install modules like numpy,pygame,matplotlib and graphviz
pip install neat-python
Description
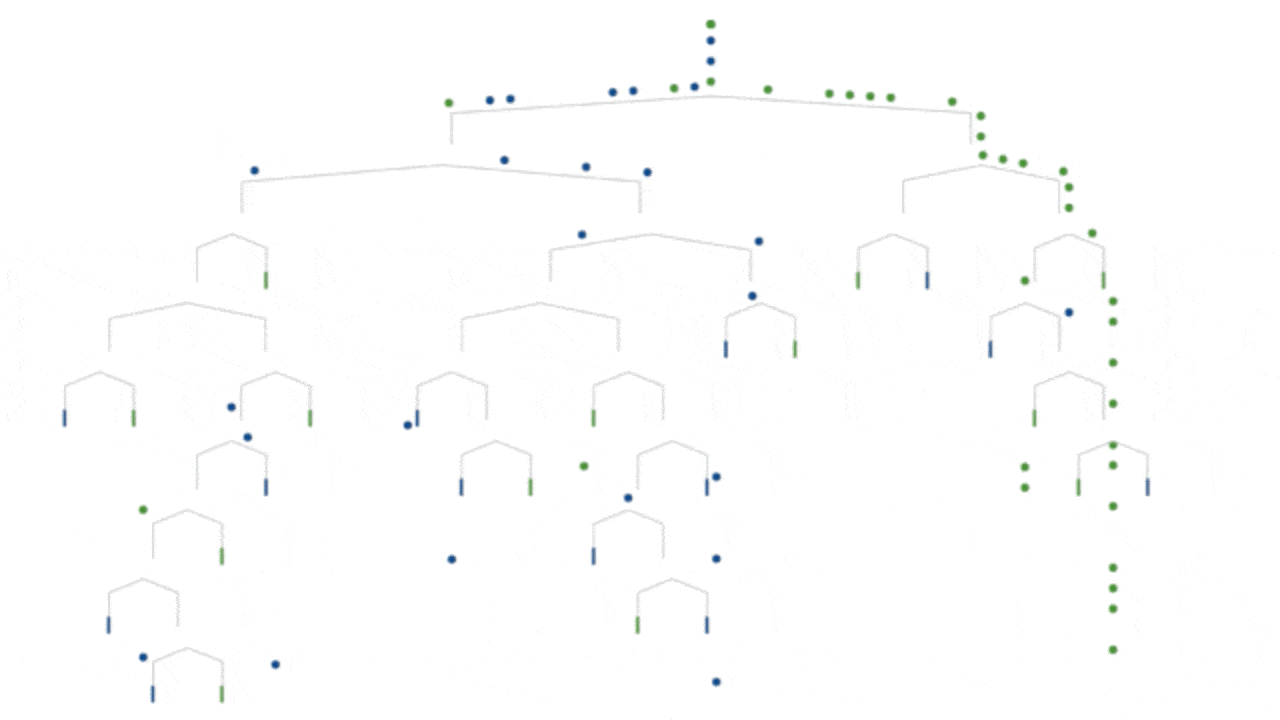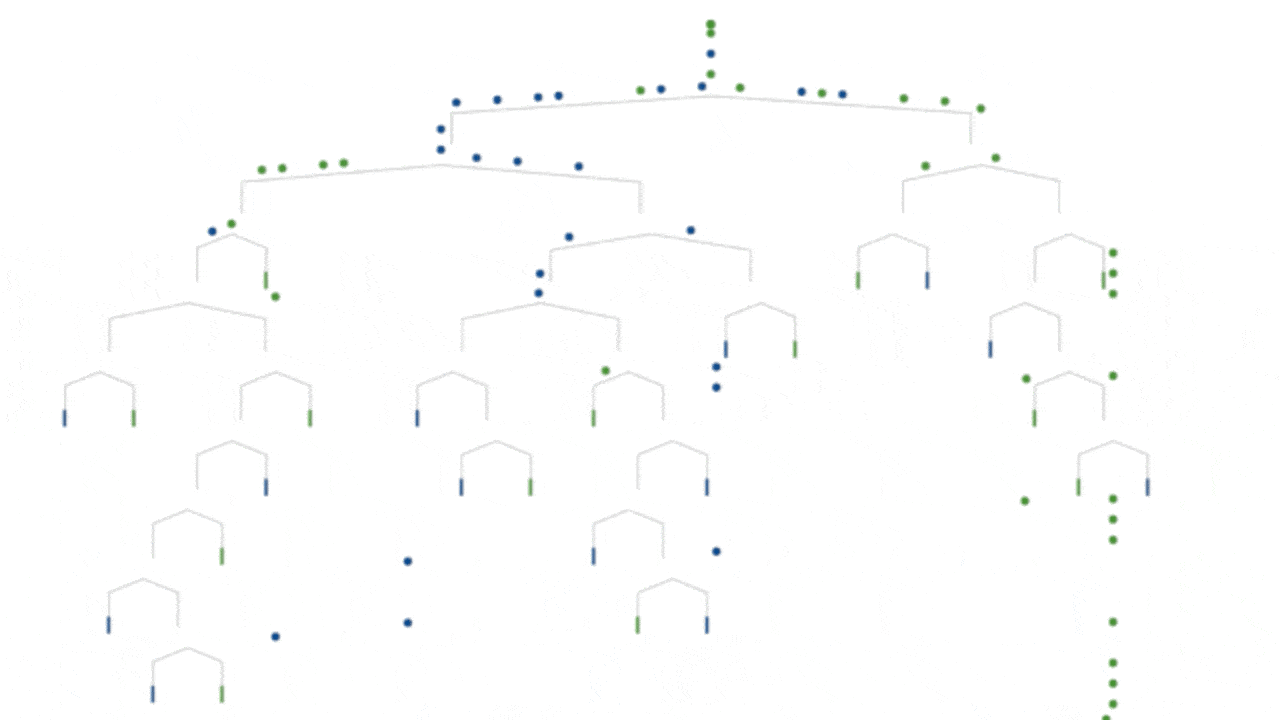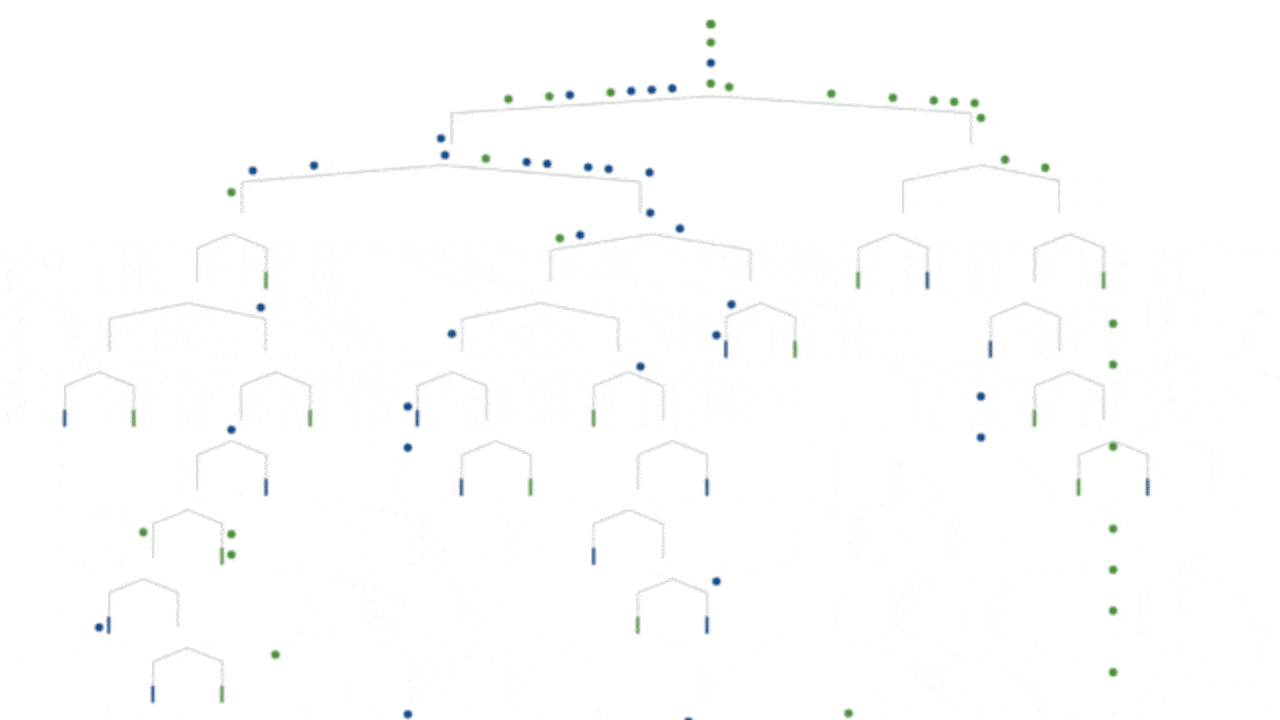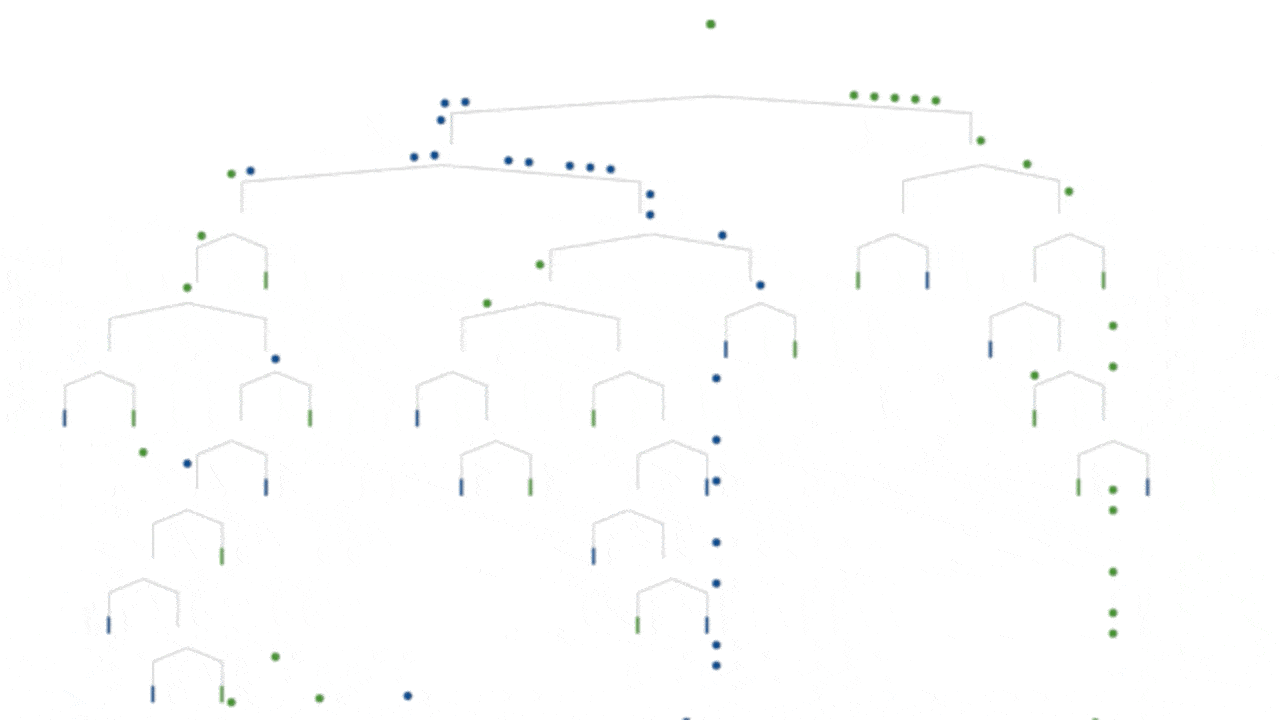
NeuroEvolution of Augmenting Topologies (NEAT) is a genetic algorithm (GA) for the generation of evolving artificial neural networks (a neuroevolution technique) developed by Ken Stanley in 2002 while at The University of Texas at Austin. It alters both the weighting parameters and structures of networks, attempting to find a balance between the fitness of evolved solutions and their diversity. It is based on applying three key techniques: tracking genes with history markers to allow crossover among topologies, applying speciation (the evolution of species) to preserve innovations, and developing topologies incrementally from simple initial structures (“complexifying”).
Traditionally a neural network topology is chosen by a human experimenter, and effective connection weight values are learned through a training procedure. This yields a situation whereby a trial and error process may be necessary in order to determine an appropriate topology. NEAT is an example of a topology and weight evolving artificial neural network (TWEANN) which attempts to simultaneously learn weight values and an appropriate topology for a neural network.
In order to encode the network into a phenotype for the GA, NEAT uses a direct encoding scheme which means every connection and neuron is explicitly represented. This is in contrast to indirect encoding schemes which define rules that allow the network to be constructed without explicitly representing every connection and neuron allowing for more compact representation.
The NEAT approach begins with a perceptron-like feed-forward network of only input neurons and output neurons. As evolution progresses through discrete steps, the complexity of the network’s topology may grow, either by inserting a new neuron into a connection path, or by creating a new connection between (formerly unconnected) neurons.
Competing conventions
The competing conventions problem arises when there is more than one way of representing information in a phenotype. For example, if a genome contains neurons A, B and C and is represented by [A B C], if this genome is crossed with an identical genome (in terms of functionality) but ordered [C B A] crossover will yield children that are missing information ([A B A] or [C B C]), in fact 1/3 of the information has been lost in this example. NEAT solves this problem by tracking the history of genes by the use of a global innovation number which increases as new genes are added. When adding a new gene the global innovation number is incremented and assigned to that gene. Thus the higher the number the more recently the gene was added. For a particular generation if an identical mutation occurs in more than one genome they are both given the same number, beyond that however the mutation number will remain unchanged indefinitely.
