Why We Need Split Testing Now More Than Ever – The Powerful Benefits of This Strategy
Why Split Testing Works and When it Doesn’t – Understanding Statistical Significance
Using Split Testing for SEO Success – The Practical Guide
The Technical Bit: Using Redirects
Tools and Best Practices
What to Test?
Advanced Strategies
SEO – What We Know and What Split Testing Has Shown Us
Related Strategies and Conclusion
Requirements
There are no requirements for this course
Description
Google is constantly changing its algorithms, moving the goal posts, and going back on what it has said.
is making a big push toward a more AI-driven service. That’s why using AB tests to identify precisely what works and what doesn’t is such an important move.
Split testing essentially means taking a rigorous and somewhat scientific approach to your search engine optimization, which effectively means removing the guess work from the process.
In fact, what split testing really amounts to, is helping your site to ‘evolve’ to become the most optimized version of itself.
Topics covered:
What is Split Testing?
Why We Need Split Testing Now More Than Ever – The Powerful Benefits of This Strategy
Why Split Testing Works and When it Doesn’t – Understanding Statistical Significance
Using Split Testing for SEO Success – The Practical Guide
The Technical Bit: Using Redirects
Tools and Best Practices
What to Test?
Advanced Strategies
SEO – What We Know and What Split Testing Has Shown Us
Related Strategies and Conclusion
Who this course is for:
For you that wants to learn SEO split testing
Course content
1 section • 11 lectures • 52m total length
Introduction11 lectures • 53min
Introduction01:45
What Is Split Testing?04:24
Need Split Testing Now More Than Ever – The Powerful Benefits Of This Strategy04:49
Why Split Testing Works And When It Doesn’t06:04
Using Split Testing For SEO Success – The Practical Guide04:56
The Technical Bit: Using Redirects06:44
Tools And Best Practices07:21
What To Test?03:37
Advance Strategies05:15
SEO – What We Know And What Split Testing Has Shown Us03:31
This is a theory course and not a practical course.
If you are stuck or don’t understand what’s happening, you should be capable to google or find a way to understand what’s being taught
Description
Welcome to the Advanced Python – Memory Management Journey.
This course is designed to take you a step from being an intermediate Python developer to being an effective Python programmer who knows why’s and how of what’s happening behind the scenes.
Python is used by world’s largest companies to accomplish all kind of task and I’m going to help you understand this language in a an easy way.
The course is going to be short sweet you wont find me rambling a lot we’ll get straight to the topic.
We will cover a lot of topics in this course! Including: Memory Management such as garbage collection, reference counting algorithm, circular reference, memory leaks.
Looking forward to seeing you inside the course.
* course image taken from Vecteezy
Who this course is for:
To move a step ahead from other python developers
Those who want to understand memory management in python
Outsourcing: How ChatGPT DOUBLED My SEO Traffic in 12 Days With THIS SEO Strategy
5 EPIC ChatGPT SEO Prompts that Increased My SEO Traffic by 100%
How I Rank ChatGPT Content #1 Page of Google 2023
How to use the ChatGPT AI PRM Extension for SEO
Requirements
You’ll need a website and a ChatGPT account.
Description
Are you ready to discover the secrets to dominating search engine rankings with ChatGPT SEO!
With this free course, you’ll learn how to tap into the power of ChatGPT and skyrocket your SEO traffic like never before WITHOUT having to hire expensive SEOs or content writers.
Hi, my name’s Julian Goldie, and I’m not going to bore you with all the marketing hype but I’m a published author of 2 best-selling books including “Link Building Mastery”, the owner of a 7 figure SEO link building company Goldie Agency, YouTuber, podcaster, and I’ve helped thousands of websites with SEO. Now that’s enough of me boasting about my accomplishments!
In this free course, you’ll learn the PROVEN Strategies and Techniques that Will Transform Your SEO Game including:
How I Increased SEO Traffic by 50% With ChatGPT – Uncover the strategies I used to supercharge my SEO traffic by leveraging ChatGPT’s AI-powered content generation.
How I Rank Money Pages #1 on Google With ChatGPT – Learn my step-by-step process for ranking money pages on the first page of Google by harnessing ChatGPT’s AI capabilities.
Outsourcing: How ChatGPT DOUBLED My SEO Traffic in 12 Days With THIS SEO Strategy – Discover how to outsource your SEO efforts effectively and use ChatGPT to double your traffic in less than two weeks.
5 EPIC ChatGPT SEO Prompts that Increased My SEO Traffic by 100% – Get access to five game-changing prompts that will help you create content that drives massive organic traffic to your site.
How I Rank ChatGPT Content #1 Page of Google 2023 – Stay ahead of the curve with my latest techniques for ranking ChatGPT-generated content on the first page of Google in 2023.
How to use the ChatGPT AI PRM Extension for SEO – Maximize your SEO efforts with the innovative ChatGPT AI PRM extension, designed to improve your content’s search engine performance.
Don’t miss out on this opportunity to revolutionize your SEO strategy and dominate the search engine rankings!
Get FREE access to the course and start your journey to SEO mastery today!
Who this course is for:
Website Owners
Business Owners
SEOs
Bloggers and Writers
Course content
1 section • 8 lectures • 1h 26m total length
Introduction8 lectures • 1hr 26min
How I Increased SEO Traffic by 50% With ChatGPT17:28
How I Rank Money Pages #1 on Google With ChatGPT25:59
Outsourcing: How ChatGPT DOUBLED My SEO Traffic in 12 Days With THIS SEO Strateg14:29
5 EPIC ChatGPT SEO Prompts that Increased My SEO Traffic by 100%13:25
How I Rank ChatGPT Content #1 Page of Google 202306:49
How to use the ChatGPT AI PRM Extension for SEO06:11
Free Link Building Book: Link Building Mastery01:00
Every week, the top AI labs globally — Google, Facebook, Microsoft, Apple, etc. — release tons of new research work, tools, datasets, models, libraries and frameworks in artificial intelligence (AI) and machine learning (ML).
Interestingly, they all seem to have picked a particular school of thought in deep learning. With time, this pattern is becoming more and more clear. For instance, Facebook AI Research (FAIR) has been championing self-supervised learning (SSL) for quite some time, alongside releasing relevant papers and tech related to computer vision, image, text, video, and audio understanding.
Even though many companies and research institutions seem to have their hands on every possible area within deep learning, a clear pattern is emerging. But, of course, all of them have their favourites. In this article, we will explore some of the recent work in their respective niche/popularised areas.
DeepMind
A subsidiary of Alphabet, DeepMind remains synonymous with reinforcement learning. From AlphaGo to MuZero and the recent AlphaFold, the company has been championing breakthroughs in reinforcement learning.
AlphaGo is a computer program to defeat a professional human Go player. It combines an advanced search tree with deep neural networks. These neural networks take a description of the Go board as input and process it through a number of different network layers containing millions of neuron-like connections. The way it works is — one neural network ‘policy network’ selects the next move to play, while the other neural network, called the ‘value network,’ predicts the winner of the game.
