A machine learning algorithm is a program code (math or program logic) that enables professionals to study, analyze, comprehend and explore large complex datasets. This article explains the fundamentals of machine learning algorithms and reveals the top 10 machine learning algorithms in 2022.
Table of Contents
What Is a Machine Learning Algorithm?
Top 10 Machine Learning Algorithms in 2022
What Is a Machine Learning Algorithm?
A machine learning algorithm refers to a program code (math or program logic) that enables professionals to study, analyze, comprehend, and explore large complex datasets. Each algorithm follows a series of instructions to accomplish the objective of making predictions or categorizing information by learning, establishing, and discovering patterns embedded in the data.
Types of Machine Learning
Machine learning algorithms specify rules and processes that a system should consider while addressing a specific problem. These algorithms analyze and simulate data to predict the result within a predetermined range. Moreover, as new data is fed into these algorithms, they learn, optimize, and improve based on the feedback on previous performance in predicting outcomes. In simple words, machine learning algorithms tend to become ‘smarter’ with each iteration.
Depending on the type of algorithm, machine learning models use several parameters such as gamma parameter, max_depth, n_neighbors, and others to analyze data and produce accurate results. These parameters are a consequence of training data that represents a larger dataset.
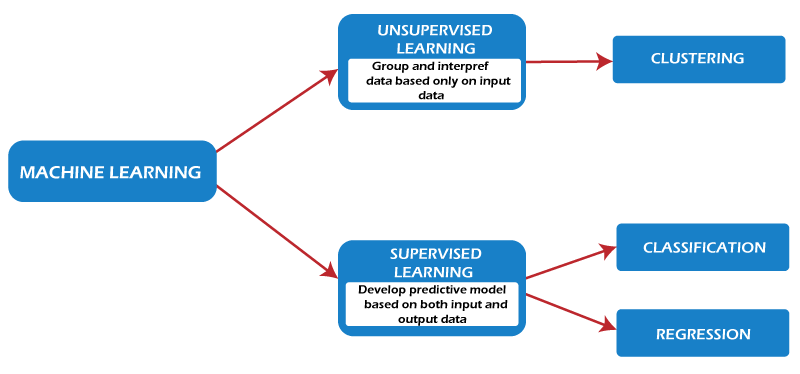
Machine learning algorithms are classified into four types based on the learning techniques: supervised, semi-supervised, unsupervised, and reinforcement learning. Regression and classification algorithms are the most popular options for predicting values, identifying similarities, and discovering unusual data patterns.
1. Supervised learning
Supervised learning algorithms use labeled datasets to make predictions. This learning technique is beneficial when you know the kind of result or outcome you intend to have.
For example, consider that you have a dataset that specifies the rain that occurred in a geographic area during a particular season over the past 200 years. You intend to know the expected rain during that specific season for the next ten years. Here, the outcome is derived based on the labels existing in the original dataset, i.e., rainfall, geographic area, season, and year.
2. Unsupervised learning
Unsupervised learning algorithms use unlabeled data. This learning technique labels the unlabeled data by categorizing the data or expressing its type, form, or structure. This technique comes in handy when the result type is unknown.
For example, when you use a dataset of Facebook users, you intend to classify users who show inclination (based on likes) toward similar Facebook ad campaigns. In this case, the dataset is unlabeled. However, the result will have labels as the algorithm will find similarities between data points while classifying the users.
3. Semi-supervised learning (SSL)
Semi-supervised learning algorithms combine the above two, where labeled and unlabeled data are used. The objective of these algorithms is to categorize unlabeled data based on the information derived from labeled data.
Consider the example of web content classification. Categorizing and classifying the content available on the internet is a time- and resource-intensive task. Apart from AI algorithms, it requires human resources to organize billions of web pages available online. In such cases, SSL models can play a crucial role in accomplishing the task efficiently.
4. Reinforcement learning
Reinforcement learning algorithms use the result or outcome as a benchmark to decide the next action step. In other words, these algorithms learn from previous outcomes, receive feedback after every step, and then decide whether to go ahead with the next step or not. The system learns whether it made a right, wrong, or neutral choice in the process. Automated systems can employ reinforcement learning as they are designed to make decisions with minimal human intervention.
For example, you design a self-driving car and intend to track whether the car is following traffic rules and ensuring safety on the roads. By applying reinforcement learning, the vehicle learns through experience and reinforcement tactics. The algorithm ensures that the car obeys traffic laws of staying in one lane, follows speed limits, and stops encountering pedestrians or animals on the road.
See More:What Is Artificial Intelligence (AI) as a Service? Definition, Architecture, and Trends
Top 10 Machine Learning Algorithms in 2022
Machine learning has significantly impacted our daily lives. Machine learning is omnipresent from smart assistants scheduling appointments, playing songs, and notifying users based on calendar events to NLP-based voice assistants. All such intelligent systems operate on machine learning algorithms.
In data science, each machine learning algorithm handles a specific problem. In some cases, professionals tend to opt for a combination of these algorithms as one algorithm may not be able to solve a particular problem.
Here, we look at the top 10 machine learning algorithms that are frequently used to achieve actual results.
1. Linear regression
Linear regression gives a relationship between input (x) and an output variable (y), also referred to as independent and dependent variables. Let’s understand the algorithm with an example where you are required to arrange a few plastic boxes of different sizes on separate shelves based on their corresponding weights.
