Dans cette introduction a Power BI Desktop, je vais de montrer comment installer Power BI Desktop et travailler avec des datas.
Qu’est-ce que Power BI ? Power BI est un ensemble de services logiciels, d’applications et de connecteurs qui œuvrent ensemble pour transformer des sources de données disparates en informations visuelles immersives et interactives.
Contenu de la formation
Power BI Desktop Module 1 Installation de Power BI Desktop
Module 2 Notre premier exemple : import d’un dataset et création d’un visuel (youra !)
Module 3 Présentation de l’interface Power BI Desktop
Module 4 Présentation de query editor et paramétrage de Power BI Desktop
Query editor
Module 5 Nettoyage et préparation de vos données (dataset)
Module 6 Utilisation des Pivot dans les colonnes
Module 7 Split
Module 9 Créations d’un schéma entre les tables
Module 10 Allez plus loin (Langage DAX, Création de report visuel, Power BI pro)
Power BI Desktop est une application gratuite qui s’installe sur un ordinateur local et permet de se connecter à des données, de les transformer et de les visualiser. Avec Power BI Desktop, vous pouvez vous connecter à plusieurs sources de données différentes et les combiner dans un modèle de données (ce qui s’appelle la modélisation ).
Power BI Desktop est inclus dans les plans Office 365. Les utilisateurs de bureau disposent de 10 Go de stockage total dans le cloud Power BI et peuvent télécharger des données de 1 Go à la fois. Desktop donne un accès à la bibliothèque de modèles de visualisation de Power BI. Power BI Desktop a par ailleurs un désavantage.
Who this course is for:
Ingenieurs des datas
Analyste de datas
Toute personne qui voudrait savoir faire des présentations graphiques et visuels
Leaf size varies within and between species, and previous work has linked this variation to the environment and evolutionary history separately. However, many previous studies fail to interlink both factors and are often data limited.
To address this, our study developed a new workflow using machine learning to automate the extraction of leaf traits (leaf area, largest in circle area and leaf curvature) from herbarium collections of Australian eucalypts (Eucalyptus, Angophora and Corymbia). Our dataset included 136,599 measurements, expanding existing data on this taxon’s leaf area by roughly 50 fold.
With this dataset, we were able to confirm global positive relationships between leaf area and mean annual temperature and precipitation. Furthermore, we linked this trait climate relationship to phylogeny, revealing large variation at the within species level, potentially due to gene flow suppressing local adaptation. At deeper phylogenetic levels, the relationship strengthens and the slope converges towards the overall eucalypt slope, suggesting that the effect of gene flow relaxes just above the species level.
The strengthening of trait-climate correlations just beyond the intraspecific level may represent a widespread phenomenon across various traits and taxa. Future studies may unveil these relationships with the larger sample sizes of new trait datasets generated through machine learning.
Introduction
As a fundamental unit of photosynthesis, leaf area has impacts across a variety of processes. This has led to an extensive body of research, ranging from regulating carbon flux over vast areas of the earth (Reich 2012), to influencing ecosystem dynamics by affecting the plant’s individual growth and survival (Wang et al. 2019, Wright et al. 2017, Leigh et al. 2017). Therefore, an improved understanding of leaf area variation can facilitate better predictions for plant adaptation to changing climates (Wang et al. 2022, Pritzkowet al.2020). This, in turn, will enable better comprehension of leaf energy balances (Wright et al. 2017) and their relationship with models of forest productivity and plantation growth (Madani et al. 2018,Reich 2012, Battaglia et al.1998).
The distribution of a plant’s traits may be tied to their environment (Li et al. 2020, Souza et al. 2018, Wright et al. 2017, Moles et al. 2014), and this link may manifest in different forms. One potential form of a trait-climate relationship is when variation is constrained by one or more limits that shift with climate. In this case, two limits may form a tight relationship (e.g.,Reich 2003), and one limit forms a ‘constraint triangle’that contains a probabilistic distribution of traits across the landscape (e.g., Wright et al. 2017, Guo et al. 2000, Cornelissen 1999). For leaf area, mean annual precipitation and temperature are two key environmental drivers that affect this triangle. However, current research suggests that there is a significant constraint on maximum leaf area that shifts with climate, whereas there is no corresponding constraint on minimum leaf area (Wright et al. 2017).
