can think of most algorithms as either classification-based, where machines sort data into classes, or regression-based, where machines predict values.
Next, let’s distinguish between supervised and unsupervised algorithms. A supervised algorithm provides target values after sufficient training with data. In contrast, the information used to instruct an unsupervised machine-learning algorithm needs no output variable to guide the learning process.
For example, a supervised algorithm might estimate the value of a home after reviewing the price (the output variable) of similar homes, while an unsupervised algorithm might look for hidden patterns in on-the-market housing.
As popular as these machine-learning models are, we still need humans to derive the final implications of data analysis. Making sense of the results or deciding, say, how to clean the data remains up to us humans.
Machine-Learning Algorithms for Data Analysis
Now let’s look at six well-known machine-learning algorithms used in data analysis. In addition to reviewing their structure, we’ll go over some of their real-world applications.
Clustering
At a local garage sale, you buy 70 monochromatic shirts, each of a different color. To avoid decision fatigue, you design an algorithm to help you color-code your closet. This algorithm uses photos of each shirt as input and, comparing the color of each shirt to the others, creates categories to account for every shirt. We call this clustering: an unsupervised learning algorithm that looks for patterns among input values and groups them accordingly. Here is a GeeksForGeeks article that provides visualizations of this machine-learning model.
Decision-tree learning
You can think of a decision tree as an upside-down tree: you start at the “top” and move through a narrowing range of options. These learning algorithms take a single data set and progressively divide it into smaller groups by creating rules to differentiate the features it observes. Eventually, they create sets small enough to be described by a specific label. For example, they might take a general car data set (the root) and classify it down to a make and then to a model (the leaves).
As you might have gathered, decision trees are supervised learning algorithms ideal for resolving classification problems in data analysis, such as guessing a person’s blood type. Check out this in-depth Medium article that explains how decision trees work.
Ensemble learning
Imagine you’re en route to a camping trip with your buddies, but no one in the group remembered to check the weather. Noting that you always seem dressed appropriately for the weather, one of your buddies asks you to stand in as a meteorologist. Judging from the time of year and the current conditions, you guess that it’s going to be 72°F (22°C) tomorrow.
Now imagine that everyone in the group came with their own predictions for tomorrow’s weather: one person listened to the weatherman; another saw Doppler radar reports online; a third asked her parents; and you made your prediction based on current conditions.
Do you think you, the group’s appointed meteorologist, will have the most accurate prediction, or will the average of all four guesses be closer to the actual weather tomorrow? Ensemble learning dictates that, taken together, your predictions are likely to be distributed around the right answer. The average will likely be closer to the mark than your guess alone.
In technical terms, this machine-learning model frequently used in data analysis is known as the random forest approach: by training decision trees on random subsets of data points, and by adding some randomness into the training procedure itself, you build a forest of diverse trees that offer a more robust average than any individual tree. For a deeper dive, read this tutorial on implementing the random forest approach in Python.
Support-vector machine
Have you ever struggled to differentiate between two species — perhaps between alligators and crocodiles? After a long while, you manage to learn how: alligators have a U-shaped snout, while crocodiles’ mouths are slender and V-shaped; and crocodiles have a much toothier grin than alligators do. But on a trip to the Everglades, you come across a reptile that, perplexingly, has features of both — so how can you tell the difference? Support-vector machine (SVM) algorithms are here to help you out.
First, let’s draw a graph with one distinguishing feature (snout shape) as the x-axis and another (grin toothiness) as the y-axis. We’ll populate the graph with plenty of data points for both species, and then find possible planes (or, in this 2D case, lines) that separate the two classes.
Our objective is to find a single “hyperplane” that divides the data by maximizing the distance between the dividing plane and each class’s closest points — called support vectors. No more confusion between crocs and gators: once the SVM finds this hyperplane, you can easily classify the reptiles in your vacation photos by seeing which side each one lands on.
SVM algorithms can only be used on categorical data, but it’s not always possible to differentiate between classes with 2D graphs. To resolve this, you can use a kernel: an established pattern to map data to higher dimensions. By using a combination of kernels and tweaks to their parameters, you’ll be able to find a non-linear hyperplane and continue on your way distinguishing between reptiles. This YouTube video does a clear job of visualizing how kernels integrate with SVM.
Linear regression
If you’ve ever used a scatterplot to find a cause-and-effect relationship between two sets of data, then you’ve used linear regression. This is a modeling method ideal for forecasting and finding correlations between variables in data analysis.
For example, say you want to see if there’s a connection between fatigue and the number of hours someone works. You gather data from a set of people with a wide array of work schedules and plot your findings. Seeking a relationship between the independent variable (hours worked) and the dependent variable (fatigue), you notice that a straight line with a positive slope best models the correlation. You’ve just used linear regression! If you’re interested in a detailed understanding of linear regression for machine learning, check out this blog pos from Machine Learning Mastery.
Logistic regression
While linear regression algorithms look for correlations between variables that are continuous by nature, logistic regression is ideal for classifying categorical data. Our alligator-versus-crocodile problem is, in fact, a logistic regression problem. Whereas the SVM model can work with non-linear kernels, logistic regression is limited to (and great for) linear classification. See this in-depth overview of logistic regression, especially good for lovers of calculus.
Summary
In this article, we looked at how machine learning can automate and scale data analysis. We summarized a few important machine-learning algorithms and saw their real-life applications.
While machine learning offers precision and scalability in data analysis, it’s important to remember that the real work of evaluating machine learning results still belongs to humans. If you think this could be a career path for you, check out Udacity’s Become a Machine Learning Enginee course.
In machine learning, there’s something called the “No Free Lunch” theorem. In a nutshell, it states that no one machine learning algorithm works best for every problem, and it’s especially relevant for supervised learning (i.e. predictive modeling).
For example, you can’t say that neural networks are always better than decision trees or vice versa. There are many factors at play, such as the size and structure of your dataset.
As a result, you should try many different algorithms for your problem, while using a hold-out “test set” of data to evaluate performance and select the winner.
Of course, the algorithms you try must be appropriate for your problem, which is where picking the right machine learning task comes in. As an analogy, if you need to clean your house, you might use a vacuum, a broom, or a mop, but you wouldn’t bust out a shovel and start digging.
THE BIG PRINCIPLE BEHIND MACHINE LEARNING ALGORITHMS
However, there is a common principle that underlies all supervised machine learning algorithms for predictive modeling.
Machine learning algorithms are described as learning a target function (f) that best maps input variables (X) to an output variable (Y): Y = f(X)
This is a general learning task where we would like to make predictions in the future (Y) given new examples of input variables (X). We don’t know what the function (f) looks like or its form. If we did, we would use it directly and we would not need to learn it from data using machine learning algorithms.
The most common type of machine learning is to learn the mapping Y = f(X) to make predictions of Y for new X. This is called predictive modeling or predictive analytics and our goal is to make the most accurate predictions possible.
Most Common Machine Learning Algorithms
For machine learning newbies who are eager to understand the basics of machine learning, here is a quick tour on the top 10 machine learning algorithms used by data scientists.
TOP MACHINE LEARNING ALGORITHMS YOU SHOULD KNOW
Linear Regression
Logistic Regression
Linear Discriminant Analysis
Classification and Regression Trees
Naive Bayes
K-Nearest Neighbors (KNN)
Learning Vector Quantization (LVQ)
Support Vector Machines (SVM)
Random Forest
Boosting
AdaBoost
1. LINEAR REGRESSION
Linear regression is perhaps one of the most well-known and well-understood algorithms in statistics and machine learning.
Predictive modeling is primarily concerned with minimizing the error of a model or making the most accurate predictions possible, at the expense of explainability. We will borrow, reuse and steal algorithms from many different fields, including statistics and use them towards these ends.