The task is to be completed without manually weighing the boxes. Instead, you need to guess the weight just by observing the boxes’ height, dimensions, and sizes. In short, the entire task is driven based on visual analysis. Thus, you have to use a combination of visible variables to make the final arrangement on the shelves.
Linear regression in machine learning is of a similar kind, where the relationship between independent and dependent variables is established by fitting them to a regression line. This line has a mathematical representation given by the linear equation y = mx + c, where y represents the dependent variable, m = slope, x = independent variable, and b = intercept.
The objective of linear regression is to find the best fit line that reveals the relationship between variables y and x.
2. Logistic regression
The dependent variable is of binary type (dichotomous) in logistic regression. This type of regression analysis describes data and explains the relationship between one dichotomous variable and one or more independent variables.
Logistic regression is used in predictive analysis where pertinent data predict an event probability to a logit function. Thus, it is also called logit regression.
Mathematically, logistic regression is represented by the equation:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Here,
x = input value, y = predicted output, b0 = bias or intercept term, b1 = coefficient for input (x).
Logistic regression could be used to predict whether a particular team will win (1) the FIFA World Cup 2022 or not (0), or whether a lockdown will be imposed (1) due to rising COVID-19 cases or not (0). Thus, the binary outcomes of logistic regression facilitate faster decision-making as you only need to pick one out of the two alternatives.
3. Decision trees
With a decision tree, you can visualize the map of potential results for a series of decisions. It enables companies to compare possible outcomes and then take a straightforward decision based on parameters such as advantages and probabilities that are beneficial to them.
Decision tree algorithms can potentially anticipate the best option based on a mathematical construct and also come in handy while brainstorming over a specific decision. The tree starts with a root node (decision node) and then branches into sub-nodes representing potential outcomes.
Each outcome can further create child nodes that can open up other possibilities. The algorithm generates a tree-like structure that is used for classification problems. For example, consider the decision tree below that helps finalize a weekend plan based on the weather forecast.
Decision Tree
4. Support vector machines (SVMs)
Support vector machine algorithms are used to accomplish both classification and regression tasks. These are supervised machine learning algorithms that plot each piece of data in the n-dimensional space, with n referring to the number of features. Each feature value is associated with a coordinate value, making it easier to plot the features.
Moreover, classification is further performed by distinctly determining the hyper-plane that separates the two sets of support vectors or classes. A good separation ensures a good classification between the plotted data points.
Support Vector Machines
In simple words, SVMs represent the coordinates for individual observations. These are popular machine learning classifiers used in applications such as data classification, facial expression classification, text classification, steganography detection in digital images, speech recognition, and others.
5. Naive Bayes algorithm
Naive Bayes refers to a probabilistic machine learning algorithm based on the Bayesian probability model and is used to address classification problems. The fundamental assumption of the algorithm is that features under consideration are independent of each other and a change in the value of one does not impact the value of the other.
For example, you can consider a ball, a cricket ball, if it is red, round, has a 7.1-7.26 cm diameter, and has a mass of 156-163 g. Although all these features could be interdependent, each one contributes to the probability that it is a cricket ball. This is the reason the algorithm is referred to as ‘naïve’.
Let’s look at the mathematical representation of the algorithm.
If X, Y = probabilistic events, P (X) = probability of X being true, P(X|Y) = conditional probability of X being true in case Y is true.
Then, Bayes’ theorem is given by the equation:
P (X|Y) = (P (Y|X) x P (X)) /P (Y)
A naive Bayesian approach is easy to develop and implement. It is capable of handling massive datasets and is useful for making real-time predictions. Its applications include spam filtering, sentiment analysis and prediction, document classification, and others.
6. KNN classification algorithm
The K Nearest Neighbors (KNN) algorithm is used for both classification and regression problems. It stores all the known use cases and classifies new use cases (or data points) by segregating them into different classes. This classification is accomplished based on the similarity score of the recent use cases to the available ones.
KNN is a supervised machine learning algorithm, wherein ‘K’ refers to the number of neighboring points we consider while classifying and segregating the known n groups. The algorithm learns at each step and iteration, thereby eliminating the need for any specific learning phase. The classification is based on the neighbor’s majority vote.
The algorithm uses these steps to perform the classification:
For a training dataset, calculate the distance between the data points that are to be classified and the rest of the data points.
Choose the closest ‘K’ elements based on the distance or function used.
Consider a ‘majority vote’ between the K points–the class or label dominating all data points reveals the final ranking.
KNN
Real-life applications of KNN algorithms include facial recognition, text mining, and recommendation systems such as Amazon, Netflix, and others.
7. K-Means
K-Means is a distance-based unsupervised machine learning algorithm that accomplishes clustering tasks. In this algorithm, you classify datasets into clusters (K clusters) where the data points within one set remain homogenous, and the data points from two different clusters remain heterogeneous.
The clusters under K-Means are formed using these steps:
Initialization: The K-means algorithm selects centroids for each cluster (‘K’ number of points).
Assign objects to centroid: Clusters are formed with the closest centroids (K clusters) at each data point.
Centroid update: Create new centroids based on existing clusters and determine the closest distance for each data point based on new centroids. Here, the position of the centroid also gets updated whenever required.