These innovation numbers allow NEAT to match up genes which can be crossed with each other
The application of machine learning is growing exponentially into every branch of business and science, including medical science. This book presents the integration of machine learning (ML) and deep learning (DL) algorithms that can be applied in the healthcare sector to reduce the time required by doctors, radiologists, and other medical professionals for analyzing, predicting, and diagnosing the conditions with accurate results. The book offers important key aspects in the development and implementation of ML and DL approaches toward developing prediction tools and models and improving medical diagnosis.
The contributors explore the recent trends, innovations, challenges, and solutions, as well as case studies of the applications of ML and DL in intelligent system-based disease diagnosis. The chapters also highlight the basics and the need for applying mathematical aspects with reference to the development of new medical models. Authors also explore ML and DL in relation to artificial intelligence (AI) prediction tools, the discovery of drugs, neuroscience, diagnosis in multiple imaging modalities, and pattern recognition approaches to functional magnetic resonance imaging images.
This book is for students and researchers of computer science and engineering, electronics and communication engineering, and information technology; for biomedical engineering researchers, academicians, and educators; and for students and professionals in other areas of the healthcare sector.
Presents key aspects in the development and the implementation of ML and DL approaches toward developing prediction tools, models, and improving medical diagnosis
Discusses the recent trends, innovations, challenges, solutions, and applications of intelligent system-based disease diagnosis
Examines DL theories, models, and tools to enhance health information systems
Explores ML and DL in relation to AI prediction tools, discovery of drugs, neuroscience, and diagnosis in multiple imaging modalities
Dr. K. Gayathri Devi is a Professor at the Department of Electronics and Communication Engineering, Dr. N.G.P Institute of Technology, Tamil Nadu, India.
Dr. Kishore Balasubramanian is an Assistant Professor (Senior Scale) at the Department of EEE at Dr. Mahalingam College of Engineering & Technology, Tamil Nadu, India.
Dr. Le Anh Ngoc is a Director of Swinburne Innovation Space and Professor in Swinburne University of Technology (Vietnam).