The representation of linear regression is an equation that describes a line that best fits the relationship between the input variables (x) and the output variables (y), by finding specific weightings for the input variables called coefficients (B).
Linear Regression
For example: y = B0 + B1 * x
We will predict y given the input x and the goal of the linear regression learning algorithm is to find the values for the coefficients B0 and B1.
Different techniques can be used to learn the linear regression model from data, such as a linear algebra solution for ordinary least squares and gradient descent optimization.
Linear regression has been around for more than 200 years and has been extensively studied. Some good rules of thumb when using this technique are to remove variables that are very similar (correlated) and to remove noise from your data, if possible. It is a fast and simple technique and a good first algorithm to try.
2. LOGISTIC REGRESSION
Logistic regression is another technique borrowed by machine learning from the field of statistics. It is the go-to method for binary classification problems (problems with two class values).
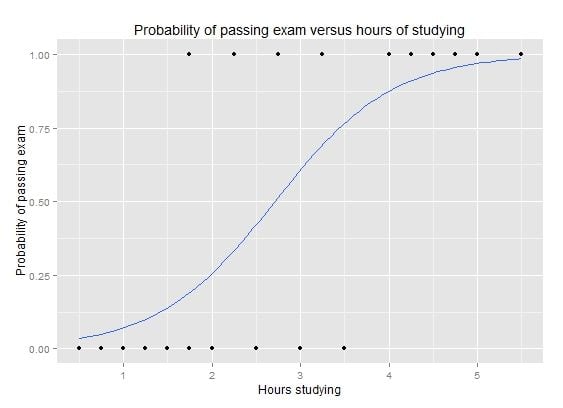
Logistic regression is like linear regression in that the goal is to find the values for the coefficients that weight each input variable. Unlike linear regression, the prediction for the output is transformed using a nonlinear function called the logistic function.
The logistic function looks like a big S and will transform any value into the range 0 to 1. This is useful because we can apply a rule to the output of the logistic function to snap values to 0 and 1 (e.g. IF less than 0.5 then output 1) and predict a class value.
Logistic Regression: Graph of a logistic regression curve showing probability of passing an exam versus hours studying
Because of the way that the model is learned, the predictions made by logistic regression can also be used as the probability of a given data instance belonging to class 0 or class 1. This can be useful for problems where you need to give more rationale for a prediction.
Like linear regression, logistic regression does work better when you remove attributes that are unrelated to the output variable as well as attributes that are very similar (correlated) to each other. It’s a fast model to learn and effective on binary classification problems.
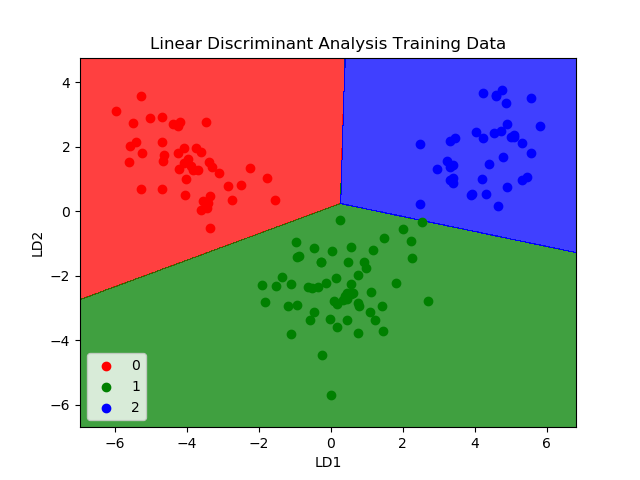
3. LINEAR DISCRIMINANT ANALYSIS
Logistic Regression is a classification algorithm traditionally limited to only two-class classification problems. If you have more than two classes then the Linear Discriminant Analysis algorithm is the preferred linear classification technique.
The representation of LDA is pretty straightforward. It consists of statistical properties of your data, calculated for each class. For a single input variable this includes:
The mean value for each class.
The variance calculated across all classes.
Linear Discriminant Analysis
Predictions are made by calculating a discriminant value for each class and making a prediction for the class with the largest value. The technique assumes that the data has a Gaussian distribution (bell curve), so it is a good idea to remove outliers from your data beforehand. It’s a simple and powerful method for classification predictive modeling problems.
4. CLASSIFICATION AND REGRESSION TREES
Decision trees are an important type of algorithm for predictive modeling machine learning.
The representation of the decision tree model is a binary tree. This is your binary tree from algorithms and data structures, nothing too fancy. Each node represents a single input variable (x) and a split point on that variable (assuming the variable is numeric).
Decision Tree
The leaf nodes of the tree contain an output variable (y) which is used to make a prediction. Predictions are made by walking the splits of the tree until arriving at a leaf node and output the class value at that leaf node.
Trees are fast to learn and very fast for making predictions. They are also often accurate for a broad range of problems and do not require any special preparation for your data.
5. NAIVE BAYES
Naive Bayes is a simple but surprisingly powerful algorithm for predictive modeling.
The model consists of two types of probabilities that can be calculated directly from your training data: 1) The probability of each class; and 2) The conditional probability for each class given each x value. Once calculated, the probability model can be used to make predictions for new data using Bayes Theorem. When your data is real-valued it is common to assume a Gaussian distribution (bell curve) so that you can easily estimate these probabilities.
Naive Bayes: Bayes Theorem
Naive Bayes is called naive because it assumes that each input variable is independent. This is a strong assumption and unrealistic for real data, nevertheless, the technique is very effective on a large range of complex problems.
HIRING NOWView All Remote Data Science Jobs
6. K-NEAREST NEIGHBORS
The KNN algorithm is very simple and very effective. The model representation for KNN is the entire training dataset. Simple right?
Predictions are made for a new data point by searching through the entire training set for the K most similar instances (the neighbors) and summarizing the output variable for those K instances. For regression problems, this might be the mean output variable, for classification problems this might be the mode (or most common) class value.
The trick is in how to determine the similarity between the data instances. The simplest technique if your attributes are all of the same scale (all in inches for example) is to use the Euclidean distance, a number you can calculate directly based on the differences between each input variable.
K-Nearest Neighbors
KNN can require a lot of memory or space to store all of the data, but only performs a calculation (or learn) when a prediction is needed, just in time. You can also update and curate your training instances over time to keep predictions accurate.
The idea of distance or closeness can break down in very high dimensions (lots of input variables) which can negatively affect the performance of the algorithm on your problem. This is called the curse of dimensionality. It suggests you only use those input variables that are most relevant to predicting the output variable.
7. LEARNING VECTOR QUANTIZATION
A downside of K-Nearest Neighbors is that you need to hang on to your entire training dataset. The Learning Vector Quantization algorithm (or LVQ for short) is an artificial neural network algorithm that allows you to choose how many training instances to hang onto and learns exactly what those instances should look like.
Learning Vector Quantization
The representation for LVQ is a collection of codebook vectors. These are selected randomly in the beginning and adapted to best summarize the training dataset over a number of iterations of the learning algorithm. After learning, the codebook vectors can be used to make predictions just like K-Nearest Neighbors. The most similar neighbor (best matching codebook vector) is found by calculating the distance between each codebook vector and the new data instance. The class value or (real value in the case of regression) for the best matching unit is then returned as the prediction. Best results are achieved if you rescale your data to have the same range, such as between 0 and 1.
If you discover that KNN gives good results on your dataset try using LVQ to reduce the memory requirements of storing the entire training dataset.
8. SUPPORT VECTOR MACHINES
Support Vector Machines are perhaps one of the most popular and talked about machine learning algorithms.
