Some Basic Machine Learning Algorithms
elow you’ll find descriptions of and links to some basic and powerful machine-learning algorithms, including:
- Attention Mechanisms & Memory Networks
- Bayes Theorem & Naive Bayes Classifiers
- Decision Trees
- Eigenvectors, Eigenvalues and Machine Learning
- Evolutionary & Genetic Algorithms
- Expert Systems/Rules Engines/Symbolic Reasoning
- Generative Adversarial Networks (GANs)
- Graph Analytics and ML
- Linear Regression
- Logistic Regression
- LSTMs and Recurrent Neural Networks
- Markov Chain Monte Carlo Methods (MCMC)
- Neural Networks
- Random Forests
- Reinforcement Learning
- Word2vec, Neural Embeddings and NLP
Machine learning algorithms are programs (math and logic) that adjust themselves to perform better as they are exposed to more data. The “learning” part of machine learning means that those programs change how they process data over time, much as humans change how they process data by learning. So a machine-learning algorithm is a program with a specific way to adjusting its own parameters, given feedback on its previous performance in making predictions about a dataset.
Linear Regression
Linear regression is simple, which makes it a great place to start thinking about algorithms more generally. Here it is:
ŷ = a * x + b
Read aloud, you’d say “y-hat equals a times x plus b.”
- y-hat is the output, or guess made by the algorithm, the dependent variable.
- a is the coefficient. It’s also the slope of the line that expresses the relationship between x and y-hat.
- x is the input, the given or independent variable.
- b is the intercept, where the line crosses the y axis.
Linear regression expresses a linear relationship between the input x and the output y; that is, for every change in x, y-hat will change by the same amount no matter how far along the line you are. The x is transformed by the same a and b at every point.
Linear regression with only one input variable is called Simple Linear Regression. With more than one input variable, it is called Multiple Linear Regression. An example of Simple Linear Regression would be attempting to predict a house price based on the square footage of the house and nothing more.
house_price_estimate = a * square_footage + b
Multiple Linear Regression would take other variables into account, such as the distance between the house and a good public school, the age of the house, etc.
The reason why we’re dealing with y-hat, an estimate about the real value of y, is because linear regression is a formula used to estimate real values, and error is inevitable. Linear regression is often used to “fit” a scatter plot of given x-y pairs. A good fit minimizes the error between y-hat and the actual y; that is, choosing the right a and b will minimize the sum of the differences between each y and its respective y-hat.
That scatter plot of data points may look like a baguette – long in one direction and short in another – in which case linear regression may achieve a fit. (If the data points look like a meandering river, a straight line is probably not the right function to use to make predictions.)
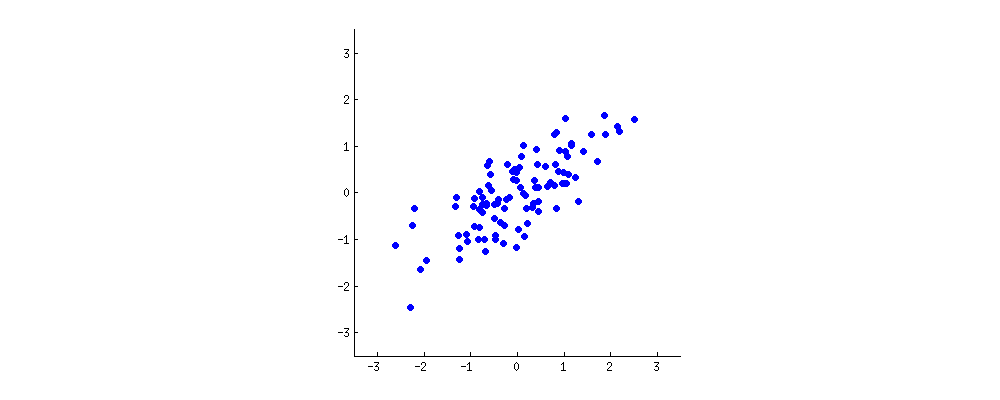
Testing one line after another against the data points of the scatter plot, and automatically correcting it in order to minimize the sum of differences between the line and the points, could be thought of as machine learning in its simplest form.
Apply AI to Business Simulations »
Logistic Regression
Let’s analyze the name first. Logistic regression is not really regression, not in the sense of linear regression, which predicts continuous numerical values. (And it has nothing to do with logistics. 😉
Logistic regression does not do that. It’s actually a binomial classifier that acts like a light switch. A light switch essentially has two states, on and off. Logistic regression takes input data and classifies it as category or not_category, on or off expressed as 1 or 0, based on the strength of the input’s signal. So it’s a light switch for signal that you find in the data. If you want to mix the metaphor, it’s actually more like a transistor, since it both amplifies and gates the signal. More on that here.
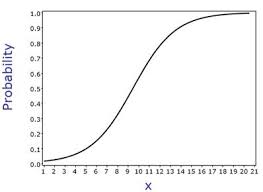
Logistic regression takes input data and squishes it, so that no matter what the range of the input is, it will be compressed into the space between 1 and 0. Notice, in the image below, no matter how large the input x becomes, the output y cannot exceed 1, which it asymptotically approaches, and no matter low x is, y cannot fall below 0. That’s how logistic regression compresses input data into a range between 0 and 1, through this s-shaped, sigmoidal transform.
