Get a comprehensive understanding of what Machine Learning is
Experience Machine Learning in practice through real world case studies
Get a broad overview of different Machine Learning models
Requirements
None
Description
Are you a beginner looking to get started with Machine Learning? This course offers a gentle introduction to Machine Learning through real world case studies as you invent your first Machine Learning algorithm.
This course gives you a broad overview of the variety of Machine Learning models and provides a learning ladder to continue learning. It also presents applications that use Machine Learning and details a plethora of techniques that are used to evolve Machine Learning models from data.
This course presents data for a simple case study of classifying emails automatically. It provides the data set, identifies features ans labels and presents the intuition behind any Machine Learning algorithm. The course goes on to talk about both the (i) Supervised and (ii) Unsupervised learning models. It presents an analysis of over fitting and under fitting in models.
The course aims to motivate a beginner to get started with their Machine Learning journey. This course will be further supplemented with focused sessions on various regression, classification and clustering algorithms.
The subsequent sessions will get in to the Math behind the algorithm while solving a real world case study. Students who continue this course through the recommended ladder will eventually have the skills to build and deploy Machine Learning models to production.
Who this course is for:
Any software developer wanting to begin their journey in Machine Learning and Artificial Intelligence
Machine Learning tutorial provides basic and advanced concepts of machine learning. Our machine learning tutorial is designed for students and working professionals.
Machine learning is a growing technology which enables computers to learn automatically from past data. Machine learning uses various algorithms for building mathematical models and making predictions using historical data or information. Currently, it is being used for various tasks such as image recognition, speech recognition, email filtering, Facebook auto-tagging, recommender system, and many more.
This machine learning tutorial gives you an introduction to machine learning along with the wide range of machine learning techniques such as Supervised, Unsupervised, and Reinforcement learning. You will learn about regression and classification models, clustering methods, hidden Markov models, and various sequential models.
When you tag a face in a Facebook photo, it is AI that is running behind the scenes and identifying faces in a picture. Face tagging is now omnipresent in several applications that display pictures with human faces. Why just human faces? There are several applications that detect objects such as cats, dogs, bottles, cars, etc. We have autonomous cars running on our roads that detect objects in real time to steer the car. When you travel, you use Google Directions to learn the real-time traffic situations and follow the best path suggested by Google at that point of time. This is yet another implementation of object detection technique in real time.
Let us consider the example of Google Translate application that we typically use while visiting foreign countries. Google’s online translator app on your mobile helps you communicate with the local people speaking a language that is foreign to you.
There are several applications of AI that we use practically today. In fact, each one of us use AI in many parts of our lives, even without our knowledge. Today’s AI can perform extremely complex jobs with a great accuracy and speed. Let us discuss an example of complex task to understand what capabilities are expected in an AI application that you would be developing today for your clients.
Example
We all use Google Directions during our trip anywhere in the city for a daily commute or even for inter-city travels. Google Directions application suggests the fastest path to our destination at that time instance. When we follow this path, we have observed that Google is almost 100% right in its suggestions and we save our valuable time on the trip.
You can imagine the complexity involved in developing this kind of application considering that there are multiple paths to your destination and the application has to judge the traffic situation in every possible path to give you a travel time estimate for each such path. Besides, consider the fact that Google Directions covers the entire globe. Undoubtedly, lots of AI and Machine Learning techniques are in-use under the hoods of such applications.
Considering the continuous demand for the development of such applications, you will now appreciate why there is a sudden demand for IT professionals with AI skills.
You’ll receive the completely annotated Jupyter Notebook used in the course.
You’ll be able to define and give examples of the top libraries in Python used to build real world predictive models.
You will be able to create models with the most powerful language for machine learning there is.
You’ll understand the supervised predictive modeling process and learn the core vernacular at a high level.
Requirements
There are no prerequisites however knowledge of Python will be helpful.
A familiarity with the concepts of machine learning would be helpful but aren’t necessary.
Description
Recent Review from Similar Course:
“This was one of the most useful classes I have taken in a long time. Very specific, real-world examples. It covered several instances of ‘what is happening’, ‘what it means’ and ‘how you fix it’. I was impressed.” Steve
Welcome to The Top 5 Machine Learning Libraries in Python. This is an introductory course on the process of building supervised machine learning models and then using libraries in a computer programming language called Python.
What’s the top career in the world? Doctor? Lawyer? Teacher? Nope. None of those.