Repeat: Repeat the process till the centroids do not change.
K-Means
K-Means clustering is useful in applications such as clustering Facebook users with common likes and dislikes, document clustering, segmenting customers who buy similar ecommerce products, etc.
8. Random forest algorithm
Random forest algorithms use multiple decision trees to handle classification and regression problems. It is a supervised machine learning algorithm where different decision trees are built on different samples during training. These algorithms help estimate missing data and tend to keep the accuracy intact in situations when a large chunk of data is missing in the dataset.
Random forest algorithms follow these steps:
Select random data samples from a given data set.
Build a decision tree for each data sample and provide the prediction result for each decision tree.
Carry out voting for each expected result.
Select the final prediction result based on the highest voted prediction result.
Random Forest Algorithm
This algorithm finds applications in finance, ecommerce (recommendation engines), computational biology (gene classification, biomarker discovery), and others.
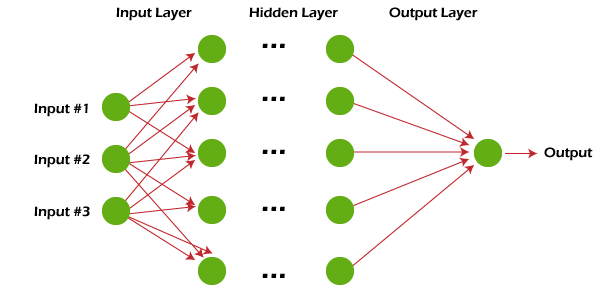
9. Artificial neural networks (ANNs)
Artificial neural networks are machine learning algorithms that mimic the human brain (neuronal behavior and connections) to solve complex problems. ANN has three or more interconnected layers in its computational model that process the input data.
The first layer is the input layer or neurons that send input data to deeper layers. The second layer is called the hidden layer. The components of this layer change or tweak the information received through various previous layers by performing a series of data transformations. These are also called neural layers. The third layer is the output layer that sends the final output data for the problem.
ANN algorithms find applications in smart home and home automation devices such as door locks, thermostats, smart speakers, lights, and appliances. They are also used in the field of computational vision, specifically in detection systems and autonomous vehicles.
10. Recurrent neural networks (RNNs)
Recurrent neural networks refer to a specific type of ANN that processes sequential data. Here, the result of the previous step acts as the input to the current step. This is facilitated via the hidden state that remembers information about a sequence. It acts as a memory that maintains the information on what was previously calculated. The memory of RNN reduces the overall complexity of the neural network.
Recurrent Neural Network
RNN analyzes time series data and possesses the ability to store, learn, and maintain contexts of any length. RNN is used in cases where time sequence is of paramount importance, such as speech recognition, language translation, video frame processing, text generation, and image captioning. Even Siri, Google Assistant, and Google Translate use the RNN architecture.
See More:What Is Logistic Regression? Equation, Assumptions, Types, and Best Practices
Takeaways
Machine learning algorithms tend to learn from observations. They analyze data, map input to output, and detect data patterns. The algorithms become smarter as they process more data, improving overall predictive performance.
Depending on the changing requirements and the complexity of the problems, new variants of existing machine learning algorithms continue to emerge. You can choose the algorithm that best suits your needs and get a head start on machine learning.
Machine learning is a data analytics technique that teaches computers to do what comes naturally to humans and animals: learn from experience. Machine learning algorithms use computational methods to directly “learn” from data without relying on a predetermined equation as a model.
As the number of samples available for learning increases, the algorithm adapts to improve performance. Deep learning is a special form of machine learning.
How does machine learning work?
Machine learning uses two techniques: supervised learning, which trains a model on known input and output data to predict future outputs, and unsupervised learning, which uses hidden patterns or internal structures in the input data.
Supervised learning
Supervised machine learning creates a model that makes predictions based on evidence in the presence of uncertainty. A supervised learning algorithm takes a known set of input data and known responses to the data (output) and trains a model to generate reasonable predictions for the response to the new data. Use supervised learning if you have known data for the output you are trying to estimate.
Supervised learning uses classification and regression techniques to develop machine learning models.
Classification models classify the input data. Classification techniques predict discrete responses. For example, the email is genuine, or spam, or the tumor is cancerous or benign. Typical applications include medical imaging, speech recognition, and credit scoring.
Use taxonomy if your data can be tagged, classified, or divided into specific groups or classes. For example, applications for handwriting recognition use classification to recognize letters and numbers. In image processing and computer vision, unsupervised pattern recognition techniques are used for object detection and image segmentation.
Common algorithms for performing classification include support vector machines (SVMs), boosted and bagged decision trees, k-nearest neighbors, Naive Bayes, discriminant analysis, logistic regression, and neural networks.
Regression techniques predict continuous responses – for example, changes in temperature or fluctuations in electricity demand. Typical applications include power load forecasting and algorithmic trading.
If you are working with a data range or if the nature of your response is a real number, such as temperature or the time until a piece of equipment fails, use regression techniques.
Common regression algorithms include linear, nonlinear models, regularization, stepwise regression, boosted and bagged decision trees, neural networks, and adaptive neuro-fuzzy learning.
