Overview of Supervised, Unsupervised, and Reinforcement Learning
Requirements
Interest in machine learning
Description
Course Outcome:
Learners completing this course will be able to give definitions and explain the types of problems that can be solved by the 3 broad areas of machine learning: Supervised, Unsupervised, and Reinforcement Learning.
Course Topics and Approach:
This course gives a gentle introduction to the 3 broad areas of machine learning: Supervised, Unsupervised, and Reinforcement Learning. The goal is to explain the key ideas using examples with many plots and animations and little math, so that the material can be accessed by a wide range of learners. The lectures are supplemented by Python demos, which show machine learning in action. Learners are encouraged to experiment with the course demo codes. Additionally, information about machine learning resources is provided, including sources of data and publicly available software packages.
Course Audience:
This course has been designed for ALL LEARNERS!!!
Course does not go into detail into the underlying math, so no specific math background is required
No previous experience with machine learning is required
No previous experience with Python (or programming in general) is required to be able to experiment with the course demo codes
Teaching Style and Resources:
Course includes many examples with plots and animations used to help students get a better understanding of the material
All resources, including course codes, Powerpoint presentations, info on additional resources, can be downloaded from the course Github site
Python Demos:
There are several options for running the Python demos:
Run online using Google Colab (With this option, demo codes can be run completely online, so no downloads are required. A Google account is required.)
Run on local machine using the Anaconda platform (This is probably best approach for those who would like to run codes locally, but don’t have python on their local machine. Demo video shows where to get free community version of Anaconda platform and how to run the codes.)
Run on local machine using python (This approach may be most suitable for those who already have python on their machines)
2021.09.28 Update
Section 5: update course codes, Powerpoint presentations, and videos so that codes are compatible with more recent versions of the Anaconda platform and plotting package
Who this course is for:
People curious about machine learning and data science
In this blog on what is Machine Learning, you will learn about Machine Learning, the differences between AI and Machine Learning, why Machine Learning matters, applications of Machine Learning, Machine Learning languages, and some of the most common open-source Machine Learning tools.
The following topics will be covered in this blog:
Machine Learning definition
Why Machine Learning?
How does Machine Learning work?
What are the different types of Machine Learning?
Machine Learning Algorithms and Processes
ML Programming Languages
Machine Learning Tools
Difference between AI and Machine Learning
Applications of Machine Learning
Advantages and Disadvantages of Machine learning
Scope of Machine Learning
Prerequisites for Machine Learning
Conclusion
Machine Learning Definition
Even though there are various Machine Learning examples or applications that we use in our daily lives, people still get confused about Machine Learning, so let’s start by looking at the Machine Learning definition.
In layman’s terms, Machine Learning can be defined as the ability of a machine to learn something without having to be programmed for that specific thing. It is the field of study where computers use a massive set of data and apply algorithms for ‘training’ themselves and making predictions. Training in Machine Learning entails feeding a lot of data into the algorithm and allowing the machine itself to learn more about the processed information.
Answering whether the animal in a photo is a cat or a dog, spotting obstacles in front of a self-driving car, spam mail detection, and speech recognition of a YouTube video to generate captions are just a few examples out of a plethora of predictive Machine Learning models.
Another Machine Learning definition can be given as Machine learning is a subset of Artificial Intelligence that comprises algorithms programmed to gather information without explicit instructions at each step. It has experienced the colossal success of late.
We have often seen confusion around the use of the words Artificial Intelligence and Machine Learning. They are very much related and often seem to be used interchangeably, yet both are different. Confused? Let us elaborate on AI vs. ML vs. DL.
Go through these Top 40 Machine Learning Interview Questions and Answers to crack your interviews.
Why Machine Learning?
Let us start with an instance where a machine surpasses in a strategic game by self-learning. In 2016, the strongest Go player (Go is an abstract strategy board game invented in China more than 2,500 years ago) in the world, Lee Sedol, sat down for a match against Google DeepMind’s Machine Learning program, AlphaGo. AlphaGo won the 5-day long match.
One thing to take away from this instance is not that a machine can learn to conquer Go, but the fact that the ways in which these revolutionary advances in Machine Learning—machines’ ability to mimic a human brain—can be applied are beyond imagination.
Machine Learning has paved its way into various business industries across the world. It is all because of the incredible ability of Machine Learning to drive organizational growth, automate manual and mundane jobs, enrich the customer experience, and meet business goals.
According to BCC Research, the global market for Machine Learning is expected to grow from $17.1 billion in 2021 to $90.1 billion by 2026 with a compound annual growth rate (CAGR) of 39.4% for the period of 2021-2026.
Moreover, Machine Learning Engineer is the fourth-fastest growing job as per LinkedIn.
Both Artificial Intelligence and Machine Learning are going to be imperative to the forthcoming society. Hence, this is the right time to learn Machine Learning.
Enroll for the Machine Learning Training in Noida now and land in your dream job!
How does Machine Learning work?
Machine learning works on different types of algorithms and techniques. These algorithms are created with the help of various ML programming languages. Usually, a training dataset is fed to the algorithm to create a model.
Now, whenever input is provided to the ML algorithm, it returns a result value/predictions based on the model. Now, if the prediction is accurate, it is accepted and the algorithm is deployed. But if the prediction is not accurate, the algorithm is trained repeatedly with a training dataset to arrive at an accurate prediction/result.
Consider this example:
If you wish to predict the weather patterns in a particular area, you can feed the past weather trends and patterns to the model through the algorithm. This will be the training dataset for the algorithm. Now if the model understands perfectly, the result will be accurate.
What are the different types of Machine Learning?
Machine Learning algorithms run on various programming languages and techniques. However, these algorithms are trained using various methods, out of which three main types of Machine learning are:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
Supervised Learning
Supervised Learning is the most basic type of Machine Learning, where labeled data is used for training the machine learning algorithms. A dataset is given to the ML model for understanding and solving the problem. This dataset is a smaller version of a larger dataset and conveys the basic idea of the problem to the machine learning algorithm.
Unsupervised Learning
Unsupervised Learning is the type of Machine Learning where no human intervention is required to make the data machine-readable and train the algorithm. Also, contrary to supervised learning, unlabeled data is used in the case of unsupervised learning.
Since there is no human intervention and unlabeled data is used, the algorithm can work on a larger data set. Unlike supervised learning, unsupervised learning does not require labels to establish relationships between two data points.
Reinforcement Learning
Reinforcement Learning is the type of Machine Learning where the algorithm works upon itself and learns from new situations by using a trial-and-error method. Whether the output is favorable or not is decided based on the output result already fed to each iteration.
Machine Learning Algorithms and Processes
Machine Learning algorithms are sets of instructions that the model follows to return an acceptable result or prediction. Basically, the algorithms analyze the data fed to them and establish a relationship between the variables and data points to return the result.
Over time, these algorithms learn to become more efficient and optimize the processes when new data is fed into the model. There are three main categories in which these algorithms are divided- Supervised Learning, Unsupervised Learning, and Reinforcement Learning. These have already been discussed in the above sections.
ML Programming Languages
Now, when it comes to the implementation of Machine Learning, it is important to have a knowledge of programming languages that a computer can understand. The most common programming languages used in Machine Learning are given below.
According to the GitHub 2021report, the below-given table ranks as the most popular programming language for Machine Learning in 2021:
Rank
Programming Language
1
JavaScript
2
Python
3
Java
4
Go
5
TypeScript
6
C++
7
Ruby
8
PHP
9
C#
10
C
Become a Master of Machine Learning by going through this online Machine Learning course in Singapore.
Machine Learning Tools
Machine Learning open-source tools are nothing but libraries used in programming languages like Python, R, C++, Java, Scala, Javascript, etc. to make the most out of Machine Learning algorithms.
Keras: Keras is an open-source neural network library written in Python. It is capable of running on top of TensorFlow.
PyTorch: PyTorch is an open-source Machine Learning library for Python, based on Torch, used for applications such as Natural Language Processing.
TensorFlow: Created by the Google Brain team, TensorFlow is an open-source library for numerical computation and large-scale Machine Learning.
Scikit-learn: Scikit-learn, also known as Sklearn, is a Python library that has become very popular for solving Science, Math, and Statistics problems–because of its easy-to-adopt nature and its wide range of applications in the field of Machine Learning.
Shogun: Shogun can be used with Java, Python, R, Ruby, and MATLAB. It offers a wide range of efficient and unified Machine Learning methods.
Spark MLlib: Spark MLlib is the Machine Learning library used in Apache Spark and Apache Hadoop. Although Java is the primary language for working in MLlib, Python users are also allowed to connect to MLlib through the NumPy library.
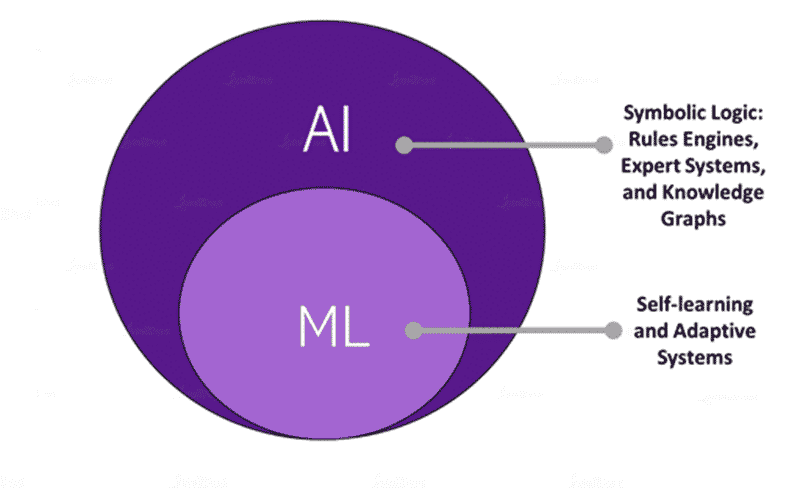
Difference between AI and Machine Learning
There seems to be a lack of a bright-line distinction between what Machine Learning is and what it is not. Moreover, everyone is using the labels ‘AI’ and ‘ML’ where they do not belong and that includes using the terms interchangeably.
Artificial Intelligence is not a machine or a system. It is a concept that is implemented on machines. When we talk about Artificial Intelligence, it could be making a machine move or it could be making a machine detect spam mail. For all these different implementations of AI, there are different sub-fields, and one such sub-field is Machine Learning. There are applications of Artificial Intelligence that are not related to Machine Learning. For example, symbolic logic: rules engines, expert systems, and knowledge graphs.
Machine Learning uses large sets of data and hours of training to make predictions on probable outcomes. But when Machine Learning ‘comes to life’ and moves beyond simple programming, and reflects and interacts with people even at the most basic level, AI comes into play.
AI is a step beyond Machine Learning, yet it needs ML to reflect and optimize decisions. AI uses what it has gained from ML to simulate intelligence, the same way a human is constantly observing their surrounding environment and making intelligent decisions. AI leads to intelligence or wisdom and its end goal is to simulate natural intelligence to solve complex problems of the world.
Now that we have gathered an idea of What Machine Learning is and the difference between AI and Machine Learning, let us move ahead and see why Machine Learning is important.
ARTIFICIAL INTELLIGENCE
MACHINE LEARNING
AI stands for Artificial intelligence, where intelligence is defined as acquisition of knowledge intelligence is defined as an ability to acquire and apply knowledge.
ML stands for Machine Learning which is defined as the acquisition of knowledge or skill
The aim is to increase the chance of success and not accuracy.
The aim is to increase accuracy, but it does not care about success
It work as a computer program that does smart work
Here, machine takes data and learn from data.
The goal is to simulate natural intelligence to solve complex problems.
The goal is to learn from data on certain tasks to maximize the performance on that task.
AI is decision making.
ML allows systems to learn new things from data.
It is developing a system which mimics humans to solve problems.
It involves creating self learning algorithms.
AI will go for finding the optimal solution.
ML will go for a solution whether it is optimal or not.
AI leads to intelligence or wisdom.
ML leads to knowledge.
AI is a broader family consisting of ML and DL as its components.
ML is a subset of AI.
Enroll in our AI Certification and be an AI Expert.
Applications of Machine Learning
As mentioned earlier, the human race has already stepped into the future world with machines. The pervasive growth of Machine Learning can be seen in almost every other field. Let me list out a few real-life applications of Machine Learning.
Fraud Detection
Fraud detection refers to the act of illicitly drawing out money from people by deceiving them. Machine Learning can go a long way in decreasing instances of fraud detection and save many individuals and organizations from losing their money.
For example- by feeding an algorithm into the model, spam emails can be easily detected. Also, the right machine learning models can easily detect fraudulent transactions or suspicious online banking activities.
In fact, fraud detection ML algorithms are nowadays being considered as much more effective than humans.
