In this course you will learn NLP with vector spaces.
You will
Get knowledge of
Sentiment analysis with logistic regression
Sentiment analysis with naive bayes
Vector space models
Machine translation and document search
Validate knowledge by answering a quiz by the end of each lecture
Be able to complete the course by ~2 hours.
Syllabus
Sentiment analysis with logistic regression
Supervised ML
Feature extraction
Logistic regression
Sentiment analysis with naive bayes
Bayes rule
Laplacian smoothing
Vector space models
Euclidean distance
Cosine similarity
PCA
Machine translation and document search
Word vectors
K-nearest neighbours
Approximating NN
Additional content
GPT-3
DALL-E
CLIP
Vector space model or term vector model is an algebraic model for representing text documents (and any objects, in general) as vectors of identifiers (such as index terms). It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a “reasonable” way (see inductive bias). This statistical quality of an algorithm is measured through the so-called generalization error.
The parallel task in human and animal psychology is often referred to as concept learning.
Machine learning (ML) can do everything from analyzing X-rays to predicting stock market prices to recommending binge-worthy television shows. With such a wide range of applications, it’s not surprising that the global machine learning market is projected to grow from $21.7 billion in 2022 to $209.91 billion by 2029, according to Fortune Business Insights.
At the core of machine learning are algorithms, which are trained to become the machine learning models used to power some of the most impactful innovations in the world today.
In this article, you’ll learn about 10 of the most popular machine learning algorithms that you’ll want to know, and explore the different learning styles used to turn machine learning algorithms into functioning machine learning models.
10 machine learning algorithms to know
In simple terms, a machine learning algorithm is like a recipe that allows computers to learn and make predictions from data. Instead of explicitly telling the computer what to do, we provide it with a large amount of data and let it discover patterns, relationships, and insights on its own.
From classification to regression, here are 10 algorithms you need to know in the field of machine learning:
1. Linear regression
Linear regression is a supervised learning algorithm used for predicting and forecasting values that fall within a continuous range, such as sales numbers or housing prices. It is a technique derived from statistics and is commonly used to establish a relationship between an input variable (X) and an output variable (Y) that can be represented by a straight line.
In simple terms, linear regression takes a set of data points with known input and output values and finds the line that best fits those points. This line, known as the “regression line,” serves as a predictive model. By using this line, we can estimate or predict the output value (Y) for a given input value (X).
Linear regression is primarily used for predictive modeling rather than categorization. It is useful when we want to understand how changes in the input variable affect the output variable. By analyzing the slope and intercept of the regression line, we can gain insights into the relationship between the variables and make predictions based on this understanding.
2. Logistic regression
Logistic regression, also known as “logit regression,” is a supervised learning algorithm primarily used for binary classification tasks. It is commonly employed when we want to determine whether an input belongs to one class or another, such as deciding whether an image is a cat or not a cat.
Logistic regression predicts the probability that an input can be categorized into a single primary class. However, in practice, it is commonly used to group outputs into two categories: the primary class and not the primary class. To accomplish this, logistic regression creates a threshold or boundary for binary classification. For example, any output value between 0 and 0.49 might be classified as one group, while values between 0.50 and 1.00 would be classified as the other group.
Consequently, logistic regression is typically used for binary categorization rather than predictive modeling. It enables us to assign input data to one of two classes based on the probability estimate and a defined threshold. This makes logistic regression a powerful tool for tasks such as image recognition, spam email detection, or medical diagnosis where we need to categorize data into distinct classes.
3. Naive Bayes
Naive Bayes is a set of supervised learning algorithms used to create predictive models for binary or multi-classification tasks. It is based on Bayes’ Theorem and operates on conditional probabilities, which estimate the likelihood of a classification based on the combined factors while assuming independence between them.
Let’s consider a program that identifies plants using a Naive Bayes algorithm. The algorithm takes into account specific factors such as perceived size, color, and shape to categorize images of plants. Although each of these factors is considered independently, the algorithm combines them to assess the probability of an object being a particular plant.
Naive Bayes leverages the assumption of independence among the factors, which simplifies the calculations and allows the algorithm to work efficiently with large datasets. It is particularly well-suited for tasks like document classification, email spam filtering, sentiment analysis, and many other applications where the factors can be considered separately but still contribute to the overall classification.
4. Decision tree
A decision tree is a supervised learning algorithm used for classification and predictive modeling tasks. It resembles a flowchart, starting with a root node that asks a specific question about the data. Based on the answer, the data is directed down different branches to subsequent internal nodes, which ask further questions and guide the data to subsequent branches. This process continues until the data reaches an end node, also known as a leaf node, where no further branching occurs.