Using supervised learning to predict heart attacks
Physicians want to predict whether someone will have a heart attack within a year. They have data on previous patients, including age, weight, height, and blood pressure. They know if previous patients had had a heart attack within a year. So the problem is to combine existing data into a model that can predict whether a new person will have a heart attack within a year.
Unsupervised Learning
Detects hidden patterns or internal structures in unsupervised learning data. It is used to eliminate datasets containing input data without labeled responses.
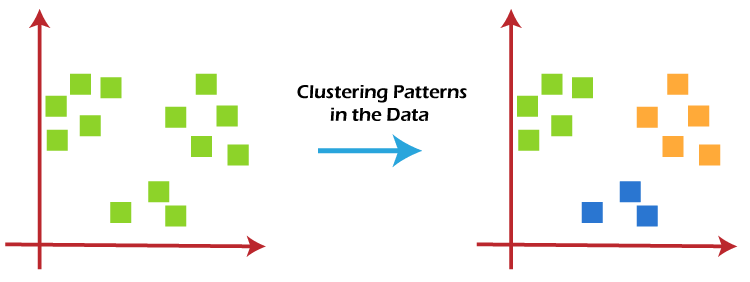
Clustering is a common unsupervised learning technique. It is used for exploratory data analysis to find hidden patterns and clusters in the data. Applications for cluster analysis include gene sequence analysis, market research, and commodity identification.
For example, if a cell phone company wants to optimize the locations where they build towers, they can use machine learning to predict how many people their towers are based on.
A phone can only talk to 1 tower at a time, so the team uses clustering algorithms to design the good placement of cell towers to optimize signal reception for their groups or groups of customers.
Common algorithms for performing clustering are k-means and k-medoids, hierarchical clustering, Gaussian mixture models, hidden Markov models, self-organizing maps, fuzzy C-means clustering, and subtractive clustering.
Ten methods are described and it is a foundation you can build on to improve your machine learning knowledge and skills:
Regression
Classification
Clustering
Dimensionality Reduction
Ensemble Methods
Neural Nets and Deep Learning
Transfer Learning
Reinforcement Learning
Natural Language Processing
Word Embedding’s
Let’s differentiate between two general categories of machine learning: supervised and unsupervised. We apply supervisedML techniques when we have a piece of data that we want to predict or interpret. We use the previous and output data to predict the output based on the new input.
For example, you can use supervised ML techniques to help a service business that wants to estimate the number of new users that will sign up for the service in the next month. In contrast, untrained ML looks at ways of connecting and grouping data points without using target variables to make predictions.
In other words, it evaluates data in terms of traits and uses traits to group objects that are similar to each other. For example, you can use unsupervised learning techniques to help a retailer who wants to segment products with similar characteristics-without specifying in advance which features to use.
1. Regression
Regression methods fall under the category of supervised ML. They help predict or interpret a particular numerical value based on prior data, such as predicting an asset’s price based on past pricing data for similar properties.
The simplest method is linear regression, where we use the mathematical equation of the line (y = m * x + b) to model the data set. We train a linear regression model with multiple data pairs (x, y) by computing the position and slope of a line that minimizes the total distance between all data points and the line. In other words, we calculate the slope (M) and the y-intercept (B) for a line that best approximates the observations in the data.
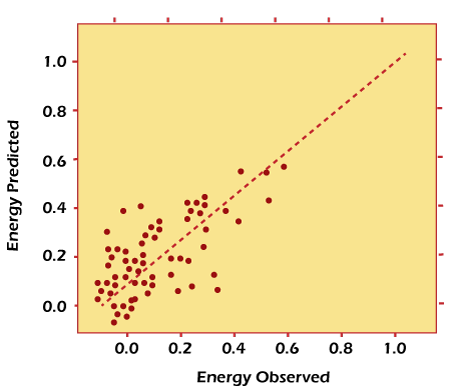
Let us consider a more concrete example of linear regression. I once used linear regression to predict the energy consumption (in kW) of some buildings by gathering together the age of the building, the number of stories, square feet, and the number of wall devices plugged in.
Since there was more than one input (age, square feet, etc.), I used a multivariable linear regression. The principle was similar to a one-to-one linear regression. Still, in this case, the “line” I created occurred in a multi-dimensional space depending on the number of variables.
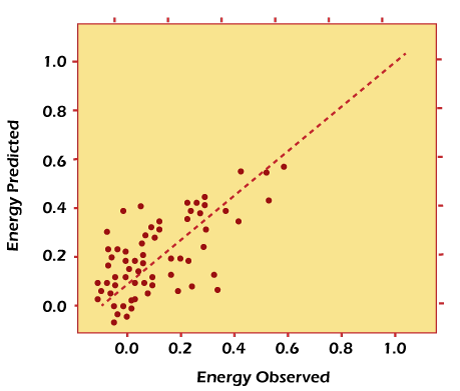
Now imagine that you have access to the characteristics of a building (age, square feet, etc.), but you do not know the energy consumption. In this case, we can use the fitted line to estimate the energy consumption of the particular building. The plot below shows how well the linear regression model fits the actual energy consumption of the building.
Note that you can also use linear regression to estimate the weight of each factor that contributes to the final prediction of energy consumed. For example, once you have a formula, you can determine whether age, size, or height are most important.
Linear regression model estimates of building energy consumption (kWh).