Table of Contents
Chapter 1. A Comprehensive Study on MLP and CNN, and the Implementation of Multi-Class Image Classification using Deep CNN
S. P. BalamuruganChapter 2. An Efficient Technique for Image Compression and Quality Retrieval in Diagnosis of Brain Tumour Hyper Spectral Image
V. V. Teresa, J. Dhanasekar, V. Gurunathan, and T. Sathiyapriya
Chapter 3. Classification of Breast Thermograms using a Multi-layer Perceptron with Back Propagation Learning
Aayesha Hakim and R. N. Awale
Chapter 4. Neural Networks for Medical Image Computing
V. A. Pravina, P. K. Poonguzhali, and A. Kishore Kumar
Chapter 5. Recent Trends in Bio-Medical Waste, Challenges and Opportunities
S. Kannadhasan and R. Nagarajan
Chapter 6. Teager-Kaiser Boost Clustered Segmentation of Retinal Fundus Images for Glaucoma Detection
P M Siva Raja, R P Sumithra, and K Ramanan
Chapter 7. IoT-Based Deep Neural Network Approach for Heart Rate and SpO2 Prediction
Madhusudan G. Lanjewar, Rajesh K. Parate, Rupesh D. Wakodikar, and Anil J. Thusoo
Chapter 8. An Intelligent System for Diagnosis and Prediction of Breast Cancer Malignant Features using Machine Learning Algorithms
Ritu Aggarwal
Chapter 9. Medical Image Classification with Artificial and Deep Convolutional Neural Networks: A Comparative Study
Amen Bidani, Mohamed Salah Gouider, and Carlos M Travieso-Gonzalez
Chapter 10. Convolutional Neural Network for Classification of Skin Cancer Images
Giang Son Tran, Quoc Viet Kieu, and Thi Phuong Nghiem
Chapter 11. Application of Artificial Intelligence in Medical Imaging
Sampurna Panda and Rakesh Kumar Dhaka
Chapter 12. Machine Learning Algorithms Used in Medical Field with a Case Study
M. Jayasanthi and R. Kalaivani
Chapter 13. Dual Customized U-Net-based Based Automated Diagnosis of Glaucoma
C. Thirumarai Selvi, J. Amudha, and R. Sudhakar
Chapter 14. MuSCF-Net: Multi-scale, Multi-Channel Feature Network using Resnet-Based Attention Mechanism for Breast Histopathological Image Classification
Meenakshi M. Pawer, Suvarna D. Pujari, Swati P. Pawar, and Sanjay N. Talbar
Chapter 15. Artificial Intelligence is Revolutionizing Cancer Research
B. Sudha, K. Suganya, K. Swathi, and S. Sumathi
Chapter 16. Deep Learning to Diagnose Diseases and Security in 5G Healthcare Informatics
Partha Ghosh
Chapter 17. New Approaches in Machine-based Image Analysis for Medical Oncology
E. Francy Irudaya Rani, T. LurthuPushparaj, E. Fantin Irudaya Raj, and M. Appadurai
Chapter 18. Performance Analysis of Deep Convolutional Neural Networks for Diagnosing COVID-19: Data to Deployment
K. Deepti
Chapter 19. Stacked Auto Encoder Deep Neural Network with Principal Components Analysis for Identification of Chronic Kidney Disease
Machine learning is a hot topic in research and industry, with new methodologies developed all the time. The speed and complexity of the field makes keeping up with new techniques difficult even for experts — and potentially overwhelming for beginners.
To demystify machine learning and to offer a learning path for those who are new to the core concepts, let’s look at ten different methods, including simple descriptions, visualizations, and examples for each one.
A machine learning algorithm, also called model, is a mathematical expression that represents data in the context of a problem, often a business problem. The aim is to go from data to insight. For example, if an online retailer wants to anticipate sales for the next quarter, they might use a machine learning algorithm that predicts those sales based on past sales and other relevant data. Similarly, a windmill manufacturer might visually monitor important equipment and feed the video data through algorithms trained to identify dangerous cracks.
The ten methods described offer an overview — and a foundation you can build on as you hone your machine learning knowledge and skill:
Regression
Classification
Clustering
Dimensionality Reduction
Ensemble Methods
Neural Nets and Deep Learning
Transfer Learning
Reinforcement Learning
Natural Language Processing
Word Embeddings
One last thing before we jump in. Let’s distinguish between two general categories of machine learning: supervised and unsupervised. We apply supervised ML techniques when we have a piece of data that we want to predict or explain. We do so by using previous data of inputs and outputs to predict an output based on a new input. For example, you could use supervised ML techniques to help a service business that wants to predict the number of new users who will sign up for the service next month. By contrast, unsupervised ML looks at ways to relate and group data points without the use of a target variable to predict. In other words, it evaluates data in terms of traits and uses the traits to form clusters of items that are similar to one another. For example, you could use unsupervised learning techniques to help a retailer that wants to segment products with similar characteristics — without having to specify in advance which characteristics to use.
Regression
Regression methods fall within the category of supervised ML. They help to predict or explain a particular numerical value based on a set of prior data, for example predicting the price of a property based on previous pricing data for similar properties.
The simplest method is linear regression where we use the mathematical equation of the line (y = m * x + b) to model a data set. We train a linear regression model with many data pairs (x, y) by calculating the position and slope of a line that minimizes the total distance between all of the data points and the line. In other words, we calculate the slope (m) and the y-intercept (b) for a line that best approximates the observations in the data.
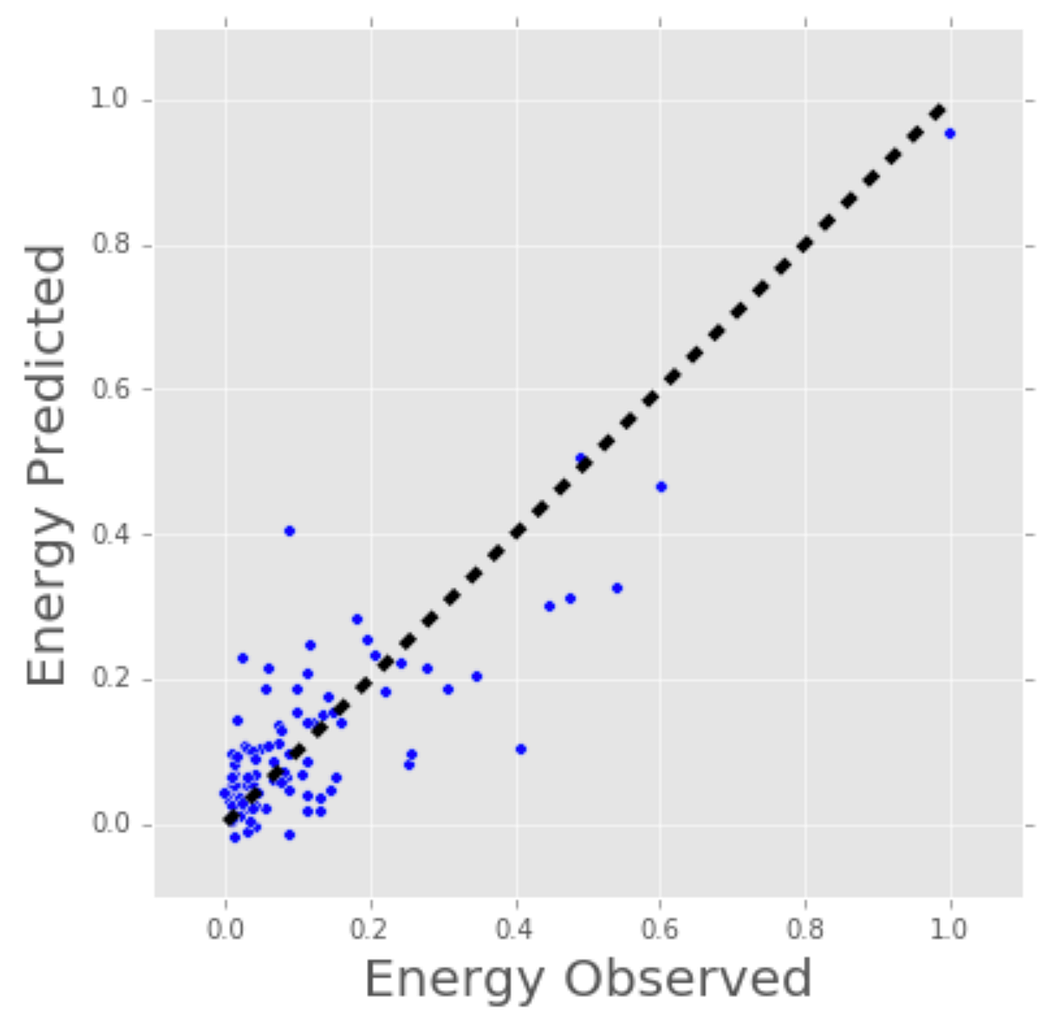
Let’s consider a more a concrete example of linear regression. I once used a linear regression to predict the energy consumption (in kWh) of certain buildings by gathering together the age of the building, number of stories, square feet and the number of plugged wall equipment. Since there were more than one input (age, square feet, etc…), I used a multi-variable linear regression. The principle was the same as a simple one-to-one linear regression, but in this case the “line” I created occurred in multi-dimensional space based on the number of variables.