Moley’s Robotic Kitchen
Machine Learning can do wonders in the food and beverage industry too. Consider this example- The kitchen comes up with a pair of robotic arms, an oven, a shelf for food and utensils, and a touch screen.
Moley’s kitchen is a gift of Machine Learning: it will learn n number of recipes for you, will cook with remarkable precision, and will also clean up by itself. It sounds great, doesn’t it?
Netflix Movie Recommendation
The algorithm that Netflix uses to recommend movies is nothing but Machine Learning. More than 80 percent of the shows and movies are discovered through the recommendation section.
To recommend movies, it goes through threads within the content rather than relying on the genre board in order to make predictions. According to Todd Yellin, VP of Product at Netflix, the Machine Learning algorithm is one of the pillars of Netflix.
Interested in learning Machine Learning? Enroll in our Machine Learning Certification course!
Alexa
The latest innovations of Amazon have the brain and the voice of Alexa. Now, for those who are not aware of Alexa, it is the voice-controlled Amazon ‘personal assistant’ in Amazon Echo devices.
Alexa can play music, provide information, deliver news and sports scores, tell you the weather, control your smart home, and even allow prime members to order products that they’ve ordered before. Alexa is smart and gets updated through the Cloud and learns all the time, by itself.
But, does Alexa understand commands? How does it learn by itself? Everything is a gift of the Machine Learning algorithm.
Amazon Product Recommendation
We are sure that you might have noticed while buying something online from Amazon, it recommends a set of items that are bought together or items that are often bought together, along with your ordered item.
Have you ever wondered how Amazon makes those recommendations? Well again, Amazon uses the Machine Learning algorithm to do so.
Google Maps
How does Google Maps predict traffic on a particular route? How does it tell you the estimated time for a certain trip?
Google Maps anonymously sends real-time data from the Google Maps users on the same route back to Google. Google uses the Machine Learning algorithm on this data to accurately predict the traffic on that route.
These are some of the Machine Learning examples that we see or use in our daily lives. Let us go ahead and discuss how we can implement a Machine Learning algorithm.
Come to Intellipaat’s Machine Learning Community if you have more queries on Machine Learning!
Advantages and Disadvantages of Machine Learning
Easily identifies trends and patterns
Machine Learning can review large volumes of data and discover specific trends and patterns that would not be apparent to humans. For instance, for e-commerce websites like Amazon and Flipkart, it serves to understand the browsing behaviors and purchase histories of its users to help cater to the right products, deals, and reminders relevant to them. It uses the results to reveal relevant advertisements to them.
Continuous Improvement
We are continuously generating new data and when we provide this data to the Machine Learning model which helps it to upgrade with time and increase its performance and accuracy. We can say it is like gaining experience as they keep improving in accuracy and efficiency. This lets them make better decisions.
Handling multidimensional and multi-variety data
Machine Learning algorithms are good at handling data that are multidimensional and multi-variety, and they can do this in dynamic or uncertain environments.
Wide Applications
You could be an e-tailer or a healthcare provider and make Machine Learning work for you. Where it does apply, it holds the capability to help deliver a much more personal experience to customers while also targeting the right customers.
Disadvantages of Machine Learning
Data Acquisition
Machine Learning requires a massive amount of data sets to train on, and these should be inclusive/unbiased, and of good quality. There can also be times where we must wait for new data to be generated.
Time and Resources
Machine Learning needs enough time to let the algorithms learn and develop enough to fulfill their purpose with a considerable amount of accuracy and relevancy. It also needs massive resources to function. This can mean additional requirements of computer power for you.
Interpretation of Results
Another major challenge is the ability to accurately interpret results generated by the algorithms. You must also carefully choose the algorithms for your purpose. Sometimes, based on some analysis you might select an algorithm but it is not necessary that this model is best for the problem.
High error-susceptibility
Machine Learning is autonomous but highly susceptible to errors. Suppose you train an algorithm with data sets small enough to not be inclusive. You end up with biased predictions coming from a biased training set. This leads to irrelevant advertisements being displayed to customers. In the case of Machine Learning, such blunders can set off a chain of errors that can go undetected for long periods of time. And when they do get noticed, it takes quite some time to recognize the source of the issue, and even longer to correct it.
Scope of Machine Learning
The scope of Machine Learning covers varied industries and sectors. It is expanding across all fields such as Banking and Finance, Information Technology, Media & Entertainment, Gaming, and the Automotive industry. As the Machine Learning scope is very high, there are some areas where researchers are working toward revolutionizing the world for the future.
The scope of Machine Learning in India, as well as in other parts of the world, is high in comparison to other career fields when it comes to job opportunities.
According to Gartner, there will be 2.3 million jobs in the field of Artificial Intelligence and Machine Learning by 2023. Also, the salary of a Machine Learning Engineer is much higher than the salaries offered to other job profiles. According to Forbes, the average salary of an ML Engineer in the United States is US$99,007.
Go through our AI Course in Chennai to master AI & ML skills and land in a high paying job!
Prerequisites for Machine Learning
Prerequisites to building a career in Machine Learning include knowledge of the following:
Statistics– Knowledge of statistical tools and techniques is a basic requirement to understand Machine Learning. You should be well trained in using various types of statistics such as descriptive statistics and inferential statistics to extract useful information from raw data.
Probability– Machine Learning is built on probability. The very possibility of the occurrence of an event is known as probability.
Programming languages– It is very important that an ML engineer knows which machine-readable programming language to be used.
Calculus– The working of Machine Learning algorithms depends on how Calculus and related concepts such as Integration and Differentiation are used. Hence, it is very important that you understand and are well acquainted with Calculus.
Linear Algebra– Vectors, Matrices, and Linear Transformations form an important part of Linear Algebra and play an important role in dataset operations.
Conclusion
This module focuses on the meaning of Machine Learning, common Machine Learning definitions, the difference between AI and Machine Learning, why Machine Learning matters, prerequisites, and types of machine learning. We have also highlighted different Machine Learning tools, as well as discussed some of the applications of Machine Learning. If you want to have a deeper understanding of Machine Learning, refer to the Machine Learning tutorial. See you there!
Daniel Faggella is Head of Research at Emerj. Called upon by the United Nations, World Bank, INTERPOL, and leading enterprises, Daniel is a globally sought-after expert on the competitive strategy implications of AI for business and government leaders.
Typing “what is machine learning?” into a Google search opens up a pandora’s box of forums, academic research, and false information – and the purpose of this article is to simplify the definition and understanding of machine learning thanks to the direct help from our panel of machine learning researchers.
At Emerj, the AI Research and Advisory Company, many of our enterprise clients feel as though they should be investing in machine learning projects, but they don’t have a strong grasp of what it is. We often direct them to this resource to get them started with the fundamentals of machine learning in business.
In addition to an informed, working definition of machine learning (ML), we detail the challenges and limitations of getting machines to ‘think,’ some of the issues being tackled today in deep learning (the frontier of machine learning), and key takeaways for developing machine learning applications for business use-cases.
This article will be broken up into the following sections:
What is machine learning?
How we arrived at our definition (IE: the perspective of expert researchers)
Machine learning basic concepts
Visual representation of ML models
How we get machines to learn
An overview of the challenges and limitations of ML
Brief introduction to deep learning
Works cited
Related ML interviews on Emerj
We put together this resource to help with whatever your area of curiosity about machine learning – so scroll along to your section of interest, or feel free to read the article in order, starting with our machine learning definition below:
What is Machine Learning?
* “Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
The above definition encapsulates the ideal objective or ultimate aim of machine learning, as expressed by many researchers in the field. The purpose of this article is to provide a business-minded reader with expert perspective on how machine learning is defined, and how it works. Machine learning and artificial intelligence share the same definition in the minds of many however, there are some distinct differences readers should recognize as well. References and related researcher interviews are included at the end of this article for further digging.
* How We Arrived at Our Definition:
(Our aggregate machine learning definition can be found at the beginning of this article)
As with any concept, machine learning may have a slightly different definition, depending on whom you ask. We combed the Internet to find five practical definitions from reputable sources:
“Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world.” – Nvidia
“Machine learning is the science of getting computers to act without being explicitly programmed.” – Stanford
“Machine learning is based on algorithms that can learn from data without relying on rules-based programming.”- McKinsey & Co.
“Machine learning algorithms can figure out how to perform important tasks by generalizing from examples.” – University of Washington
“The field of Machine Learning seeks to answer the question “How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?” – Carnegie Mellon University
We sent these definitions to experts whom we’ve interviewed and/or included in one of our past research consensuses, and asked them to respond with their favorite definition or to provide their own. Our introductory definition is meant to reflect the varied responses. Below are some of their responses:
Dr. Yoshua Bengio, Université de Montréal:
ML should not be defined by negatives (thus ruling 2 and 3). Here is my definition:
Machine learning research is part of research on artificial intelligence, seeking to provide knowledge to computers through data, observations and interacting with the world. That acquired knowledge allows computers to correctly generalize to new settings.
Dr. Danko Nikolic, CSC and Max-Planck Institute:
(edit of number 2 above): “Machine learning is the science of getting computers to act without being explicitly programmed, but instead letting them learn a few tricks on their own.”
Dr. Roman Yampolskiy, University of Louisville:
Machine Learning is the science of getting computers to learn as well as humans do or better.
Dr. Emily Fox, University of Washington:
My favorite definition is #5.
Machine Learning Basic Concepts
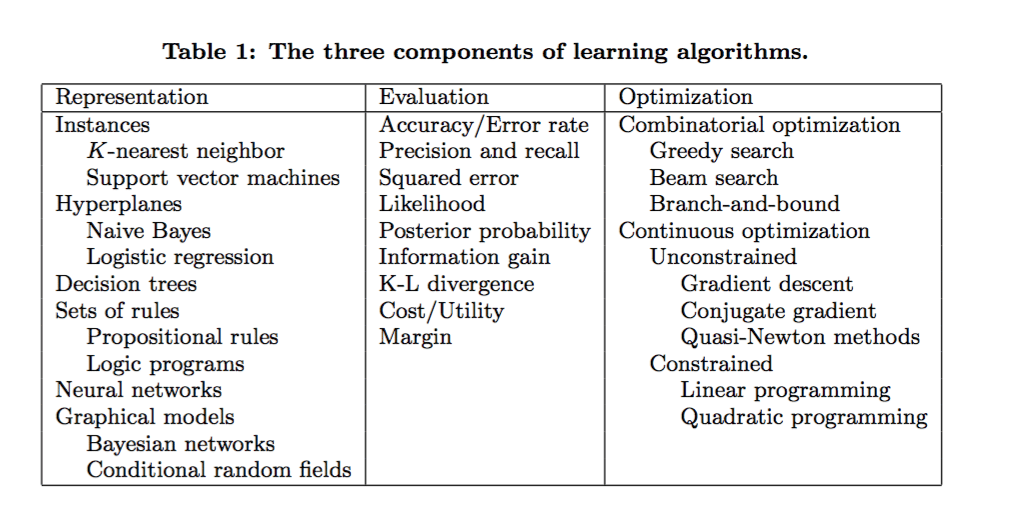
There are many different types of machine learning algorithms, with hundreds published each day, and they’re typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). Regardless of learning style or function, all combinations of machine learning algorithms consist of the following:
Representation (a set of classifiers or the language that a computer understands)
Evaluation (aka objective/scoring function)
Optimization (search method; often the highest-scoring classifier, for example; there are both off-the-shelf and custom optimization methods used)
Image credit: Dr. Pedro Domingo, University of Washington
The fundamental goal of machine learning algorithms is to generalize beyond the training samples i.e. successfully interpret data that it has never ‘seen’ before.