Decision tree algorithms are popular in machine learning because they can handle complex datasets with ease and simplicity. The algorithm’s structure makes it straightforward to understand and interpret the decision-making process. By asking a sequence of questions and following the corresponding branches, decision trees enable us to classify or predict outcomes based on the data’s characteristics.
This simplicity and interpretability make decision trees valuable for various applications in machine learning, especially when dealing with complex datasets.
5. Random forest
A random forest algorithm is an ensemble of decision trees used for classification and predictive modeling. Instead of relying on a single decision tree, a random forest combines the predictions from multiple decision trees to make more accurate predictions.
In a random forest, numerous decision tree algorithms (sometimes hundreds or even thousands) are individually trained using different random samples from the training dataset. This sampling method is called “bagging.” Each decision tree is trained independently on its respective random sample.
Once trained, the random forest takes the same data and feeds it into each decision tree. Each tree produces a prediction, and the random forest tallies the results. The most common prediction among all the decision trees is then selected as the final prediction for the dataset.
Random forests address a common issue called “overfitting” that can occur with individual decision trees. Overfitting happens when a decision tree becomes too closely aligned with its training data, making it less accurate when presented with new data.
6. K-nearest neighbor (KNN)
K-nearest neighbor (KNN) is a supervised learning algorithm commonly used for classification and predictive modeling tasks. The name “K-nearest neighbor” reflects the algorithm’s approach of classifying an output based on its proximity to other data points on a graph.
Let’s say we have a dataset with labeled points, some marked as blue and others as red. When we want to classify a new data point, KNN looks at its nearest neighbors in the graph. The “K” in KNN refers to the number of nearest neighbors considered. For example, if K is set to 5, the algorithm looks at the 5 closest points to the new data point.
Based on the majority of the labels among the K nearest neighbors, the algorithm assigns a classification to the new data point. For instance, if most of the nearest neighbors are blue points, the algorithm classifies the new point as belonging to the blue group.
Additionally, KNN can also be used for prediction tasks. Instead of assigning a class label, KNN can estimate the value of an unknown data point based on the average or median of its K nearest neighbors.
7. K-means
K-means is an unsupervised learning algorithm commonly used for clustering and pattern recognition tasks. It aims to group data points based on their proximity to one another. Similar to K-nearest neighbor (KNN), K-means utilizes the concept of proximity to identify patterns or clusters in the data.
Each of the clusters is defined by a centroid, a real or imaginary center point for the cluster. K-means is useful on large data sets, especially for clustering, though it can falter when handling outliers.
K-means is particularly useful for large datasets and can provide insights into the inherent structure of the data by grouping similar points together. It has applications in various fields such as customer segmentation, image compression, and anomaly detection.
8. Support vector machine (SVM)
A support vector machine (SVM) is a supervised learning algorithm commonly used for classification and predictive modeling tasks. SVM algorithms are popular because they are reliable and can work well even with a small amount of data. SVM algorithms work by creating a decision boundary called a “hyperplane.” In two-dimensional space, this hyperplane is like a line that separates two sets of labeled data.
The goal of SVM is to find the best possible decision boundary by maximizing the margin between the two sets of labeled data. It looks for the widest gap or space between the classes. Any new data point that falls on either side of this decision boundary is classified based on the labels in the training dataset.
It’s important to note that hyperplanes can take on different shapes when plotted in three-dimensional space, allowing SVM to handle more complex patterns and relationships in the data.
9. Apriori
Apriori is an unsupervised learning algorithm used for predictive modeling, particularly in the field of association rule mining.
The Apriori algorithm was initially proposed in the early 1990s as a way to discover association rules between item sets. It is commonly used in pattern recognition and prediction tasks, such as understanding a consumer’s likelihood of purchasing one product after buying another.
The Apriori algorithm works by examining transactional data stored in a relational database. It identifies frequent itemsets, which are combinations of items that often occur together in transactions. These itemsets are then used to generate association rules. For example, if customers frequently buy product A and product B together, an association rule can be generated to suggest that purchasing A increases the likelihood of buying B.
By applying the Apriori algorithm, analysts can uncover valuable insights from transactional data, enabling them to make predictions or recommendations based on observed patterns of itemset associations.