The top career in the world is the data scientist. Great. What’s a data scientist?
The area of study which involves extracting knowledge from data is called Data Science and people practicing in this field are called as Data Scientists.
Business generate a huge amount of data. The data has tremendous value but there so much of it where do you begin to look for value that is actionable? That’s where the data scientist comes in. The job of the data scientist is to create predictive models that can find hidden patterns in data that will give the business a competitive advantage in their space.
Don’t I need a PhD? Nope. Some data scientists do have PhDs but it’s not a requirement. A similar career to that of the data scientist is the machine learning engineer.
A machine learning engineer is a person who builds predictive models, scores them and then puts them into production so that others in the company can consume or use their model. They are usually skilled programmers that have a solid background in data mining or other data related professions and they have learned predictive modeling.
In the course we are going to take a look at what machine learning engineers do. We are going to learn about the process of building supervised predictive models and build several using the most widely used programming language for machine learning. Python. There are literally hundreds of libraries we can import into Python that are machine learning related.
A library is simply a group of code that lives outside the core language. We “import it” into our work space when we need to use its functionality. We can mix and match these libraries like Lego blocks.
Thanks for your interest in the The Top 5 Machine Learning Libraries in Python and we will see you in the course.
Who this course is for:
If you’re looking to learn machine learning then this course is for you.
Overview of Supervised, Unsupervised, and Reinforcement Learning
Requirements
Interest in machine learning
Description
Course Outcome:
Learners completing this course will be able to give definitions and explain the types of problems that can be solved by the 3 broad areas of machine learning: Supervised, Unsupervised, and Reinforcement Learning.
Course Topics and Approach:
This course gives a gentle introduction to the 3 broad areas of machine learning: Supervised, Unsupervised, and Reinforcement Learning. The goal is to explain the key ideas using examples with many plots and animations and little math, so that the material can be accessed by a wide range of learners. The lectures are supplemented by Python demos, which show machine learning in action. Learners are encouraged to experiment with the course demo codes. Additionally, information about machine learning resources is provided, including sources of data and publicly available software packages.
Course Audience:
This course has been designed for ALL LEARNERS!!!
Course does not go into detail into the underlying math, so no specific math background is required
No previous experience with machine learning is required
No previous experience with Python (or programming in general) is required to be able to experiment with the course demo codes
Teaching Style and Resources:
Course includes many examples with plots and animations used to help students get a better understanding of the material
All resources, including course codes, Powerpoint presentations, info on additional resources, can be downloaded from the course Github site
Python Demos:
There are several options for running the Python demos:
Run online using Google Colab (With this option, demo codes can be run completely online, so no downloads are required. A Google account is required.)
Run on local machine using the Anaconda platform (This is probably best approach for those who would like to run codes locally, but don’t have python on their local machine. Demo video shows where to get free community version of Anaconda platform and how to run the codes.)
Run on local machine using python (This approach may be most suitable for those who already have python on their machines)
2021.09.28 Update
Section 5: update course codes, Powerpoint presentations, and videos so that codes are compatible with more recent versions of the Anaconda platform and plotting package
Who this course is for:
People curious about machine learning and data science
Supervised and Unsupervised Learning in Machine Learning with Real life Examples
Applications of Data Science in Real Life
What is Data Engineering
Who is a Data Engineer
What is Machine Learning
Who is a Machine Learning Engineer
Skills Needed to become a Data scientist
How to Practice Data Science and Build your portfolio
Certifications in Data Science
Some Great Books in Data Science
Requirements
Laptop or PC
A Good Connection to the internet
Passion to Learn about Data Science
Description
Data science and machine learning is one of the hottest fields in the market and has a bright future
In the past ten years, many courses have appeared that explains the field in a more practical way than in theory
During my experience in counseling and mentoring, I faced many obstacles, the most important of which was the existence of educational gaps for the learner, and most of the gaps were in the theoretical field.
To fill this gap, I made this course, Thank God, this course helped many students to properly understand the field of data science.
If you have no idea what the field of data science is and are looking for a very quick introduction to data science, this course will help you become familiar with and understand some of the main concepts underlying data science.
If you are an expert in the field of data science, then attending this course will give you a general overview of the field
This short course will lay a strong foundation for understanding the most important concepts taught in advanced data science courses, and this course will be very suitable if you do not have any idea about the field of data science and want to start learning data science from scratch
Students will learn about the types of machine learning addressed in Python’s library, sklearn.