Taking the ideas one step further, MuZero matches the performance of AlphaZero on Go, chess and shogi, alongside mastering a range of visually complex Atari games, all without being told the rules of any game. Meanwhile, DeepMind’s AlphaFold, the latest proprietary algorithm, can predict the structure of proteins in a time-efficient way.
OpenAI
GPT-3 is one of the most talked-about transformer models globally. However, its creator OpenAI is not done yet. In a recent Q&A session, Sam Altman spoke about the soon to be launched language model GPT-4, which is expected to have 100 trillion parameters — 500x the size of GPT-3.
Besides GPT-4, Altman gave a sneak-peek into GPT-5 and said that it might pass the Turing test. Overall, OpenAI looks to achieve artificial general intelligence with its series of transformer models into new areas.
Today, GPT-3 competes with the likes of EleutherAI GPT-j, BAAI’s Wu Dao 2.0 and Google’s Switch Transformer, among others. Recently, OpenAI launched OpenAI Codex, an AI system that translates natural language into code. It is a descendant of GPT-3; its training data contains both natural language and billions of lines of source code from publicly available sources, including code in public GitHub repositories.
Facebook
Facebook is ubiquitous to self-supervised learning techniques across domains via fundamental, open scientific research. It looks to improve image, text, audio and video understanding systems in its products. Like its pretrained language model XLM, self-supervised learning is accelerating important applications at Facebook today — like proactive detection of hate speech. Further, its XLM-R, a model that leverages RoBERTa architecture, improves hate speech classifiers in multiple languages across Instagram and Facebook.
Facebook believes that self-supervised learning is the right path to human-level intelligence. It accelerates research in this area by sharing its latest work publicly and publishing at top conferences, alongside organising workshops and releasing libraries. Some of its recent work in self-supervised learning include VICReg, Textless NLP, DINO, etc.
Google
Google is one of the pioneers in automated machine learning (AutoML). It is advancing AutoML in highly diverse areas like time-series analysis and computer vision. Earlier this year, Google Brain researchers introduced a new way of programming AutoML based on symbolic programming called PyGlove. It is a general symbolic programming library for Python, used for implementing symbolic formulation of AutoML.
Some of its latest products in this area include Vertex AI, AutoML Video Intelligence, AutoML Natural Language, AutoML Translation, and AutoML Tables.
Apple
On-device machine learning comes with privacy challenges. To tackle the issue, Apple, in the last few years, has ventured into federated learning. For those unaware, federated learning is a decentralised form of machine learning. It was first introduced by Google researchers in 2016 in a paper titled, ‘Communication Efficient Learning of Deep Networks for Decentralized Data,’ but has been widely adopted by various players in the industry to ensure smooth training of machine learning models on edge, alongside maintaining the privacy and security of user data.
In 2019, Apple, in collaboration with Stanford University, released a research paper called ‘Protection Against Reconstruction and Its Applications in Private Federated Learning,” which showcased practicable approaches to large-scale locally private model training that were previously impossible. The research also touched upon theoretical and empirical ways to fit large-scale image classification and language models with little degradation in utility.
Check out other top research papers in federated learning here.
Apple designs all its products to protect user privacy and give them control of their data. Despite the setbacks, the tech giant is working on various innovative ways to offer privacy-focused products and apps by leveraging federated learning and decentralised alternative techniques.
Microsoft
Microsoft Research has become one of the number one AI labs globally, pioneering machine teaching research and technology in computer vision and speech analysis. It offers resources across the spectrum, including intelligence, systems, theory and other sciences.
Under intelligence, it covers research areas like artificial intelligence, computer vision, search and information retrieval, among others. In the systems, the team offers resources in quantum computing, data platforms and analytics, security, privacy and cryptography, and more. Currently, it has become a go-to platform for attending lecture series, sessions and workshops.
Earlier, Microsoft launched free machine learning for beginners to teach students the basics of machine learning. For this, Azure Cloud advocates and Microsoft student ambassador authors, contributors, and reviewers put together the lesson plan that uses pre-and-post lesson quizzes, infographics, sketch notes, and assignments to help students adhere to machine learning skills.
Amazon
Amazon has become one of the leading research hubs for transfer learning methods due to its exceptional work in the Alexa digital assistant. Since then, it has been pushing research in the transfer learning space incredibly, be it to transfer knowledge across different language models, techniques, or better machine translation.
There have been several research works implemented by Amazon, especially in transfer learning. For example, in January this year, Amazon researchers proposed ProtoDA, an efficient transfer learning for few-shot intent classification.
Check out more resources related to transfer learning from Amazon here.
IBM
While IBM pioneered technology in many machine learning areas, it lost a leadership position to other tech companies. For example, in the 1950s, Arthur Samuel of IBM developed a computer programme for playing checkers. Cut to the 2020s, IBM is pushing its research boundaries in quantum machine learning.
The company is now pioneering specialised hardware and building libraries of circuits to empower researchers, developers and businesses to tap into quantum as a service through the cloud, using preferred coding language and without the knowledge of quantum computing.
By 2023, IBM looks to offer entire families of pre-built runtimes across domains, callable from a cloud-based API, using various common development frameworks. It believes that it has already laid the foundations with quantum kernel and algorithm developers, which will help enterprise developers explore quantum computing models independently without having to think about quantum physics.
In other words, developers will have the freedom to enrich systems built in any cloud-native hybrid runtime, language, and programming framework or integrate quantum components simply into any business workflow.
Wrapping up
The article paints a bigger picture of where the research efforts of the big AI labs are heading. Overall, the research work in deep learning seems to be going in the right direction. Hopefully, the AI industry gets to reap the benefits sooner than later.
Machine Learning, coupled with the ever elusively defined field of “Artificial Intelligence” promises to revolutionise the way businesses work, cars drive, factories plan — pretty much every area of our life today. It’s a promise that the technology behemoths — Google, Amazon, Apple and Microsoft — have poured millions of dollars of research into. We know that machine learning is at the centre of key technologies such as voice recognition (Alexa, Siri), face recognition (Face ID) and autonomous driving (Tesla) — but where’s the rest of the technology application? Can we point to real world machine learning applications outside the big tech behemoths? And if not, why not?
One interesting application of machine learning is in predictive scoring — whereby an algorithm can begin to make predictions regarding an outcome. Salesforce Cloud’s Einstein product is a good example of this. Their algorithms claim the ability to predict success factors on Leads held in Salesforce Cloud. The idea here is very attractive — Einstein should be able to predict which leads are likely to close allowing Sales Managers to focus on the top 10% of their opportunities and nurture those potential clients through to closing. It should signal the end to the ‘shotgun’ approach to lead acquisition and management. Initial reviews when the tech launched back in 2016 were mixed, with some claiming the hype outstripped the reality of its usefulness. Fast forward to 2017 and the technology has picked up, with an example case study from Silverline quoting 30% higher close rates since going live with Einstein.