10. Gradient boosting
Gradient boosting algorithms employ an ensemble method, which means they create a series of “weak” models that are iteratively improved upon to form a strong predictive model. The iterative process gradually reduces the errors made by the models, leading to the generation of an optimal and accurate final model.
The algorithm starts with a simple, naive model that may make basic assumptions, such as classifying data based on whether it is above or below the mean. This initial model serves as a starting point.
In each iteration, the algorithm builds a new model that focuses on correcting the mistakes made by the previous models. It identifies the patterns or relationships that the previous models struggled to capture and incorporates them into the new model.
Gradient boosting is effective in handling complex problems and large datasets. It can capture intricate patterns and dependencies that may be missed by a single model. By combining the predictions from multiple models, gradient boosting produces a powerful predictive model.
Get started in machine learning
With Machine Learning from DeepLearning.AI on Coursera, you’ll have the opportunity to learn essential machine learning concepts and techniques from industry experts. Develop the skills to build and deploy machine learning models, analyze data, and make informed decisions through hands-on projects and interactive exercises. Not only will you build confidence in applying machine learning in various domains, you could also open doors to exciting career opportunities in data science.
All of us make mistakes and (try to) learn from our experiences. Machine learning is pretty similar, but unlike us, machines can learn and improve automatically. There exist many types of ML techniques, all with different learning methods. What are those?
Machine learning (ML) has come a long way. It started as an algorithm that mimicked human thought processes. This idea was first described by logician Walter Pitts and neuroscientist Warren McCulloch in 1943. It has now emerged as a solid tech with applications in healthcare, eCommerce, finance, cybersecurity, digital marketing, and even food service.
These days, machine learning is a steadily developing field. According to Fortune Business Insights, the global ML market is expected to grow from $15.44 billion in 2021 and $21.17 billion in 2022 to $209.91 billion by 2029.
Let’s take a closer look at how machine learning works, what types of technology are out there, what machine learning techniques are used most frequently, and how they differ from each other.
How does machine learning work?
Machine learning uses computational methods to analyze data, identify patterns, learn from these patterns, and make predictions.
Basically, ML imitates humans — the more we learn and experience, the better and faster are the decisions and predictions we make. In the case of ML, it is “fed” with data. So, the more data it receives and processes, the more accurate the result will be.
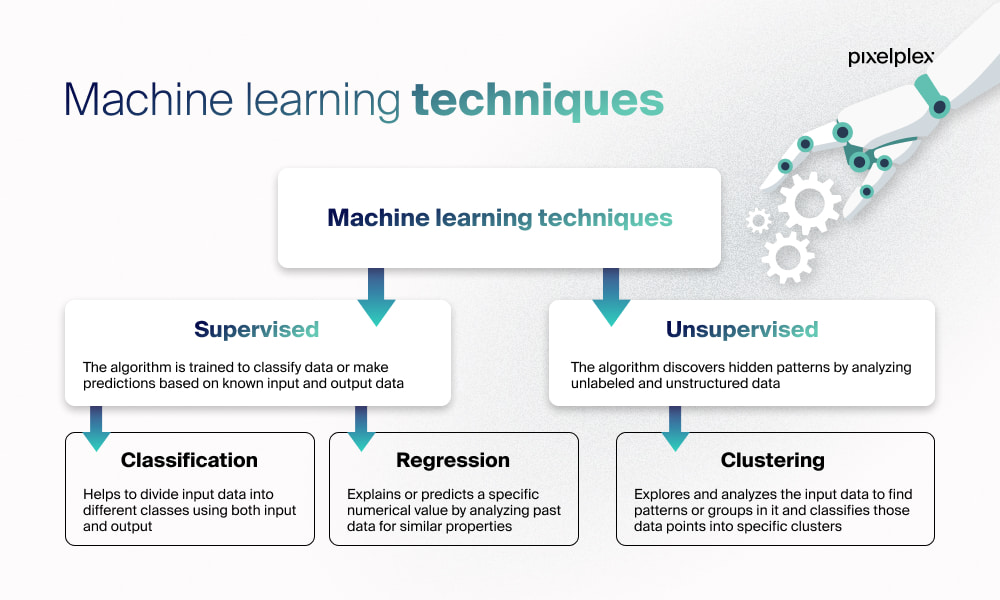
Machine learning categories
The majority of machine learning algorithms fall into the following categories: supervised machine learning methods, unsupervised machine learning techniques, semi-supervised learning, and reinforcement learning. The first two are the most common.