Decision Tree
Decision, or decide, stems from the Latin decidere, which itself is the combination of “de” (off) and “caedere” (to cut). So decision is about the cutting off of possibilities. Decision trees can be used to classify data, and they cut off possibilities of what a given instance of data might be by examining a data point’s features. Is it bigger than a bread box? Well, then it’s not a marble. Is it alive? Well, then it’s not a bicycle. Think of a decision as a game of 20 questions that an algorithm is asking about the data point under examination.
A decision tree is a series of nodes, a directional graph that starts at the base with a single node and extends to the many leaf nodes that represent the categories that the tree can classify. Another way to think of a decision tree is as a flow chart, where the flow starts at the root node and ends with a decision made at the leaves. It is a decision-support tool. It uses a tree-like graph to show the predictions that result from a series of feature-based splits.
Here are some useful terms for describing a decision tree:
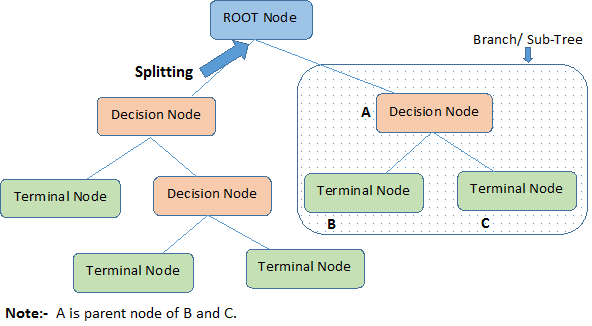
- Root Node: A root node is at the beginning of a tree. It represents entire population being analyzed. From the root node, the population is divided according to various features, and those sub-groups are split in turn at each decision node under the root node.
- Splitting: It is a process of dividing a node into two or more sub-nodes.
- Decision Node: When a sub-node splits into further sub-nodes, it’s a decision node.
- Leaf Node or Terminal Node: Nodes that do not split are called leaf or terminal nodes.
- Pruning: Removing the sub-nodes of a parent node is called pruning. A tree is grown through splitting and shrunk through pruning.
- Branch or Sub-Tree: A sub-section of decision tree is called branch or a sub-tree, just as a portion of a graph is called a sub-graph.
- Parent Node and Child Node: These are relative terms. Any node that falls under another node is a child node or sub-node, and any node which precedes those child nodes is called a parent node.
Decision trees are a popular algorithm for several reasons:
- Explanatory Power: The output of decision trees is interpretable. It can be understood by people without analytical or mathematical backgrounds. It does not require any statistical knowledge to interpret them.
- Exploratory data analysis: Decision trees can enable analysts to identify significant variables and important relations between two or more variables, helping to surface the signal contained by many input variables.
- Minimal data cleaning: Because decision trees are resilient to outliers and missing values, they require less data cleaning than some other algorithms.
- Any data type: Decision trees can make classifications based on both numerical and categorical variables.
- Non-parametric: A decision tree is a non-parametric algorithm, as opposed to neural networks, which process input data transformed into a tensor, via tensor multiplication using large number of coefficients, known as parameters.
Disadvantages
- Overfitting: Over fitting is a common flaw of decision trees. Setting constraints on model parameters and making the model simpler through pruning are two ways to regularize a decision tree.
- Predicting continuous variables: While decision trees can ingest continuous numerical input, they are not a practical way to predict such values, since decision-tree predictions must be separated into discrete categories, which results in a loss of information when applying the model to continuous values.
- Heavy feature engineering: The flip side of a decision tree’s explanatory power is that it requires heavy feature engineering. When dealing with unstructured data or data with latent factors, this makes decision trees sub-optimal. Neural networks are clearly superior in this regard.
Random Forest
Random forests are made of many decision trees. They are ensembles of decision trees, each decision tree created by using a subset of the attributes used to classify a given population (they are sub-trees, see above). Those decision trees vote on how to classify a given instance of input data, and the random forest bootstraps those votes to choose the best prediction. This is done to prevent overfitting, a common flaw of decision trees.
A random forest is a supervised classification algorithm. It creates a forest (many decision trees) and orders their nodes and splits randomly. The more trees in the forest, the better the results it can produce.
If you input a training dataset with targets and features into the decision tree, it will formulate some set of rules that can be used to perform predictions.
Example: You want to predict whether a visitor to your e-commerce Web site will enjoy a mystery novel. First, collect information about past books they’ve read and liked. Metadata about the novels will be the input; e.g. number of pages, author, publication date, which series it’s part of if any. The decision tree contains rules that apply to those features; for example, some readers like very long books and some don’t. Inputting metadata about new novels will result in a prediction regarding whether or not the Web site visitor in question would like that novel. Arranging the nodes and defining the rules relies on information gain and Gini-index calculations. With random forests, finding the root node and splitting the feature nodes is done randomly.