Regression techniques run the gamut from simple (linear regression) to complex (regular linear regression, polynomial regression, decision trees, random forest regression, and neural nets). But don’t get confused: start by studying simple linear regression, master the techniques, and move on.
2. Classification
In another class of supervised ML, classification methods predict or explain a class value. For example, they can help predict whether an online customer will purchase a product. Output can be yes or no: buyer or no buyer. But the methods of classification are not limited to two classes. For example, a classification method can help assess whether a given image contains a car or a truck. The simplest classification algorithm is logistic regression, which sounds like a regression method, but it is not. Logistic regression estimates the probability of occurrence of an event based on one or more inputs.
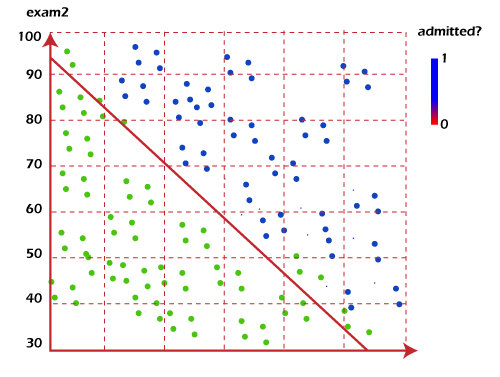
For example, logistic regression can take two test scores for a student to predict that the student will get admission to a particular college. Because the guess is a probability, the output is a number between 0 and 1, where 1 represents absolute certainty. For the student, if the predicted probability is greater than 0.5, we estimate that they will be admitted. If the predicted probability is less than 0.5, we estimate it will be rejected.
The chart below shows the marks of past students and whether they were admitted. Logistic regression allows us to draw a line that represents the decision boundary.
Because logistic regression is the simplest classification model, it is a good place to start for classification. As you progress, you can dive into nonlinear classifiers such as decision trees, random forests, support vector machines, and neural nets, among others.
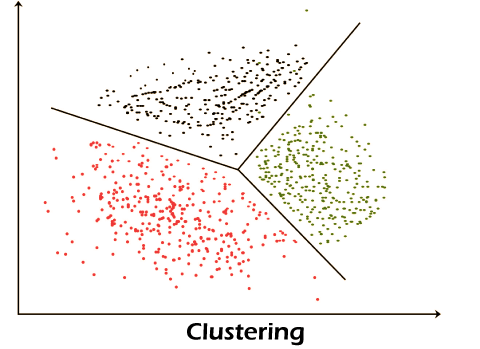
3. Clustering
We fall into untrained ML with clustering methods because they aim to group or group observations with similar characteristics. Clustering methods do not use the output information for training but instead let the algorithm define the output. In clustering methods, we can only use visualization to observe the quality of the solution.
The most popular clustering method is K-Means, where “K” represents the number of clusters selected by the user. (Note that there are several techniques for selecting the value of K, such as the elbow method.)
Randomly chooses K centers within the data.
Assigns each data point closest to the randomly generated centers.
Otherwise, we return to step 2. (To prevent ending in an infinite loop if the centers continue to change, set the maximum number of iterations in advance.)
The process is over if the centers do not change (or change very little).
The next plot applies the K-means to the building’s data set. The four measurements pertain to air conditioning, plug-in appliances (microwave, refrigerator, etc.), household gas, and heating gas. Each column of the plot represents the efficiency of each building.
Linear regression model estimates of building energy consumption (kWh).
Regression techniques run the gamut from simple (linear) to complex (regular linear, polynomial, decision trees, random forest, and neural nets). But don’t get confused: start by studying simple linear regression, master the techniques, and move on.
Clustering Buildings into Efficient (Green) and Inefficient (Red) Groups.
As you explore clustering, you will come across very useful algorithms such as Density-based Spatial Clustering of Noise (DBSCAN), Mean Shift Clustering, Agglomerative Hierarchical Clustering, and Expectation-Maximization Clustering using the Gaussian Mixture Model, among others.
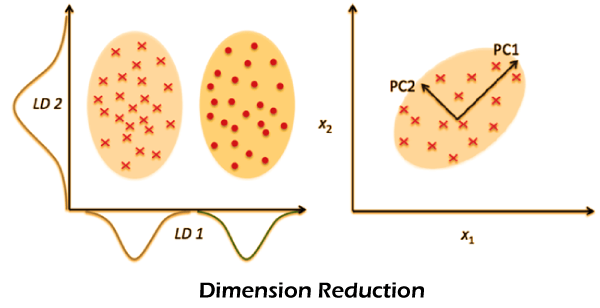
4. Dimensionality Reduction
We use dimensionality reduction to remove the least important information (sometimes unnecessary columns) from the data setFor example, and images may consist of thousands of pixels, which are unimportant to your analysis. Or, when testing microchips within the manufacturing process, you may have thousands of measurements and tests applied to each chip, many of which provide redundant information. In these cases, you need a dimensionality reduction algorithm to make the data set manageable.
The most popular dimensionality reduction method is Principal Component Analysis (PCA), which reduces the dimensionality of the feature space by finding new vectors that maximize the linear variance of the data. (You can also measure the extent of information loss and adjust accordingly.) When the linear correlations of the data are strong, PCA can dramatically reduce the dimension of the data without losing too much information.