A hyperplane is a line that splits the input variable space. In SVM, a hyperplane is selected to best separate the points in the input variable space by their class, either class 0 or class 1. In two-dimensions, you can visualize this as a line and let’s assume that all of our input points can be completely separated by this line. The SVM learning algorithm finds the coefficients that result in the best separation of the classes by the hyperplane.
Support Vector Machine
The distance between the hyperplane and the closest data points is referred to as the margin. The best or optimal hyperplane that can separate the two classes is the line that has the largest margin. Only these points are relevant in defining the hyperplane and in the construction of the classifier. These points are called the support vectors. They support or define the hyperplane. In practice, an optimization algorithm is used to find the values for the coefficients that maximizes the margin.
SVM might be one of the most powerful out-of-the-box classifiers and worth trying on your dataset.
9. BAGGING AND RANDOM FOREST
Random forest is one of the most popular and most powerful machine learning algorithms. It is a type of ensemble machine learning algorithm called Bootstrap Aggregation or bagging.
The bootstrap is a powerful statistical method for estimating a quantity from a data sample. Such as a mean. You take lots of samples of your data, calculate the mean, then average all of your mean values to give you a better estimation of the true mean value.
In bagging, the same approach is used, but instead for estimating entire statistical models, most commonly decision trees. Multiple samples of your training data are taken then models are constructed for each data sample. When you need to make a prediction for new data, each model makes a prediction and the predictions are averaged to give a better estimate of the true output value.
Random Forest
Random forest is a tweak on this approach where decision trees are created so that rather than selecting optimal split points, suboptimal splits are made by introducing randomness.
The models created for each sample of the data are therefore more different than they otherwise would be, but still accurate in their unique and different ways. Combining their predictions results in a better estimate of the true underlying output value.
If you get good results with an algorithm with high variance (like decision trees), you can often get better results by bagging that algorithm.
10. BOOSTING AND ADABOOST
Adaboost
Boosting is an ensemble technique that attempts to create a strong classifier from a number of weak classifiers. This is done by building a model from the training data, then creating a second model that attempts to correct the errors from the first model. Models are added until the training set is predicted perfectly or a maximum number of models are added.
AdaBoost was the first really successful boosting algorithm developed for binary classification. It is the best starting point for understanding boosting. Modern boosting methods build on AdaBoost, most notably stochastic gradient boosting machines.
https://www.youtube.com/embed/LsK-xG1cLYA?autoplay=0&start=0&rel=0Explanation of AdaBoost
AdaBoost is used with short decision trees. After the first tree is created, the performance of the tree on each training instance is used to weight how much attention the next tree that is created should pay attention to each training instance. Training data that is hard to predict is given more weight, whereas easy to predict instances are given less weight. Models are created sequentially one after the other, each updating the weights on the training instances that affect the learning performed by the next tree in the sequence. After all the trees are built, predictions are made for new data, and the performance of each tree is weighted by how accurate it was on training data.
Because so much attention is put on correcting mistakes by the algorithm it is important that you have clean data with outliers removed.
Which Machine Learning Algorithm Should I Use?
A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is “which algorithm should I use?” The answer to the question varies depending on many factors, including: (1) The size, quality, and nature of data; (2) The available computational time; (3) The urgency of the task; and (4) What you want to do with the data.
Even an experienced data scientist cannot tell which algorithm will perform the best before trying different algorithms. Although there are many other machine learning algorithms, these are the most popular ones. If you’re a newbie to machine learning, these would be a good starting point to learn.
A machine learning algorithm is a program code (math or program logic) that enables professionals to study, analyze, comprehend and explore large complex datasets. This article explains the fundamentals of machine learning algorithms and reveals the top 10 machine learning algorithms in 2022.
Table of Contents
What Is a Machine Learning Algorithm?
Top 10 Machine Learning Algorithms in 2022
What Is a Machine Learning Algorithm?
A machine learning algorithm refers to a program code (math or program logic) that enables professionals to study, analyze, comprehend, and explore large complex datasets. Each algorithm follows a series of instructions to accomplish the objective of making predictions or categorizing information by learning, establishing, and discovering patterns embedded in the data.
Types of Machine Learning
Machine learning algorithms specify rules and processes that a system should consider while addressing a specific problem. These algorithms analyze and simulate data to predict the result within a predetermined range. Moreover, as new data is fed into these algorithms, they learn, optimize, and improve based on the feedback on previous performance in predicting outcomes. In simple words, machine learning algorithms tend to become ‘smarter’ with each iteration.
Depending on the type of algorithm, machine learning models use several parameters such as gamma parameter, max_depth, n_neighbors, and others to analyze data and produce accurate results. These parameters are a consequence of training data that represents a larger dataset.
Machine learning algorithms are classified into four types based on the learning techniques: supervised, semi-supervised, unsupervised, and reinforcement learning. Regression and classification algorithms are the most popular options for predicting values, identifying similarities, and discovering unusual data patterns.
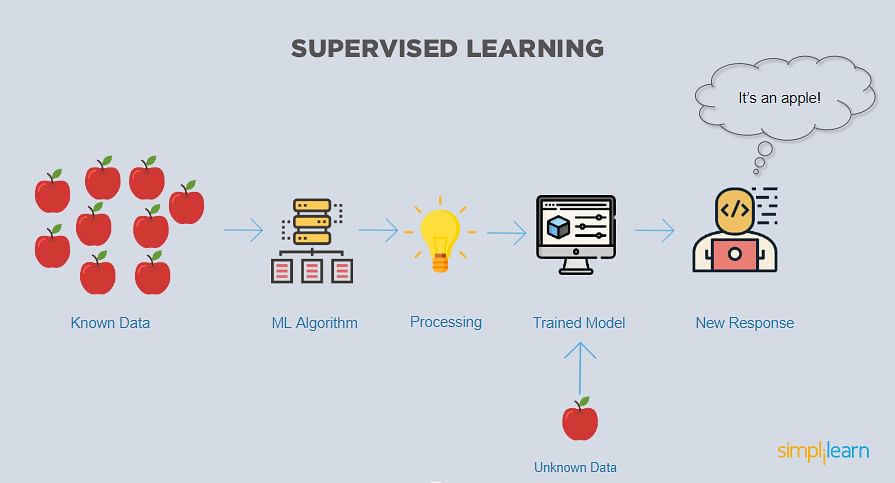
1. Supervised learning
Supervised learning algorithms use labeled datasets to make predictions. This learning technique is beneficial when you know the kind of result or outcome you intend to have.
For example, consider that you have a dataset that specifies the rain that occurred in a geographic area during a particular season over the past 200 years. You intend to know the expected rain during that specific season for the next ten years. Here, the outcome is derived based on the labels existing in the original dataset, i.e., rainfall, geographic area, season, and year.
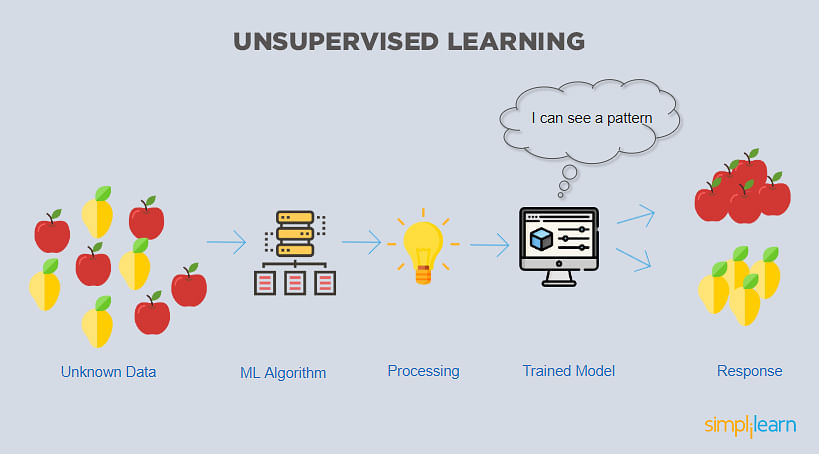
2. Unsupervised learning
Unsupervised learning algorithms use unlabeled data. This learning technique labels the unlabeled data by categorizing the data or expressing its type, form, or structure. This technique comes in handy when the result type is unknown.