Across climatic gradients, leaf area has been found to increase from dry to wet environments and from colder to hotter climates (Souza et al. 2018, Wright et al. 2017, Moles et al. 2014,Peppe et al. 2011). One proposed explanation is that smaller leaves, particularly leaves with narrow effective widths, possess more effective thermal regulation and reduced water loss through a smaller boundary layer. This layer is a thin space around the leaf with reduced air movement, promoting cooling (Leigh et al. 2017, Nobel 2009). However, the relationship between leaf area and climate is complex. For instance, studies have shown thermal constraints on leaf area to be ineffective in ever wet conditions (Souza et al. 2018 Wright etal. 2017). Therefore, while a general relationship exists between leaf area and climate, it is influenced by various factors.
Empirical research at differing geographical and taxonomic scales have yielded varied results on the relative importance of temperature and precipitation in influencing leaf traits; with regional trait-climate correlations possibly being decoupled at local scales (Ackerly et al.2007). For instance, in Australian eucalypt vegetation stands, Ellis & Hatton (2008) found water availability to play a greater part than temperature in explaining leaf area index. On the other hand, in central Europe ,Meier & Leuschner (2008) found leaf expansion of Fagus sylvatica(L.)stands primarily controlled by temperature, consistent with a global meta analysis (Moles et al. 2014). Similarly, leaf area index in Melaleuca lanceolata (Otto) in southern Australia was found to have a stronger association to mean maximum temperature than precipitation (Hill et al. 2014). Here, our study aims to clarify this relationship between both climatic variables and leaf traits of Australian eucalypts through a unique workflow. In turn, this can contribute to a better local understanding of ecological processes and improved predictions of trait composition (Peppe et al. 2011, Violle et al. 2007).
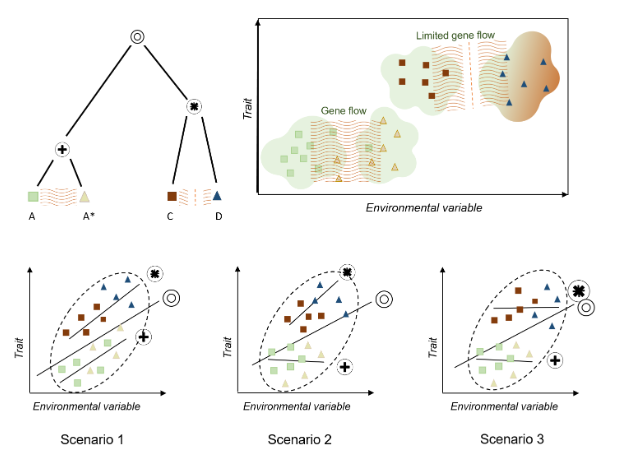
When studying the variation in leaf area across climate, it is important to also consider the influence of evolutionary history (e.g., Milla & Reich 2007,McDonald et al. 2003, Ackerly etal. 2002). Varying effects of phylogeny, and contemporary demography (intraspecific gene flow) may result in trait-climate relationships within species being weaker, unrelated, or even following opposite directions to that reported among species (with various potential scenarios illustrated in Fig. 1) (Wilde et al. 2023, An et al. 2021, McDonald et al. 2003, Ackerly et al.2002). For instance, in Figure Scenario 2, gene flow between populations may prevent adaptation to local environments, counteracting environmental pressures (reviewed at Alexander et al. 2022, Leimu & Fischer 2008). Additionally, an individual’s evolutionary history may constrain phenotype and local adaptive capacity (Fig. 1 Scenario 3, An et al. 2021, Leimu & Fischer 2008). This intraspecific trait variation (ITV) has been debated in previous studies. Some have suggested that ITV may obscure general trends (Bastias et al.2017, Ackerly et al. 2002), while others argue that it does not have such an impact (Westerband et al. 2021, Li et al. 2020, Mudráket al. 2019). This conflict is potentially due to the limitations of datasets generated using traditional methods (also suggested by Li et al.
2020, Bastias et al. 2017). Regardless, studies of links of leaf traits and climatic variables across varying evolutionary scales, from ITV (e.g., An et al. 2021) to major plant families (e.g.,Wilde et al. 2023, Ackerly & Reich 1999) is critical to predicting phenotypic evolution and shifts in traits under a changing climate.