Another popular method is t-stochastic neighbor embedding (t-SNE), which minimizes nonlinear dimensions. People usually use t-SNE for data visualization, but you can also use it for machine learning tasks such as feature space reduction and clustering, to mention a few.
The next plot shows the analysis of the MNIST database of handwritten digits. MNIST contains thousands of images of numbers 0 to 9, which the researchers use to test their clustering and classification algorithms. Each row of the data set is a vector version of the original image (size 28 x 28 = 784) and a label for each image (zero, one, two, three, …, nine). Therefore, we are reducing the dimensionality from 784 (pixels) to 2 (the dimensions in our visualization). Projecting to two dimensions allows us to visualize higher-dimensional original data sets.
5. Ensemble Methods
Imagine that you have decided to build a bicycle because you are not happy with the options available in stores and online. Once you’ve assembled these great parts, the resulting bike will outlast all other options.
Each model uses the same idea of combining multiple predictive models (supervised ML) to obtain higher quality predictions than the model.
For example, the Random Forest algorithm is an ensemble method that combines multiple decision trees trained with different samples from a data set. As a result, the quality of predictions of a random forest exceeds the quality of predictions predicted with a single decision tree.
Think about ways to reduce the variance and bias of a single machine learning model. By combining the two models, the quality of the predictions becomes balanced. With another model, the relative accuracy may be reversed. It is important because any given model may be accurate under some conditions but may be inaccurate under other conditions.
Most of the top winners of Kaggle competitions use some dressing method. The most popular ensemble algorithms are Random Forest, XGBoost, and LightGBM.
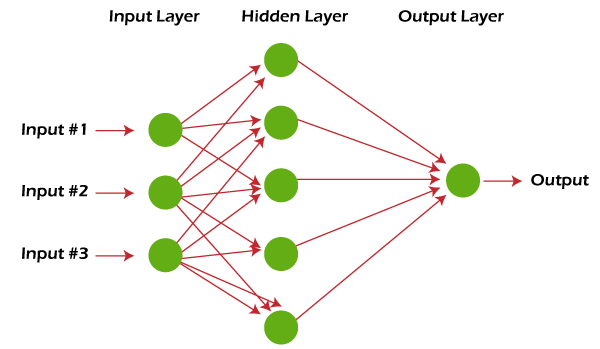
6. Neural networks and deep learning
Unlike linear and logistic regression, which is considered linear models, neural networks aim to capture nonlinear patterns in data by adding layers of parameters to the model. The simple neural net has three inputs as in the image below, a hidden layer with five parameters and an output layer.
Neural network with a hidden layer.
The neural network structure is flexible enough to construct our famous linear and logistic regression. The term deep learning comes from a neural net with many hidden layers and encompasses a variety of architectures.
It is especially difficult to keep up with development in deep learning as the research and industry communities redouble their deep learning efforts, spawning whole new methods every day.
Deep learning: A neural network with multiple hidden layers.
Deep learning techniques require a lot of data and computation power for best performance as this method is self-tuning many parameters within vast architectures. It quickly becomes clear why deep learning practitioners need powerful computers with GPUs (Graphical Processing Units).
In particular, deep learning techniques have been extremely successful in vision (image classification), text, audio, and video. The most common software packages for deep learning are Tensorflow and PyTorch.
7. Transfer learning
Let’s say you are a data scientist working in the retail industry. You’ve spent months training a high-quality model to classify images as shirts, t-shirts, and polos. Your new task is to create a similar model to classify clothing images like jeans, cargo, casual, and dress pants.
Transfer learning refers to reusing part of an already trained neural net and adapting it to a new but similar task. Specifically, once you train a neural net using the data for a task, you can move a fraction of the trained layers and combine them with some new layers that you can use for the new task. The new neural net can learn and adapt quickly to a new task by adding a few layers.
The advantage of transfer learning is that you need fewer data to train a neural net, which is especially important because training for deep learning algorithms is expensive in terms of both time and money.
The main advantage of transfer learning is that you need fewer data to train a neural net, which is especially important because training for deep learning algorithms is expensive both in terms of time and money (computational resources). Of course, it isn’t easy to find enough labeled data for training.
Let’s come back to your example and assume that you use a neural net with 20 hidden layers for the shirt model. After running a few experiments, you realize that you can move the 18 layers of the shirt model and combine them with a new layer of parameters to train on the pant images.
So the Pants model will have 19 hidden layers. The inputs and outputs of the two functions are different but reusable layers can summarize information relevant to both, for example, fabric aspects.
Transfer learning has become more and more popular, and there are many concrete pre-trained models now available for common deep learning tasks such as image and text classification.
8. Reinforcement Learning
Imagine a mouse in a maze trying to find hidden pieces of cheese. At first, the Mouse may move randomly, but after a while, the Mouse’s feel helps sense which actions bring it closer to the cheese. The more times we expose the Mouse to the maze, the better at finding the cheese.
Process for Mouse refers to what we do with Reinforcement Learning (RL) to train a system or game. Generally speaking, RL is a method of machine learning that helps an agent to learn from experience.
RL can maximize a cumulative reward by recording actions and using a trial-and-error approach in a set environment. In our example, the Mouse is the agent, and the maze is the environment. The set of possible actions for the Mouse is: move forward, backward, left, or right. The reward is cheese.