Visual Representations of Machine Learning Models
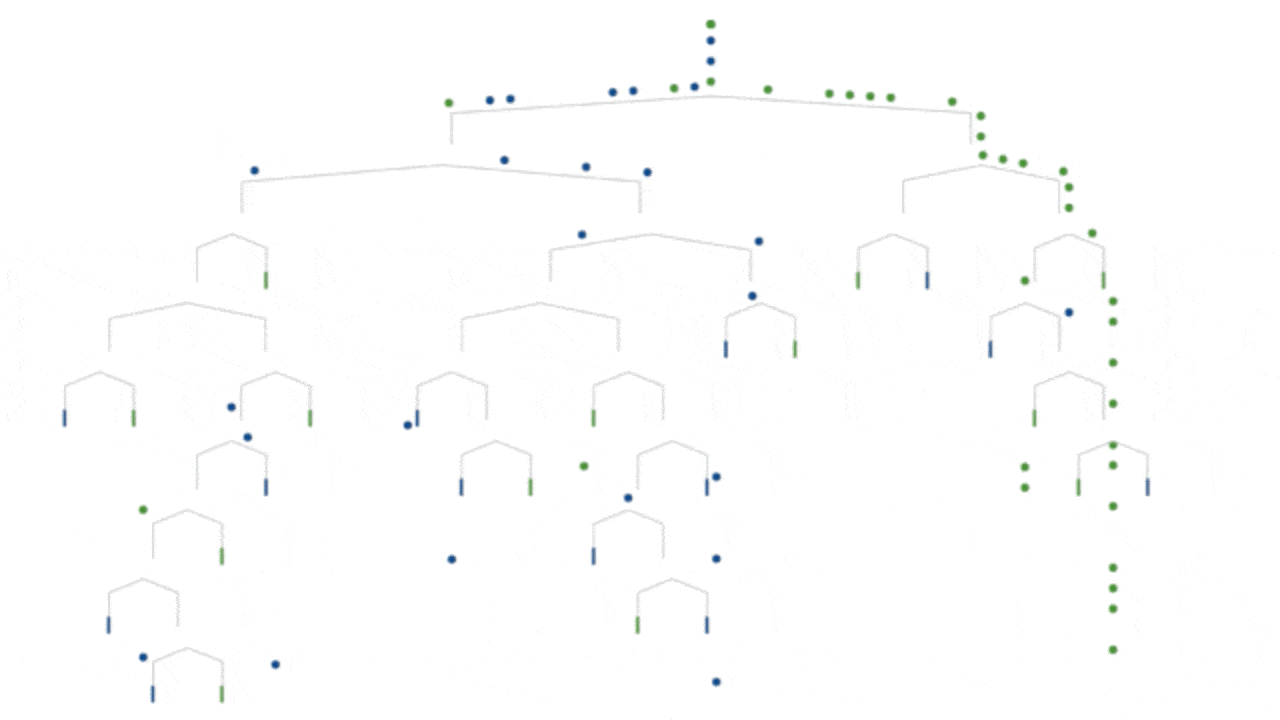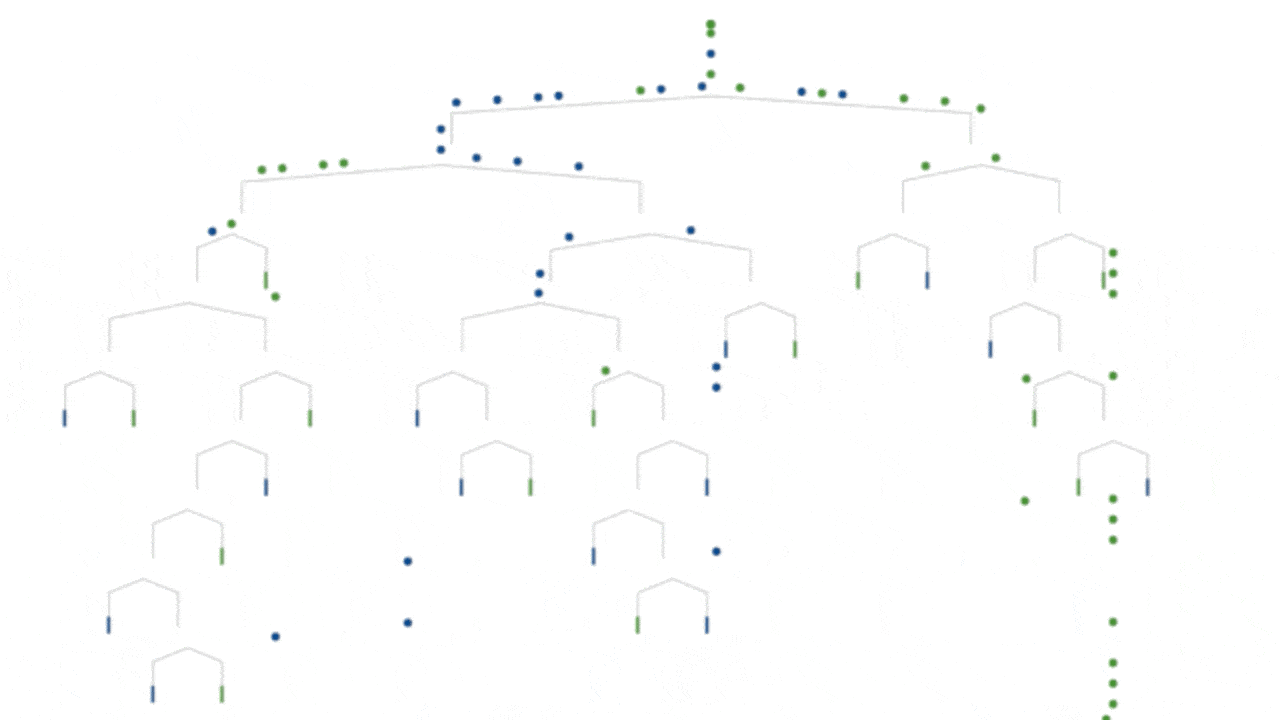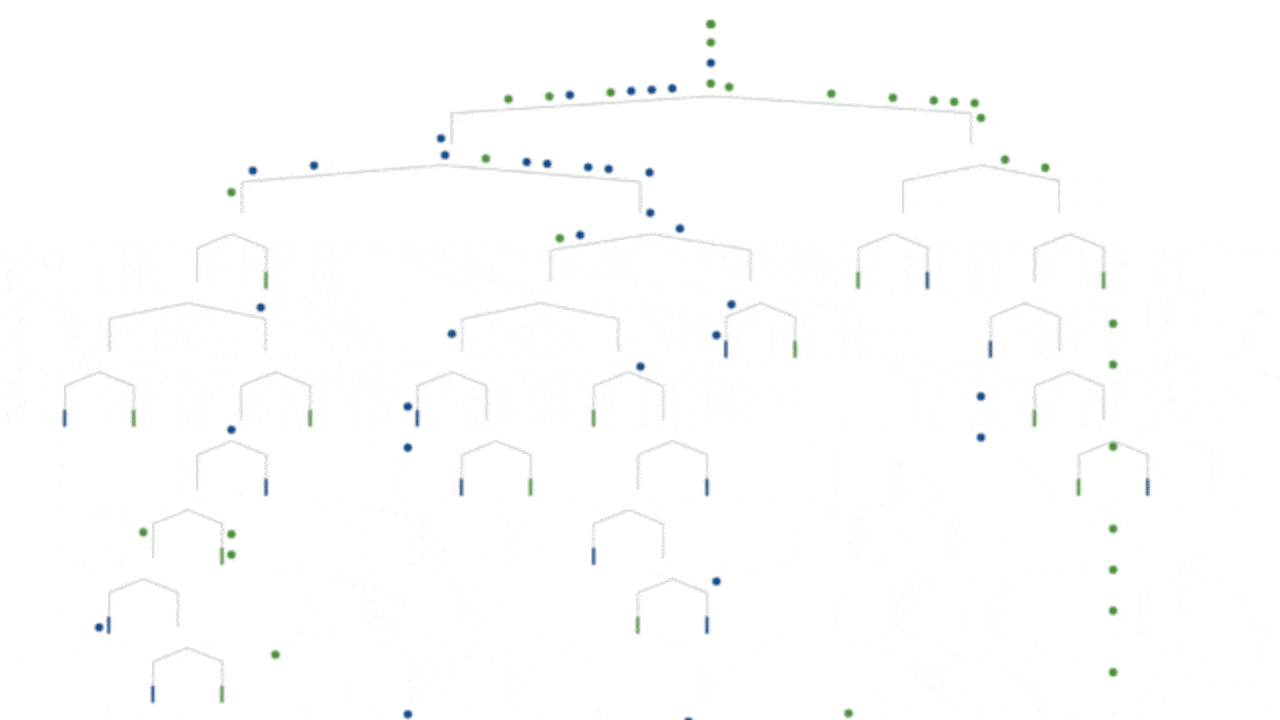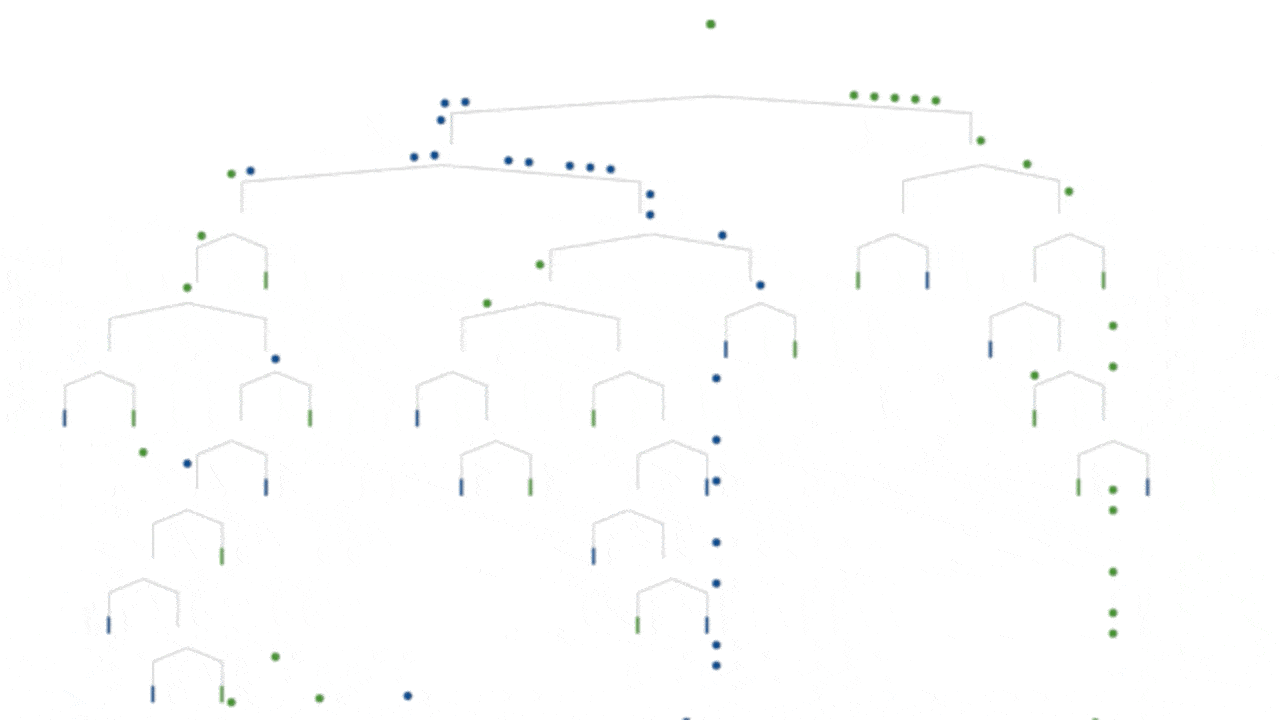
Concepts and bullet points can only take one so far in understanding. When people ask “What is machine learning?”, they often want to see what it is and what it does. Below are some visual representations of machine learning models, with accompanying links for further information. Even more resources can be found at the bottom of this article.
Decision tree model
Gaussian mixture model
Dropout neural network
Merging chrominance and luminance using Convolutional Neural Networks
How We Get Machines to Learn
There are different approaches to getting machines to learn, from using basic decision trees to clustering to layers of artificial neural networks (the latter of which has given way to deep learning), depending on what task you’re trying to accomplish and the type and amount of data that you have available. This dynamic sees itself played out in applications as varying as medical diagnostics or self-driving cars.
While emphasis is often placed on choosing the best learning algorithm, researchers have found that some of the most interesting questions arise out of none of the available machine learning algorithms performing to par. Most of the time this is a problem with training data, but this also occurs when working with machine learning in new domains.
Research done when working on real applications often drives progress in the field, and reasons are twofold: 1. Tendency to discover boundaries and limitations of existing methods 2. Researchers and developers working with domain experts and leveraging time and expertise to improve system performance.
Sometimes this also occurs by “accident.” We might consider model ensembles, or combinations of many learning algorithms to improve accuracy, to be one example. Teams competing for the 2009 Netflix Price found that they got their best results when combining their learners with other team’s learners, resulting in an improved recommendation algorithm (read Netflix’s blog for more on why they didn’t end up using this ensemble).
One important point (based on interviews and conversations with experts in the field), in terms of application within business and elsewhere, is that machine learning is not just, or even about, automation, an often misunderstood concept. If you think this way, you’re bound to miss the valuable insights that machines can provide and the resulting opportunities (rethinking an entire business model, for example, as has been in industries like manufacturing and agriculture).
Machines that learn are useful to humans because, with all of their processing power, they’re able to more quickly highlight or find patterns in big (or other) data that would have otherwise been missed by human beings. Machine learning is a tool that can be used to enhance humans’ abilities to solve problems and make informed inferences on a wide range of problems, from helping diagnose diseases to coming up with solutions for global climate change.