The plot below shows how well the linear regression model fit the actual energy consumption of building. Now imagine that you have access to the characteristics of a building (age, square feet, etc…) but you don’t know the energy consumption. In this case, we can use the fitted line to approximate the energy consumption of the particular building.
Note that you can also use linear regression to estimate the weight of each factor that contributes to the final prediction of consumed energy. For example, once you have a formula, you can determine whether age, size, or height is most important.
Linear Regression Model Estimates of Building’s Energy Consumption (kWh).
Regression techniques run the gamut from simple (like linear regression) to complex (like regularized linear regression, polynomial regression, decision trees and random forest regressions, neural nets, among others). But don’t get bogged down: start by studying simple linear regression, master the techniques, and move on from there.
Classification
Another class of supervised ML, classification methods predict or explain a class value. For example, they can help predict whether or not an online customer will buy a product. The output can be yes or no: buyer or not buyer. But classification methods aren’t limited to two classes. For example, a classification method could help to assess whether a given image contains a car or a truck. In this case, the output will be 3 different values: 1) the image contains a car, 2) the image contains a truck, or 3) the image contains neither a car nor a truck.
The simplest classification algorithm is logistic regression — which makes it sounds like a regression method, but it’s not. Logistic regression estimates the probability of an occurrence of an event based on one or more inputs.
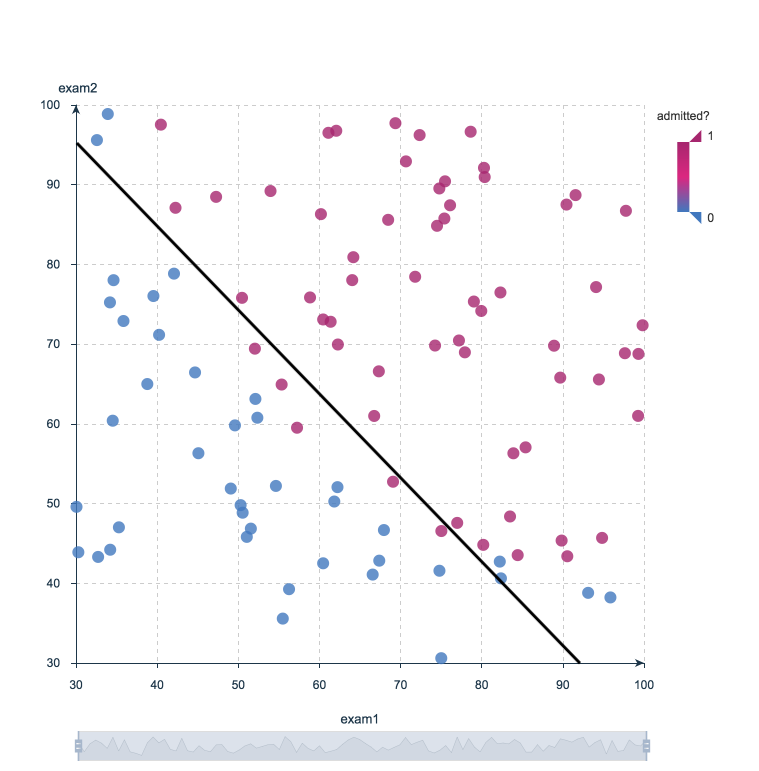
For instance, a logistic regression can take as inputs two exam scores for a student in order to estimate the probability that the student will get admitted to a particular college. Because the estimate is a probability, the output is a number between 0 and 1, where 1 represents complete certainty. For the student, if the estimated probability is greater than 0.5, then we predict that he or she will be admitted. If the estimated probabiliy is less than 0.5, we predict the he or she will be refused.
The chart below plots the scores of previous students along with whether they were admitted. Logistic regression allows us to draw a line that represents the decision boundary.
Logistic Regression Decision Boundary: Admitted to College or Not?
Because logistic regression is the simplest classification model, it’s a good place to start for classification. As you progress, you can dive into non-linear classifiers such as decision trees, random forests, support vector machines, and neural nets, among others.
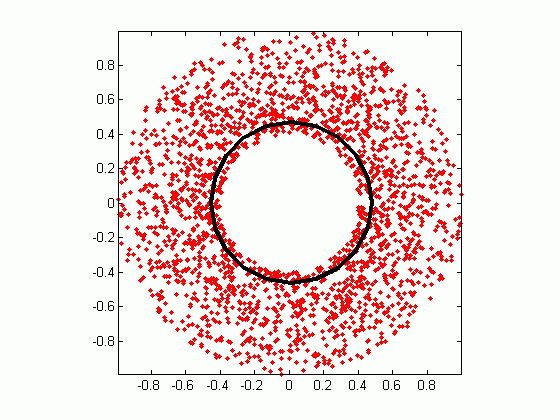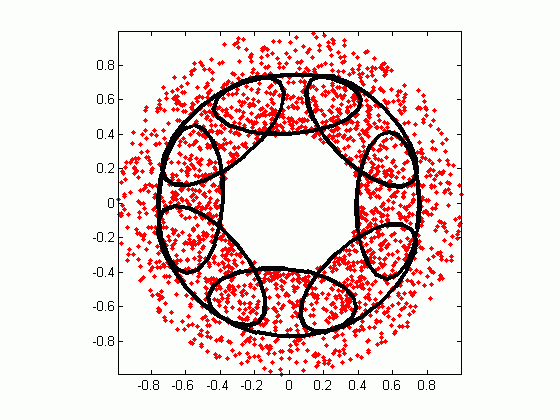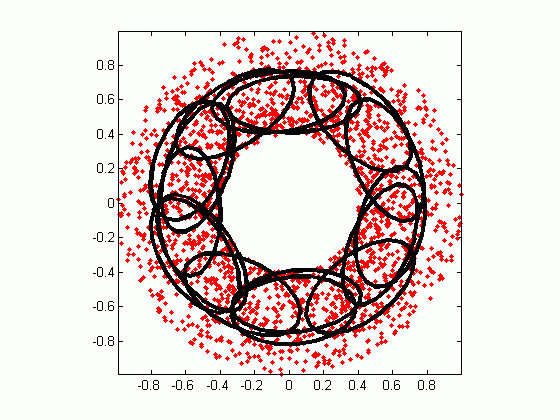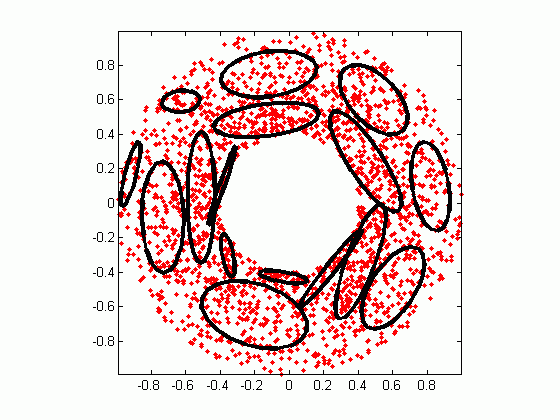
Clustering
With clustering methods, we get into the category of unsupervised ML because their goal is to group or cluster observations that have similar characteristics. Clustering methods don’t use output information for training, but instead let the algorithm define the output. In clustering methods, we can only use visualizations to inspect the quality of the solution.
The most popular clustering method is K-Means, where “K” represents the number of clusters that the user chooses to create. (Note that there are various techniques for choosing the value of K, such as the elbow method.)
Roughly, what K-Means does with the data points:
Randomly chooses K centers within the data.
Assigns each data point to the closest of the randomly created centers.
Re-computes the center of each cluster.
If centers don’t change (or change very little), the process is finished. Otherwise, we return to step 2. (To prevent ending up in an infinite loop if the centers continue to change, set a maximum number of iterations in advance.)