You can use RL when you have little or no historical data about a problem, as it does not require prior information (unlike traditional machine learning methods). In the RL framework, you learn from the data as you go. Not surprisingly, RL is particularly successful with games, especially games of “correct information” such as chess and Go. With games, feedback from the agent and the environment comes quickly, allowing the model to learn faster. The downside of RL is that it can take a very long time to train if the problem is complex.
As IBM’s Deep Blue beat the best human chess player in 1997, the RL-based algorithm AlphaGo beat the best Go player in 2016. The current forerunners of RL are the teams of DeepMind in the UK.
In April 2019, the OpenAI Five team was the first AI to defeat the world champion team of e-sport Dota 2, a very complex video game that the OpenAI Five team chose because there were no RL algorithms capable of winning it. You can tell that reinforcement learning is a particularly powerful form of AI, and we certainly want to see more progress from these teams. Still, it’s also worth remembering the limitations of the method.
9. Natural Language Processing
A large percentage of the world’s data and knowledge is in some form of human language. For example, we can train our phones to autocomplete our text messages or correct misspelled words. We can also teach a machine to have a simple conversation with a human.
Natural Language Processing (NLP) is not a machine learning method but a widely used technique for preparing text for machine learning. Think of many text documents in different formats (Word, online blog). Most of these text documents will be full of typos, missing characters, and other words that need to be filtered out. At the moment, the most popular package for processing text is NLTK (Natural Language Toolkit), created by Stanford researchers.
The easiest way to map text to a numerical representation is to count the frequency of each word in each text document. Think of a matrix of integers where each row represents a text document, and each column represents a word. This matrix representation of the term frequency is usually called the term frequency matrix (TFM). We can create a more popular matrix representation of a text document by dividing each entry on the matrix by the weighting of how important each word is in the entire corpus of documents. We call this method Term Frequency Inverse Document Frequency (TFIDF), and it generally works better for machine learning tasks.
10. Word Embedding
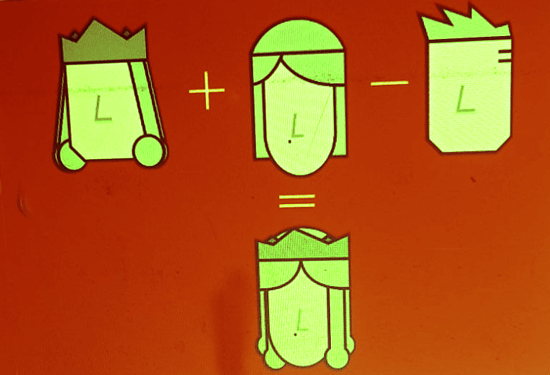
TFM and TFIDF are numerical representations of text documents that consider only frequency and weighted frequencies to represent text documents. In contrast, word embedding can capture the context of a word in a document. As with word context, embeddings can measure similarity between words, allowing us to perform arithmetic with words.
Word2Vec is a neural net-based method that maps words in a corpus to a numerical vector. We can then use these vectors to find synonyms, perform arithmetic operations with words, or represent text documents (by taking the mean of all word vectors in the document). For example, we use a sufficiently large corpus of text documents to estimate word embeddings.
Let’s say vector(‘word’) is the numeric vector representing the word ‘word’. To approximate the vector (‘female’), we can perform an arithmetic operation with the vectors:
The word representation allows finding the similarity between words by computing the cosine similarity between the vector representations of two words. The cosine similarity measures the angle between two vectors.
We calculate word embedding’s using machine learning methods, but this is often a pre-stage of implementing machine learning algorithms on top. For example, let’s say we have access to the tweets of several thousand Twitter users. Let’s also assume that we know which Twitter users bought the house. To estimate the probability of a new Twitter user buying a home, we can combine Word2Vec with logistic regression.
You can train the word embedding yourself or get a pre-trained (transfer learning) set of word vectors. To download pre-trained word vectors in 157 different languages, look at Fast Text.
Summary
Studying these methods thoroughly and fully understanding the basics of each can serve as a solid starting point for further study of more advanced algorithms and methods.
There is no best way or one size fits all. Finding the right algorithm is partly just trial and error – even highly experienced data scientists can’t tell whether an algorithm will work without trying it out. But algorithmic selection also depends on the size and type of data you’re working with, the insights you want to derive from the data, and how those insights will be used.
A machine learning model is a program that can find patterns or make decisions from a previously unseen dataset. For example, in natural language processing, machine learning models can parse and correctly recognize the intent behind previously unheard sentences or combinations of words. In image recognition, a machine learning model can be taught to recognize objects – such as cars or dogs. A machine learning model can perform such tasks by having it ‘trained’ with a large dataset. During training, the machine learning algorithm is optimized to find certain patterns or outputs from the dataset, depending on the task. The output of this process – often a computer program with specific rules and data structures – is called a machine learning model.
What is a machine learning Algorithm?
A machine learning algorithm is a mathematical method to find patterns in a set of data. Machine Learning algorithms are often drawn from statistics, calculus, and linear algebra. Some popular examples of machine learning algorithms include linear regression, decision trees, random forest, and XGBoost.
What is Model Training in machine learning?
The process of running a machine learning algorithm on a dataset (called training data) and optimizing the algorithm to find certain patterns or outputs is called model training. The resulting function with rules and data structures is called the trained machine learning model.