One of the difficulties with truly assessing the success of AI tech, however, is really understanding the driving force behind that success. Let’s imagine we take a company like Silverline who decide to embark on adding AI to their sales teams processes. The first thing that machine learning demands is data: good data and lots of it. Second to rollout is instigating change: “Listen up sales team! We’re rolling out AI to your sales software. We want you to focus on the leads that have a predicted 90%+ closure rate”. Finally, this change demands focus and adjusting the way the team operates: don’t do what you used to do, follow this systemic process because the technology demands it.
The tech goes live and close rates go up 30%. A resounding success. But pausing for a moment, and thinking objectively, can we conclusively say that the machine learning suggestions drove that improvement? Who’s to say that the mere razor sharp focus on a subset of sales (those predicted at 90%+ closure rate) wasn’t actually responsible for the improvement? Would it have mattered which leads had that focus applied or could the same level of success be attributed to the mere act of focusing on some leads and not others? How did improvements in data contribute to the success? Did the introduction of a systemic process help the chaotic sales people operate more effectively?
The real crux of the issue and certainly where this author feels we are, is that the gamut of “Artificial Intelligence” technology is very much at a handholding stage. Humans can still routinely outperform machine learning algorithms in almost every single application of the technology today. Many technologists won’t admit this but the evidence is clear — how many times does Siri fumble to understand your meaning compared to day day to conversations with other humans? Does your partner ever fail to recognise your face the way Face ID sometimes does? Does your Tesla Auto Pilot drive as well as you do? Does Salesforce Einstein outperform a seasoned sales professional?
So where does that leave us? Consensus seems to be that “AI” and particularly machine learning is currently highly effective — and impressive — at very narrowly focused tasks. This is obvious to anyone who understands how a machine learning matrix actually operates. Even deep learning is about training a network to generate predictions or outcomes that operate on a constrained set of input data, solving a highly specialised task. This is why the Salesforce Einstein technology will work well for some, and terribly for others. The training input for the model depends on the ‘law of averages’ across, presumably, all of Salesforce’s customer dataset. So if you have a slightly different sales approach it’s very difficult for an algorithm to accommodate you.
Machine Learning today, therefore remains highly impressive at highly specific tasks, such as voice recognition, facial recognition and image recognition. The question therefore is — where can this technology be applied in the real world? The answer: in highly specific tasks. And the business benefit? Automating those tasks. If it’s a highly specific, but complex task then automating that task through machine learning is the way to go. We are working with customers on projects such as classifying damage to objects and training a machine learning model to categorise and price damage using the same judgement a human operator does. How useful would it be to present a machine learning algorithm with 50 random photos of an object and for that algorithm to suggest a cost to fix it? This is completely within the realms of what is possible with machine learning today.
The best times for this nascent technology are certainly ahead. We believe that as new approaches from academia and research move to real world application, coupled with the democratisation of technology through Cloud Computing infrastructure, the number of real world machine learning applications is going to increase exponentially in the coming years.
The recent revelation that Google is using machine learning to help process some of its search results is attracting interest and questions about this field within artificial intelligence. What exactly is “machine learning” and how do machines teach themselves? Here’s some background drawn from those involved with machine learning at Google itself.
Yesterday, Google held a “Machine Learning 101” event for a variety of technology journalists. I was one of those in attendance. Despite the billing as an introduction, what was covered still was fairly technical and hard to digest for me and several others in attendance.
For example, when a speaker tells you the math with machine learning is “easy” and mentions calculus in the same sentence, they have a far different definition of easy than the layperson, I’d say!
Still, I came away with a much better understanding of the process and parts involved with how machines — computers — learn to teach themselves to recognize objects, text, spoken words and more. Here’s my takeaway.
The Parts Of Machine Learning
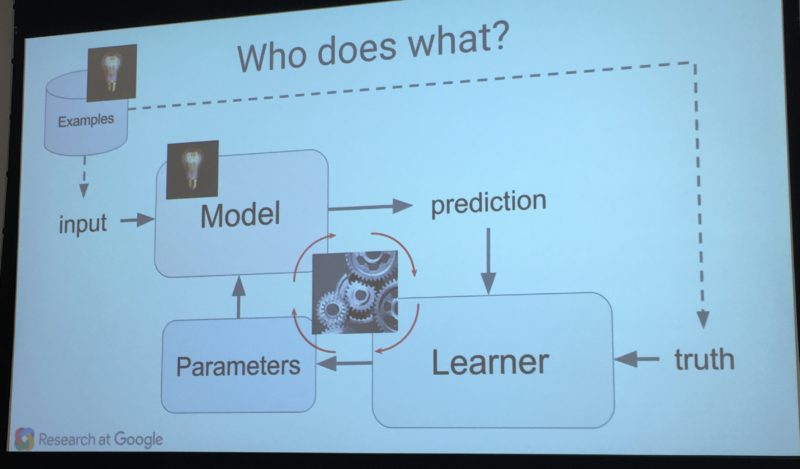
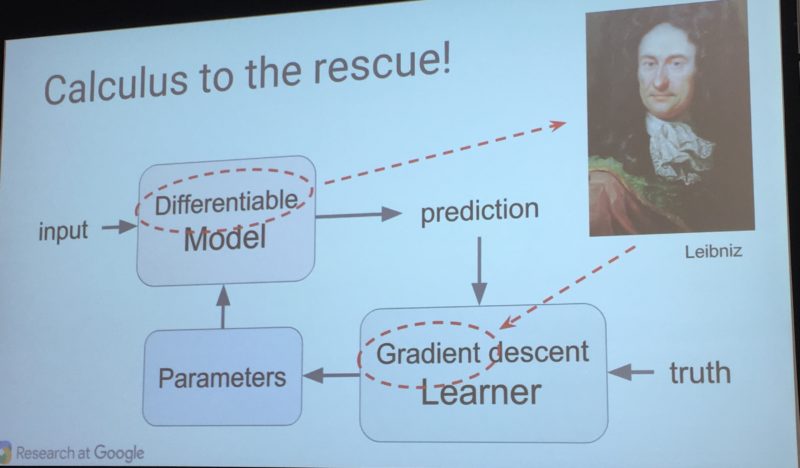
Machine learning systems are made up of three major parts, which are:
Model: the system that makes predictions or identifications.
Parameters: the signals or factors used by the model to form its decisions.
Learner: the system that adjusts the parameters — and in turn the model — by looking at differences in predictions versus actual outcome.
Now let me translate that into a possible real world problem, based on something that was discussed yesterday by Greg Corrado, a senior research scientist with Google and cofounder of the company’s deep learning team.