Figure 1. Three scenarios illustrating impacts of evolutionary divergence and intraspecific gene flow on trait-climate relationships. Groups A and A* are populations of a species and remain connected by gene flow, while groups C and D are quite recently ,but completely ,diverged and have limited recent gene flow. The circles represent different internal nodes within the hypothetical phylogenetic tree. In all three scenarios, there is a positive overall trait-climate association. In Scenario 1, there is a strong trait-climate relationship within each of the two recently diverged clades, resulting in roughly similar slopes in each clade In Scenario 2, gene flow strongly suppresses local adaptation within species, potentially causing divergence from overall trait-climate trends. This effect is however relaxed in recently diverged groups. Therefore, the clade consisting of A and A* does not exhibit a trait-climate relationship, and the clade containing groups C and D exhibits a strong trait-climate relationship. In Scenario 3, trait evolution is more constrained, so that strong adaptation is observed only among longer diverged groups. Here, there is no trait-climate relationships within the clade containing A and A* or C and D, but there is an association overall, reflecting adaptation over longer time scales.
Understanding evolution of leaf morphology has a recognised importance (Mudrák et al.2019,Souza et al. 2018, Leimu et al. 2008).Despite this, there is a paucity of research that examines leaf variation in the perspective of phylogeny and ITV simultaneously. One potential reason lies in the laborious and time intensive nature of data collection (Li et al.2020, Bastias et al. 2017) ,which traditionally involve manual measurements of each data point. This makes it difficult to gather datasets with high intraspecific sampling within and across different clades and climates (Li et al. 2020,Bastias et al. 2017).As a consequence, few studies spanning both intraspecific and phylogenetic scales simultaneously have been conducted (see also Wilde et al. 2023, Cutts et al. 2021, Goëau et al. 2020, Pearson et al. 2020, Brenskelle et al. 2020).
This study addresses this by using machine learning (ML) paired with herbarium records. Herbarium specimens are pressed plants of various taxa collected globally. These specimens provide a holistic representation of plant shoots and include both mature and juvenile leaves (Kozlov et al. 2021). As a consequence, trait measurements from these sheets will encompass leaves at different developmental stages, propagating into resulting datasets. Herbarium specimens provide extensive phylogenetic and geographic sampling. However, their potential has remained underutilised due to the impracticality of extracting trait data using traditional methods (Heberling 2022). Thus, we employed ML as a new tool to automate the extraction of trait data from these specimens. Previous studies have used ML to extract leaf traits from digital herbarium specimen images (Hussein et al. 2021, Weaver et al. 2020, Younis et al. 2018). However, to our knowledge, this approach is the first to utilise machine learning operationally in trait ecology, allowing us to create a comprehensive dataset that spans various taxonomic levels across Australia. By pairing this dataset with a fully resolved phylogenetic tree (Thornhill et al. 2019), we could link microevolution to macroevolution, enabling a better observation of the shift in trait climate relationships across different clades and evolutionary depths.
Overall, leaf morphological traits enable better comprehension of leaf energy balances (Wright et al. 2017), improving our understanding of ecosystem dynamics (Pritzkow et al.2020) and global vegetation models (Madani et al. 2018, Reich 2012, Battaglia et al.1998).Despite this, there is a paucity of datasets spanning a wide phylogenetic and spatial range (Moran et al. 2016). Our study proposes a method to address this gap by using ML to bypass traditional trait collection methods. In particular, we sought to address the following questions:
a) Could ML be used to automatically extract various commonly measured leaf morphological traits, including leaf area, and the largest in circle area? This will allow us to build a large dataset, unique in its ability in allowing us to answer the following questions simultaneously in the study taxa.
b) How do leaf traits shift across the Australian climate? We hypothesise that leaf area and largest in circle area will correlate positively with mean annual precipitation and temperature
c) To what extent does phylogeny shape leaf traits?We hypothesise that gene flow will resolve in large trait variability at a shallow phylogenetic level (within species), which will gradually resolve to a trait-climate relationship at deeper levels (for example, among species).
Our study and its findings help reveal the relationship between traits and their influences, in addition to formulating a more efficient method of trait data collection, applicable to additional taxa and traits in the future.