Challenges and Limitations
“Machine learning can’t get something from nothing…what it does is get more from less.” – Dr. Pedro Domingo, University of Washington
The two biggest, historical (and ongoing) problems in machine learning have involved overfitting (in which the model exhibits bias towards the training data and does not generalize to new data, and/or variance i.e. learns random things when trained on new data) and dimensionality (algorithms with more features work in higher/multiple dimensions, making understanding the data more difficult). Having access to a large enough data set has in some cases also been a primary problem.
One of the most common mistakes among machine learning beginners is testing training data successfully and having the illusion of success; Domingo (and others) emphasize the importance of keeping some of the data set separate when testing models, and only using that reserved data to test a chosen model, followed by learning on the whole data set.
When a learning algorithm (i.e. learner) is not working, often the quicker path to success is to feed the machine more data, the availability of which is by now well-known as a primary driver of progress in machine and deep learning algorithms in recent years; however, this can lead to issues with scalability, in which we have more data but time to learn that data remains an issue.
In terms of purpose, machine learning is not an end or a solution in and of itself. Furthermore, attempting to use it as a blanket solution i.e. “BLANK” is not a useful exercise; instead, coming to the table with a problem or objective is often best driven by a more specific question – “BLANK”.
Deep Learning and Modern Developments in Neural Networks
Deep learning involves the study and design of machine algorithms for learning good representation of data at multiple levels of abstraction (ways of arranging computer systems). Recent publicity of deep learning through DeepMind, Facebook, and other institutions has highlighted it as the “next frontier” of machine learning.
The International Conference on Machine Learning (ICML) is widely regarded as one of the most important in the world. This year’s took place in June in New York City, and it brought together researchers from all over the world who are working on addressing the current challenges in deep learning:
Unsupervised learning in small data sets
Simulation-based learning and transferability to the real world
Deep-learning systems have made great gains over the past decade in domains like bject detection and recognition, text-to-speech, information retrieval and others. Research is now focused on developing data-efficient machine learning i.e. deep learning systems that can learn more efficiently, with the same performance in less time and with less data, in cutting-edge domains like personalized healthcare, robot reinforcement learning, sentiment analysis, and others.
Key Takeaways in Applying Machine Learning
Below is a selection of best-practices and concepts of applying machine learning that we’ve collated from our interviews for out podcast series, and from select sources cited at the end of this article. We hope that some of these principles will clarify how ML is used, and how to avoid some of the common pitfalls that companies and researchers might be vulnerable to in starting off on an ML-related project.
Arguably the most important factor in successful machine learning projects is the features used to describe the data (which are domain-specific), and having adequate data to train your models in the first place
Most of the time when algorithms don’t perform well, it’s due a to a problem with the training data (i.e. insufficient amounts/skewed data; noisy data; or insufficient features describing the data for making decisions
“Simplicity does not imply accuracy” – there is (according to Domingo) no given connection between number of parameters of a model and tendency to overfit
Obtaining experimental data (as opposed to observational data, over which we have no control) should be done if possible (for example, data gleaned from sending different variations of an email to a random audience sampling)
Whether or not we label data causal or correlative, the more important point is to predict the effects of our actions
Always set aside a portion of your training data set for cross validation; you want your chosen classifier or learning algorithm to perform well on fresh data
Emerj For Enterprise Leaders
Emerj helps businesses get started with artificial intelligence and machine learning. Using our AI Opportunity Landscapes, clients can discover the largest opportunities for automation and AI at their companies and pick the highest ROI first AI projects. Instead of wasting money on pilot projects that are destined to fail, Emerj helps clients do business with the right AI vendors for them and increase their AI project success rate.
One of the best ways to learn about artificial intelligence concepts is to learn from the research and applications of the smartest minds in the field. Below is a brief list of some of our interviews with machine learning researchers, many of which may be of interest for readers who want to explore these topics further:
The Science of Machine Learning with Dr. Yoshua Bengio (one of the world’s foremost ML experts)
UPENN’s Dr. Lyle Ungar on Using Machine Learning to See Patterns and Meaning on Social Media
Silicon Valley AI Consultant Lorien Pratt on the Business Use Cases of Machine Learning
Most of us would find it hard to go a full day without using at least one app or web service driven by machine learning. But what is machine learning (ML), exactly?
Though the term machine learning has become increasingly common, many people still don’t know exactly what it means and how it is applied, nor do they understand the role of machine learning algorithms and datasets in data science. Here, we will examine the question “what is ML?”
We will provide insight into how machine learning is used by data scientists and others, how it was developed, and what lies ahead as it continues to evolve.
Definition of Machine Learning
The basic concept of machine learning in data science involves using statistical learning and optimization methods that let computers analyze datasets and identify patterns (view a visual of machine learning via R2D3External link:open_in_new). Machine learning techniques leverage data mining to identify historic trends and inform future models.
The typical supervised machine learning algorithm consists of roughly three components:
A decision process: A recipe of calculations or other steps that takes in the data and “guesses” what kind of pattern your algorithm is looking to find.
An error function: A method of measuring how good the guess was by comparing it to known examples (when they are available). Did the decision process get it right? If not, how do you quantify “how bad” the miss was?
An updating or optimization process: A method in which the algorithm looks at the miss and then updates how the decision process comes to the final decision, so next time the miss won’t be as great.
For example, if you’re building a movie recommendation system, you can provide information about yourself and your watch history as input. The algorithm will take that input and learn how to return an accurate output: movies you will enjoy. Some inputs could be movies you watched and rated highly, the percentage of movies you’ve seen that are comedies, or how many movies feature a particular actor. The algorithm’s job is to find these parameters and assign weights to them. If the algorithm gets it right, the weights it used stay the same. If it gets a movie wrong, the weights that led to the wrong decision get turned down so it doesn’t make that kind of mistake again.
Since a machine learning algorithm updates autonomously, the analytical accuracy improves with each run as it teaches itself from the data it analyzes. This iterative nature of learning is both unique and valuable because it occurs without human intervention — empowering the algorithm to uncover hidden insights without being specifically programmed to do so.
Types of Machine Learning
There are many types of machine learning models defined by the presence or absence of human influence on raw data — whether a reward is offered, specific feedback is given, or labels are used.
According to Nvidia.com, there are different machine learning models such as:External link:open_in_new
Supervised learning: The dataset being used has been pre-labeled and classified by users to allow the algorithm to see how accurate its performance is.
Unsupervised learning: The raw dataset being used is unlabeled and an algorithm identifies patterns and relationships within the data without help from users.
Semi-supervised learning: The dataset contains structured and unstructured data, which guides the algorithm on its way to making independent conclusions. The combination of the two data types in one training dataset allows machine learning algorithms to learn to label unlabeled data.
Reinforcement learning: The dataset uses a “rewards/punishments” system, offering feedback to the algorithm to learn from its own experiences by trial and error.
Finally, there’s the concept of deep learning, which is a newer area of machine learning that automatically learns from datasets without introducing human rules or knowledge. This requires massive amounts of raw data for processing — and the more data that is received, the more the predictive model improves.
Commonly Used Machine Learning Algorithms
The purpose of machine learning is to use machine learning algorithms to analyze data. By leveraging machine learning, a developer can improve the efficiency of a task involving large quantities of data without the need for manual human input. Around the world, strong machine learning algorithms can be used to improve the productivity of professionals working in data science, computer science, and many other fields.
There are a number of machine learning algorithms that are commonly used by modern technology companies. Each of these machine learning algorithms can have numerous applications in a variety of educational and business settings.
Read on to learn about many different machine learning algorithms, as well as how they are applicable to the broader field of machine learning.
Linear Regression
Linear regression is an algorithm used to analyze the relationship between independent input variables and at least one target variable. This kind of regression is used to predict continuous outcomes — variables that can take any numerical outcome. For example, given data on the neighborhood and property, can a model predict the sale value of a home? Linear relationships occur when the data relationship being observed tends to follow a straight line overall — and as such, this model can be used to observe whether a data point is increasing, decreasing, or remaining the same relative to some independent variable, such as time elapsed or position.
Machine learning models can be employed to analyze data in order to observe and map linear regressions. Independent variables and target variables can be input into a linear regression machine learning model, and the model will then map the coefficients of the best fit line to the data. In other words, the linear regression models attempt to map a straight line, or a linear relationship, through the dataset.
Logistic Regression
Logistic regression is a supervised learning algorithm that is used for classification problems. Instead of continuous output like in linear regression, a logistic model predicts the probability of a binary event occurring. For example, given an email, can a model predict whether the contents are spam or not?
Machine learning algorithms can use logistic regression models to determine categorical outcomes. When given a dataset, the logistic regression model can check any weights and biases and then use the given dependent categorical target variables to understand how to correctly categorize that dataset.
Neural Networks
Neural networks are artificial intelligence algorithms that attempt to replicate the way the human brain processes information to understand and intelligently classify data. These neural network learning algorithms are used to recognize patterns in data and speech, translate languages, make financial predictions, and much more through thousands, or sometimes millions, of interconnected processing nodes. Data is “fed-forward” through layers that process and assign weights, before being sent to the next layer of nodes, and so on.
Crucially, neural network algorithms are designed to quickly learn from input training data in order to improve the proficiency and efficiency of the network’s algorithms. As such, neural networks serve as key examples of the power and potential of machine learning models.
Decision Trees
Decision trees are data structures with nodes that are used to test against some input data. The input data is tested against the leaf nodes down the tree to attempt to produce the correct, desired output. They are easy to visually understand due to their tree-like structure and can be designed to categorize data based on some categorization schema.
Decision trees are one method of supervised learning, a field in machine learning that refers to how the predictive machine learning model is devised via the training of a learning algorithm.
Random Forest
Random forest models are capable of classifying data using a variety of decision tree models all at once. Like decision trees, random forests can be used to determine the classification of categorical variables or the regression of continuous variables. These random forest models generate a number of decision trees as specified by the user, forming what is known as an ensemble. Each tree then makes its own prediction based on some input data, and the random forest machine learning algorithm then makes a prediction by combining the predictions of each decision tree in the ensemble.
What Is Deep Learning?
Deep learning models are a nascent subset of machine learning paradigms. Deep learning uses a series of connected layers which together are capable of quickly and efficiently learning complex prediction models.
If deep learning sounds similar to neural networks, that’s because deep learning is, in fact, a subset of neural networks. Both try to simulate the way the human brain functions. Deep learning models can be distinguished from other neural networks because deep learning models employ more than one hidden layer between the input and the output. This enables deep learning models to be sophisticated in the speed and capability of their predictions.
Deep learning modelsExternal link:open_in_new are employed in a variety of applications and services related to artificial intelligence to improve levels of automation in previously manual tasks. You might find this emerging approach to machine learning powering digital assistants like Siri and voice-driven TV remotes, in fraud detection technology for credit card companies, and as the bedrock of operating systems for self-driving cars.
Machine Learning (ML) vs. Artificial Intelligence (AI)
Trying to make sense of the distinctions between machine learning vs. AI can be tricky, since the two are closely related. In fact, machine learning algorithms are a subset of artificial intelligence algorithms — but not the other way around.
To pinpoint the difference between machine learning and artificial intelligence, it’s important to understand what each subject encompasses. AI refers to any of the software and processes that are designed to mimic the way humans think and process information. It includes computer vision, natural language processing, robotics, autonomous vehicle operating systems, and of course, machine learning. With the help of artificial intelligence, devices are able to learn and identify information in order to solve problems and offer key insights into various domains.
On the other hand, machine learning specifically refers to teaching devices to learn information given to a dataset without manual human interference. This approach to artificial intelligence uses machine learning algorithms that are able to learn from data over time in order to improve the accuracy and efficiency of the overall machine learning model. There are numerous approaches to machine learning, including the previously mentioned deep learning model.
Why Is Machine Learning Important?
Machine learning and data mining, a component of machine learning, are crucial tools used by many companies and researchers. There are two main reasons for this:
Scale of data: Companies are faced with massive volumes and varieties of data that need to be processed. Processing power is more efficient and readily available. Models that can be programmed to process data on their own, determine conclusions, and identify patterns are invaluable.
Unexpected findings: Since a machine learning algorithm updates autonomously, analytical accuracy improves with each run as it teaches itself from the datasets it analyzes. This iterative nature of learning is unique and valuable because it occurs without human intervention — in other words, machine learning algorithms can uncover hidden insights without being specifically programmed to do so.
Who Is Using Machine Learning?