For example, when you use a dataset of Facebook users, you intend to classify users who show inclination (based on likes) toward similar Facebook ad campaigns. In this case, the dataset is unlabeled. However, the result will have labels as the algorithm will find similarities between data points while classifying the users.
3. Semi-supervised learning (SSL)
Semi-supervised learning algorithms combine the above two, where labeled and unlabeled data are used. The objective of these algorithms is to categorize unlabeled data based on the information derived from labeled data.
Consider the example of web content classification. Categorizing and classifying the content available on the internet is a time- and resource-intensive task. Apart from AI algorithms, it requires human resources to organize billions of web pages available online. In such cases, SSL models can play a crucial role in accomplishing the task efficiently.
4. Reinforcement learning
Reinforcement learning algorithms use the result or outcome as a benchmark to decide the next action step. In other words, these algorithms learn from previous outcomes, receive feedback after every step, and then decide whether to go ahead with the next step or not. The system learns whether it made a right, wrong, or neutral choice in the process. Automated systems can employ reinforcement learning as they are designed to make decisions with minimal human intervention.
For example, you design a self-driving car and intend to track whether the car is following traffic rules and ensuring safety on the roads. By applying reinforcement learning, the vehicle learns through experience and reinforcement tactics. The algorithm ensures that the car obeys traffic laws of staying in one lane, follows speed limits, and stops encountering pedestrians or animals on the road.
See More:What Is Artificial Intelligence (AI) as a Service? Definition, Architecture, and Trends
Top 10 Machine Learning Algorithms in 2022
Machine learning has significantly impacted our daily lives. Machine learning is omnipresent from smart assistants scheduling appointments, playing songs, and notifying users based on calendar events to NLP-based voice assistants. All such intelligent systems operate on machine learning algorithms.
In data science, each machine learning algorithm handles a specific problem. In some cases, professionals tend to opt for a combination of these algorithms as one algorithm may not be able to solve a particular problem.
Here, we look at the top 10 machine learning algorithms that are frequently used to achieve actual results.
1. Linear regression
Linear regression gives a relationship between input (x) and an output variable (y), also referred to as independent and dependent variables. Let’s understand the algorithm with an example where you are required to arrange a few plastic boxes of different sizes on separate shelves based on their corresponding weights.
The task is to be completed without manually weighing the boxes. Instead, you need to guess the weight just by observing the boxes’ height, dimensions, and sizes. In short, the entire task is driven based on visual analysis. Thus, you have to use a combination of visible variables to make the final arrangement on the shelves.
Linear regression in machine learning is of a similar kind, where the relationship between independent and dependent variables is established by fitting them to a regression line. This line has a mathematical representation given by the linear equation y = mx + c, where y represents the dependent variable, m = slope, x = independent variable, and b = intercept.
The objective of linear regression is to find the best fit line that reveals the relationship between variables y and x.
2. Logistic regression
The dependent variable is of binary type (dichotomous) in logistic regression. This type of regression analysis describes data and explains the relationship between one dichotomous variable and one or more independent variables.
Logistic regression is used in predictive analysis where pertinent data predict an event probability to a logit function. Thus, it is also called logit regression.
Mathematically, logistic regression is represented by the equation:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Here,
x = input value, y = predicted output, b0 = bias or intercept term, b1 = coefficient for input (x).
Logistic regression could be used to predict whether a particular team will win (1) the FIFA World Cup 2022 or not (0), or whether a lockdown will be imposed (1) due to rising COVID-19 cases or not (0). Thus, the binary outcomes of logistic regression facilitate faster decision-making as you only need to pick one out of the two alternatives.
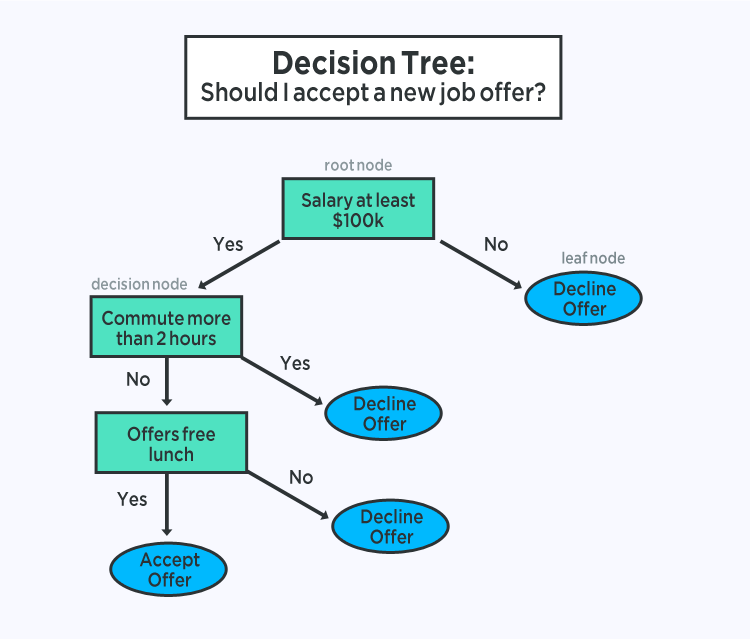
3. Decision trees
With a decision tree, you can visualize the map of potential results for a series of decisions. It enables companies to compare possible outcomes and then take a straightforward decision based on parameters such as advantages and probabilities that are beneficial to them.
Decision tree algorithms can potentially anticipate the best option based on a mathematical construct and also come in handy while brainstorming over a specific decision. The tree starts with a root node (decision node) and then branches into sub-nodes representing potential outcomes.
Each outcome can further create child nodes that can open up other possibilities. The algorithm generates a tree-like structure that is used for classification problems. For example, consider the decision tree below that helps finalize a weekend plan based on the weather forecast.
Decision Tree
4. Support vector machines (SVMs)
Support vector machine algorithms are used to accomplish both classification and regression tasks. These are supervised machine learning algorithms that plot each piece of data in the n-dimensional space, with n referring to the number of features. Each feature value is associated with a coordinate value, making it easier to plot the features.
Moreover, classification is further performed by distinctly determining the hyper-plane that separates the two sets of support vectors or classes. A good separation ensures a good classification between the plotted data points.
Support Vector Machines
In simple words, SVMs represent the coordinates for individual observations. These are popular machine learning classifiers used in applications such as data classification, facial expression classification, text classification, steganography detection in digital images, speech recognition, and others.
5. Naive Bayes algorithm
Naive Bayes refers to a probabilistic machine learning algorithm based on the Bayesian probability model and is used to address classification problems. The fundamental assumption of the algorithm is that features under consideration are independent of each other and a change in the value of one does not impact the value of the other.
For example, you can consider a ball, a cricket ball, if it is red, round, has a 7.1-7.26 cm diameter, and has a mass of 156-163 g. Although all these features could be interdependent, each one contributes to the probability that it is a cricket ball. This is the reason the algorithm is referred to as ‘naïve’.
Let’s look at the mathematical representation of the algorithm.
If X, Y = probabilistic events, P (X) = probability of X being true, P(X|Y) = conditional probability of X being true in case Y is true.