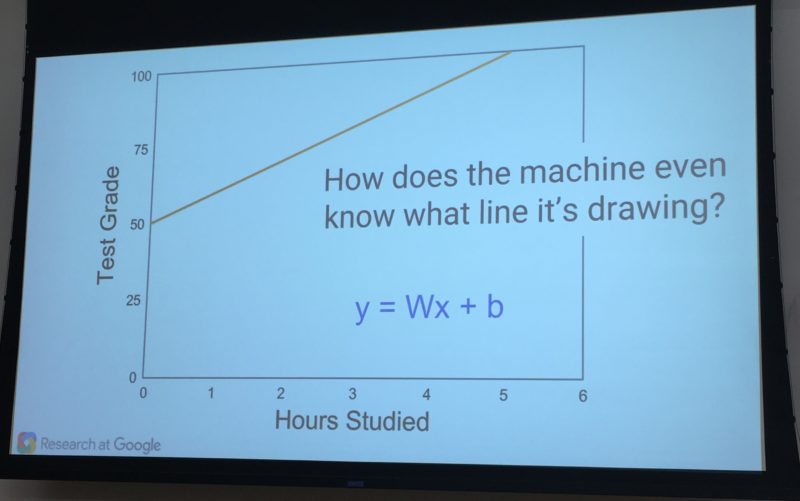
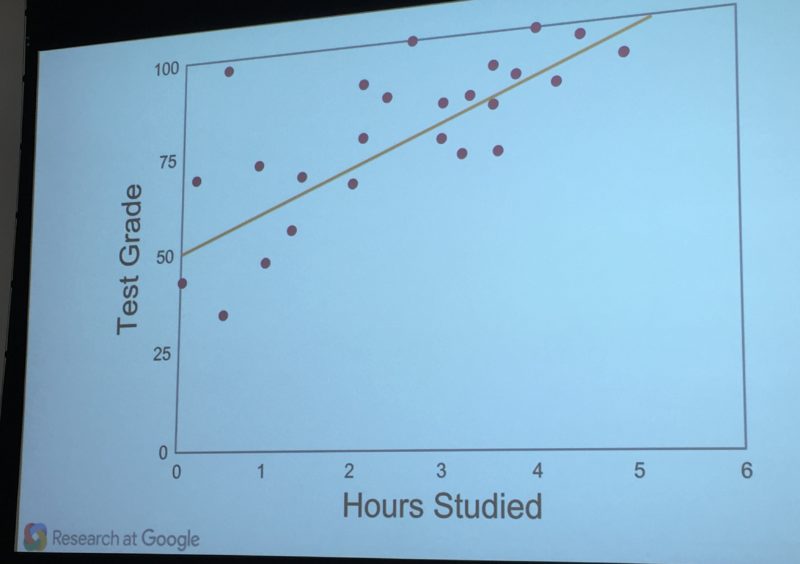
Imagine that you’re a teacher. You want to identify the optimal amount of time students should study to get the best grade on a test. You turn to machine learning for a solution. Yes, this is overkill for this particular problem. But this is a very simplified illustration!
Making The Model
Everything starts with the model, a prediction that the machine learning system will use. The model initially has to be given to the system by a human being, at least with this particular example. In our case, the teacher will tell the machine learning model to assume that studying for five hours will lead to a perfect test score.
The model itself depends on the parameters used to make its calculations. In this example, the parameters are the hours spent studying and the test scores received. Imagine that the parameters are something like this:
0 hours = 50% score
1 hour = 60% score
2 hours = 70% score
3 hours = 80% score
4 hours = 90% score
5 hours = 100% score
The machine learning system will actually use a mathematical equation to express all this above, to effectively form a trend line of what’s expected. Here’s an example of that from yesterday’s talk:
Providing Initial Input
Now that the model is set, real life information is entered. Our teacher, for example, might input four test scores from different students, along with the hours they each studied.
As it turns out, the scores don’t match the model, in this example. Some are above or below the predicted trend line:
Now it’s time for that learning part of machine learning!
The Learner Learns
That set of scores that were entered? Data like this given to a machine learning system is often called a “training set” or “training data” because it’s used by the learner in the machine learning system to train itself to create a better model.
The learner looks at the scores and see how far off they were from the model. It then uses more math to adjust the initial assumptions. For example, the list from above might effectively be altered like this:
0 hours = 45% score
1 hour = 55% score
2 hours = 65% score
3 hours = 75% score
4 hours = 85% score
5 hours = 95% score
6 hours = 100% score
The new prediction is reworked so that more study time is projected to earn that prefect score.
This is just an example of the process, one that’s completely made up. The most important takeaway is simply to understand that the learner makes very small adjustments to the parameters, to refine the model. I’ll come back to this in a moment.
Rinse & Repeat
Now the system is run again, this time with a new set of scores. Those real scores are compared against the revised model by the learner. If successful, the scores will be closer to the prediction:
These won’t be perfect, however. So, the learner will once again adjust the parameters, to reshape the model. Another set of test data will be inputted. A comparison will happen again, and the learner will again adjust the model.
The cycle will keep repeating until there’s a high degree of confidence in the ultimate model, that it really is predicting the outcome of scores based on hours of study.
Gradient Descent: How Machine Learning Keeps From Falling Down
Google’s Corrado stressed that a big part of most machine learning is a concept known as “gradient descent” or “gradient learning.” It means that the system makes those little adjustments over and over, until it gets things right.
Corrado likened it to climbing down a steep mountain. You don’t want to jump or run, because that’s dangerous. You’ll more likely make a mistake and fall. Instead, you inch your way down, carefully, a little at a time.
Remember that “the math is easy” line I mentioned above? Apparently for those who know calculus and mathematics, it really is easy, the equations involved.
The real challenge, instead, has been the computing horsepower. It takes a long time for machines to learn, to go through all these steps. But as our computers have gotten faster and bigger, machine learning that seemed impossible years ago is now becoming almost commonplace.
Getting Fancy: Identifying Cats
The example above is very simplistic. As said, it’s overkill for a teacher to use a machine learning system to predict test scores. But the same basic system is used to do very complex things, such as identifying pictures of cats.
Computers can’t see as humans can. So how can they identify objects, in the way that Google Photos picks out many objects in my photos:
Machine learning to the rescue! The same principle applies. You build a model of likely factors that might help identify what’s a cat in images, colors, shapes and so on. Then you feed in a training set of known pictures of cats and see how well the model works.
The learner then makes adjustments, and the training cycle continues. But cats or any object identification is complicated. There are many parameters used as part of forming the model, and you even have parameters within parameters all designed to translate pictures into patterns that the system can match to objects.
For example, here’s how the system might ultimately view a cat on a carpet:
That almost painting-like image has become known as a deep dream, based on the DeepDream code that Google released, which in turn came out of information it shared on how its machine learning systems were building patterns to recognize objects.
The image is really an illustration of the type of patterns that the computer is looking for, when it identifies a cat, rather than being part of the actual learning process. But if the machine could really see, it’s a hint toward how it would actually do so.