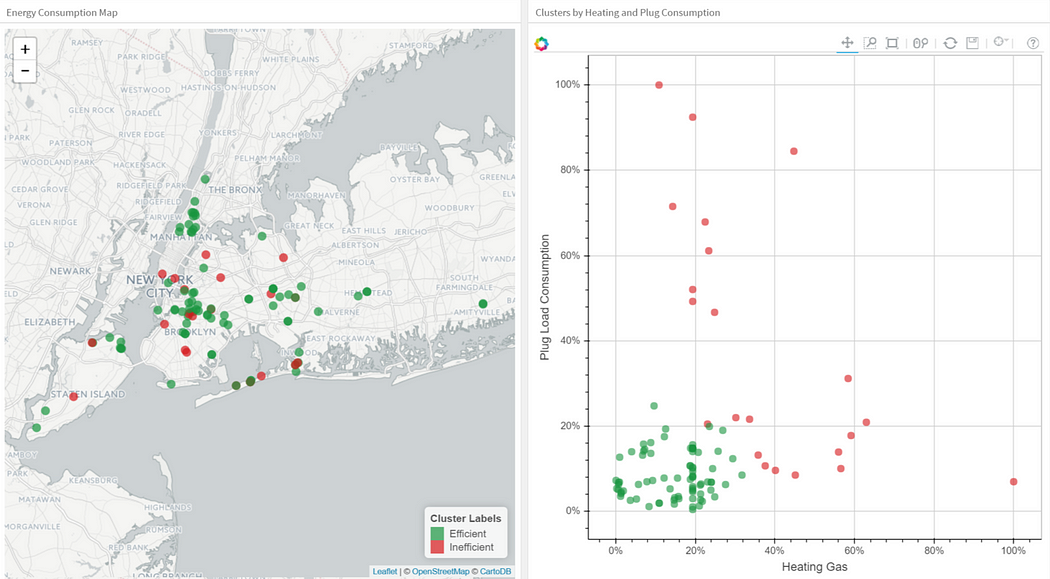
The next plot applies K-Means to a data set of buildings. Each column in the plot indicates the efficiency for each building. The four measurements are related to air conditioning, plugged-in equipment (microwaves, refrigerators, etc…), domestic gas, and heating gas. We chose K=2 for clustering, which makes it easy to interpret one of the clusters as the group of efficient buildings and the other cluster as the group of inefficient buildings. To the left you see the location of the buildings and to right you see two of the four dimensions we used as inputs: plugged-in equipment and heating gas.
Clustering Buildings into Efficient (Green) and Inefficient (Red) Groups.
As you explore clustering, you’ll encounter very useful algorithms such as Density-Based Spatial Clustering of Applications with Noise (DBSCAN), Mean Shift Clustering, Agglomerative Hierarchical Clustering, Expectation–Maximization Clustering using Gaussian Mixture Models, among others.
Dimensionality Reduction
As the name suggests, we use dimensionality reduction to remove the least important information (sometime redundant columns) from a data set. In practice, I often see data sets with hundreds or even thousands of columns (also called features), so reducing the total number is vital. For instance, images can include thousands of pixels, not all of which matter to your analysis. Or when testing microchips within the manufacturing process, you might have thousands of measurements and tests applied to every chip, many of which provide redundant information. In these cases, you need dimensionality reduction algorithms to make the data set manageable.
The most popular dimensionality reduction method is Principal Component Analysis (PCA), which reduces the dimension of the feature space by finding new vectors that maximize the linear variation of the data. PCA can reduce the dimension of the data dramatically and without losing too much information when the linear correlations of the data are strong. (And in fact you can also measure the actual extent of the information loss and adjust accordingly.)
Another popular method is t-Stochastic Neighbor Embedding (t-SNE), which does non-linear dimensionality reduction. People typically use t-SNE for data visualization, but you can also use it for machine learning tasks like reducing the feature space and clustering, to mention just a few.
The next plot shows an analysis of the MNIST database of handwritten digits. MNIST contains thousands of images of digits from 0 to 9, which researchers use to test their clustering and classification algorithms. Each row of the data set is a vectorized version of the original image (size 28 x 28 = 784) and a label for each image (zero, one, two, three, …, nine). Note that we’re therefore reducing the dimensionality from 784 (pixels) to 2 (dimensions in our visualization). Projecting to two dimensions allows us to visualize the high-dimensional original data set.
t-SNE Iterations on MNIST Database of Handwritten Digits.
Ensemble Methods
Imagine you’ve decided to build a bicycle because you are not feeling happy with the options available in stores and online. You might begin by finding the best of each part you need. Once you assemble all these great parts, the resulting bike will outshine all the other options.
Ensemble methods use this same idea of combining several predictive models (supervised ML) to get higher quality predictions than each of the models could provide on its own. For example, the Random Forest algorithms is an ensemble method that combines many Decision Trees trained with different samples of the data sets. As a result, the quality of the predictions of a Random Forest is higher than the quality of the predictions estimated with a single Decision Tree.
Think of ensemble methods as a way to reduce the variance and bias of a single machine learning model. That’s important because any given model may be accurate under certain conditions but inaccurate under other conditions. With another model, the relative accuracy might be reversed. By combining the two models, the quality of the predictions is balanced out.
The great majority of top winners of Kaggle competitions use ensemble methods of some kind. The most popular ensemble algorithms are Random Forest, XGBoost and LightGBM.
Neural Networks and Deep Learning
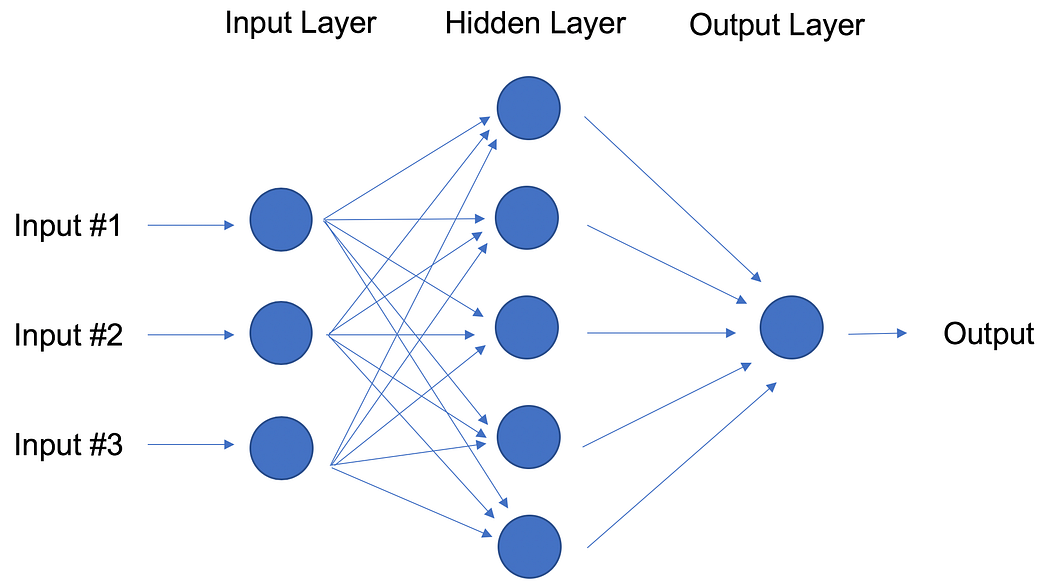
In contrast to linear and logistic regressions which are considered linear models, the objective of neural networks is to capture non-linear patterns in data by adding layers of parameters to the model. In the image below, the simple neural net has three inputs, a single hidden layer with five parameters, and an output layer.
Neural Network with One Hidden Layer.