Then, Bayes’ theorem is given by the equation:
P (X|Y) = (P (Y|X) x P (X)) /P (Y)
A naive Bayesian approach is easy to develop and implement. It is capable of handling massive datasets and is useful for making real-time predictions. Its applications include spam filtering, sentiment analysis and prediction, document classification, and others.
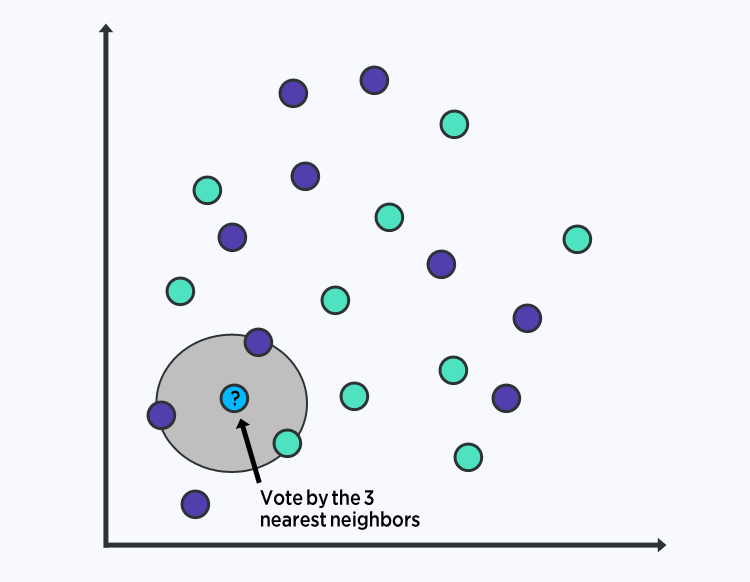
6. KNN classification algorithm
The K Nearest Neighbors (KNN) algorithm is used for both classification and regression problems. It stores all the known use cases and classifies new use cases (or data points) by segregating them into different classes. This classification is accomplished based on the similarity score of the recent use cases to the available ones.
KNN is a supervised machine learning algorithm, wherein ‘K’ refers to the number of neighboring points we consider while classifying and segregating the known n groups. The algorithm learns at each step and iteration, thereby eliminating the need for any specific learning phase. The classification is based on the neighbor’s majority vote.
The algorithm uses these steps to perform the classification:
For a training dataset, calculate the distance between the data points that are to be classified and the rest of the data points.
Choose the closest ‘K’ elements based on the distance or function used.
Consider a ‘majority vote’ between the K points–the class or label dominating all data points reveals the final ranking.
KNN
Real-life applications of KNN algorithms include facial recognition, text mining, and recommendation systems such as Amazon, Netflix, and others.
7. K-Means
K-Means is a distance-based unsupervised machine learning algorithm that accomplishes clustering tasks. In this algorithm, you classify datasets into clusters (K clusters) where the data points within one set remain homogenous, and the data points from two different clusters remain heterogeneous.
The clusters under K-Means are formed using these steps:
Initialization: The K-means algorithm selects centroids for each cluster (‘K’ number of points).
Assign objects to centroid: Clusters are formed with the closest centroids (K clusters) at each data point.
Centroid update: Create new centroids based on existing clusters and determine the closest distance for each data point based on new centroids. Here, the position of the centroid also gets updated whenever required.
Repeat: Repeat the process till the centroids do not change.
K-Means
K-Means clustering is useful in applications such as clustering Facebook users with common likes and dislikes, document clustering, segmenting customers who buy similar ecommerce products, etc.
8. Random forest algorithm
Random forest algorithms use multiple decision trees to handle classification and regression problems. It is a supervised machine learning algorithm where different decision trees are built on different samples during training. These algorithms help estimate missing data and tend to keep the accuracy intact in situations when a large chunk of data is missing in the dataset.
Random forest algorithms follow these steps:
Select random data samples from a given data set.
Build a decision tree for each data sample and provide the prediction result for each decision tree.
Carry out voting for each expected result.
Select the final prediction result based on the highest voted prediction result.
Random Forest Algorithm
This algorithm finds applications in finance, ecommerce (recommendation engines), computational biology (gene classification, biomarker discovery), and others.
9. Artificial neural networks (ANNs)
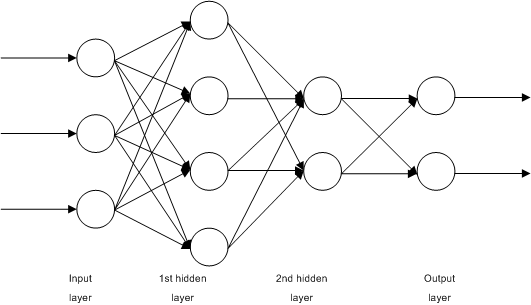
Artificial neural networks are machine learning algorithms that mimic the human brain (neuronal behavior and connections) to solve complex problems. ANN has three or more interconnected layers in its computational model that process the input data.
The first layer is the input layer or neurons that send input data to deeper layers. The second layer is called the hidden layer. The components of this layer change or tweak the information received through various previous layers by performing a series of data transformations. These are also called neural layers. The third layer is the output layer that sends the final output data for the problem.
ANN algorithms find applications in smart home and home automation devices such as door locks, thermostats, smart speakers, lights, and appliances. They are also used in the field of computational vision, specifically in detection systems and autonomous vehicles.
10. Recurrent neural networks (RNNs)
Recurrent neural networks refer to a specific type of ANN that processes sequential data. Here, the result of the previous step acts as the input to the current step. This is facilitated via the hidden state that remembers information about a sequence. It acts as a memory that maintains the information on what was previously calculated. The memory of RNN reduces the overall complexity of the neural network.
Recurrent Neural Network
RNN analyzes time series data and possesses the ability to store, learn, and maintain contexts of any length. RNN is used in cases where time sequence is of paramount importance, such as speech recognition, language translation, video frame processing, text generation, and image captioning. Even Siri, Google Assistant, and Google Translate use the RNN architecture.
See More:What Is Logistic Regression? Equation, Assumptions, Types, and Best Practices
Takeaways
Machine learning algorithms tend to learn from observations. They analyze data, map input to output, and detect data patterns. The algorithms become smarter as they process more data, improving overall predictive performance.
Depending on the changing requirements and the complexity of the problems, new variants of existing machine learning algorithms continue to emerge. You can choose the algorithm that best suits your needs and get a head start on machine learning.
Most of us would find it hard to go a full day without using at least one app or web service driven by machine learning. But what is machine learning (ML), exactly?
Though the term machine learning has become increasingly common, many people still don’t know exactly what it means and how it is applied, nor do they understand the role of machine learning algorithms and datasets in data science. Here, we will examine the question “what is ML?”
We will provide insight into how machine learning is used by data scientists and others, how it was developed, and what lies ahead as it continues to evolve.
Definition of Machine Learning
The basic concept of machine learning in data science involves using statistical learning and optimization methods that let computers analyze datasets and identify patterns (view a visual of machine learning via R2D3External link:open_in_new). Machine learning techniques leverage data mining to identify historic trends and inform future models.
The typical supervised machine learning algorithm consists of roughly three components:
A decision process: A recipe of calculations or other steps that takes in the data and “guesses” what kind of pattern your algorithm is looking to find.
An error function: A method of measuring how good the guess was by comparing it to known examples (when they are available). Did the decision process get it right? If not, how do you quantify “how bad” the miss was?
An updating or optimization process: A method in which the algorithm looks at the miss and then updates how the decision process comes to the final decision, so next time the miss won’t be as great.