Method
Study clade and design
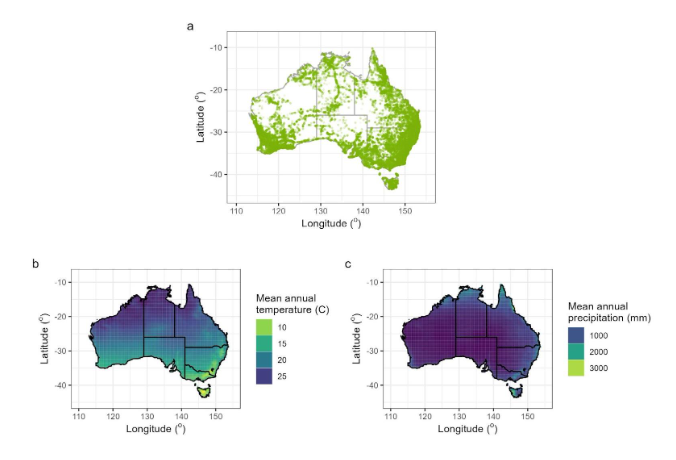
This study focused on eucalypts, which are the dominant canopy trees throughout many Australian forests and shrublands (Booth et al. 2015, Govindan 2005). The eucalypt clade consists of three genera, Eucalyptus (L’Hér.) ,Angophora (Cav.),and Corymbia (K.D. Hill & L.A.S. Johnson). They were selected as the study genera for their wide distribution across Australia’s temperature and precipitation range (Fig. 2), the availability of a molecular phylogeny for the clade (Thornhill et al. 2019), and characteristic simple leaves with entire margins. These features allowed us to explore the impact of climate and phylogeny as drivers of leaf trait variation at different evolutionary scales, with the aid of machine learning (ML).
Digital images of herbarium sheets from the National Herbarium of New South Walespds.s3ap southeast 2.amazonaws.com/images/)were used to capture trait variation across wide spatial and environmental ranges (Fig. 2) This enabled the study of traits in a broader range of lineages and biomes than data collected using observational approaches (Heberling 2022). Herbarium specimens are collected with the aim to record traits present in the population (Kozlov et al. 2021) and thus include both mature and immature leaves. As such, our workflow uses a novel approach of trait sampling that diverges from conventional sampling methods of physiologists, which target fully expanded leaves (e.g., in Wright et al. 2017 and Pérez Harguindeguy et al. 2013). This distinction is critical within eucalypts due to the significance of ontogeny in leaf morphology, and it is worth noting the important implications it plays in the analysis.
Our project aimed to generate a large dataset of leaf measurements from digital images of eucalypt herbarium specimens and use it to test ecological associations. This dataset would be unusual in its combination of wide spatial distribution (Fig2 a) and its deep intra-and interspecific sampling. To do this, the method consisted of three separate parts. (i) Develop and refine a leaf masking model, (ii) develop and refine a leaf classification model, (iii)application of models to produce a large trait dataset and carry out quantitative analysis of trait climate relationships in a phylogenetic framework. An overview of this workflow is found at Figure 4, and relevant data and scripts are available in the Supplementary Information.
Figure 2. The spatial distribution of sampling. a) The location of each data point of leaf trait measurement. b) The mean annual precipitation across Australia as sourced from WorldClim. c) The mean annual temperature across Australia as sourced from WorldClim, indicating the range of climatic variables the sampling encompasses
Leaf Masking Model
A convolutional neural network (CNN) model was trained to find leaves and pixels that belonged to each ‘instance’ of a leaf (known as instance segmentation). The CNN model used a ResNet50 architecture (He et al. 2015) and was implemented in Detectron2 (Wuet al.2019). Transfer learning was performed to reduce the amount of training required. It was conducted from a pretrained model, a Mask R CNN model with a ResNet50 FPN backbone that was pretrained on the COCO dataset (Lin et al. 2014). Extra details of the model and methods used to train, validate, and test can be found in Supplementary Information A and B. A table of definitions has also been provided in Table 1.
ML models ‘learn’ patterns through a set of training data that has been manually annotated. In this case, our model is ‘learning’ to identify pixels of a leaf using annotated images of herbarium specimens. Generating these manual annotations involved creating a polygon around each instance of a leaf following a protocol provided in Supplementary Information B. All annotations were made using the program LabelMe(v 5.01, Wada 2022). In total, 113 manually annotated herbarium sheets were used to train the model, a further were used for validation during training (for adjustment of hyper parameters by Detectron2) and 20 were used for testing the performance of models after training (for manual adjustment of training parameters).
The final model was refined using an optimisation process. This involved: (i) Training the initial model using the manually annotated training and validation data set, (ii) Predicting leaves for images of the testing data set using the trained model, (iii) Gathering quantitative and qualitative measures of model accuracy from part ii, (iv) altering the model’s training parameters and repeating the cycle at part (i) with a new model. Different iterations of the model are described in Table SA_1.