Companies leveraging algorithms to sort through data and optimize business operations aren’t new. Leveraging algorithms extends not only to digital business models such as web services or apps, but also to any company or industry where data can be gathered,External link:open_in_new including the following:
Marketing and sales
Financial services
Brick-and-mortar retail
Health care
Transportation
Oil and gas
Government
Amazon, Facebook, Netflix, and, of course, Google have all been using machine learning algorithms to drive searches, recommendations, targeted advertising, and more for well over a decade. For example, Uber Eats shared in a GeekWire article that they use data mining and machine learningExternal link:open_in_new to estimate delivery times.
Evolution of Machine Learning
Although advances in computing technologies have made machine learning more popular than ever, it’s not a new concept. According to Forbes, the origins of machine learning date back to 1950External link:open_in_new. Speculating on how one could tell if they had developed a truly integrated artificial intelligence (AI), Alan Turing created what is now referred to as the Turing test, which suggests that one way of testing whether or not the AI is capable of understanding language is to see if it’s able to fool a human into thinking they are speaking to another person.
In 1952, Arthur Samuel wrote the first learning program for IBM, this time involving a game of checkers. The work of many other machine learning pioneers followed, including Frank Rosenblatt’s design of the first neural network in 1957 and Gerald DeJong’s introduction of explanation-based learning in 1981.
In the 1990s, a major shift occurred in machine learning when the focus moved away from a knowledge-based approach to one driven by data. This was a critical decade in the field’s evolution, as scientists began creating computer programs that could analyze large datasets and learn in the process.
The 2000s were marked by unsupervised learning becoming widespread, eventually leading to the advent of deep learning and the ubiquity of machine learning as a practice.
Milestones in machine learning are marked by instances in which an algorithm is able to beat the performance of a human being, including Russian chess grandmaster Garry Kasparov’s defeat at the hands of IBM supercomputer Deep Blue in 1997 and, more recently, the 2016 victory of the Google DeepMind AI program AlphaGo over Lee Sedol playing Go, a game notorious for its massively large space of possibilities in game play.
Today, researchers are hard at work to expand on these achievements. As machine learning and artificial intelligence applications become more popular, they’re also becoming more accessible, moving from server-based systems to the cloud. At Google Next 2018, Google touted several new deep learning and machine learning capabilities,External link:open_in_new like Cloud AutoML, BigQuery ML, and more. During the past few years, Amazon, Microsoft, Baidu, and IBM have all unveiled machine learning platforms through open source projects and enterprise cloud services. Machine learning algorithms are here to stay, and they’re rapidly widening the parameters of what research and industry can accomplish.
What Is the Future of Machine Learning?
Machine learning algorithms are being used around the world in nearly every major sector, including business, government, finance, agriculture, transportation, cybersecurity, and marketing. Such rapid adoption across disparate industries is evidence of the value that machine learning (and, by extension, data science) creates. Armed with insights from vast datasets — which often occur in real time — organizations can operate more efficiently and gain a competitive edge.
The applications of machine learning and artificial intelligence extend beyond commerce and optimizing operations. Following its Jeopardy win, IBM applied the Watson algorithm to medical research literature,External link:open_in_new thereby “sending Watson to medical school.” More recently, precision medicine initiatives are breaking new ground using machine learning algorithms driven by massive artificial neural networks (i.e., “deep learning” algorithms) to detect subtle patterns in genetic structure and how one might respond to different medical treatments. Breakthroughs in how machine learning algorithms can be used to represent natural language have enabled a surge in new possibilities that include automated text translation, text summarization techniques, and sophisticated question and answering systems. Other advancements involve learning systems for automated robotics, self-flying drones, and the promise of industrialized self-driving cars.
The continued digitization of most sectors of society and industry means that an ever-growing volume of data will continue to be generated. The ability to gain insights from these vast datasets is one key to addressing an enormous array of issues — from identifying and treating diseases more effectively, to fighting cyber criminals, to helping organizations operate more effectively to boost the bottom line.
The universal capabilities that machine learning enables across so many sectors make it an essential tool — and experts predict a bright future for its use. In fact, in Gartner’s “Top 10 Technology Trends for 2017,”External link:open_in_new machine learning and artificial intelligence topped the list:
“AI and machine learning […] can also encompass more advanced systems that understand, learn, predict, adapt and potentially operate autonomously.” The article also notes: “The combination of extensive parallel processing power, advanced algorithms and massive datasets to feed the algorithms has unleashed this new era.”
Machine Learning and UC Berkeley School of Information
In recognition of machine learning’s critical role today and in the future, datascience@berkeley includes an in-depth focus on machine learning in its online Master of Information and Data Science (MIDS) curriculum.
The foundation course is Applied Machine Learning,External link:open_in_new which provides a broad introduction to the key ideas in machine learning. The emphasis is on intuition and practical examples rather than theoretical results, though some experience with probability, statistics, and linear algebra is important. Students learn how to apply powerful machine learning techniques to new problems, run evaluations and interpret results, and think about scaling up from thousands of data points to billions.
The advanced course, Machine Learning at Scale, builds on and goes beyond the collect-and-analyze phase of big data by focusing on how machine learning algorithms can be rewritten and extended to scale to work on petabytes of data, both structured and unstructured, to generate sophisticated models used for real-time predictions.
In the Natural Language Processing with Deep Learning course, students learn how-to skills using cutting-edge distributed computation and machine learning systems such as Spark. They are trained to code their own implementations of large-scale projects, like Google’s original PageRank algorithm, and discover how to use modern deep learning techniques to train text-understanding algorithms.
This report is part of “A Blueprint for the Future of AI,” a series from the Brookings Institution that analyzes the new challenges and potential policy solutions introduced by artificial intelligence and other emerging technologies.
In the summer of 1955, while planning a now famous workshop at Dartmouth College, John McCarthy coined the term “artificial intelligence” to describe a new field of computer science. Rather than writing programs that tell a computer how to carry out a specific task, McCarthy pledged that he and his colleagues would instead pursue algorithms that could teach themselves how to do so. The goal was to create computers that could observe the world and then make decisions based on those observations—to demonstrate, that is, an innate intelligence.
The question was how to achieve that goal. Early efforts focused primarily on what’s known as symbolic AI, which tried to teach computers how to reason abstractly. But today the dominant approach by far is machine learning, which relies on statistics instead. Although the approach dates back to the 1950s—one of the attendees at Dartmouth, Arthur Samuels, was the first to describe his work as “machine learning”—it wasn’t until the past few decades that computers had enough storage and processing power for the approach to work well. The rise of cloud computing and customized chips has powered breakthrough after breakthrough, with research centers like OpenAI or DeepMind announcing stunning new advances seemingly every week.
Machine learning is now so popular that it has effectively become synonymous with artificial intelligence itself. As a result, it’s not possible to tease out the implications of AI without understanding how machine learning works.
The extraordinary success of machine learning has made it the default method of choice for AI researchers and experts. Indeed, machine learning is now so popular that it has effectively become synonymous with artificial intelligence itself. As a result, it’s not possible to tease out the implications of AI without understanding how machine learning works—as well as how it doesn’t.
HOW DOES MACHINE LEARNING WORK?
The core insight of machine learning is that much of what we recognize as intelligence hinges on probability rather than reason or logic. If you think about it long enough, this makes sense. When we look at a picture of someone, our brains unconsciously estimate how likely it is that we have seen their face before. When we drive to the store, we estimate which route is most likely to get us there the fastest. When we play a board game, we estimate which move is most likely to lead to victory. Recognizing someone, planning a trip, plotting a strategy—each of these tasks demonstrate intelligence. But rather than hinging primarily on our ability to reason abstractly or think grand thoughts, they depend first and foremost on our ability to accurately assess how likely something is. We just don’t always realize that that’s what we’re doing.
Back in the 1950s, though, McCarthy and his colleagues did realize it. And they understood something else too: Computers should be very good at computing probabilities. Transistors had only just been invented, and had yet to fully supplant vacuum tube technology. But it was clear even then that with enough data, digital computers would be ideal for estimating a given probability. Unfortunately for the first AI researchers, their timing was a bit off. But their intuition was spot on—and much of what we now know as AI is owed to it. When Facebook recognizes your face in a photo, or Amazon Echo understands your question, they’re relying on an insight that is over sixty years old.
The core insight of machine learning is that much of what we recognize as intelligence hinges on probability rather than reason or logic.
The machine learning algorithm that Facebook, Google, and others all use is something called a deep neural network. Building on the prior work of Warren McCullough and Walter Pitts, Frank Rosenblatt coded one of the first working neural networks in the late 1950s. Although today’s neural networks are a bit more complex, the main idea is still the same: The best way to estimate a given probability is to break the problem down into discrete, bite-sized chunks of information, or what McCullough and Pitts termed a “neuron.” Their hunch was that if you linked a bunch of neurons together in the right way, loosely akin to how neurons are linked in the brain, then you should be able to build models that can learn a variety of tasks.
To get a feel for how neural networks work, imagine you wanted to build an algorithm to detect whether an image contained a human face. A basic deep neural network would have several layers of thousands of neurons each. In the first layer, each neuron might learn to look for one basic shape, like a curve or a line. In the second layer, each neuron would look at the first layer, and learn to see whether the lines and curves it detects ever make up more advanced shapes, like a corner or a circle. In the third layer, neurons would look for even more advanced patterns, like a dark circle inside a white circle, as happens in the human eye. In the final layer, each neuron would learn to look for still more advanced shapes, such as two eyes and a nose. Based on what the neurons in the final layer say, the algorithm will then estimate how likely it is that an image contains a face. (For an illustration of how deep neural networks learn hierarchical feature representations, see here.)
The magic of deep learning is that the algorithm learns to do all this on its own. The only thing a researcher does is feed the algorithm a bunch of images and specify a few key parameters, like how many layers to use and how many neurons should be in each layer, and the algorithm does the rest. At each pass through the data, the algorithm makes an educated guess about what type of information each neuron should look for, and then updates each guess based on how well it works. As the algorithm does this over and over, eventually it “learns” what information to look for, and in what order, to best estimate, say, how likely an image is to contain a face.
What’s remarkable about deep learning is just how flexible it is. Although there are other prominent machine learning algorithms too—albeit with clunkier names, like gradient boosting machines—none are nearly so effective across nearly so many domains. With enough data, deep neural networks will almost always do the best job at estimating how likely something is. As a result, they’re often also the best at mimicking intelligence too.
Related
Teaching the public about machine learning
What is artificial intelligence?
The Brookings glossary of AI and emerging technologies
Yet as with machine learning more generally, deep neural networks are not without limitations. To build their models, machine learning algorithms rely entirely on training data, which means both that they will reproduce the biases in that data, and that they will struggle with cases that are not found in that data. Further, machine learning algorithms can also be gamed. If an algorithm is reverse engineered, it can be deliberately tricked into thinking that, say, a stop sign is actually a person. Some of these limitations may be resolved with better data and algorithms, but others may be endemic to statistical modeling.
MACHINE LEARNING APPLICATIONS
To glimpse how the strengths and weaknesses of AI will play out in the real-world, it is necessary to describe the current state of the art across a variety of intelligent tasks. Below, I look at the situation in regard to speech recognition, image recognition, robotics, and reasoning in general.
Speech recognition
Ever since digital computers were invented, linguists and computer scientists have sought to use them to recognize speech and text. Known as natural language processing, or NLP, the field once focused on hardwiring syntax and grammar into code. However, over the past several decades, machine learning has largely surpassed rule-based systems, thanks to everything from support vector machines to hidden markov models to, most recently, deep learning. Apple’s Siri, Amazon’s Alexa, and Google’s Duplex all rely heavily on deep learning to recognize speech or text, and represent the cutting-edge of the field.
When several leading researchers recently set a deep learning algorithm loose on Amazon reviews, they were surprised to learn that the algorithm had not only taught itself grammar and syntax, but a sentiment classifier too.
The specific deep learning algorithms at play have varied somewhat. Recurrent neural networks powered many of the initial deep learning breakthroughs, while hierarchical attention networks are responsible for more recent ones. What they all share in common, though, is that the higher levels of a deep learning network effectively learn grammar and syntax on their own. In fact, when several leading researchers recently set a deep learning algorithm loose on Amazon reviews, they were surprised to learn that the algorithm had not only taught itself grammar and syntax, but a sentiment classifier too.
Yet for all the success of deep learning at speech recognition, key limitations remain. The most important is that because deep neural networks only ever build probabilistic models, they don’t understand language in the way humans do; they can recognize that the sequence of letters k-i-n-g and q-u-e-e-n are statistically related, but they have no innate understanding of what either word means, much less the broader concepts of royalty and gender. As a result, there is likely to be a ceiling to how intelligent speech recognition systems based on deep learning and other probabilistic models can ever be. If we ever build an AI like the one in the movie “Her,” which was capable of genuine human relationships, it will almost certainly take a breakthrough well beyond what a deep neural network can deliver.