What are the different types of Machine Learning?
In general, most machine learning techniques can be classified into supervised learning, unsupervised learning, and reinforcement learning.
What is Supervised Machine Learning?
In supervised machine learning, the algorithm is provided an input dataset, and is rewarded or optimized to meet a set of specific outputs. For example, supervised machine learning is widely deployed in image recognition, utilizing a technique called classification. Supervised machine learning is also used in predicting demographics such as population growth or health metrics, utilizing a technique called regression.
What is Unsupervised Machine Learning?
In unsupervised machine learning, the algorithm is provided an input dataset, but not rewarded or optimized to specific outputs, and instead trained to group objects by common characteristics. For example, recommendation engines on online stores rely on unsupervised machine learning, specifically a technique called clustering.
What is Reinforcement Learning?
In reinforcement learning, the algorithm is made to train itself using many trial and error experiments. Reinforcement learning happens when the algorithm interacts continually with the environment, rather than relying on training data. One of the most popular examples of reinforcement learning is autonomous driving.
What are the different machine learning models?
There are many machine learning models, and almost all of them are based on certain machine learning algorithms. Popular classification and regression algorithms fall under supervised machine learning, and clustering algorithms are generally deployed in unsupervised machine learning scenarios.
Supervised Machine Learning
Logistic Regression: Logistic Regression is used to determine if an input belongs to a certain group or not
SVM: SVM, or Support Vector Machines create coordinates for each object in an n-dimensional space and uses a hyperplane to group objects by common features
Naive Bayes: Naive Bayes is an algorithm that assumes independence among variables and uses probability to classify objects based on features
Decision Trees: Decision trees are also classifiers that are used to determine what category an input falls into by traversing the leaf’s and nodes of a tree
Linear Regression: Linear regression is used to identify relationships between the variable of interest and the inputs, and predict its values based on the values of the input variables.
kNN: The k Nearest Neighbors technique involves grouping the closest objects in a dataset and finding the most frequent or average characteristics among the objects.
Random Forest: Random forest is a collection of many decision trees from random subsets of the data, resulting in a combination of trees that may be more accurate in prediction than a single decision tree.
Boosting algorithms: Boosting algorithms, such as Gradient Boosting Machine, XGBoost, and LightGBM, use ensemble learning. They combine the predictions from multiple algorithms (such as decision trees) while taking into account the error from the previous algorithm.
Unsupervised Machine Learning
K-Means: The K-Means algorithm finds similarities between objects and groups them into K different clusters.
Hierarchical Clustering: Hierarchical clustering builds a tree of nested clusters without having to specify the number of clusters.
What is a Decision Tree in Machine Learning (ML)?
A Decision Tree is a predictive approach in ML to determine what class an object belongs to. As the name suggests, a decision tree is a tree-like flow chart where the class of an object is determined step-by-step using certain known conditions.
A decision tree visualized in the Databricks
What is Regression in Machine Learning?
Regression in data science and machine learning is a statistical method that enables predicting outcomes based on a set of input variables. The outcome is often a variable that depends on a combination of the input variables.
A linear regression model performed on the Databricks
What is a Classifier in Machine Learning?
A classifier is a machine learning algorithm that assigns an object as a member of a category or group. For example, classifiers are used to detect if an email is spam, or if a transaction is fraudulent.
How many models are there in machine learning?
Many! Machine learning is an evolving field and there are always more machine learning models being developed.
What is the best model for machine learning?
The machine learning model most suited for a specific situation depends on the desired outcome. For example, to predict the number of vehicle purchases in a city from historical data, a supervised learning technique such as linear regression might be most useful. On the other hand, to identify if a potential customer in that city would purchase a vehicle, given their income and commuting history, a decision tree might work best.
What is model deployment in Machine Learning (ML)?
Model deployment is the process of making a machine learning model available for use on a target environment—for testing or production. The model is usually integrated with other applications in the environment (such as databases and UI) through APIs. Deployment is the stage after which an organization can actually make a return on the heavy investment made in model development.
A full machine learning model lifecycle on the Databricks Lakehouse.
What are Deep Learning Models?
Deep learning models are a class of ML models that imitate the way humans process information. The model consists of several layers of processing (hence the term ‘deep’) to extract high-level features from the data provided. Each processing layer passes on a more abstract representation of the data to the next layer, with the final layer providing a more human-like insight. Unlike traditional ML models which require data to be labeled, deep learning models can ingest large amounts of unstructured data. They are used to perform more human-like functions such as facial recognition and natural language processing.
A simplified representation of deep learning.Source: https://www.databricks.com/discover/pages/the-democratization-of-artificial-intelligence-and-deep-learning
What is Time Series Machine Learning?
A time-series machine learning model is one in which one of the independent variables is a successive length of time minutes, days, years etc.), and has a bearing on the dependent or predicted variable. Time series machine learning models are used to predict time-bound events, for example – the weather in a future week, expected number of customers in a future month, revenue guidance for a future year, and so on.
Where can I learn more about machine learning?
Check out this free eBook to discover the many fascinating machine learning use-cases being deployed by enterprises globally.
To get a deeper understanding of machine learning from the experts, check out the Databricks Machine Learning blog.