In this blog on what is Machine Learning, you will learn about Machine Learning, the differences between AI and Machine Learning, why Machine Learning matters, applications of Machine Learning, Machine Learning languages, and some of the most common open-source Machine Learning tools.
The following topics will be covered in this blog:
Machine Learning definition
Why Machine Learning?
How does Machine Learning work?
What are the different types of Machine Learning?
Machine Learning Algorithms and Processes
ML Programming Languages
Machine Learning Tools
Difference between AI and Machine Learning
Applications of Machine Learning
Advantages and Disadvantages of Machine learning
Scope of Machine Learning
Prerequisites for Machine Learning
Conclusion
Machine Learning Definition
Even though there are various Machine Learning examples or applications that we use in our daily lives, people still get confused about Machine Learning, so let’s start by looking at the Machine Learning definition.
In layman’s terms, Machine Learning can be defined as the ability of a machine to learn something without having to be programmed for that specific thing. It is the field of study where computers use a massive set of data and apply algorithms for ‘training’ themselves and making predictions. Training in Machine Learning entails feeding a lot of data into the algorithm and allowing the machine itself to learn more about the processed information.
Answering whether the animal in a photo is a cat or a dog, spotting obstacles in front of a self-driving car, spam mail detection, and speech recognition of a YouTube video to generate captions are just a few examples out of a plethora of predictive Machine Learning models.
Another Machine Learning definition can be given as Machine learning is a subset of Artificial Intelligence that comprises algorithms programmed to gather information without explicit instructions at each step. It has experienced the colossal success of late.
We have often seen confusion around the use of the words Artificial Intelligence and Machine Learning. They are very much related and often seem to be used interchangeably, yet both are different. Confused? Let us elaborate on AI vs. ML vs. DL.
Go through these Top 40 Machine Learning Interview Questions and Answers to crack your interviews.
Why Machine Learning?
Let us start with an instance where a machine surpasses in a strategic game by self-learning. In 2016, the strongest Go player (Go is an abstract strategy board game invented in China more than 2,500 years ago) in the world, Lee Sedol, sat down for a match against Google DeepMind’s Machine Learning program, AlphaGo. AlphaGo won the 5-day long match.
One thing to take away from this instance is not that a machine can learn to conquer Go, but the fact that the ways in which these revolutionary advances in Machine Learning—machines’ ability to mimic a human brain—can be applied are beyond imagination.
Machine Learning has paved its way into various business industries across the world. It is all because of the incredible ability of Machine Learning to drive organizational growth, automate manual and mundane jobs, enrich the customer experience, and meet business goals.
According to BCC Research, the global market for Machine Learning is expected to grow from $17.1 billion in 2021 to $90.1 billion by 2026 with a compound annual growth rate (CAGR) of 39.4% for the period of 2021-2026.
Moreover, Machine Learning Engineer is the fourth-fastest growing job as per LinkedIn.
Both Artificial Intelligence and Machine Learning are going to be imperative to the forthcoming society. Hence, this is the right time to learn Machine Learning.
Enroll for the Machine Learning Training in Noida now and land in your dream job!
How does Machine Learning work?
Machine learning works on different types of algorithms and techniques. These algorithms are created with the help of various ML programming languages. Usually, a training dataset is fed to the algorithm to create a model.
Now, whenever input is provided to the ML algorithm, it returns a result value/predictions based on the model. Now, if the prediction is accurate, it is accepted and the algorithm is deployed. But if the prediction is not accurate, the algorithm is trained repeatedly with a training dataset to arrive at an accurate prediction/result.
Consider this example:
If you wish to predict the weather patterns in a particular area, you can feed the past weather trends and patterns to the model through the algorithm. This will be the training dataset for the algorithm. Now if the model understands perfectly, the result will be accurate.
What are the different types of Machine Learning?
Machine Learning algorithms run on various programming languages and techniques. However, these algorithms are trained using various methods, out of which three main types of Machine learning are:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
Supervised Learning
Supervised Learning is the most basic type of Machine Learning, where labeled data is used for training the machine learning algorithms. A dataset is given to the ML model for understanding and solving the problem. This dataset is a smaller version of a larger dataset and conveys the basic idea of the problem to the machine learning algorithm.