For example, if you’re building a movie recommendation system, you can provide information about yourself and your watch history as input. The algorithm will take that input and learn how to return an accurate output: movies you will enjoy. Some inputs could be movies you watched and rated highly, the percentage of movies you’ve seen that are comedies, or how many movies feature a particular actor. The algorithm’s job is to find these parameters and assign weights to them. If the algorithm gets it right, the weights it used stay the same. If it gets a movie wrong, the weights that led to the wrong decision get turned down so it doesn’t make that kind of mistake again.
Since a machine learning algorithm updates autonomously, the analytical accuracy improves with each run as it teaches itself from the data it analyzes. This iterative nature of learning is both unique and valuable because it occurs without human intervention — empowering the algorithm to uncover hidden insights without being specifically programmed to do so.
Types of Machine Learning
There are many types of machine learning models defined by the presence or absence of human influence on raw data — whether a reward is offered, specific feedback is given, or labels are used.
According to Nvidia.com, there are different machine learning models such as:External link:open_in_new
Supervised learning: The dataset being used has been pre-labeled and classified by users to allow the algorithm to see how accurate its performance is.
Unsupervised learning: The raw dataset being used is unlabeled and an algorithm identifies patterns and relationships within the data without help from users.
Semi-supervised learning: The dataset contains structured and unstructured data, which guides the algorithm on its way to making independent conclusions. The combination of the two data types in one training dataset allows machine learning algorithms to learn to label unlabeled data.
Reinforcement learning: The dataset uses a “rewards/punishments” system, offering feedback to the algorithm to learn from its own experiences by trial and error.
Finally, there’s the concept of deep learning, which is a newer area of machine learning that automatically learns from datasets without introducing human rules or knowledge. This requires massive amounts of raw data for processing — and the more data that is received, the more the predictive model improves.
Commonly Used Machine Learning Algorithms
The purpose of machine learning is to use machine learning algorithms to analyze data. By leveraging machine learning, a developer can improve the efficiency of a task involving large quantities of data without the need for manual human input. Around the world, strong machine learning algorithms can be used to improve the productivity of professionals working in data science, computer science, and many other fields.
There are a number of machine learning algorithms that are commonly used by modern technology companies. Each of these machine learning algorithms can have numerous applications in a variety of educational and business settings.
Read on to learn about many different machine learning algorithms, as well as how they are applicable to the broader field of machine learning.
Linear Regression
Linear regression is an algorithm used to analyze the relationship between independent input variables and at least one target variable. This kind of regression is used to predict continuous outcomes — variables that can take any numerical outcome. For example, given data on the neighborhood and property, can a model predict the sale value of a home? Linear relationships occur when the data relationship being observed tends to follow a straight line overall — and as such, this model can be used to observe whether a data point is increasing, decreasing, or remaining the same relative to some independent variable, such as time elapsed or position.
Machine learning models can be employed to analyze data in order to observe and map linear regressions. Independent variables and target variables can be input into a linear regression machine learning model, and the model will then map the coefficients of the best fit line to the data. In other words, the linear regression models attempt to map a straight line, or a linear relationship, through the dataset.
Logistic Regression
Logistic regression is a supervised learning algorithm that is used for classification problems. Instead of continuous output like in linear regression, a logistic model predicts the probability of a binary event occurring. For example, given an email, can a model predict whether the contents are spam or not?
Machine learning algorithms can use logistic regression models to determine categorical outcomes. When given a dataset, the logistic regression model can check any weights and biases and then use the given dependent categorical target variables to understand how to correctly categorize that dataset.
Neural Networks
Neural networks are artificial intelligence algorithms that attempt to replicate the way the human brain processes information to understand and intelligently classify data. These neural network learning algorithms are used to recognize patterns in data and speech, translate languages, make financial predictions, and much more through thousands, or sometimes millions, of interconnected processing nodes. Data is “fed-forward” through layers that process and assign weights, before being sent to the next layer of nodes, and so on.
Crucially, neural network algorithms are designed to quickly learn from input training data in order to improve the proficiency and efficiency of the network’s algorithms. As such, neural networks serve as key examples of the power and potential of machine learning models.
Decision Trees
Decision trees are data structures with nodes that are used to test against some input data. The input data is tested against the leaf nodes down the tree to attempt to produce the correct, desired output. They are easy to visually understand due to their tree-like structure and can be designed to categorize data based on some categorization schema.
Decision trees are one method of supervised learning, a field in machine learning that refers to how the predictive machine learning model is devised via the training of a learning algorithm.
Random Forest
Random forest models are capable of classifying data using a variety of decision tree models all at once. Like decision trees, random forests can be used to determine the classification of categorical variables or the regression of continuous variables. These random forest models generate a number of decision trees as specified by the user, forming what is known as an ensemble. Each tree then makes its own prediction based on some input data, and the random forest machine learning algorithm then makes a prediction by combining the predictions of each decision tree in the ensemble.
What Is Deep Learning?
Deep learning models are a nascent subset of machine learning paradigms. Deep learning uses a series of connected layers which together are capable of quickly and efficiently learning complex prediction models.
If deep learning sounds similar to neural networks, that’s because deep learning is, in fact, a subset of neural networks. Both try to simulate the way the human brain functions. Deep learning models can be distinguished from other neural networks because deep learning models employ more than one hidden layer between the input and the output. This enables deep learning models to be sophisticated in the speed and capability of their predictions.
Deep learning modelsExternal link:open_in_new are employed in a variety of applications and services related to artificial intelligence to improve levels of automation in previously manual tasks. You might find this emerging approach to machine learning powering digital assistants like Siri and voice-driven TV remotes, in fraud detection technology for credit card companies, and as the bedrock of operating systems for self-driving cars.
Machine Learning (ML) vs. Artificial Intelligence (AI)
Trying to make sense of the distinctions between machine learning vs. AI can be tricky, since the two are closely related. In fact, machine learning algorithms are a subset of artificial intelligence algorithms — but not the other way around.
To pinpoint the difference between machine learning and artificial intelligence, it’s important to understand what each subject encompasses. AI refers to any of the software and processes that are designed to mimic the way humans think and process information. It includes computer vision, natural language processing, robotics, autonomous vehicle operating systems, and of course, machine learning. With the help of artificial intelligence, devices are able to learn and identify information in order to solve problems and offer key insights into various domains.
On the other hand, machine learning specifically refers to teaching devices to learn information given to a dataset without manual human interference. This approach to artificial intelligence uses machine learning algorithms that are able to learn from data over time in order to improve the accuracy and efficiency of the overall machine learning model. There are numerous approaches to machine learning, including the previously mentioned deep learning model.
Why Is Machine Learning Important?
Machine learning and data mining, a component of machine learning, are crucial tools used by many companies and researchers. There are two main reasons for this:
Scale of data: Companies are faced with massive volumes and varieties of data that need to be processed. Processing power is more efficient and readily available. Models that can be programmed to process data on their own, determine conclusions, and identify patterns are invaluable.
Unexpected findings: Since a machine learning algorithm updates autonomously, analytical accuracy improves with each run as it teaches itself from the datasets it analyzes. This iterative nature of learning is unique and valuable because it occurs without human intervention — in other words, machine learning algorithms can uncover hidden insights without being specifically programmed to do so.
Who Is Using Machine Learning?
Companies leveraging algorithms to sort through data and optimize business operations aren’t new. Leveraging algorithms extends not only to digital business models such as web services or apps, but also to any company or industry where data can be gathered,External link:open_in_new including the following:
Marketing and sales
Financial services
Brick-and-mortar retail
Health care
Transportation
Oil and gas
Government
Amazon, Facebook, Netflix, and, of course, Google have all been using machine learning algorithms to drive searches, recommendations, targeted advertising, and more for well over a decade. For example, Uber Eats shared in a GeekWire article that they use data mining and machine learningExternal link:open_in_new to estimate delivery times.