Supervised learning
Supervised learning implies that there is known data (input) and known responses to it (output), and the algorithm is trained to make predictions or classify data based on this information.
This type of machine learning requires large amounts of data. In the algorithm training process, the ways of processing data can be constantly adjusted and corrected until you get the desired outcomes. Once the algorithm is well-trained, it can generate reasoned responses to newly added data.
Unsupervised learning
Unsupervised learning works with unlabeled and unstructured data and helps discover hidden patterns in it. This type of learning requires neither large amounts of data nor human intervention.
Unsupervised learning is often used to categorize data or, for example, to find patterns in customer behavior and to recommend products that are similar to those already in the cart.
Semi-supervised learning
Semi-supervised learning makes use of all available data — usually small chunks of labeled and bigger amounts of unlabeled data. Part of the data can be classified manually. Then the algorithm will be able to sort the rest of the data in a more accurate way.
Reinforcement learning
Reinforcement learning trains itself from its own experience, without any training dataset. In this type of ML, the algorithm learns to behave in an uncertain environment, making various decisions and receiving feedback on its actions — positive or negative.
Check out PixelPlex’s portfolio of projects where we have successfully implemented ML and AI technology
3 main techniques of machine learning
The three most used machine learning techniques are classification, regression, and clustering. Classification and regression represent supervised learning, while clustering comes under the category of unsupervised ML. Let’s dive a little deeper and look at the differences between the three.
1. Classification
Classification is a machine learning technique that helps to divide input data into different classes. For example, it can decide whether there is a bicycle or a truck in a picture, or if an email is spam or not, or whether a tumor is cancerous or benign, and so on. Classification techniques can also help predict whether or not an online customer will make a purchase.
Companies often choose this type of ML technique when they need to automate and speed up workflows. By having data automatically classified, employees can focus on more important and complex tasks.
2. Regression
Machine learning regression methods are used to explain or predict a specific numerical value by analyzing past data for similar properties. For example, regression algorithms can assist businesses with forecasting retail demand, real estate prices, and required electricity load. They can even help optimize food procurement for restaurants.
3. Clustering
Clustering is the most popular type of unsupervised machine learning. This technique does not use any output information and does not require labeled data. It only explores and analyzes the input data to find patterns or groups in it and eventually classify those data points into specific clusters.
The clustering machine learning technique is especially useful in object recognition, market research, marketing campaigns, and recommendations for Internet users.
Find out more about how machine learning is applied in eCommerce and how it benefits this industry
Most common machine learning algorithms and their applications
There are dozens of different algorithms that fall under classification, regression, clustering, or other types of ML methods. Now it’s time for us to focus on the most popular among these machine learning algorithms to understand what they do and how they are used.
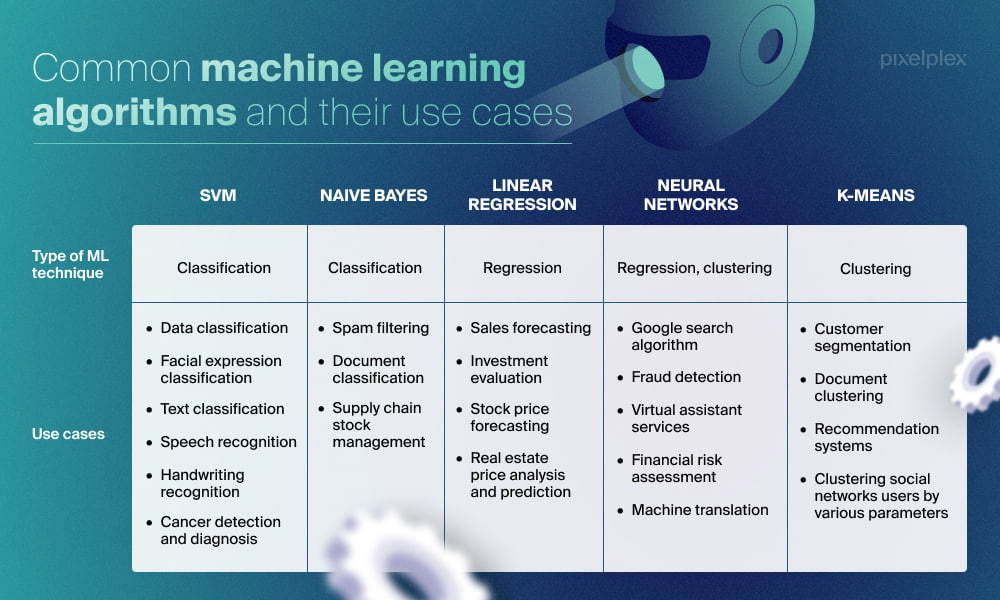
SVM
The SVM algorithm belongs to the classification machine learning method, but it can also be applied to regression.