Image recognition
When Rosenblatt first implemented his neural network in 1958, he initially set it loose on images of dogs and cats. AI researchers have been focused on tackling image recognition ever since. By necessity, much of that time was spent devising algorithms that could detect pre-specified shapes in an image, like edges and polyhedrons, using the limited processing power of early computers. Thanks to modern hardware, however, the field of computer vision is now dominated by deep learning instead. When a Tesla drives safely in autopilot mode, or when Google’s new augmented-reality microscope detects cancer in real-time, it’s because of a deep learning algorithm.
A few stickers on a stop sign can be enough to prevent a deep learning model from recognizing it as such. For image recognition algorithms to reach their full potential, they’ll need to become much more robust.
Convolutional neural networks, or CNNs, are the variant of deep learning most responsible for recent advances in computer vision. Developed by Yann LeCun and others, CNNs don’t try to understand an entire image all at once, but instead scan it in localized regions, much the way a visual cortex does. LeCun’s early CNNs were used to recognize handwritten numbers, but today the most advanced CNNs, such as capsule networks, can recognize complex three-dimensional objects from multiple angles, even those not represented in training data. Meanwhile, generative adversarial networks, the algorithm behind “deep fake” videos, typically use CNNs not to recognize specific objects in an image, but instead to generate them.
As with speech recognition, cutting-edge image recognition algorithms are not without drawbacks. Most importantly, just as all that NLP algorithms learn are statistical relationships between words, all that computer vision algorithms learn are statistical relationships between pixels. As a result, they can be relatively brittle. A few stickers on a stop sign can be enough to prevent a deep learning model from recognizing it as such. For image recognition algorithms to reach their full potential, they’ll need to become much more robust.
Robotics
What makes our intelligence so powerful is not just that we can understand the world, but that we can interact with it. The same will be true for machines. Computers that can learn to recognize sights and sounds are one thing; those that can learn to identify an object as well as how to manipulate it are another altogether. Yet if image and speech recognition are difficult challenges, touch and motor control are far more so. For all their processing power, computers are still remarkably poor at something as simple as picking up a shirt.
The reason: Picking up an object like a shirt isn’t just one task, but several. First you need to recognize a shirt as a shirt. Then you need to estimate how heavy it is, how its mass is distributed, and how much friction its surface has. Based on those guesses, then you need to estimate where to grasp the shirt and how much force to apply at each point of your grip, a task made all the more challenging because the shirt’s shape and distribution of mass will change as you lift it up. A human does this trivially and easily. But for a computer, the uncertainty in any of those calculations compounds across all of them, making it an exceedingly difficult task.
Initially, programmers tried to solve the problem by writing programs that instructed robotic arms how to carry out each task step by step. However, just as rule-based NLP can’t account for all possible permutations of language, there also is no way for rule-based robotics to run through all the possible permutations of how an object might be grasped. By the 1980s, it became increasingly clear that robots would need to learn about the world on their own and develop their own intuitions about how to interact with it. Otherwise, there was no way they would be able to reliably complete basic maneuvers like identifying an object, moving toward it, and picking it up.
The current state of the art is something called deep reinforcement learning. As a crude shorthand, you can think of reinforcement learning as trial and error. If a robotic arm tries a new way of picking up an object and succeeds, it rewards itself; if it drops the object, it punishes itself. The more the arm attempts its task, the better it gets at learning good rules of thumb for how to complete it. Coupled with modern computing, deep reinforcement learning has shown enormous promise. For instance, by simulating a variety of robotic hands across thousands of servers, OpenAI recently taught a real robotic hand how to manipulate a cube marked with letters.
For all their processing power, computers are still remarkably poor at something as simple as picking up a shirt.
Compared with prior research, OpenAI’s breakthrough is tremendously impressive. Yet it also shows the limitations of the field. The hand OpenAI built didn’t actually “feel” the cube at all, but instead relied on a camera. For an object like a cube, which doesn’t change shape and can be easily simulated in virtual environments, such an approach can work well. But ultimately, robots will need to rely on more than just eyes. Machines with the dexterity and fine motor skills of a human are still a ways away.
Reasoning
When Arthur Samuels coined the term “machine learning,” he wasn’t researching image or speech recognition, nor was he working on robots. Instead, Samuels was tackling one of his favorite pastimes: checkers. Since the game had far too many potential board moves for a rule-based algorithm to encode them all, Samuels devised an algorithm that could teach itself to efficiently look several moves ahead. The algorithm was noteworthy for working at all, much less being competitive with other humans. But it also anticipated the astonishing breakthroughs of more recent algorithms like AlphaGo and AlphaGo Zero, which have surpassed all human players at Go, widely regarded as the most intellectually demanding board game in the world.
As with robotics, the best strategic AI relies on deep reinforcement learning. In fact, the algorithm that OpenAI used to power its robotic hand also formed the core of its algorithm for playing Dota 2, a multi-player video game. Although motor control and gameplay may seem very different, both involve the same process: making a sequence of moves over time, and then evaluating whether they led to success or failure. Trial and error, it turns out, is as useful for learning to reason about a game as it is for manipulating a cube.
Since the algorithm works only by learning from outcome data, it needs a human to define what the outcome should be. As a result, reinforcement learning is of little use in the many strategic contexts in which the outcome is not always clear.
From Samuels on, the success of computers at board games has posed a puzzle to AI optimists and pessimists alike. If a computer can beat a human at a strategic game like chess, how much can we infer about its ability to reason strategically in other environments? For a long time, the answer was, “very little.” After all, most board games involve a single player on each side, each with full information about the game, and a clearly preferred outcome. Yet most strategic thinking involves cases where there are multiple players on each side, most or all players have only limited information about what is happening, and the preferred outcome is not clear. For all of AlphaGo’s brilliance, you’ll note that Google didn’t then promote it to CEO, a role that is inherently collaborative and requires a knack for making decisions with incomplete information.
Fortunately, reinforcement learning researchers have recently made progress on both of those fronts. One team outperformed human players at Texas Hold ‘Em, a poker game where making the most of limited information is key. Meanwhile, OpenAI’s Dota 2 player, which coupled reinforcement learning with what’s called a Long Short-Term Memory (LSTM) algorithm, has made headlines for learning how to coordinate the behavior of five separate bots so well that they were able to beat a team of professional Dota 2 players. As the algorithms improve, humans will likely have a lot to learn about optimal strategies for cooperation, especially in information-poor environments. This kind of information would be especially valuable for commanders in military settings, who sometimes have to make decisions without having comprehensive information.
Yet there’s still one challenge no reinforcement learning algorithm can ever solve. Since the algorithm works only by learning from outcome data, it needs a human to define what the outcome should be. As a result, reinforcement learning is of little use in the many strategic contexts in which the outcome is not always clear. Should corporate strategy prioritize growth or sustainability? Should U.S. foreign policy prioritize security or economic development? No AI will ever be able to answer higher-order strategic reasoning, because, ultimately, those are moral or political questions rather than empirical ones. The Pentagon may lean more heavily on AI in the years to come, but it won’t be taking over the situation room and automating complex tradeoffs any time soon.
WHAT’S NEXT FOR MACHINE LEARNING?
From autonomous cars to multiplayer games, machine learning algorithms can now approach or exceed human intelligence across a remarkable number of tasks. The breakout success of deep learning in particular has led to breathless speculation about both the imminent doom of humanity and its impending techno-liberation. Not surprisingly, all the hype has led several luminaries in the field, such as Gary Marcus or Judea Pearl, to caution that machine learning is nowhere near as intelligent as it is being presented, or that perhaps we should defer our deepest hopes and fears about AI until it is based on more than mere statistical correlations. Even Geoffrey Hinton, a researcher at Google and one of the godfathers of modern neural networks, has suggested that deep learning alone is unlikely to deliver the level of competence many AI evangelists envision.
Where the long-term implications of AI are concerned, the key question about machine learning is this: How much of human intelligence can be approximated with statistics? If all of it can be, then machine learning may well be all we need to get to a true artificial general intelligence. But it’s very unclear whether that’s the case. As far back as 1969, when Marvin Minsky and Seymour Papert famously argued that neural networks had fundamental limitations, even leading experts in AI have expressed skepticism that machine learning would be enough. Modern skeptics like Marcus and Pearl are only writing the latest chapter in a much older book. And it’s hard not to find their doubts at least somewhat compelling. The path forward from the deep learning of today, which can mistake a rifle for a helicopter, is by no means obvious.
Where the long-term implications of AI are concerned, the key question about machine learning is this: How much of human intelligence can be approximated with statistics?
Yet the debate over machine learning’s long-term ceiling is to some extent beside the point. Even if all research on machine learning were to cease, the state-of-the-art algorithms of today would still have an unprecedented impact. The advances that have already been made in computer vision, speech recognition, robotics, and reasoning will be enough to dramatically reshape our world. Just as happened in the so-called “Cambrian explosion,” when animals simultaneously evolved the ability to see, hear, and move, the coming decade will see an explosion in applications that combine the ability to recognize what is happening in the world with the ability to move and interact with it. Those applications will transform the global economy and politics in ways we can scarcely imagine today. Policymakers need not wring their hands just yet about how intelligent machine learning may one day become. They will have their hands full responding to how intelligent it already is.
Machine learning is a subset of artificial intelligence (AI) in which algorithms learn by example from historical data to predict outcomes and uncover patterns not easily spotted by humans. For example, machine learning can reveal customers who are likely to churn, likely fraudulent insurance claims, and more. While machine learning has been around since the 1950s, recent breakthroughs in low-cost compute resources like cloud storage, easier data collection, and the proliferation of data science have made it very much “the next big thing” in business analytics.
To put it simply, the machine learning algorithm learns by example, and then users apply those self-learning algorithms to uncover insights, determine relationships, and make predictions about future trends. Machine learning has practical implications across industry sectors, including healthcare, insurance, energy, marketing, manufacturing, financial technology (fintech), and more. When implemented effectively, machine learning allows businesses to uncover optimal solutions to practical problems, which leads to real, tangible business value.
Why is Machine Learning Important?
While most statistical analysis relies on rule-based decision-making, machine learning excels at tasks that are hard to define with exact step-by-step rules. Machine learning can be applied to numerous business scenarios in which an outcome depends on hundreds of factors — factors that are difficult or impossible for a human to monitor. As a result, businesses use machine learning for predicting loan defaults, understanding factors that lead to customer churn, identifying likely fraudulent transactions, optimizing insurance claims processes, predicting hospital readmission, and many other cases.
Companies that effectively implement machine learning and other AI technologies gain a massive competitive advantage. According to a recent report by McKinsey & Company, AI technologies will create $50 trillion of value by the year 2025. Companies that fail to do the same will be unable to compete with those who embrace the new frontier – and sooner rather than later.
Machine Learning + DataRobot
Historically, machine learning has been a tedious process that requires a lot of manual coding, limiting the ability of organizations to take full advantage of the technology. Without teams of difficult-to-find data scientists at their disposal, companies are limited in the number of models they are able to develop and test – and often those models take so long to develop, they are outdated by the time they are complete.
To solve this problem, DataRobot invented automated machine learning. Building a high-quality machine learning model often involves a combination of elaborate feature engineering, a Ph.D.-level knowledge of statistics, and extensive software engineering experience. DataRobot strives to make machine learning more accessible to everyone in every organization by incorporating the knowledge and best practices of the world’s best data scientists into a fully automated modeling platform that you can use regardless of data science experience or coding knowledge, delivering insights an order of magnitude faster than was previously possible.
Learn More About AI
End-to-End AI: The Complete Guide to DataRobot’s Enterprise AI Platform
Machine-learning algorithms find and apply patterns in data. And they pretty much run the world.
Machine-learning algorithms are responsible for the vast majority of the artificial intelligence advancements and applications you hear about. (For more background, check out our first flowchart on “What is AI?” here.)
What is the definition of machine learning?
Machine-learning algorithms use statistics to find patterns in massive* amounts of data. And data, here, encompasses a lot of things—numbers, words, images, clicks, what have you. If it can be digitally stored, it can be fed into a machine-learning algorithm.
Machine learning is the process that powers many of the services we use today—recommendation systems like those on Netflix, YouTube, and Spotify; search engines like Google and Baidu; social-media feeds like Facebook and Twitter; voice assistants like Siri and Alexa. The list goes on.
In all of these instances, each platform is collecting as much data about you as possible—what genres you like watching, what links you are clicking, which statuses you are reacting to—and using machine learning to make a highly educated guess about what you might want next. Or, in the case of a voice assistant, about which words match best with the funny sounds coming out of your mouth.
Frankly, this process is quite basic: find the pattern, apply the pattern. But it pretty much runs the world. That’s in big part thanks to an invention in 1986, courtesy of Geoffrey Hinton, today known as the father of deep learning.