Unsupervised Learning
Unsupervised Learning is the type of Machine Learning where no human intervention is required to make the data machine-readable and train the algorithm. Also, contrary to supervised learning, unlabeled data is used in the case of unsupervised learning.
Since there is no human intervention and unlabeled data is used, the algorithm can work on a larger data set. Unlike supervised learning, unsupervised learning does not require labels to establish relationships between two data points.
Reinforcement Learning
Reinforcement Learning is the type of Machine Learning where the algorithm works upon itself and learns from new situations by using a trial-and-error method. Whether the output is favorable or not is decided based on the output result already fed to each iteration.
Machine Learning Algorithms and Processes
Machine Learning algorithms are sets of instructions that the model follows to return an acceptable result or prediction. Basically, the algorithms analyze the data fed to them and establish a relationship between the variables and data points to return the result.
Over time, these algorithms learn to become more efficient and optimize the processes when new data is fed into the model. There are three main categories in which these algorithms are divided- Supervised Learning, Unsupervised Learning, and Reinforcement Learning. These have already been discussed in the above sections.
ML Programming Languages
Now, when it comes to the implementation of Machine Learning, it is important to have a knowledge of programming languages that a computer can understand. The most common programming languages used in Machine Learning are given below.
According to the GitHub 2021report, the below-given table ranks as the most popular programming language for Machine Learning in 2021:
Rank
Programming Language
1
JavaScript
2
Python
3
Java
4
Go
5
TypeScript
6
C++
7
Ruby
8
PHP
9
C#
10
C
Become a Master of Machine Learning by going through this online Machine Learning course in Singapore.
Machine Learning Tools
Machine Learning open-source tools are nothing but libraries used in programming languages like Python, R, C++, Java, Scala, Javascript, etc. to make the most out of Machine Learning algorithms.
Keras: Keras is an open-source neural network library written in Python. It is capable of running on top of TensorFlow.
PyTorch: PyTorch is an open-source Machine Learning library for Python, based on Torch, used for applications such as Natural Language Processing.
TensorFlow: Created by the Google Brain team, TensorFlow is an open-source library for numerical computation and large-scale Machine Learning.
Scikit-learn: Scikit-learn, also known as Sklearn, is a Python library that has become very popular for solving Science, Math, and Statistics problems–because of its easy-to-adopt nature and its wide range of applications in the field of Machine Learning.
Shogun: Shogun can be used with Java, Python, R, Ruby, and MATLAB. It offers a wide range of efficient and unified Machine Learning methods.
Spark MLlib: Spark MLlib is the Machine Learning library used in Apache Spark and Apache Hadoop. Although Java is the primary language for working in MLlib, Python users are also allowed to connect to MLlib through the NumPy library.
Difference between AI and Machine Learning
There seems to be a lack of a bright-line distinction between what Machine Learning is and what it is not. Moreover, everyone is using the labels ‘AI’ and ‘ML’ where they do not belong and that includes using the terms interchangeably.
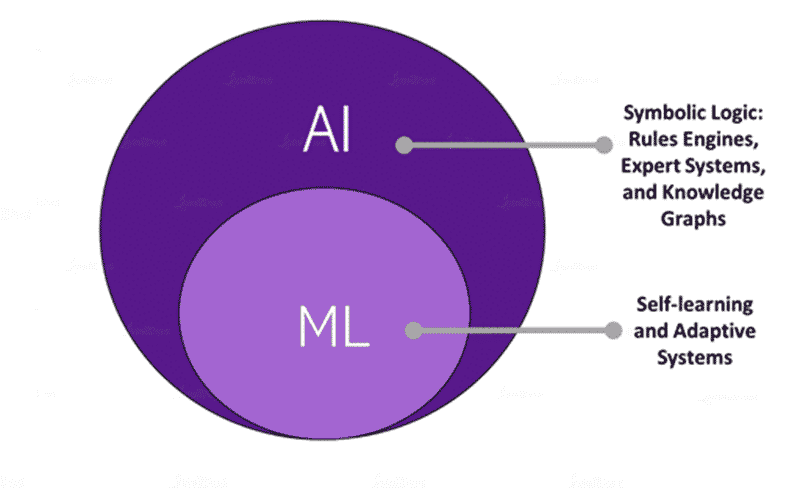
Artificial Intelligence is not a machine or a system. It is a concept that is implemented on machines. When we talk about Artificial Intelligence, it could be making a machine move or it could be making a machine detect spam mail. For all these different implementations of AI, there are different sub-fields, and one such sub-field is Machine Learning. There are applications of Artificial Intelligence that are not related to Machine Learning. For example, symbolic logic: rules engines, expert systems, and knowledge graphs.