Students will learn about supervised learning.
Students will learn about semi-supervised learning.
Students will learn about unsupervised learning.
Students will learn about sklearn’s models used in supervised learning, semi-supervised learning and unsupervised learning.
Students will learn about dimensionality reduction and sklearn functions that adress this.
Students will learn about feature selection and sklearn functions that address this.
Students will learn about data preprocessing and sklearn functions that address this.
Students will learn about hyperparameter tuning and sklearn functions that address this.
Students will learn about goodness of fit tests and sklearn functions that address this.
Requirements
No programming experience is needed, but it would be helpful to know basic Python programming.
Description
This course covers over 27 functions in Python’s machine learning library, sklearn. The functions covered in this course take the student through the entire machine learning life cycle.
The student will learn the types of learning that are part of sklearn, to include supervised, semi-supervised and unsupervised learning.
The student will learn about the types of estimators used in supervised, semi-supervised and unsupervised learning, to include classification and regression.
The student will learn about a variety of supervised learning estimators to include linear regression, logistic regression, decision tree, random forrest, naive bayes, support vector machine, k nearest neighbour, and neural network.
The student will learn about sklearn’s three semi-supervised functions to make predictions on classification problems.
the student will learn about some of the estimators used to make predictions on unsupervised learning, to include k means, hierarchical and Gaussian method.
The student will learn about dimensionality reduction and feature selection as a means of reducing the number of features in the dataset.
The student will learn about the different functions in sklearn that carry out preprocessing activities to include standardisation, normalisation, encoding and imputation.
The student will learn about hyperparameter tuning and how to perform a grid search on the different parameters in the model to help it work at peak optimisation.
The student will learn about goodness of fit tests, to include root mean squared error, accuracy score, confusion matrix, and classification report, which tell the user how well the model has performed.
The students will receive additional learning and cover the machine learning life cycle to enable him to initiate how own machine learning project using sklearn.
Who this course is for:
Beginner Python developers who would like to know how to undertake machine learning using Python’s sklearn library.
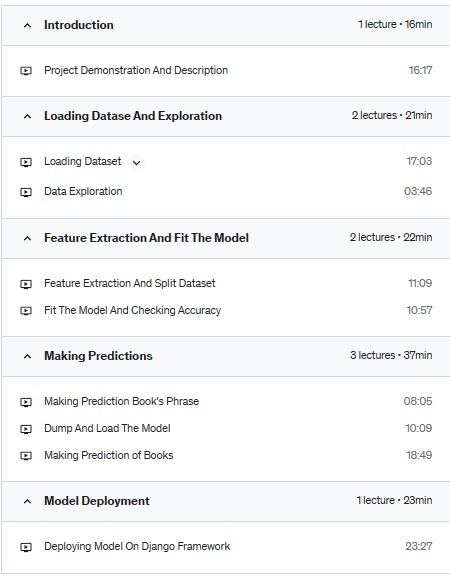
Use pickle to dump the model and vectorizer in the disk
Deploy machine learning model on Django
Requirements
Python, Django And Machine Learning Basics
Description
Become Artificial Intelligence Engineer.
This is a step-by-step course on how to create book classification using machine learning. It covers Numpy, Pandas, Matplotlib, Scikit learns, and Django, and at the end predictive model is deployed on Django. Most of the things machine learning beginners do not know is how they can deploy a created model. How to put created model into the application? The training model and get 80%, 85%, or 90% accuracy does not matter. As Artificial Intelligence Engineer you should be able to put created model into the application.
Actually, learning how to deploy a Machine Learning model created by machine learning is a big win for you and is a motivating effect towards improving, embracing, and learning machine learning. The piece me off when I hear people saying Artificial Intelligence is not really. It is just a theoretical study. Let’s learn together how to deploy models, solve people’s problems and change people’s minds about Artificial Intelligence.
At the end of this course, you will become Artificial Intelligence by your ability to put created models into the application and solve people’s problems. Not only that you will be exposed to a few concepts of Django which are Python web framework and current trending web framework. By understanding Django, you will be able to deploy the previously created model you could not in the previous time.