By the way, a twist with image recognition from our initial example is that the model itself is initially created by machines, rather than humans. They try to figure out for themselves what an object is making initial groupings of colors, shapes and other features, then use the training data to refine that.
Identifying Events
For a further twist on how complicated all this can be, consider if you want to identify not just objects but events. Google explained that you have to help add in some common sense rules, some human guidance that allows the machine learning process to understand how various objects might add up to an event.
For example, consider this:
As illustrated, a machine learning system sees a tiny human, a basket and an egg. But a human being sees all these and recognizes this as an Easter egg hunt.
What About RankBrain?
How does all this machine learning apply to RankBrain? Google didn’t get into the specifics of that at all, In fact, it wasn’t even mentioned during the formal discussions and little more was revealed in talks during breaks than has already been released.
Why? Basically, competition. Google shares a lot generally about how it does machine learning. It even shares lots of specifics in terms of some fields. But it’s staying pretty quiet on what exactly is going on with machine learning in search, to avoid giving away things it believes are pretty important and unique.
Daniel Faggella is Head of Research at Emerj. Called upon by the United Nations, World Bank, INTERPOL, and leading enterprises, Daniel is a globally sought-after expert on the competitive strategy implications of AI for business and government leaders.
Typing “what is machine learning?” into a Google search opens up a pandora’s box of forums, academic research, and false information – and the purpose of this article is to simplify the definition and understanding of machine learning thanks to the direct help from our panel of machine learning researchers.
At Emerj, the AI Research and Advisory Company, many of our enterprise clients feel as though they should be investing in machine learning projects, but they don’t have a strong grasp of what it is. We often direct them to this resource to get them started with the fundamentals of machine learning in business.
In addition to an informed, working definition of machine learning (ML), we detail the challenges and limitations of getting machines to ‘think,’ some of the issues being tackled today in deep learning (the frontier of machine learning), and key takeaways for developing machine learning applications for business use-cases.
This article will be broken up into the following sections:
What is machine learning?
How we arrived at our definition (IE: the perspective of expert researchers)
Machine learning basic concepts
Visual representation of ML models
How we get machines to learn
An overview of the challenges and limitations of ML
Brief introduction to deep learning
Works cited
Related ML interviews on Emerj
We put together this resource to help with whatever your area of curiosity about machine learning – so scroll along to your section of interest, or feel free to read the article in order, starting with our machine learning definition below:
What is Machine Learning?
* “Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
The above definition encapsulates the ideal objective or ultimate aim of machine learning, as expressed by many researchers in the field. The purpose of this article is to provide a business-minded reader with expert perspective on how machine learning is defined, and how it works. Machine learning and artificial intelligence share the same definition in the minds of many however, there are some distinct differences readers should recognize as well. References and related researcher interviews are included at the end of this article for further digging.
* How We Arrived at Our Definition:
(Our aggregate machine learning definition can be found at the beginning of this article)
As with any concept, machine learning may have a slightly different definition, depending on whom you ask. We combed the Internet to find five practical definitions from reputable sources:
“Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world.” – Nvidia
“Machine learning is the science of getting computers to act without being explicitly programmed.” – Stanford
“Machine learning is based on algorithms that can learn from data without relying on rules-based programming.”- McKinsey & Co.
“Machine learning algorithms can figure out how to perform important tasks by generalizing from examples.” – University of Washington
“The field of Machine Learning seeks to answer the question “How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?” – Carnegie Mellon University
We sent these definitions to experts whom we’ve interviewed and/or included in one of our past research consensuses, and asked them to respond with their favorite definition or to provide their own. Our introductory definition is meant to reflect the varied responses. Below are some of their responses:
Dr. Yoshua Bengio, Université de Montréal:
ML should not be defined by negatives (thus ruling 2 and 3). Here is my definition:
Machine learning research is part of research on artificial intelligence, seeking to provide knowledge to computers through data, observations and interacting with the world. That acquired knowledge allows computers to correctly generalize to new settings.
Dr. Danko Nikolic, CSC and Max-Planck Institute:
(edit of number 2 above): “Machine learning is the science of getting computers to act without being explicitly programmed, but instead letting them learn a few tricks on their own.”
Dr. Roman Yampolskiy, University of Louisville:
Machine Learning is the science of getting computers to learn as well as humans do or better.
Dr. Emily Fox, University of Washington:
My favorite definition is #5.
Machine Learning Basic Concepts
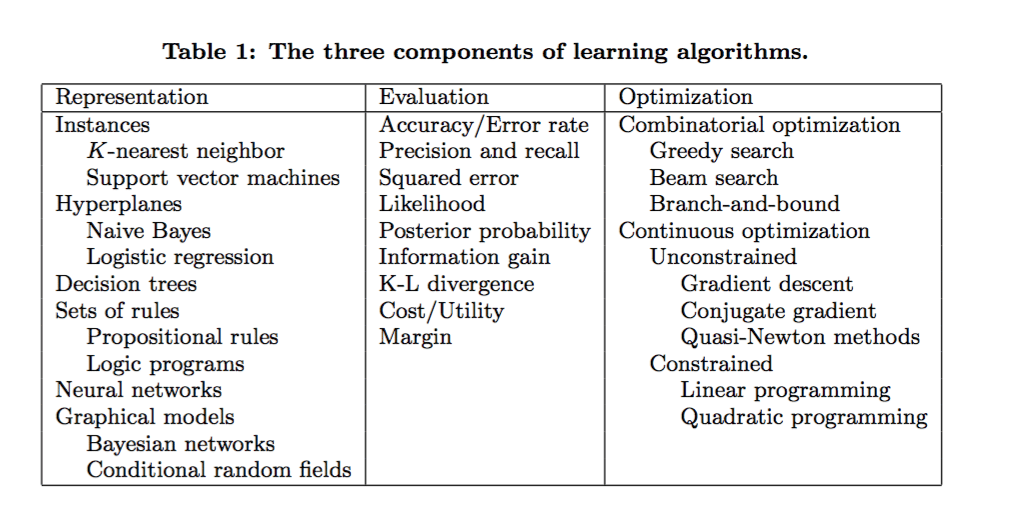
There are many different types of machine learning algorithms, with hundreds published each day, and they’re typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). Regardless of learning style or function, all combinations of machine learning algorithms consist of the following:
Representation (a set of classifiers or the language that a computer understands)
Evaluation (aka objective/scoring function)
Optimization (search method; often the highest-scoring classifier, for example; there are both off-the-shelf and custom optimization methods used)
Image credit: Dr. Pedro Domingo, University of Washington
The fundamental goal of machine learning algorithms is to generalize beyond the training samples i.e. successfully interpret data that it has never ‘seen’ before.