Machine Learning uses large sets of data and hours of training to make predictions on probable outcomes. But when Machine Learning ‘comes to life’ and moves beyond simple programming, and reflects and interacts with people even at the most basic level, AI comes into play.
AI is a step beyond Machine Learning, yet it needs ML to reflect and optimize decisions. AI uses what it has gained from ML to simulate intelligence, the same way a human is constantly observing their surrounding environment and making intelligent decisions. AI leads to intelligence or wisdom and its end goal is to simulate natural intelligence to solve complex problems of the world.
Now that we have gathered an idea of What Machine Learning is and the difference between AI and Machine Learning, let us move ahead and see why Machine Learning is important.
ARTIFICIAL INTELLIGENCE
MACHINE LEARNING
AI stands for Artificial intelligence, where intelligence is defined as acquisition of knowledge intelligence is defined as an ability to acquire and apply knowledge.
ML stands for Machine Learning which is defined as the acquisition of knowledge or skill
The aim is to increase the chance of success and not accuracy.
The aim is to increase accuracy, but it does not care about success
It work as a computer program that does smart work
Here, machine takes data and learn from data.
The goal is to simulate natural intelligence to solve complex problems.
The goal is to learn from data on certain tasks to maximize the performance on that task.
AI is decision making.
ML allows systems to learn new things from data.
It is developing a system which mimics humans to solve problems.
It involves creating self learning algorithms.
AI will go for finding the optimal solution.
ML will go for a solution whether it is optimal or not.
AI leads to intelligence or wisdom.
ML leads to knowledge.
AI is a broader family consisting of ML and DL as its components.
ML is a subset of AI.
Enroll in our AI Certification and be an AI Expert.
Applications of Machine Learning
As mentioned earlier, the human race has already stepped into the future world with machines. The pervasive growth of Machine Learning can be seen in almost every other field. Let me list out a few real-life applications of Machine Learning.
Fraud Detection
Fraud detection refers to the act of illicitly drawing out money from people by deceiving them. Machine Learning can go a long way in decreasing instances of fraud detection and save many individuals and organizations from losing their money.
For example- by feeding an algorithm into the model, spam emails can be easily detected. Also, the right machine learning models can easily detect fraudulent transactions or suspicious online banking activities.
In fact, fraud detection ML algorithms are nowadays being considered as much more effective than humans.
Moley’s Robotic Kitchen
Machine Learning can do wonders in the food and beverage industry too. Consider this example- The kitchen comes up with a pair of robotic arms, an oven, a shelf for food and utensils, and a touch screen.
Moley’s kitchen is a gift of Machine Learning: it will learn n number of recipes for you, will cook with remarkable precision, and will also clean up by itself. It sounds great, doesn’t it?
Netflix Movie Recommendation
The algorithm that Netflix uses to recommend movies is nothing but Machine Learning. More than 80 percent of the shows and movies are discovered through the recommendation section.
To recommend movies, it goes through threads within the content rather than relying on the genre board in order to make predictions. According to Todd Yellin, VP of Product at Netflix, the Machine Learning algorithm is one of the pillars of Netflix.
Interested in learning Machine Learning? Enroll in our Machine Learning Certification course!
Alexa
The latest innovations of Amazon have the brain and the voice of Alexa. Now, for those who are not aware of Alexa, it is the voice-controlled Amazon ‘personal assistant’ in Amazon Echo devices.
Alexa can play music, provide information, deliver news and sports scores, tell you the weather, control your smart home, and even allow prime members to order products that they’ve ordered before. Alexa is smart and gets updated through the Cloud and learns all the time, by itself.
But, does Alexa understand commands? How does it learn by itself? Everything is a gift of the Machine Learning algorithm.
Amazon Product Recommendation
We are sure that you might have noticed while buying something online from Amazon, it recommends a set of items that are bought together or items that are often bought together, along with your ordered item.
Have you ever wondered how Amazon makes those recommendations? Well again, Amazon uses the Machine Learning algorithm to do so.
Google Maps
How does Google Maps predict traffic on a particular route? How does it tell you the estimated time for a certain trip?