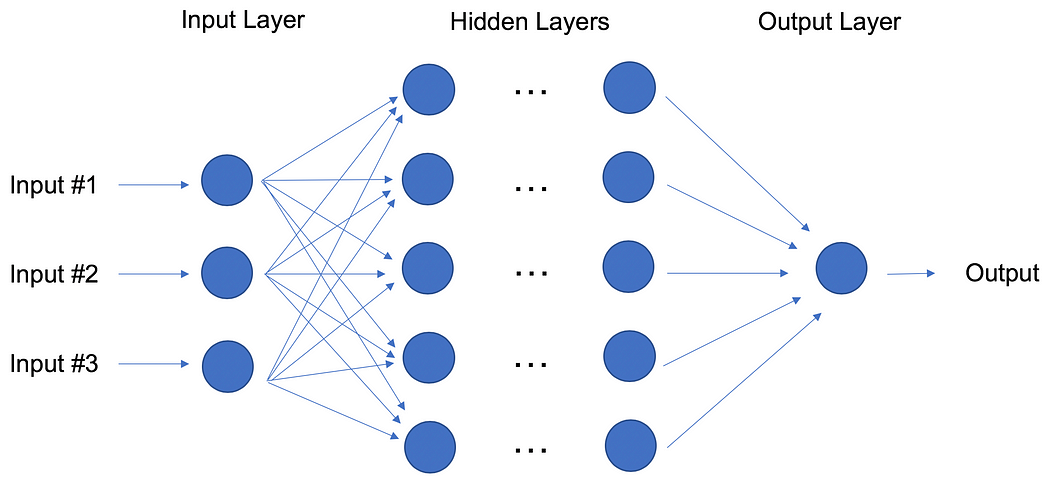
In fact, the structure of neural networks is flexible enough to build our well-known linear and logistic regression. The term Deep learning comes from a neural net with many hidden layers (see next Figure) and encapsulates a wide variety of architectures.
It’s especially difficult to keep up with developments in deep learning, in part because the research and industry communities have doubled down on their deep learning efforts, spawning whole new methodologies every day.
Deep Learning: Neural Network with Many Hidden Layers.
For the best performance, deep learning techniques require a lot of data — and a lot of compute power since the method is self-tuning many parameters within huge architectures. It quickly becomes clear why deep learning practitioners need very powerful computers enhanced with GPUs (graphical processing units).
In particular, deep learning techniques have been extremely successful in the areas of vision (image classification), text, audio and video. The most common software packages for deep learning are Tensorflow and PyTorch.
Transfer Learning
Let’s pretend that you’re a data scientist working in the retail industry. You’ve spent months training a high-quality model to classify images as shirts, t-shirts and polos. Your new task is to build a similar model to classify images of dresses as jeans, cargo, casual, and dress pants. Can you transfer the knowledge built into the first model and apply it to the second model? Yes, you can, using Transfer Learning.
Transfer Learning refers to re-using part of a previously trained neural net and adapting it to a new but similar task. Specifically, once you train a neural net using data for a task, you can transfer a fraction of the trained layers and combine them with a few new layers that you can train using the data of the new task. By adding a few layers, the new neural net can learn and adapt quickly to the new task.
The main advantage of transfer learning is that you need less data to train the neural net, which is particularly important because training for deep learning algorithms is expensive in terms of both time and money (computational resources) — and of course it’s often very difficult to find enough labeled data for the training.
Let’s return to our example and assume that for the shirt model you use a neural net with 20 hidden layers. After running a few experiments, you realize that you can transfer 18 of the shirt model layers and combine them with one new layer of parameters to train on the images of pants. The pants model would therefore have 19 hidden layers. The inputs and outputs of the two tasks are different but the re-usable layers may be summarizing information that is relevant to both, for example aspects of cloth.
Transfer learning has become more and more popular and there are now many solid pre-trained models available for common deep learning tasks like image and text classification.
Reinforcement Learning
Imagine a mouse in a maze trying to find hidden pieces of cheese. The more times we expose the mouse to the maze, the better it gets at finding the cheese. At first, the mouse might move randomly, but after some time, the mouse’s experience helps it realize which actions bring it closer to the cheese.
The process for the mouse mirrors what we do with Reinforcement Learning (RL) to train a system or a game. Generally speaking, RL is a machine learning method that helps an agent learn from experience. By recording actions and using a trial-and-error approach in a set environment, RL can maximize a cumulative reward. In our example, the mouse is the agent and the maze is the environment. The set of possible actions for the mouse are: move front, back, left or right. The reward is the cheese.
You can use RL when you have little to no historical data about a problem, because it doesn’t need information in advance (unlike traditional machine learning methods). In a RL framework, you learn from the data as you go. Not surprisingly, RL is especially successful with games, especially games of “perfect information” like chess and Go. With games, feedback from the agent and the environment comes quickly, allowing the model to learn fast. The downside of RL is that it can take a very long time to train if the problem is complex.
Just as IBM’s Deep Blue beat the best human chess player in 1997, AlphaGo, a RL-based algorithm, beat the best Go player in 2016. The current pioneers of RL are the teams at DeepMind in the UK. More on AlphaGo and DeepMind here.
On April, 2019, the OpenAI Five team was the first AI to beat a world champion team of e-sport Dota 2, a very complex video game that the OpenAI Five team chose because there were no RL algorithms that were able to win it at the time. The same AI team that beat Dota 2’s champion human team also developed a robotic hand that can reorient a block. Read more about the OpenAI Five team here.
You can tell that Reinforcement Learning is an especially powerful form of AI, and we’re sure to see more progress from these teams, but it’s also worth remembering the method’s limitations.
Natural Language Processing
A huge percentage of the world’s data and knowledge is in some form of human language. Can you imagine being able to read and comprehend thousands of books, articles and blogs in seconds? Obviously, computers can’t yet fully understand human text but we can train them to do certain tasks. For example, we can train our phones to autocomplete our text messages or to correct misspelled words. We can even teach a machine to have a simple conversation with a human.
Natural Language Processing (NLP) is not a machine learning method per se, but rather a widely used technique to prepare text for machine learning. Think of tons of text documents in a variety of formats (word, online blogs, ….). Most of these text documents will be full of typos, missing characters and other words that needed to be filtered out. At the moment, the most popular package for processing text is NLTK (Natural Language ToolKit), created by researchers at Stanford.
The simplest way to map text into a numerical representation is to compute the frequency of each word within each text document. Think of a matrix of integers where each row represents a text document and each column represents a word. This matrix representation of the word frequencies is commonly called Term Frequency Matrix (TFM). From there, we can create another popular matrix representation of a text document by dividing each entry on the matrix by a weight of how important each word is within the entire corpus of documents. We call this method Term Frequency Inverse Document Frequency (TFIDF) and it typically works better for machine learning tasks.
Word Embeddings
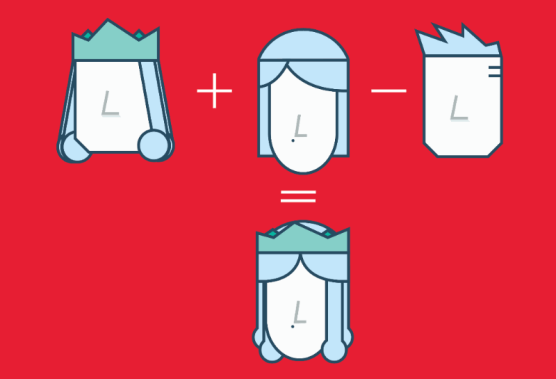
TFM and TFIDF are numerical representations of text documents that only consider frequency and weighted frequencies to represent text documents. By contrast, word embeddings can capture the context of a word in a document. With the word context, embeddings can quantify the similarity between words, which in turn allows us to do arithmetic with words.
Word2Vec is a method based on neural nets that maps words in a corpus to a numerical vector. We can then use these vectors to find synonyms, perform arithmetic operations with words, or to represent text documents (by taking the mean of all the word vectors in a document). For example, let’s assume that we use a sufficiently big corpus of text documents to estimate word embeddings. Let’s also assume that the words king, queen, man and woman are part of the corpus. Let say that vector(‘word’) is the numerical vector that represents the word ‘word’. To estimate vector(‘woman’), we can perform the arithmetic operation with vectors:
Word representations allow finding similarities between words by computing the cosine similarity between the vector representation of two words. The cosine similarity measures the angle between two vectors.
We compute word embeddings using machine learning methods, but that’s often a pre-step to applying a machine learning algorithm on top. For instance, suppose we have access to the tweets of several thousand Twitter users. Also suppose that we know which of these Twitter users bought a house. To predict the probability of a new Twitter user buying a house, we can combine Word2Vec with a logistic regression.
You can train word embeddings yourself or get a pre-trained (transfer learning) set of word vectors. To download pre-trained word vectors in 157 different languages, take a look at FastText.
Summary
I’ve tried to cover the ten most important machine learning methods: from the most basic to the bleeding edge. Studying these methods well and fully understanding the basics of each one can serve as a solid starting point for further study of more advanced algorithms and methods.
There is of course plenty of very important information left to cover, including things like quality metrics, cross validation, class imbalance in classification methods, and over-fitting a model, to mention just a few. Stay tuned.