The algorithm works really well in high dimensional spaces and can process all types of data: structured, unstructured, and semi-structured. However, it is not recommended for use with large data sets since it will take a lot of time to train the model. Another disadvantage is that the final model is quite difficult to interpret.
All in all, SVM is a very flexible and efficient algorithm that is often used to classify data, facial features and expressions, texts, and textures. In addition, SVM can recognize speech and handwriting and even detect cancer.
Naive Bayes
The Naive Bayes algorithm is another classification machine learning technique. This algorithm is very simple and easy to implement. As well as being fast, it is suitable for real-time forecasting.
Among other advantages, Naive Bayes doesn’t need a lot of training data to produce reliable results, and it scales easily with the number of predictors and data points. Additionally, the algorithm is noise resistant, which means that even if data has irrelevant features, these will not greatly affect the prediction accuracy.
Interestingly, one of the advantages can evolve into a disadvantage: because the algorithm avoids noise, it processes all predictors independently, which means that some of them are liable to be processed with a certain amount of bias.
Another drawback is that real-world applications of the Naive Bayes algorithm are limited. Generally, they include simple classifications such as filtering spam, classifying documents. It is also appropriate to use this algorithm for supply chain stock management.
If you need something more complex or sophisticated, it might be better not to go “naive” and instead choose another algorithm.
Linear regression
Linear regression is one of the most popular algorithms of the regression machine learning method. This algorithm is much faster at training than many other ML algorithms. It is also simple to implement and convenient to interpret.
What’s more, linear regression is highly scalable, does not require large computing resources, and works really well for linearly separable data.
As for disadvantages, linear regression can be sensitive to outliers and doesn’t handle noise and overfitting well. For all that this algorithm is exceptionally good at working with linear relationships, it is unfortunately limited purely to them.
Linear regression is used to analyze and describe data as well as to explain relationships between variables. Sales forecasting, investment evaluation, stock price forecasting, real estate price analysis and prediction are some of the most common applications of linear regression.
See how our ML-powered WatchDog solution is capable of protecting intellectual property
Neural networks
We can find neutral networks within both regression and clustering types of machine learning methods.
Basically, neural networks resemble the human brain, where each neuron is connected to another and together form a complex cognitive network capable of classifying problems, making decisions, and “thinking” artificially yet intelligently.
Neural networks have a multilayer structure: as soon as some neurons of one layer receive information, they transfer that knowledge to the neurons of the next layer.
Neural networks are good at working with incomplete knowledge and detecting complex nonlinear relationships between variables — both dependent and independent. They also provide good fault tolerance, are capable of parallel processing, and store information on the entire network.
At the same time, neural networks have their drawbacks, too. For example, you will need strong and quite costly hardware because neural networks require lots of computational power. What’s more, neural networks need large amounts of data in order to be trained properly.
One further fly in the ointment is that the results generated by neural networks can be difficult to explain.
Neural networks have found applications in multiple areas, with the Google search algorithm being one of the best known use cases. Neural networks can also be used for fraud detection, virtual assistant services, risk assessment, and machine translation.
K-means
Last but not least — the K-means algorithm. This algorithm is a part of the clustering machine learning method.
K-means is simple to implement and interpret. It is capable of scaling to large datasets and adapting to new examples quickly, easily and efficiently. The algorithm provides the outcomes in tight clusters, which is also a big plus.
One of the main drawbacks is that the K-means algorithm requires you to set the expected number of clusters at the very beginning, so the algorithm will largely depend on the initial settings and values. It also has trouble clustering data where clusters have different sizes and density, and it cannot handle noisy data and outliers.
Where can K-means clustering be used? It can be applied to customer segmentation, document clustering, and recommendation systems, as well as for clustering social networks users by their likes and dislikes.
Closing thoughts
Machine learning methods differ in how they analyze information, train a model, and provide results. Moreover, the decision about which one to choose depends on the industry your business belongs to and what goals you have set.
This is why it is important to find the right company — one that will not only consult you on what options are out there but also consider each and every detail of your future project, offer the most appropriate solution, and build it in partnership with you.
Fortunately, PixelPlex machine learning consultants and developers are ready to help you with your project from start to launch. Reach out to us today for immediate tech assistance!