What is deep learning?
Deep learning is machine learning on steroids: it uses a technique that gives machines an enhanced ability to find—and amplify—even the smallest patterns. This technique is called a deep neural network—deep because it has many, many layers of simple computational nodes that work together to munch through data and deliver a final result in the form of the prediction.
What are neural networks?
Neural networks were vaguely inspired by the inner workings of the human brain. The nodes are sort of like neurons, and the network is sort of like the brain itself. (For the researchers among you who are cringing at this comparison: Stop pooh-poohing the analogy. It’s a good analogy.) But Hinton published his breakthrough paper at a time when neural nets had fallen out of fashion. No one really knew how to train them, so they weren’t producing good results. It took nearly 30 years for the technique to make a comeback. And boy, did it make a comeback.
What is supervised learning?
One last thing you need to know: machine (and deep) learning comes in three flavors: supervised, unsupervised, and reinforcement. In supervised learning, the most prevalent, the data is labeled to tell the machine exactly what patterns it should look for. Think of it as something like a sniffer dog that will hunt down targets once it knows the scent it’s after. That’s what you’re doing when you press play on a Netflix show—you’re telling the algorithm to find similar shows.
What is unsupervised learning?
In unsupervised learning, the data has no labels. The machine just looks for whatever patterns it can find. This is like letting a dog smell tons of different objects and sorting them into groups with similar smells. Unsupervised techniques aren’t as popular because they have less obvious applications. Interestingly, they have gained traction in cybersecurity.
What is reinforcement learning?
Lastly, we have reinforcement learning, the latest frontier of machine learning. A reinforcement algorithm learns by trial and error to achieve a clear objective. It tries out lots of different things and is rewarded or penalized depending on whether its behaviors help or hinder it from reaching its objective. This is like giving and withholding treats when teaching a dog a new trick. Reinforcement learning is the basis of Google’s AlphaGo, the program that famously beat the best human players in the complex game of Go.
That’s it. That’s machine learning. Now check out the flowchart above for a final recap.
*Note: Okay, there are technically ways to perform machine learning on smallish amounts of data, but you typically need huge piles of it to achieve good results.
ARTIFICIAL INTELLIGENCE
ChatGPT is about to revolutionize the economy. We need to decide what that looks like.
New large language models will transform many jobs. Whether they will lead to widespread prosperity or not is up to us.
ChatGPT is going to change education, not destroy it
The narrative around cheating students doesn’t tell the whole story. Meet the teachers who think generative AI could actually make learning better.
Deep learning pioneer Geoffrey Hinton has quit Google
Hinton will be speaking at EmTech Digital on Wednesday.
Many services that we use every day rely on machine learning – a field of science and a powerful technology that allows machines to learn from data and self-improve.
Machine learning is used in internet search engines, email filters to sort out spam, websites to make personalised recommendations, banking software to detect unusual transactions, and lots of apps on our phones such as voice recognition.
The technology has many more potential applications, some with higher stakes than others. Future developments could support the UK economy and will have a significant impact upon society. For example, machine learning could provide us with readily available ‘personal assistants’ to help manage our lives, it could dramatically improve the transport system through the use of autonomous vehicles; and the healthcare system, by improving disease diagnoses or personalising treatment. Machine learning could also be used for security applications, such as analysing email communications or internet usage. The implications of these and other applications of the technology need to be considered now and action taken to ensure uses will be beneficial to society.
Machine learning is distinct from, but overlaps with, some aspects of robotics (robots are an example of the hardware that can use machine learning algorithms, for instance to make robots autonomous) and artificial intelligence (AI) (a concept that doesn’t have an agreed definition; however machine learning is a way of achieving a degree of AI).
What is the Royal Society project about?
There are both opportunities and challenges around this transformative technology
There are both opportunities and challenges around this transformative technology and it raises social, legal, and ethical questions. This is why the Royal Society is starting a project on machine learning, aiming to stimulate a debate, to increase awareness and demonstrate the potential of machine learning and highlight the opportunities and challenges it presents. In the course of the project we will engage with policymakers, academia, industry and the wider public.
The project will focus on current and near-term (5-10 years) applications of machine learning. It will have a strong public engagement element, and a variety of resources will be produced over the course of the project. Details of these will also be posted these web pages.
The project scope was developed by a Core Group of experts who met over the summer 2015.
Who will inform this project?
This Royal Society project is led by a Working Group involving a range of expertise.
Answers to our call for evidence (now closed) also inform the project.
Evidence gathering sessions and public events will be held over the course of the project.
What will come out of the project?
The project also pulls together evidence-based recommendations in a policy report for UK and EU policy makers, published April 2017.
Machine learning (ML) is the subset of artificial intelligence (AI) that focuses on building systems that learn—or improve performance—based on the data they consume. Artificial intelligence is a broad term that refers to systems or machines that mimic human intelligence. Machine learning and AI are often discussed together, and the terms are sometimes used interchangeably, but they don’t mean the same thing. An important distinction is that although all machine learning is AI, not all AI is machine learning.
Today, machine learning is at work all around us. When we interact with banks, shop online, or use social media, machine learning algorithms come into play to make our experience efficient, smooth, and secure. Machine learning and the technology around it are developing rapidly, and we’re just beginning to scratch the surface of its capabilities.
Learn more about machine learning solution
Types of Machine learning: two approaches to learning
Algorithms are the engines that power machine learning. In general, two major types of machine learning algorithms are used today: supervised learning and unsupervised learning. The difference between them is defined by how each learns about data to make predictions.
Supervised Machine Learning
Supervised machine learning algorithms are the most commonly used. With this model, a data scientist acts as a guide and teaches the algorithm what conclusions it should make. Just as a child learns to identify fruits by memorizing them in a picture book, in supervised learning, the algorithm is trained by a dataset that is already labeled and has a predefined output.
Examples of supervised machine learning include algorithms such as linear and logistic regression, multiclass classification, and support vector machines.
Unsupervised Machine Learning
Unsupervised machine learning uses a more independent approach, in which a computer learns to identify complex processes and patterns without a human providing close, constant guidance. Unsupervised machine learning involves training based on data that does not have labels or a specific, defined output.
To continue the childhood teaching analogy, unsupervised machine learning is akin to a child learning to identify fruit by observing colors and patterns, rather than memorizing the names with a teacher’s help. The child would look for similarities between images and separate them into groups, assigning each group its own new label. Examples of unsupervised machine learning algorithms include k-means clustering, principal and independent component analysis, and association rules.
Choosing an Approach
Which approach is best for your needs? Choosing a supervised or unsupervised machine learning algorithm usually depends on factors related to the structure and volume of your data, and the use case to which you want to apply it. Machine learning has blossomed across a wide range of industries, supporting a variety of business goals and use cases including:
When getting started with machine learning, developers will rely on their knowledge of statistics, probability, and calculus to most successfully create models that learn over time. With sharp skills in these areas, developers should have no problem learning the tools many other developers use to train modern ML algorithms. Developers also can make decisions about whether their algorithms will be supervised or unsupervised. It’s possible for a developer to make decisions and set up a model early on in a project, then allow the model to learn without much further developer involvement.
There is often a blurry line between developer and data scientist. Sometimes developers will synthesize data from a machine learning model, while data scientists will contribute to developing solutions for the end user. Collaboration between these two disciplines can make ML projects more valuable and useful.
Get started with ML
Machine learning business goal: model customer lifetime value
Customer lifetime value modeling is essential for ecommerce businesses but is also applicable across many other industries. In this model, organizations use machine learning algorithms to identify, understand, and retain their most valuable customers. These value models evaluate massive amounts of customer data to determine the biggest spenders, the most loyal advocates for a brand, or combinations of these types of qualities.
Customer lifetime value models are especially effective at predicting the future revenue that an individual customer will bring to a business in a given period. This information empowers organizations to focus marketing efforts on encouraging high-value customers to interact with their brand more often. Customer lifetime value models also help organizations target their acquisition spend to attract new customers that are similar to existing high-value customers.
Model customer churn through machine learning
Acquiring new customers is more time consuming and costlier than keeping existing customers satisfied and loyal. Customer churn modeling helps organizations identify which customers are likely to stop engaging with a business—and why.
An effective churn model uses machine learning algorithms to provide insight into everything from churn risk scores for individual customers to churn drivers, ranked by importance. These outputs are key to developing an algorithmic retention strategy.
Gaining deeper insight into customer churn helps businesses optimize discount offers, email campaigns, and other targeted marketing initiatives that keep their high-value customers buying—and coming back for more.
Consumers have more choices than ever, and they can compare prices via a wide range of channels, instantly. Dynamic pricing, also known as demand pricing, enables businesses to keep pace with accelerating market dynamics. It lets organizations flexibly price items based on factors including the level of interest of the target customer, demand at the time of purchase, and whether the customer has engaged with a marketing campaign.
This level of business agility requires a solid machine learning strategy and a great deal of data about how different customers’ willingness to pay for a good or service changes across a variety of situations. Although dynamic pricing models can be complex, companies such as airlines and ride-share services have successfully implemented dynamic price optimization strategies to maximize revenue.
Machine learning business goal: target customers with customer segmentation
Successful marketing has always been about offering the right product to the right person at the right time. Not so long ago, marketers relied on their own intuition for customer segmentation, separating customers into groups for targeted campaigns.
Today, machine learning enables data scientists to use clustering and classification algorithms to group customers into personas based on specific variations. These personas consider customer differences across multiple dimensions such as demographics, browsing behavior, and affinity. Connecting these traits to patterns of purchasing behavior enables data-savvy companies to roll out highly personalized marketing campaigns that are more effective at boosting sales than generalized campaigns are.
As the data available to businesses grows and algorithms become more sophisticated, personalization capabilities will increase, moving businesses closer to the ideal customer segment of one.
Machine learning business goal: tap the power of image classification
Machine learning supports a variety of use cases beyond retail, financial services, and ecommerce. It also has tremendous potential for science, healthcare, construction, and energy applications. For example, image classification employs machine learning algorithms to assign a label from a fixed set of categories to any input image. It enables organizations to model 3D construction plans based on 2D designs, facilitate photo tagging in social media, inform medical diagnoses, and more.
Deep learning methods such as neural networks are often used for image classification because they can most effectively identify the relevant features of an image in the presence of potential complications. For example, they can consider variations in the point of view, illumination, scale, or volume of clutter in the image and offset these issues to deliver the most relevant, high-quality insights.
Blog: What’s the Difference Between AI, Machine Learning, and Deep Learning?
Recommendation engines
Recommendation engines are essential to cross-selling and up-selling consumers and delivering a better customer experience.
Netflix values the recommendation engine powering its content suggestions at US$1 billion per year and Amazon claims that its system increases annual sales by 20 to 35 percent.
Recommendation engines use machine learning algorithms to sift through large quantities of data to predict how likely a customer is to purchase an item or enjoy a piece of content, and then make customized suggestions to the user. The result is a more personalized, relevant experience that encourages better engagement and reduces churn.
Machine learning use cases
Machine learning powers a variety of key business use cases. But how does it deliver competitive advantage? Among machine learning’s most compelling qualities is its ability to automate and speed time to decision and accelerate time to value. That starts with gaining better business visibility and enhancing collaboration.
“Traditionally what we see is people not being able to work together,” says Rich Clayton, vice president of product strategy for Oracle Analytics. “Adding machine learning to Oracle Analytics Cloud ultimately helps people organize their work and build, train, and deploy these data models. It’s a collaboration tool whose value is in accelerating the process and allowing different parts of the business to collaborate, giving you better quality and models for you to deploy.”
For example, typical finance departments are routinely burdened by repeating a variance analysis process—a comparison between what is actual and what was forecast. It’s a low-cognitive application that can benefit greatly from machine learning.
“By embedding machine learning, finance can work faster and smarter, and pick up where the machine left off,” Clayton says.
The power of prediction
Another exciting capability of machine learning is its predictive capabilities. In the past, business decisions were often made based on historical outcomes. Today, machine learning employs rich analytics to predict what will happen. Organizations can make forward-looking, proactive decisions instead of relying on past data.
For example, predictive maintenance can enable manufacturers, energy companies, and other industries to seize the initiative and ensure that their operations remain dependable and optimized. In an oil field with hundreds of drills in operation, machine learning models can spot equipment that’s at risk of failure in the near future and then notify maintenance teams in advance. This approach not only maximizes productivity, it increases asset performance, uptime, and longevity. It can also minimize worker risk, decrease liability, and improve regulatory compliance.
The benefits of predictive maintenance extend to inventory control and management. Avoiding unplanned equipment downtime by implementing predictive maintenance helps organizations more accurately predict the need for spare parts and repairs—significantly reducing capital and operating expenses.