All the visualizations of this blog were done using Watson Studio Desktop.
Daniel Faggella is Head of Research at Emerj. Called upon by the United Nations, World Bank, INTERPOL, and leading enterprises, Daniel is a globally sought-after expert on the competitive strategy implications of AI for business and government leaders.
Typing “what is machine learning?” into a Google search opens up a pandora’s box of forums, academic research, and false information – and the purpose of this article is to simplify the definition and understanding of machine learning thanks to the direct help from our panel of machine learning researchers.
At Emerj, the AI Research and Advisory Company, many of our enterprise clients feel as though they should be investing in machine learning projects, but they don’t have a strong grasp of what it is. We often direct them to this resource to get them started with the fundamentals of machine learning in business.
In addition to an informed, working definition of machine learning (ML), we detail the challenges and limitations of getting machines to ‘think,’ some of the issues being tackled today in deep learning (the frontier of machine learning), and key takeaways for developing machine learning applications for business use-cases.
This article will be broken up into the following sections:
What is machine learning?
How we arrived at our definition (IE: the perspective of expert researchers)
Machine learning basic concepts
Visual representation of ML models
How we get machines to learn
An overview of the challenges and limitations of ML
Brief introduction to deep learning
Works cited
Related ML interviews on Emerj
We put together this resource to help with whatever your area of curiosity about machine learning – so scroll along to your section of interest, or feel free to read the article in order, starting with our machine learning definition below:
What is Machine Learning?
* “Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
The above definition encapsulates the ideal objective or ultimate aim of machine learning, as expressed by many researchers in the field. The purpose of this article is to provide a business-minded reader with expert perspective on how machine learning is defined, and how it works. Machine learning and artificial intelligence share the same definition in the minds of many however, there are some distinct differences readers should recognize as well. References and related researcher interviews are included at the end of this article for further digging.
* How We Arrived at Our Definition:
(Our aggregate machine learning definition can be found at the beginning of this article)
As with any concept, machine learning may have a slightly different definition, depending on whom you ask. We combed the Internet to find five practical definitions from reputable sources:
“Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world.” – Nvidia
“Machine learning is the science of getting computers to act without being explicitly programmed.” – Stanford
“Machine learning is based on algorithms that can learn from data without relying on rules-based programming.”- McKinsey & Co.
“Machine learning algorithms can figure out how to perform important tasks by generalizing from examples.” – University of Washington
“The field of Machine Learning seeks to answer the question “How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?” – Carnegie Mellon University
We sent these definitions to experts whom we’ve interviewed and/or included in one of our past research consensuses, and asked them to respond with their favorite definition or to provide their own. Our introductory definition is meant to reflect the varied responses. Below are some of their responses:
Dr. Yoshua Bengio, Université de Montréal:
ML should not be defined by negatives (thus ruling 2 and 3). Here is my definition:
Machine learning research is part of research on artificial intelligence, seeking to provide knowledge to computers through data, observations and interacting with the world. That acquired knowledge allows computers to correctly generalize to new settings.
Dr. Danko Nikolic, CSC and Max-Planck Institute:
(edit of number 2 above): “Machine learning is the science of getting computers to act without being explicitly programmed, but instead letting them learn a few tricks on their own.”
Dr. Roman Yampolskiy, University of Louisville:
Machine Learning is the science of getting computers to learn as well as humans do or better.
Dr. Emily Fox, University of Washington:
My favorite definition is #5.
Machine Learning Basic Concepts
There are many different types of machine learning algorithms, with hundreds published each day, and they’re typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). Regardless of learning style or function, all combinations of machine learning algorithms consist of the following:
Representation (a set of classifiers or the language that a computer understands)
Evaluation (aka objective/scoring function)
Optimization (search method; often the highest-scoring classifier, for example; there are both off-the-shelf and custom optimization methods used)
Image credit: Dr. Pedro Domingo, University of Washington
The fundamental goal of machine learning algorithms is to generalize beyond the training samples i.e. successfully interpret data that it has never ‘seen’ before.
Visual Representations of Machine Learning Models
Concepts and bullet points can only take one so far in understanding. When people ask “What is machine learning?”, they often want to see what it is and what it does. Below are some visual representations of machine learning models, with accompanying links for further information. Even more resources can be found at the bottom of this article.
Decision tree model
Gaussian mixture model
Dropout neural network
Merging chrominance and luminance using Convolutional Neural Networks
How We Get Machines to Learn
There are different approaches to getting machines to learn, from using basic decision trees to clustering to layers of artificial neural networks (the latter of which has given way to deep learning), depending on what task you’re trying to accomplish and the type and amount of data that you have available. This dynamic sees itself played out in applications as varying as medical diagnostics or self-driving cars.
While emphasis is often placed on choosing the best learning algorithm, researchers have found that some of the most interesting questions arise out of none of the available machine learning algorithms performing to par. Most of the time this is a problem with training data, but this also occurs when working with machine learning in new domains.
Research done when working on real applications often drives progress in the field, and reasons are twofold: 1. Tendency to discover boundaries and limitations of existing methods 2. Researchers and developers working with domain experts and leveraging time and expertise to improve system performance.
Sometimes this also occurs by “accident.” We might consider model ensembles, or combinations of many learning algorithms to improve accuracy, to be one example. Teams competing for the 2009 Netflix Price found that they got their best results when combining their learners with other team’s learners, resulting in an improved recommendation algorithm (read Netflix’s blog for more on why they didn’t end up using this ensemble).
One important point (based on interviews and conversations with experts in the field), in terms of application within business and elsewhere, is that machine learning is not just, or even about, automation, an often misunderstood concept. If you think this way, you’re bound to miss the valuable insights that machines can provide and the resulting opportunities (rethinking an entire business model, for example, as has been in industries like manufacturing and agriculture).
Machines that learn are useful to humans because, with all of their processing power, they’re able to more quickly highlight or find patterns in big (or other) data that would have otherwise been missed by human beings. Machine learning is a tool that can be used to enhance humans’ abilities to solve problems and make informed inferences on a wide range of problems, from helping diagnose diseases to coming up with solutions for global climate change.
Challenges and Limitations
“Machine learning can’t get something from nothing…what it does is get more from less.” – Dr. Pedro Domingo, University of Washington
The two biggest, historical (and ongoing) problems in machine learning have involved overfitting (in which the model exhibits bias towards the training data and does not generalize to new data, and/or variance i.e. learns random things when trained on new data) and dimensionality (algorithms with more features work in higher/multiple dimensions, making understanding the data more difficult). Having access to a large enough data set has in some cases also been a primary problem.
One of the most common mistakes among machine learning beginners is testing training data successfully and having the illusion of success; Domingo (and others) emphasize the importance of keeping some of the data set separate when testing models, and only using that reserved data to test a chosen model, followed by learning on the whole data set.
When a learning algorithm (i.e. learner) is not working, often the quicker path to success is to feed the machine more data, the availability of which is by now well-known as a primary driver of progress in machine and deep learning algorithms in recent years; however, this can lead to issues with scalability, in which we have more data but time to learn that data remains an issue.
In terms of purpose, machine learning is not an end or a solution in and of itself. Furthermore, attempting to use it as a blanket solution i.e. “BLANK” is not a useful exercise; instead, coming to the table with a problem or objective is often best driven by a more specific question – “BLANK”.
Deep Learning and Modern Developments in Neural Networks
Deep learning involves the study and design of machine algorithms for learning good representation of data at multiple levels of abstraction (ways of arranging computer systems). Recent publicity of deep learning through DeepMind, Facebook, and other institutions has highlighted it as the “next frontier” of machine learning.
The International Conference on Machine Learning (ICML) is widely regarded as one of the most important in the world. This year’s took place in June in New York City, and it brought together researchers from all over the world who are working on addressing the current challenges in deep learning:
Unsupervised learning in small data sets
Simulation-based learning and transferability to the real world
Deep-learning systems have made great gains over the past decade in domains like bject detection and recognition, text-to-speech, information retrieval and others. Research is now focused on developing data-efficient machine learning i.e. deep learning systems that can learn more efficiently, with the same performance in less time and with less data, in cutting-edge domains like personalized healthcare, robot reinforcement learning, sentiment analysis, and others.