Visual Representations of Machine Learning Models
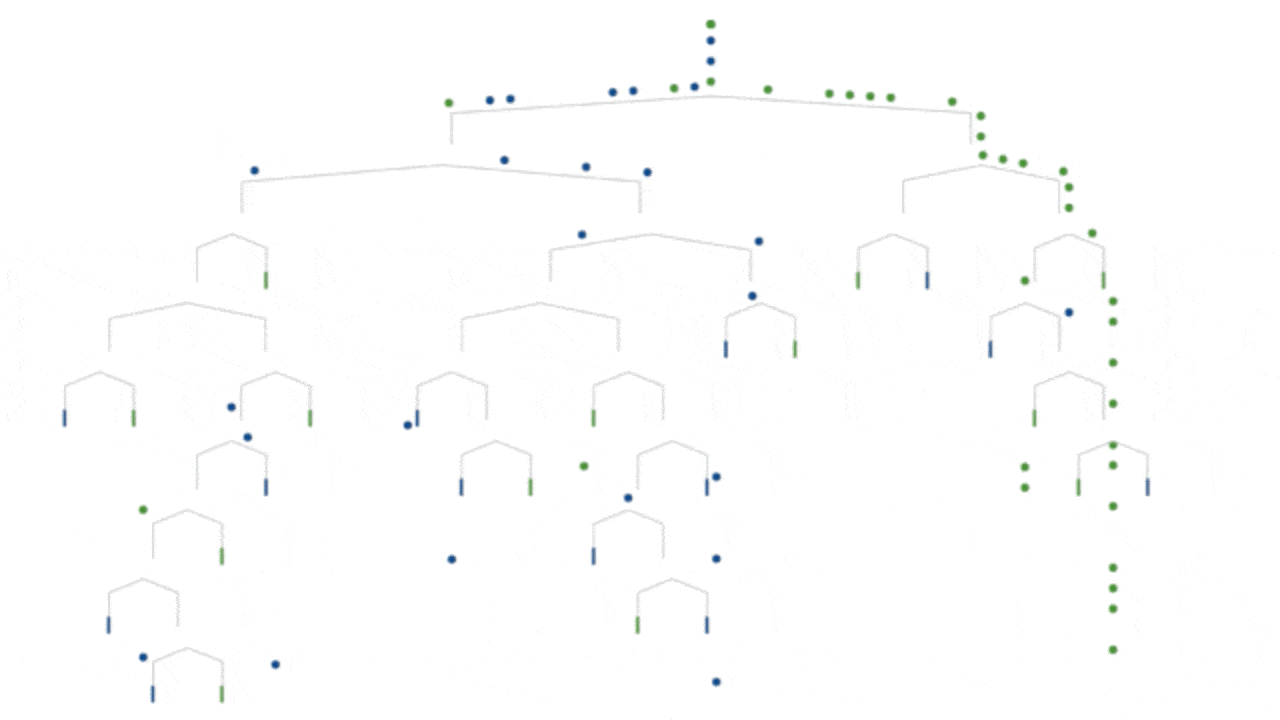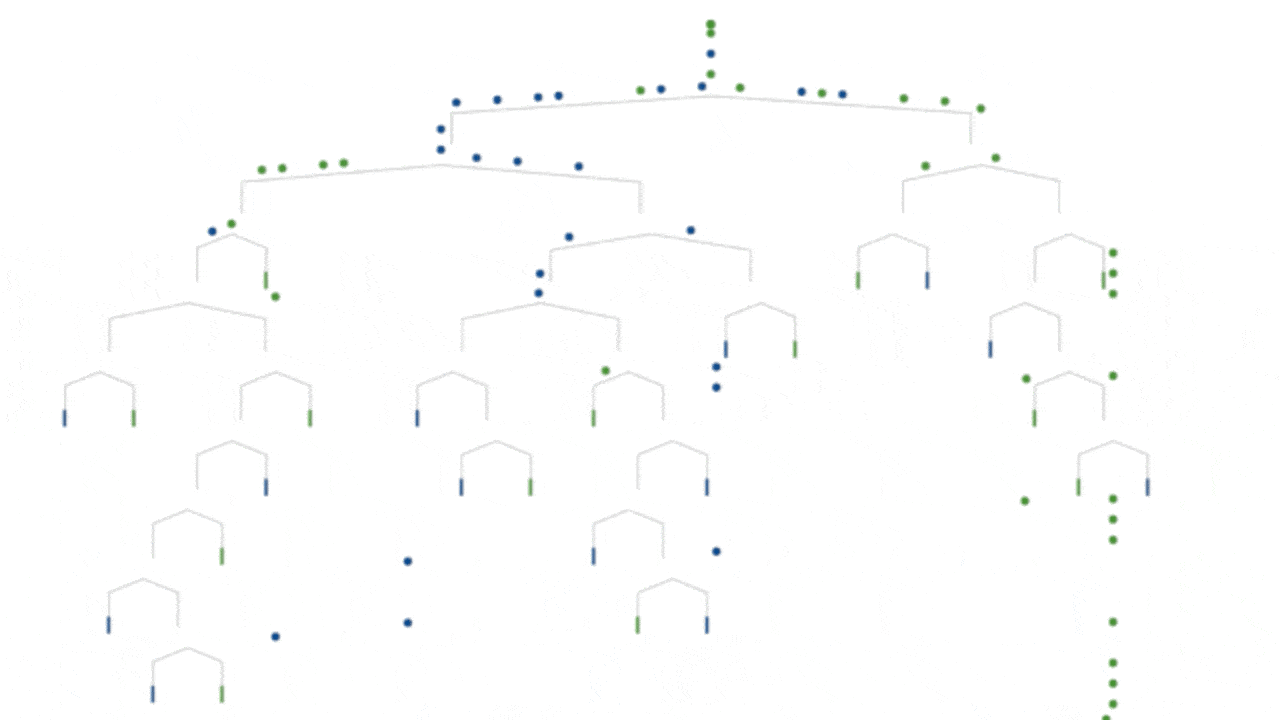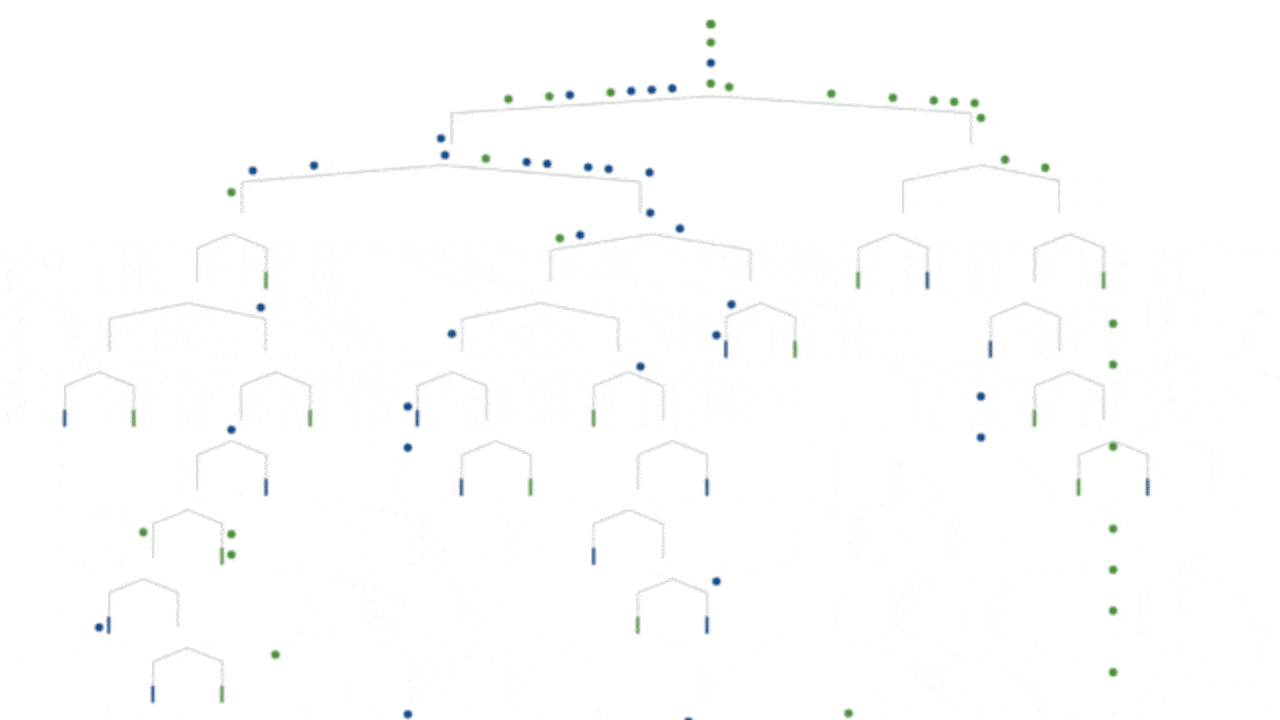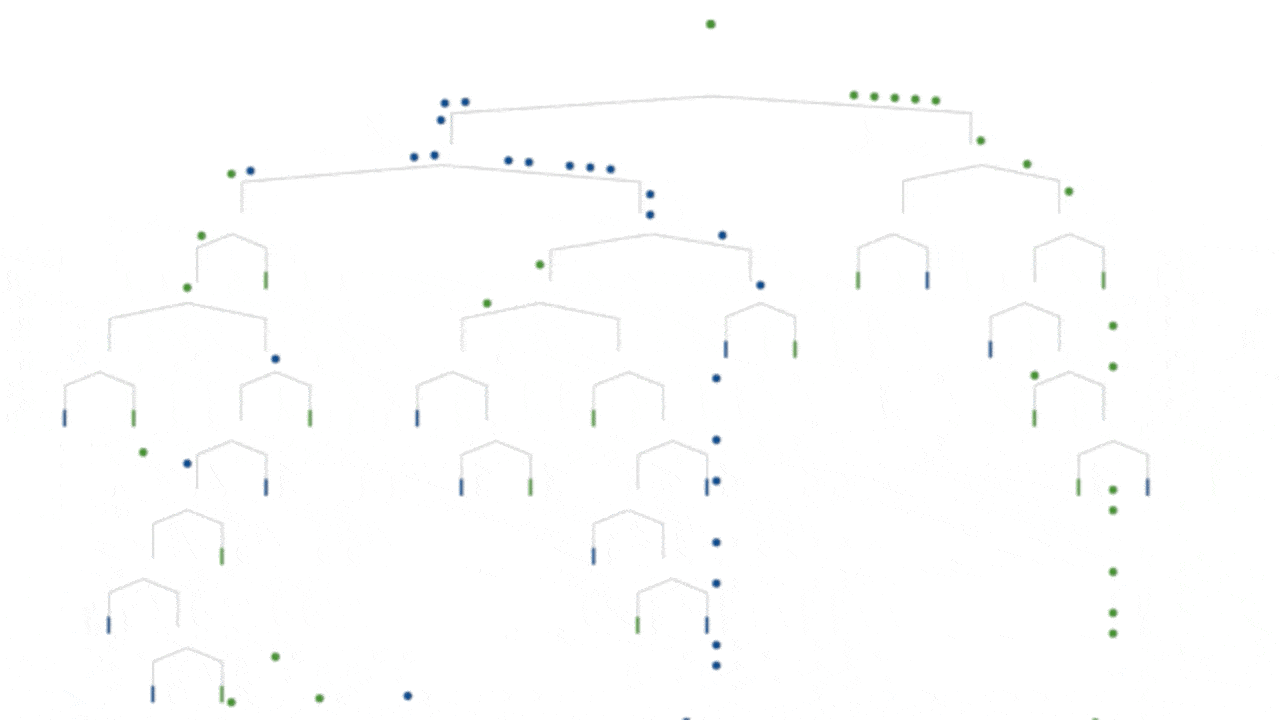
Concepts and bullet points can only take one so far in understanding. When people ask “What is machine learning?”, they often want to see what it is and what it does. Below are some visual representations of machine learning models, with accompanying links for further information. Even more resources can be found at the bottom of this article.
Decision tree model
Gaussian mixture model
Dropout neural network
Merging chrominance and luminance using Convolutional Neural Networks
How We Get Machines to Learn
There are different approaches to getting machines to learn, from using basic decision trees to clustering to layers of artificial neural networks (the latter of which has given way to deep learning), depending on what task you’re trying to accomplish and the type and amount of data that you have available. This dynamic sees itself played out in applications as varying as medical diagnostics or self-driving cars.
While emphasis is often placed on choosing the best learning algorithm, researchers have found that some of the most interesting questions arise out of none of the available machine learning algorithms performing to par. Most of the time this is a problem with training data, but this also occurs when working with machine learning in new domains.
Research done when working on real applications often drives progress in the field, and reasons are twofold: 1. Tendency to discover boundaries and limitations of existing methods 2. Researchers and developers working with domain experts and leveraging time and expertise to improve system performance.
Sometimes this also occurs by “accident.” We might consider model ensembles, or combinations of many learning algorithms to improve accuracy, to be one example. Teams competing for the 2009 Netflix Price found that they got their best results when combining their learners with other team’s learners, resulting in an improved recommendation algorithm (read Netflix’s blog for more on why they didn’t end up using this ensemble).
One important point (based on interviews and conversations with experts in the field), in terms of application within business and elsewhere, is that machine learning is not just, or even about, automation, an often misunderstood concept. If you think this way, you’re bound to miss the valuable insights that machines can provide and the resulting opportunities (rethinking an entire business model, for example, as has been in industries like manufacturing and agriculture).
Machines that learn are useful to humans because, with all of their processing power, they’re able to more quickly highlight or find patterns in big (or other) data that would have otherwise been missed by human beings. Machine learning is a tool that can be used to enhance humans’ abilities to solve problems and make informed inferences on a wide range of problems, from helping diagnose diseases to coming up with solutions for global climate change.