Evolution of Machine Learning
Although advances in computing technologies have made machine learning more popular than ever, it’s not a new concept. According to Forbes, the origins of machine learning date back to 1950External link:open_in_new. Speculating on how one could tell if they had developed a truly integrated artificial intelligence (AI), Alan Turing created what is now referred to as the Turing test, which suggests that one way of testing whether or not the AI is capable of understanding language is to see if it’s able to fool a human into thinking they are speaking to another person.
In 1952, Arthur Samuel wrote the first learning program for IBM, this time involving a game of checkers. The work of many other machine learning pioneers followed, including Frank Rosenblatt’s design of the first neural network in 1957 and Gerald DeJong’s introduction of explanation-based learning in 1981.
In the 1990s, a major shift occurred in machine learning when the focus moved away from a knowledge-based approach to one driven by data. This was a critical decade in the field’s evolution, as scientists began creating computer programs that could analyze large datasets and learn in the process.
The 2000s were marked by unsupervised learning becoming widespread, eventually leading to the advent of deep learning and the ubiquity of machine learning as a practice.
Milestones in machine learning are marked by instances in which an algorithm is able to beat the performance of a human being, including Russian chess grandmaster Garry Kasparov’s defeat at the hands of IBM supercomputer Deep Blue in 1997 and, more recently, the 2016 victory of the Google DeepMind AI program AlphaGo over Lee Sedol playing Go, a game notorious for its massively large space of possibilities in game play.
Today, researchers are hard at work to expand on these achievements. As machine learning and artificial intelligence applications become more popular, they’re also becoming more accessible, moving from server-based systems to the cloud. At Google Next 2018, Google touted several new deep learning and machine learning capabilities,External link:open_in_new like Cloud AutoML, BigQuery ML, and more. During the past few years, Amazon, Microsoft, Baidu, and IBM have all unveiled machine learning platforms through open source projects and enterprise cloud services. Machine learning algorithms are here to stay, and they’re rapidly widening the parameters of what research and industry can accomplish.
What Is the Future of Machine Learning?
Machine learning algorithms are being used around the world in nearly every major sector, including business, government, finance, agriculture, transportation, cybersecurity, and marketing. Such rapid adoption across disparate industries is evidence of the value that machine learning (and, by extension, data science) creates. Armed with insights from vast datasets — which often occur in real time — organizations can operate more efficiently and gain a competitive edge.
The applications of machine learning and artificial intelligence extend beyond commerce and optimizing operations. Following its Jeopardy win, IBM applied the Watson algorithm to medical research literature,External link:open_in_new thereby “sending Watson to medical school.” More recently, precision medicine initiatives are breaking new ground using machine learning algorithms driven by massive artificial neural networks (i.e., “deep learning” algorithms) to detect subtle patterns in genetic structure and how one might respond to different medical treatments. Breakthroughs in how machine learning algorithms can be used to represent natural language have enabled a surge in new possibilities that include automated text translation, text summarization techniques, and sophisticated question and answering systems. Other advancements involve learning systems for automated robotics, self-flying drones, and the promise of industrialized self-driving cars.
The continued digitization of most sectors of society and industry means that an ever-growing volume of data will continue to be generated. The ability to gain insights from these vast datasets is one key to addressing an enormous array of issues — from identifying and treating diseases more effectively, to fighting cyber criminals, to helping organizations operate more effectively to boost the bottom line.
The universal capabilities that machine learning enables across so many sectors make it an essential tool — and experts predict a bright future for its use. In fact, in Gartner’s “Top 10 Technology Trends for 2017,”External link:open_in_new machine learning and artificial intelligence topped the list:
“AI and machine learning […] can also encompass more advanced systems that understand, learn, predict, adapt and potentially operate autonomously.” The article also notes: “The combination of extensive parallel processing power, advanced algorithms and massive datasets to feed the algorithms has unleashed this new era.”
Machine Learning and UC Berkeley School of Information
In recognition of machine learning’s critical role today and in the future, datascience@berkeley includes an in-depth focus on machine learning in its online Master of Information and Data Science (MIDS) curriculum.
The foundation course is Applied Machine Learning,External link:open_in_new which provides a broad introduction to the key ideas in machine learning. The emphasis is on intuition and practical examples rather than theoretical results, though some experience with probability, statistics, and linear algebra is important. Students learn how to apply powerful machine learning techniques to new problems, run evaluations and interpret results, and think about scaling up from thousands of data points to billions.
The advanced course, Machine Learning at Scale, builds on and goes beyond the collect-and-analyze phase of big data by focusing on how machine learning algorithms can be rewritten and extended to scale to work on petabytes of data, both structured and unstructured, to generate sophisticated models used for real-time predictions.
In the Natural Language Processing with Deep Learning course, students learn how-to skills using cutting-edge distributed computation and machine learning systems such as Spark. They are trained to code their own implementations of large-scale projects, like Google’s original PageRank algorithm, and discover how to use modern deep learning techniques to train text-understanding algorithms.
How Do You Decide Which Machine Learning Algorithm to Use?
What is the Best Programming Language for Machine Learning?
Enterprise Machine Learning and MLOps
A Look at Some Machine Learning Algorithms and Processes
Prerequisites for Machine Learning (ML)
So, What Next?
Machine learning is an exciting branch of Artificial Intelligence, and it’s all around us. Machine learning brings out the power of data in new ways, such as Facebook suggesting articles in your feed. This amazing technology helps computer systems learn and improve from experience by developing computer programs that can automatically access data and perform tasks via predictions and detections.
As you input more data into a machine, this helps the algorithms teach the computer, thus improving the delivered results. When you ask Alexa to play your favorite music station on Amazon Echo, she will go to the station you played most often. You can further improve and refine your listening experience by telling Alexa to skip songs, adjust the volume, and many more possible commands. Machine Learning and the rapid advance of Artificial Intelligence makes this all possible.
Let us start by answering the question – What is Machine Learning?
What is Machine Learning, Exactly?
For starters, machine learning is a core sub-area of Artificial Intelligence (AI). ML applications learn from experience (or to be accurate, data) like humans do without direct programming. When exposed to new data, these applications learn, grow, change, and develop by themselves. In other words, machine learning involves computers finding insightful information without being told where to look. Instead, they do this by leveraging algorithms that learn from data in an iterative process.
The concept of machine learning has been around for a long time (think of the World War II Enigma Machine, for example). However, the idea of automating the application of complex mathematical calculations to big data has only been around for several years, though it’s now gaining more momentum.
At a high level, machine learning is the ability to adapt to new data independently and through iterations. Applications learn from previous computations and transactions and use “pattern recognition” to produce reliable and informed results.
Now that we understand what Machine Learning is, let us understand how it works and why you should opt for an AI course like our AI & Machine Learning Bootcamp today!
How Does Machine Learning Work?
Machine Learning is, undoubtedly, one of the most exciting subsets of Artificial Intelligence. It completes the task of learning from data with specific inputs to the machine. It’s important to understand what makes Machine Learning work and, thus, how it can be used in the future.
The Machine Learning process starts with inputting training data into the selected algorithm. Training data being known or unknown data to develop the final Machine Learning algorithm. The type of training data input does impact the algorithm, and that concept will be covered further momentarily.
New input data is fed into the machine learning algorithm to test whether the algorithm works correctly. The prediction and results are then checked against each other.
If the prediction and results don’t match, the algorithm is re-trained multiple times until the data scientist gets the desired outcome. This enables the machine learning algorithm to continually learn on its own and produce the optimal answer, gradually increasing in accuracy over time.
The next section discusses the three types of and use of machine learning.