Key Takeaways in Applying Machine Learning
Below is a selection of best-practices and concepts of applying machine learning that we’ve collated from our interviews for out podcast series, and from select sources cited at the end of this article. We hope that some of these principles will clarify how ML is used, and how to avoid some of the common pitfalls that companies and researchers might be vulnerable to in starting off on an ML-related project.
Arguably the most important factor in successful machine learning projects is the features used to describe the data (which are domain-specific), and having adequate data to train your models in the first place
Most of the time when algorithms don’t perform well, it’s due a to a problem with the training data (i.e. insufficient amounts/skewed data; noisy data; or insufficient features describing the data for making decisions
“Simplicity does not imply accuracy” – there is (according to Domingo) no given connection between number of parameters of a model and tendency to overfit
Obtaining experimental data (as opposed to observational data, over which we have no control) should be done if possible (for example, data gleaned from sending different variations of an email to a random audience sampling)
Whether or not we label data causal or correlative, the more important point is to predict the effects of our actions
Always set aside a portion of your training data set for cross validation; you want your chosen classifier or learning algorithm to perform well on fresh data
Emerj For Enterprise Leaders
Emerj helps businesses get started with artificial intelligence and machine learning. Using our AI Opportunity Landscapes, clients can discover the largest opportunities for automation and AI at their companies and pick the highest ROI first AI projects. Instead of wasting money on pilot projects that are destined to fail, Emerj helps clients do business with the right AI vendors for them and increase their AI project success rate.
One of the best ways to learn about artificial intelligence concepts is to learn from the research and applications of the smartest minds in the field. Below is a brief list of some of our interviews with machine learning researchers, many of which may be of interest for readers who want to explore these topics further:
The Science of Machine Learning with Dr. Yoshua Bengio (one of the world’s foremost ML experts)
UPENN’s Dr. Lyle Ungar on Using Machine Learning to See Patterns and Meaning on Social Media
Silicon Valley AI Consultant Lorien Pratt on the Business Use Cases of Machine Learning
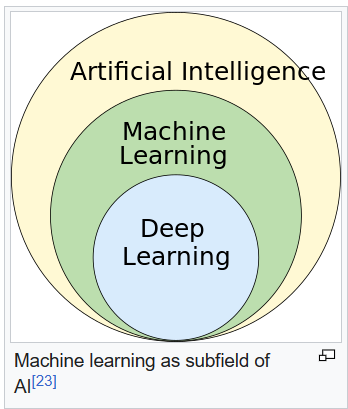
Machine Learning (ML) is a sub-category of artificial intelligence, that refers to the process by which computers develop pattern recognition, or the ability to continuously learn from and make predictions based on data, then make adjustments without being specifically programmed to do so.
How does machine learning work?
Machine learning is incredibly complex and how it works varies depending on the task and the algorithm used to accomplish it. However, at its core, a machine learning model is a computer looking at data and identifying patterns, and then using those insights to better complete its assigned task. Any task that relies upon a set of data points or rules can be automated using machine learning, even those more complex tasks such as responding to customer service calls and reviewing resumes.
What are the different types of machine learning models?
Depending on the situation, machine learning algorithms function using more or less human intervention/reinforcement. The four major machine learning models are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
With supervised learning, the computer is provided with a labeled set of data that enables it to learn how to do a human task. This is the least complex model, as it attempts to replicate human learning.
With unsupervised learning, the computer is provided with unlabeled data and extracts previously unknown patterns/insights from it. There are many different ways machine learning algorithms do this, including:
Clustering, in which the computer finds similar data points within a data set and groups them accordingly (creating “clusters”).
Density estimation, in which the computer discovers insights by looking at how a data set is distributed.
Anomaly detection, in which the computer identifies data points within a data set that are significantly different from the rest of the data.
Principal component analysis (PCA), in which the computer analyzes a data set and summarizes it so that it can be used to make accurate predictions.
With semi-supervised learning, the computer is provided with a set of partially labeled data and performs its task using the labeled data to understand the parameters for interpreting the unlabeled data.
With reinforcement learning, the computer observes its environment and uses that data to identify the ideal behavior that will minimize risk and/or maximize reward. This is an iterative approach that requires some kind of reinforcement signal to help the computer better identify its best action.
How are deep learning and machine learning related?
Machine learning is the broader category of algorithms that are able to take a data set and use it to identify patterns, discover insights, and/or make predictions. Deep learning is a particular branch of machine learning that takes ML’s functionality and moves beyond its capabilities.
With machine learning in general, there is some human involvement in that engineers are able to review an algorithm’s results and make adjustments to it based on their accuracy. Deep learning doesn’t rely on this review. Instead, a deep learning algorithm uses its own neural network to check the accuracy of its results and then learn from them.
A deep learning algorithm’s neural network is a structure of algorithms that are layered to replicate the structure of the human brain. Accordingly, the neural network learns how to get better at a task over time without engineers providing it with feedback.
The two major stages of a neural network’s development are training and inference. Training is the initial stage in which the deep learning algorithm is provided with a data set and tasked with interpreting what that data set represents. Engineers then provide the neural network with feedback about the accuracy of its interpretation, and it adjusts accordingly. There may be many iterations of this process. Inference is when the neural network is deployed and is able to take a data set it has never seen before and make accurate predictions about what it represents.
What are the benefits of machine learning?
Machine learning is the catalyst for a strong, flexible, and resilient enterprise. Smart organizations choose ML to generate top-to-bottom growth, employee productivity, and customer satisfaction.
Many enterprises achieve success with a few ML use cases, but that’s really just the beginning of the journey. Experimenting with ML may come first, but what needs to follow is the integration of ML models into business applications and processes so it can be scaled across the enterprise.
Machine learning use cases
Across vertical industries, ML technologies and techniques are being deployed successfully, providing organizations with tangible, real-world results.
Financial services
In financial services for example, banks are using ML predictive models that look across a massive array of interrelated measures to better understand and meet customer needs. ML predictive models are also capable of uncovering and limiting exposure to risk. Banks can identify cyber threats, track and document fraudulent customer behavior, and better predict risk for new products. Top use cases for ML in banking include fraud detection and mitigation, personal financial advisor services, and credit scoring and loan analysis.
Manufacturing
In manufacturing, companies have embraced automation and are now instrumenting both equipment and processes. They use ML modeling to reorganize and optimize production in a way that is both responsive to current demand and conscious of future change. The end result is a manufacturing process that is at once agile and resilient. The top three ML use cases identified in manufacturing include yield improvements, root cause analysis, and supply chain and inventory management.
Why do enterprises use MLOps?
Many organizations lack the skills, processes, and tools to accomplish this level of enterprise-wide integration. In order to successfully achieve ML at scale, companies should consider investing in ML Ops, which includes the process, tools, and technology that streamline and standardize each stage of the ML lifecycle, from model development to operationalization. The emerging field of ML Ops aims to deliver agility and speed to the ML lifecycle. It can be compared to what DevOps has done for the software development lifecycle.
To progress from ML experimentation to ML operationalization, enterprises need strong ML Ops processes. ML Ops not only gives an organization a competitive edge but also makes it possible for the organization to implement other machine learning use cases. This results in other benefits, including the creation of stronger talent through increased skills and a more collaborative environment, plus increased profitability, better customer experiences, and increased revenue growth.
HPE and machine learning
HPE offers machine learning to untangle complexity and create end-to-end solutions—from the core enterprise data center to the intelligent edge.
HPEApollo Gen10 systems offer an enterprise deep learning and machine learning platform with industry-leading accelerators that deliver exceptional performance for faster intelligence.
The HPE Ezmeral software platform is designed to help enterprises accelerate digital transformation across the organization. It enables them to increase agility and efficiency, unlock insights, and deliver business innovation. The complete portfolio spans artificial intelligence, machine learning, and data analytics, as well as container orchestration and management, cost control, IT automation, AI-driven operations, and security.
The HPE Ezmeral ML Ops software solution extends the capabilities of the HPE Ezmeral Container platform to support the entire machine learning lifecycle and implement DevOps-like processes to standardize machine learning workflows.
To help enterprises move rapidly beyond ML proofs-of-concepts to production, HPE Pointnext Advisory and Professional Services provides the expertise and services needed to deliver ML projects. With experience delivering hundreds of workshops and projects across the world, HPE Pointnext experts provide the skills and expertise to accelerate project deployments from years to months to weeks.