Challenges and Limitations
“Machine learning can’t get something from nothing…what it does is get more from less.” – Dr. Pedro Domingo, University of Washington
The two biggest, historical (and ongoing) problems in machine learning have involved overfitting (in which the model exhibits bias towards the training data and does not generalize to new data, and/or variance i.e. learns random things when trained on new data) and dimensionality (algorithms with more features work in higher/multiple dimensions, making understanding the data more difficult). Having access to a large enough data set has in some cases also been a primary problem.
One of the most common mistakes among machine learning beginners is testing training data successfully and having the illusion of success; Domingo (and others) emphasize the importance of keeping some of the data set separate when testing models, and only using that reserved data to test a chosen model, followed by learning on the whole data set.
When a learning algorithm (i.e. learner) is not working, often the quicker path to success is to feed the machine more data, the availability of which is by now well-known as a primary driver of progress in machine and deep learning algorithms in recent years; however, this can lead to issues with scalability, in which we have more data but time to learn that data remains an issue.
In terms of purpose, machine learning is not an end or a solution in and of itself. Furthermore, attempting to use it as a blanket solution i.e. “BLANK” is not a useful exercise; instead, coming to the table with a problem or objective is often best driven by a more specific question – “BLANK”.
Deep Learning and Modern Developments in Neural Networks
Deep learning involves the study and design of machine algorithms for learning good representation of data at multiple levels of abstraction (ways of arranging computer systems). Recent publicity of deep learning through DeepMind, Facebook, and other institutions has highlighted it as the “next frontier” of machine learning.
The International Conference on Machine Learning (ICML) is widely regarded as one of the most important in the world. This year’s took place in June in New York City, and it brought together researchers from all over the world who are working on addressing the current challenges in deep learning:
Unsupervised learning in small data sets
Simulation-based learning and transferability to the real world
Deep-learning systems have made great gains over the past decade in domains like bject detection and recognition, text-to-speech, information retrieval and others. Research is now focused on developing data-efficient machine learning i.e. deep learning systems that can learn more efficiently, with the same performance in less time and with less data, in cutting-edge domains like personalized healthcare, robot reinforcement learning, sentiment analysis, and others.
Key Takeaways in Applying Machine Learning
Below is a selection of best-practices and concepts of applying machine learning that we’ve collated from our interviews for out podcast series, and from select sources cited at the end of this article. We hope that some of these principles will clarify how ML is used, and how to avoid some of the common pitfalls that companies and researchers might be vulnerable to in starting off on an ML-related project.
Arguably the most important factor in successful machine learning projects is the features used to describe the data (which are domain-specific), and having adequate data to train your models in the first place
Most of the time when algorithms don’t perform well, it’s due a to a problem with the training data (i.e. insufficient amounts/skewed data; noisy data; or insufficient features describing the data for making decisions
“Simplicity does not imply accuracy” – there is (according to Domingo) no given connection between number of parameters of a model and tendency to overfit
Obtaining experimental data (as opposed to observational data, over which we have no control) should be done if possible (for example, data gleaned from sending different variations of an email to a random audience sampling)
Whether or not we label data causal or correlative, the more important point is to predict the effects of our actions
Always set aside a portion of your training data set for cross validation; you want your chosen classifier or learning algorithm to perform well on fresh data
Emerj For Enterprise Leaders
Emerj helps businesses get started with artificial intelligence and machine learning. Using our AI Opportunity Landscapes, clients can discover the largest opportunities for automation and AI at their companies and pick the highest ROI first AI projects. Instead of wasting money on pilot projects that are destined to fail, Emerj helps clients do business with the right AI vendors for them and increase their AI project success rate.
One of the best ways to learn about artificial intelligence concepts is to learn from the research and applications of the smartest minds in the field. Below is a brief list of some of our interviews with machine learning researchers, many of which may be of interest for readers who want to explore these topics further:
The Science of Machine Learning with Dr. Yoshua Bengio (one of the world’s foremost ML experts)
UPENN’s Dr. Lyle Ungar on Using Machine Learning to See Patterns and Meaning on Social Media
Silicon Valley AI Consultant Lorien Pratt on the Business Use Cases of Machine Learning
Artificial intelligence has been making headlines in recent weeks as major tech companies like Google and Microsoft have announced new tools powered by the technology.
Experts say the rapid growth of AI could affect manufacturing, health care and other industries.
The Canton Repository spoke to Shawn Campbell, an assistant professor of computer science and cybersecurity at Malone University, about the rise of AI technology and what it means for the future.
What is artificial intelligence?
It is the ability for computers to perform functions typically done by humans, including decision making or speech or visual recognition. The study has been around since the 1950s, according to an article from Harvard University.
Campbell said one type of AI commonly used in the medical field is expert systems. This technology uses knowledge databases to offer advice or make decisions regarding medical diagnoses.
How are Microsoft and Google using ChatGPT?
A developer called OpenAI launched an AI chatbot in November 2022 known as ChatGPT. Users can interact with the chatbot and receive conversational responses.
Campbell said the rise of this technology has created competition between Microsoft and Google. Microsoft plans to invest billions into ChatGPT, and recently announced AI upgrades to its search engine, Bing. Google, meanwhile, has introduced new AI features in Gmail and Google Docs that create text.
The major tech companies are in an arms race, Campbell said, to see who can develop the best AI technology.
Will the growth of AI affect job opportunities in different industries?
There is some concern that AI technology will replace jobs traditionally held by humans. In some cases, it’s already happened. For example, fast-food chain White Castle started installing hamburger-flipping robots in some of its locations in 2020 to reduce human contact with food during the cooking process.
Campbell said it’s possible that AI will result in fewer employees doing certain tasks.
“If you have a product line that had 100 people on it, and they get a new type of machine in and kind of redesign the process, then they do it with 80 people or 60 people, … I do think you’re going to find more of the same jobs being done by fewer people, and those people being freed up to do other tasks, essentially,” Campbell said.
Some worry that trucking jobs will disappear if developers figure out self-driving technology, but Campbell doesn’t expect that to happen anytime soon.
What kind of changes will AI like ChatGPT have on daily life?
Campbell said he expects AI to become a tool that makes life easier, noting that technology like adaptive cruise control and camera tools that let users remove unwanted objects from the background of photos involve AI and are already used on a daily basis.
“I think that’s really the progression it will follow. … It’s being used as a tool, and it’s making people’s jobs easier, or making a long drive more enjoyable and safer as well,” he said.
One of the biggest changes Campbell expects is for data science and analytics to be emphasized more in education. Some employers are already paying for their employees to receive data analytics and literacy training, he said, and Malone University recently added a data analytics major.
Campbell predicted these skills will become important in the job market and that educational institutions may start incorporating data analytics into general curriculum, like they do with writing and public speaking.