Become a Data Scientist by learning from the best with Simplilearn’s Caltech Post Graduate Program In Data Science. Enroll Now!
What are the Different Types of Machine Learning?
Machine Learning is complex, which is why it has been divided into two primary areas, supervised learning and unsupervised learning. Each one has a specific purpose and action, yielding results and utilizing various forms of data. Approximately 70 percent of machine learning is supervised learning, while unsupervised learning accounts for anywhere from 10 to 20 percent. The remainder is taken up by reinforcement learning.
1. Supervised Learning
In supervised learning, we use known or labeled data for the training data. Since the data is known, the learning is, therefore, supervised, i.e., directed into successful execution. The input data goes through the Machine Learning algorithm and is used to train the model. Once the model is trained based on the known data, you can use unknown data into the model and get a new response.
In this case, the model tries to figure out whether the data is an apple or another fruit. Once the model has been trained well, it will identify that the data is an apple and give the desired response.
Here is the list of top algorithms currently being used for supervised learning are:
Polynomial regression
Random forest
Linear regression
Logistic regression
Decision trees
K-nearest neighbors
Naive Bayes
Now let’s learn about unsupervised learning
The following part of the What is Machine Learning article focuses on unsupervised learning.
2. Unsupervised Learning
In unsupervised learning, the training data is unknown and unlabeled – meaning that no one has looked at the data before. Without the aspect of known data, the input cannot be guided to the algorithm, which is where the unsupervised term originates from. This data is fed to the Machine Learning algorithm and is used to train the model. The trained model tries to search for a pattern and give the desired response. In this case, it is often like the algorithm is trying to break code like the Enigma machine but without the human mind directly involved but rather a machine.
In this case, the unknown data consists of apples and pears which look similar to each other. The trained model tries to put them all together so that you get the same things in similar groups.
The top 7 algorithms currently being used for unsupervised learning are:
Partial least squares
Fuzzy means
Singular value decomposition
K-means clustering
Apriori
Hierarchical clustering
Principal component analysis
3. Reinforcement Learning
Like traditional types of data analysis, here, the algorithm discovers data through a process of trial and error and then decides what action results in higher rewards. Three major components make up reinforcement learning: the agent, the environment, and the actions. The agent is the learner or decision-maker, the environment includes everything that the agent interacts with, and the actions are what the agent does.
Reinforcement learning happens when the agent chooses actions that maximize the expected reward over a given time. This is easiest to achieve when the agent is working within a sound policy framework.
Now let’s see why Machine Learning is such a vital concept today.
Why is Machine Learning Important?
To better answer the question :what is machine learning” and understand the uses of Machine Learning, consider some of the applications of Machine Learning: the self-driving Google car, cyber fraud detection, and online recommendation engines from Facebook, Netflix, and Amazon. Machines make all these things possible by filtering useful pieces of information and piecing them together based on patterns to get accurate results.
The process flow depicted here represents how Machine Learning works:
The rapid evolution in Machine Learning (ML) has caused a subsequent rise in the use cases, demands, and the sheer importance of ML in modern life. Big Data has also become a well-used buzzword in the last few years. This is, in part, due to the increased sophistication of Machine Learning, which enables the analysis of large chunks of Big Data. Machine Learning has also changed the way data extraction and interpretation are done by automating generic methods/algorithms, thereby replacing traditional statistical techniques.
Now that you know what machine learning is, its types, and its importance, let us move on to the uses of machine learning.
Main Uses of Machine Learning
Typical results from machine learning applications usually include web search results, real-time ads on web pages and mobile devices, email spam filtering, network intrusion detection, and pattern and image recognition. All these are the by-products of using machine learning to analyze massive volumes of data.
Traditionally, data analysis was trial and error-based, an approach that became increasingly impractical thanks to the rise of large, heterogeneous data sets. Machine learning provides smart alternatives for large-scale data analysis. Machine learning can produce accurate results and analysis by developing fast and efficient algorithms and data-driven models for real-time data processing.
Pro Tip: For more on Big Data and how it’s revolutionizing industries globally, check out our “What is Big Data?” article.
According to Marketwatch, the global machine learning market is expected to grow at a healthy rate of over 45.9 percent during the period of 2017-2025. If this trend holds, then we will see a greater use of machine learning across a wide spectrum of industries worldwide. Machine learning is here to stay!
How Do You Decide Which Machine Learning Algorithm to Use?
There are dozens of different algorithms to choose from, but there’s no best choice or one that suits every situation. In many cases, you must resort to trial and error. But there are some questions you can ask that can help narrow down your choices.
What’s the size of the data you will be working with?
What’s the type of data you will be working with?
What kinds of insights are you looking for from the data?
How will those insights be used?
What is the Best Programming Language for Machine Learning?
If you’re looking at the choices based on sheer popularity, then Python gets the nod, thanks to the many libraries available as well as the widespread support. Python is ideal for data analysis and data mining and supports many algorithms (for classification, clustering, regression, and dimensionality reduction), and machine learning models.
Enterprise Machine Learning and MLOps
Enterprise machine learning gives businesses important insights into customer loyalty and behavior, as well as the competitive business environment. Machine learning also can be used to forecast sales or real-time demand.
Machine learning operations (MLOps) is the discipline of Artificial Intelligence model delivery. It helps organizations scale production capacity to produce faster results, thereby generating vital business value.
A Look at Some Machine Learning Algorithms and Processes
If you’re studying what is Machine Learning, you should familiarize yourself with standard Machine Learning algorithms and processes. These include neural networks, decision trees, random forests, associations, and sequence discovery, gradient boosting and bagging, support vector machines, self-organizing maps, k-means clustering, Bayesian networks, Gaussian mixture models, and more.
There are other machine learning tools and processes that leverage various algorithms to get the most value out of big data. These include:
Comprehensive data quality and management
GUIs for building models and process flows
Interactive data exploration and visualization of model results
Comparisons of different Machine Learning models to quickly identify the best one
Automated ensemble model evaluation to determine the best performers
Easy model deployment so you can get repeatable, reliable results quickly
An integrated end-to-end platform for the automation of the data-to-decision process
Prerequisites for Machine Learning (ML)
For those interested in learning beyond what is Machine Learning, a few requirements should be met to be successful in pursual of this field. These requirements include:
Basic knowledge of programming languages such as Python, R, Java, JavaScript, etc
Intermediate knowledge of statistics and probability
Basic knowledge of linear algebra. In the linear regression model, a line is drawn through all the data points, and that line is used to compute new values.
Understanding of calculus
Knowledge of how to clean and structure raw data to the desired format to reduce the time taken for decision-making.
These prerequisites will improve your chances of successfully pursuing a machine learning career. For a refresh on the above-mentioned prerequisites, the Simplilearn YouTube channel provides succinct and detailed overviews.
Acelerate your career in AI and ML with the AI and ML Courses with Purdue University collaborated with IBM.
So, What Next?
Wondering how to get ahead after this “What is Machine Learning” tutorial? Consider taking Simplilearn’s Artificial Intelligence Course which will set you on the path to success in this exciting field. Master Machine Learning concepts, machine learning steps and techniques including supervised and unsupervised learning, mathematical and heuristic aspects, and hands-on modeling to develop algorithms and prepare you for the role of Machine Learning Engineer.
You can also take the AI and ML Course in partnership with Purdue University. This program gives you in-depth and practical knowledge on the use of machine learning in real world cases. Further, you will learn the basics you need to succeed in a machine learning career like statistics, Python, and data science.
You should also consider accelerating your AI or ML career with the AI Course with Caltech University and in collaboration with IBM.
Machine learning is the future, and the future is now. Are you ready to transform? Start your journey with Simplilearn!