Webcast: Where Will Machine Learning Take You?
Machine learning potential
Machine learning offers tremendous potential to help organizations derive business value from the wealth of data available today. However, inefficient workflows can hold companies back from realizing machine learning’s maximum potential.
To succeed at an enterprise level, machine learning needs to be part of a comprehensive platform that helps organizations simplify operations and deploy models at scale. The right solution will enable organizations to centralize all data science work in a collaborative platform and accelerate the use and management of open source tools, frameworks, and infrastructure.
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
IBM has a rich history with machine learning. One of its own, Arthur Samuel, is credited for coining the term, “machine learning” with his research (PDF, 481 KB) (link resides outside IBM) around the game of checkers. Robert Nealey, the self-proclaimed checkers master, played the game on an IBM 7094 computer in 1962, and he lost to the computer. Compared to what can be done today, this feat seems trivial, but it’s considered a major milestone in the field of artificial intelligence.
Over the last couple of decades, the technological advances in storage and processing power have enabled some innovative products based on machine learning, such as Netflix’s recommendation engine and self-driving cars.
Machine learning is an important component of the growing field of data science. Through the use of statistical methods, algorithms are trained to make classifications or predictions, and to uncover key insights in data mining projects. These insights subsequently drive decision making within applications and businesses, ideally impacting key growth metrics. As big data continues to expand and grow, the market demand for data scientists will increase. They will be required to help identify the most relevant business questions and the data to answer them.
Machine learning algorithms are typically created using frameworks that accelerate solution development, such as TensorFlow and PyTorch.
Machine Learning vs. Deep Learning vs. Neural Networks Since deep learning and machine learning tend to be used interchangeably, it’s worth noting the nuances between the two. Machine learning, deep learning, and neural networks are all sub-fields of artificial intelligence. However, neural networks is actually a sub-field of machine learning, and deep learning is a sub-field of neural networks.
The way in which deep learning and machine learning differ is in how each algorithm learns. “Deep” machine learning can use labeled datasets, also known as supervised learning, to inform its algorithm, but it doesn’t necessarily require a labeled dataset. Deep learning can ingest unstructured data in its raw form (e.g., text or images), and it can automatically determine the set of features which distinguish different categories of data from one another. This eliminates some of the human intervention required and enables the use of larger data sets. You can think of deep learning as “scalable machine learning” as Lex Fridman notes in this MIT lecture (01:08:05) (link resides outside IBM).
Classical, or “non-deep”, machine learning is more dependent on human intervention to learn. Human experts determine the set of features to understand the differences between data inputs, usually requiring more structured data to learn.
Neural networks, or artificial neural networks (ANNs), are comprised of node layers, containing an input layer, one or more hidden layers, and an output layer. Each node, or artificial neuron, connects to another and has an associated weight and threshold. If the output of any individual node is above the specified threshold value, that node is activated, sending data to the next layer of the network. Otherwise, no data is passed along to the next layer of the network by that node. The “deep” in deep learning is just referring to the number of layers in a neural network. A neural network that consists of more than three layers—which would be inclusive of the input and the output—can be considered a deep learning algorithm or a deep neural network. A neural network that only has three layers is just a basic neural network.
Deep learning and neural networks are credited with accelerating progress in areas such as computer vision, natural language processing, and speech recognition.
See the blog post “AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the Difference?” for a closer look at how the different concepts relate.
How machine learning works UC Berkeley (link resides outside IBM) breaks out the learning system of a machine learning algorithm into three main parts.
A Decision Process: In general, machine learning algorithms are used to make a prediction or classification. Based on some input data, which can be labeled or unlabeled, your algorithm will produce an estimate about a pattern in the data. An Error Function: An error function evaluates the prediction of the model. If there are known examples, an error function can make a comparison to assess the accuracy of the model. A Model Optimization Process: If the model can fit better to the data points in the training set, then weights are adjusted to reduce the discrepancy between the known example and the model estimate. The algorithm will repeat this “evaluate and optimize” process, updating weights autonomously until a threshold of accuracy has been met. Machine learning methods Machine learning models fall into three primary categories.
Supervised machine learning Supervised learning, also known as supervised machine learning, is defined by its use of labeled datasets to train algorithms to classify data or predict outcomes accurately. As input data is fed into the model, the model adjusts its weights until it has been fitted appropriately. This occurs as part of the cross validation process to ensure that the model avoids overfitting or underfitting. Supervised learning helps organizations solve a variety of real-world problems at scale, such as classifying spam in a separate folder from your inbox. Some methods used in supervised learning include neural networks, naïve bayes, linear regression, logistic regression, random forest, and support vector machine (SVM).
Unsupervised machine learning Unsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets. These algorithms discover hidden patterns or data groupings without the need for human intervention. This method’s ability to discover similarities and differences in information make it ideal for exploratory data analysis, cross-selling strategies, customer segmentation, and image and pattern recognition. It’s also used to reduce the number of features in a model through the process of dimensionality reduction. Principal component analysis (PCA) and singular value decomposition (SVD) are two common approaches for this. Other algorithms used in unsupervised learning include neural networks, k-means clustering, and probabilistic clustering methods.
Semi-supervised learning Semi-supervised learning offers a happy medium between supervised and unsupervised learning. During training, it uses a smaller labeled data set to guide classification and feature extraction from a larger, unlabeled data set. Semi-supervised learning can solve the problem of not having enough labeled data for a supervised learning algorithm. It also helps if it’s too costly to label enough data.
For a deep dive into the differences between these approaches, check out “Supervised vs. Unsupervised Learning: What’s the Difference?”
Reinforcement machine learning Reinforcement machine learning is a machine learning model that is similar to supervised learning, but the algorithm isn’t trained using sample data. This model learns as it goes by using trial and error. A sequence of successful outcomes will be reinforced to develop the best recommendation or policy for a given problem.
The IBM Watson® system that won the Jeopardy! challenge in 2011 is a good example. The system used reinforcement learning to learn when to attempt an answer (or question, as it were), which square to select on the board, and how much to wager—especially on daily doubles.
Learn more about reinforcement learning.
Common machine learning algorithms A number of machine learning algorithms are commonly used. These include:
Neural networks: Neural networks simulate the way the human brain works, with a huge number of linked processing nodes. Neural networks are good at recognizing patterns and play an important role in applications including natural language translation, image recognition, speech recognition, and image creation. Linear regression: This algorithm is used to predict numerical values, based on a linear relationship between different values. For example, the technique could be used to predict house prices based on historical data for the area. Logistic regression: This supervised learning algorithm makes predictions for categorical response variables, such as“yes/no” answers to questions. It can be used for applications such as classifying spam and quality control on a production line. Clustering: Using unsupervised learning, clustering algorithms can identify patterns in data so that it can be grouped. Computers can help data scientists by identifying differences between data items that humans have overlooked. Decision trees: Decision trees can be used for both predicting numerical values (regression) and classifying data into categories. Decision trees use a branching sequence of linked decisions that can be represented with a tree diagram. One of the advantages of decision trees is that they are easy to validate and audit, unlike the black box of the neural network. Random forests: In a random forest, the machine learning algorithm predicts a value or category by combining the results from a number of decision trees. Real-world machine learning use cases Here are just a few examples of machine learning you might encounter every day:
Speech recognition: It is also known as automatic speech recognition (ASR), computer speech recognition, or speech-to-text, and it is a capability which uses natural language processing (NLP) to translate human speech into a written format. Many mobile devices incorporate speech recognition into their systems to conduct voice search—e.g. Siri—or improve accessibility for texting.
Customer service: Customer service: Online chatbots are replacing human agents along the customer journey, changing the way we think about customer engagement across websites and social media platforms. Chatbots answer frequently asked questions (FAQs) about topics such as shipping, or provide personalized advice, cross-selling products or suggesting sizes for users. Examples include virtual agents on e-commerce sites; messaging bots, using Slack and Facebook Messenger; and tasks usually done by virtual assistants and voice assistants.
Computer vision: This AI technology enables computers to derive meaningful information from digital images, videos, and other visual inputs, and then take the appropriate action. Powered by convolutional neural networks, computer vision has applications in photo tagging on social media, radiology imaging in healthcare, and self-driving cars in the automotive industry.
Recommendation engines: Using past consumption behavior data, AI algorithms can help to discover data trends that can be used to develop more effective cross-selling strategies. This approach is used by online retailers to make relevant product recommendations to customers during the checkout process.
Automated stock trading: Designed to optimize stock portfolios, AI-driven high-frequency trading platforms make thousands or even millions of trades per day without human intervention.
Fraud detection: Banks and other financial institutions can use machine learning to spot suspicious transactions. Supervised learning can train a model using information about known fraudulent transactions. Anomaly detection can identify transactions that look atypical and deserve further investigation.
Challenges of machine learning As machine learning technology has developed, it has certainly made our lives easier. However, implementing machine learning in businesses has also raised a number of ethical concerns about AI technologies. Some of these include:
Technological singularity While this topic garners a lot of public attention, many researchers are not concerned with the idea of AI surpassing human intelligence in the near future. Technological singularity is also referred to as strong AI or superintelligence. Philosopher Nick Bostrum defines superintelligence as “any intellect that vastly outperforms the best human brains in practically every field, including scientific creativity, general wisdom, and social skills.” Despite the fact that superintelligence is not imminent in society, the idea of it raises some interesting questions as we consider the use of autonomous systems, like self-driving cars. It’s unrealistic to think that a driverless car would never have an accident, but who is responsible and liable under those circumstances? Should we still develop autonomous vehicles, or do we limit this technology to semi-autonomous vehicles which help people drive safely? The jury is still out on this, but these are the types of ethical debates that are occurring as new, innovative AI technology develops.
AI impact on jobs While a lot of public perception of artificial intelligence centers around job losses, this concern should probably be reframed. With every disruptive, new technology, we see that the market demand for specific job roles shifts. For example, when we look at the automotive industry, many manufacturers, like GM, are shifting to focus on electric vehicle production to align with green initiatives. The energy industry isn’t going away, but the source of energy is shifting from a fuel economy to an electric one.
In a similar way, artificial intelligence will shift the demand for jobs to other areas. There will need to be individuals to help manage AI systems. There will still need to be people to address more complex problems within the industries that are most likely to be affected by job demand shifts, such as customer service. The biggest challenge with artificial intelligence and its effect on the job market will be helping people to transition to new roles that are in demand.
Privacy Privacy tends to be discussed in the context of data privacy, data protection, and data security. These concerns have allowed policymakers to make more strides in recent years. For example, in 2016, GDPR legislation was created to protect the personal data of people in the European Union and European Economic Area, giving individuals more control of their data. In the United States, individual states are developing policies, such as the California Consumer Privacy Act (CCPA), which was introduced in 2018 and requires businesses to inform consumers about the collection of their data. Legislation such as this has forced companies to rethink how they store and use personally identifiable information (PII). As a result, investments in security have become an increasing priority for businesses as they seek to eliminate any vulnerabilities and opportunities for surveillance, hacking, and cyberattacks.
Bias and discrimination Instances of bias and discrimination across a number of machine learning systems have raised many ethical questions regarding the use of artificial intelligence. How can we safeguard against bias and discrimination when the training data itself may be generated by biased human processes? While companies typically have good intentions for their automation efforts, Reuters (link resides outside IBM) ) highlights some of the unforeseen consequences of incorporating AI into hiring practices. In their effort to automate and simplify a process, Amazon unintentionally discriminated against job candidates by gender for technical roles, and the company ultimately had to scrap the project. Harvard Business Review (link resides outside IBM) has raised other pointed questions about the use of AI in hiring practices, such as what data you should be able to use when evaluating a candidate for a role.
Bias and discrimination aren’t limited to the human resources function either; they can be found in a number of applications from facial recognition software to social media algorithms.
As businesses become more aware of the risks with AI, they’ve also become more active in this discussion around AI ethics and values. For example, IBM has sunset its general purpose facial recognition and analysis products. IBM CEO Arvind Krishna wrote: “IBM firmly opposes and will not condone uses of any technology, including facial recognition technology offered by other vendors, for mass surveillance, racial profiling, violations of basic human rights and freedoms, or any purpose which is not consistent with our values and Principles of Trust and Transparency.”
Accountability Since there isn’t significant legislation to regulate AI practices, there is no real enforcement mechanism to ensure that ethical AI is practiced. The current incentives for companies to be ethical are the negative repercussions of an unethical AI system on the bottom line. To fill the gap, ethical frameworks have emerged as part of a collaboration between ethicists and researchers to govern the construction and distribution of AI models within society. However, at the moment, these only serve to guide. Some research (link resides outside IBM) (PDF, 1 MB) shows that the combination of distributed responsibility and a lack of foresight into potential consequences aren’t conducive to preventing harm to society.