Google Maps anonymously sends real-time data from the Google Maps users on the same route back to Google. Google uses the Machine Learning algorithm on this data to accurately predict the traffic on that route.
These are some of the Machine Learning examples that we see or use in our daily lives. Let us go ahead and discuss how we can implement a Machine Learning algorithm.
Come to Intellipaat’s Machine Learning Community if you have more queries on Machine Learning!
Advantages and Disadvantages of Machine Learning
Easily identifies trends and patterns
Machine Learning can review large volumes of data and discover specific trends and patterns that would not be apparent to humans. For instance, for e-commerce websites like Amazon and Flipkart, it serves to understand the browsing behaviors and purchase histories of its users to help cater to the right products, deals, and reminders relevant to them. It uses the results to reveal relevant advertisements to them.
Continuous Improvement
We are continuously generating new data and when we provide this data to the Machine Learning model which helps it to upgrade with time and increase its performance and accuracy. We can say it is like gaining experience as they keep improving in accuracy and efficiency. This lets them make better decisions.
Handling multidimensional and multi-variety data
Machine Learning algorithms are good at handling data that are multidimensional and multi-variety, and they can do this in dynamic or uncertain environments.
Wide Applications
You could be an e-tailer or a healthcare provider and make Machine Learning work for you. Where it does apply, it holds the capability to help deliver a much more personal experience to customers while also targeting the right customers.
Disadvantages of Machine Learning
Data Acquisition
Machine Learning requires a massive amount of data sets to train on, and these should be inclusive/unbiased, and of good quality. There can also be times where we must wait for new data to be generated.
Time and Resources
Machine Learning needs enough time to let the algorithms learn and develop enough to fulfill their purpose with a considerable amount of accuracy and relevancy. It also needs massive resources to function. This can mean additional requirements of computer power for you.
Interpretation of Results
Another major challenge is the ability to accurately interpret results generated by the algorithms. You must also carefully choose the algorithms for your purpose. Sometimes, based on some analysis you might select an algorithm but it is not necessary that this model is best for the problem.
High error-susceptibility
Machine Learning is autonomous but highly susceptible to errors. Suppose you train an algorithm with data sets small enough to not be inclusive. You end up with biased predictions coming from a biased training set. This leads to irrelevant advertisements being displayed to customers. In the case of Machine Learning, such blunders can set off a chain of errors that can go undetected for long periods of time. And when they do get noticed, it takes quite some time to recognize the source of the issue, and even longer to correct it.
Scope of Machine Learning
The scope of Machine Learning covers varied industries and sectors. It is expanding across all fields such as Banking and Finance, Information Technology, Media & Entertainment, Gaming, and the Automotive industry. As the Machine Learning scope is very high, there are some areas where researchers are working toward revolutionizing the world for the future.
The scope of Machine Learning in India, as well as in other parts of the world, is high in comparison to other career fields when it comes to job opportunities.
According to Gartner, there will be 2.3 million jobs in the field of Artificial Intelligence and Machine Learning by 2023. Also, the salary of a Machine Learning Engineer is much higher than the salaries offered to other job profiles. According to Forbes, the average salary of an ML Engineer in the United States is US$99,007.
Go through our AI Course in Chennai to master AI & ML skills and land in a high paying job!
Prerequisites for Machine Learning
Prerequisites to building a career in Machine Learning include knowledge of the following:
Statistics– Knowledge of statistical tools and techniques is a basic requirement to understand Machine Learning. You should be well trained in using various types of statistics such as descriptive statistics and inferential statistics to extract useful information from raw data.
Probability– Machine Learning is built on probability. The very possibility of the occurrence of an event is known as probability.
Programming languages– It is very important that an ML engineer knows which machine-readable programming language to be used.
Calculus– The working of Machine Learning algorithms depends on how Calculus and related concepts such as Integration and Differentiation are used. Hence, it is very important that you understand and are well acquainted with Calculus.
Linear Algebra– Vectors, Matrices, and Linear Transformations form an important part of Linear Algebra and play an important role in dataset operations.
Conclusion
This module focuses on the meaning of Machine Learning, common Machine Learning definitions, the difference between AI and Machine Learning, why Machine Learning matters, prerequisites, and types of machine learning. We have also highlighted different Machine Learning tools, as well as discussed some of the applications of Machine Learning. If you want to have a deeper understanding of Machine Learning, refer to the Machine Learning tutorial. See you there!