Who this course is for:
Python Developers interested with machine learning
Configure and use the Unity Machine Learning Agents toolkit to solve physical problems in simulated environments
Understand the concepts of neural networks, supervised and deep reinforcement learning (PPO)
Apply ML control techniques to teach a go-kart to drive around a track in Unity
Requirements
Basic algebra and basic programming skills
Description
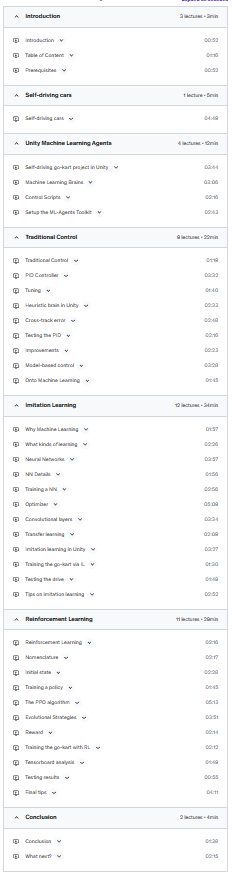
WARNING: take this class as a gentle introduction to machine learning, with particular focus on machine vision and reinforcement learning. The Unity project provided in this course is now obsolete because the Unity ML agents library is still in its beta version and the interface keeps changing all the time! Some of the implementation details you will find in this course will look different if you are using the latest release, but the key concepts and the background theory are still valid. Please refer to the official migrating documentation on the ml-agents github for the latest updates.
Learn how to combine the beauty of Unity with the power of Tensorflow to solve physical problems in a simulated environment with state-of-the-art machine learning techniques.
We study the problem of a go-kart racing around a simple track and try three different approaches to control it: a simple PID controller; a neural network trained via imitation (supervised) learning; and a neural network trained via deep reinforcement learning.
Each technique has its strengths and weaknesses, which we first show in a theoretical way at simple conceptual level, and then apply in a practical way. In all three cases the go-kart will be able to complete a lap without crashing.
We provide the Unity template and the files for all three solutions. Then see if you can build on it and improve performance further more.
Buckle up and have fun!
Who this course is for:
Students interested in a quick jump into machine learning, focusing on the application rather than the theory
Engineers looking for a machine learning realistic simulator
Python, business and accounting understanding and keen to learn attitude.
Description
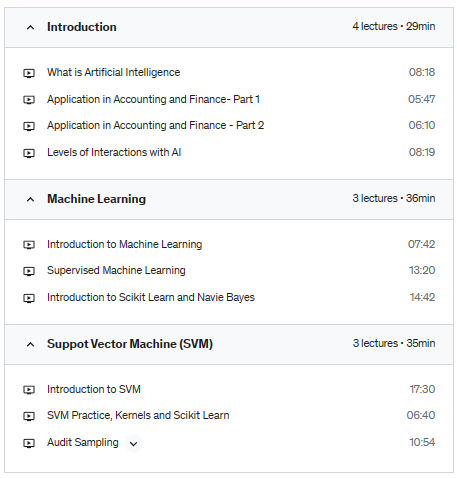
Artificial Intelligence for Accountants I :
Are you ready to stay ahead of the game and tackle disruption head-on? As a finance professional, you know that AI is the future, but do you know how to use it to your advantage? Our course, Artificial Intelligence for Accountants I, will give you the tools and knowledge you need to succeed in a rapidly evolving landscape.
Every leader, manager and finance professional now understands the importance of dealing with disruption.
According to the 2018 EY Global Financial Accounting and Advisory Services (FAAS), corporate reporting survey, close to three-quarters (72%) of finance leaders worldwide believed that AI would have a significant impact on how finance drives data-driven insight. However, businesses that dive into the implementation of AI technologies without understanding the associated challenges face substantial risks.
The question is whether an ordinary accountant does understand what AI is. And why do accountants working in various business domains such as financial reporting, financial analysis, compliance, internal and external audit, finance, investments, etc., even worry about Artificial Intelligence?
This is an introductory-level multi-series course on Artificial Intelligence. Which develops basic understanding and explain
– What is intelligence
– What is AI
– Why AI
– A high-level overview of AI applications in accounting and finance
– How you can interact with AI
– Types of AI
– Introduction most popular form of AI, i.e. Machine Learning
– Introduction to Supervised Machine Learning
– Introduction to Python-based popular library Scikit Learn
This series aims to develop next-generation accountants that understand the most complicated technology humans have ever invented.
Prerequisite:
To get maximum benefit, you would have a basic level of Python knowledge. However, you can still go for this course to gain familiarity with AI.
Who this course is for:
Accountants, Business Manager, accounting and finance students, auditors, analysts, data analysts