Daniel Faggella is Head of Research at Emerj. Called upon by the United Nations, World Bank, INTERPOL, and leading enterprises, Daniel is a globally sought-after expert on the competitive strategy implications of AI for business and government leaders.

Typing “what is machine learning?” into a Google search opens up a pandora’s box of forums, academic research, and false information – and the purpose of this article is to simplify the definition and understanding of machine learning thanks to the direct help from our panel of machine learning researchers.
At Emerj, the AI Research and Advisory Company, many of our enterprise clients feel as though they should be investing in machine learning projects, but they don’t have a strong grasp of what it is. We often direct them to this resource to get them started with the fundamentals of machine learning in business.
In addition to an informed, working definition of machine learning (ML), we detail the challenges and limitations of getting machines to ‘think,’ some of the issues being tackled today in deep learning (the frontier of machine learning), and key takeaways for developing machine learning applications for business use-cases.
This article will be broken up into the following sections:
- What is machine learning?
- How we arrived at our definition (IE: the perspective of expert researchers)
- Machine learning basic concepts
- Visual representation of ML models
- How we get machines to learn
- An overview of the challenges and limitations of ML
- Brief introduction to deep learning
- Works cited
- Related ML interviews on Emerj
We put together this resource to help with whatever your area of curiosity about machine learning – so scroll along to your section of interest, or feel free to read the article in order, starting with our machine learning definition below:
What is Machine Learning?
* “Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.”
The above definition encapsulates the ideal objective or ultimate aim of machine learning, as expressed by many researchers in the field. The purpose of this article is to provide a business-minded reader with expert perspective on how machine learning is defined, and how it works. Machine learning and artificial intelligence share the same definition in the minds of many however, there are some distinct differences readers should recognize as well. References and related researcher interviews are included at the end of this article for further digging.
* How We Arrived at Our Definition:
(Our aggregate machine learning definition can be found at the beginning of this article)
As with any concept, machine learning may have a slightly different definition, depending on whom you ask. We combed the Internet to find five practical definitions from reputable sources:
- “Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world.” – Nvidia
- “Machine learning is the science of getting computers to act without being explicitly programmed.” – Stanford
- “Machine learning is based on algorithms that can learn from data without relying on rules-based programming.”- McKinsey & Co.
- “Machine learning algorithms can figure out how to perform important tasks by generalizing from examples.” – University of Washington
- “The field of Machine Learning seeks to answer the question “How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?” – Carnegie Mellon University
We sent these definitions to experts whom we’ve interviewed and/or included in one of our past research consensuses, and asked them to respond with their favorite definition or to provide their own. Our introductory definition is meant to reflect the varied responses. Below are some of their responses:
Dr. Yoshua Bengio, Université de Montréal:
ML should not be defined by negatives (thus ruling 2 and 3). Here is my definition:
Machine learning research is part of research on artificial intelligence, seeking to provide knowledge to computers through data, observations and interacting with the world. That acquired knowledge allows computers to correctly generalize to new settings.
Dr. Danko Nikolic, CSC and Max-Planck Institute:
(edit of number 2 above): “Machine learning is the science of getting computers to act without being explicitly programmed, but instead letting them learn a few tricks on their own.”
Dr. Roman Yampolskiy, University of Louisville:
Machine Learning is the science of getting computers to learn as well as humans do or better.
Dr. Emily Fox, University of Washington:
My favorite definition is #5.
Machine Learning Basic Concepts
There are many different types of machine learning algorithms, with hundreds published each day, and they’re typically grouped by either learning style (i.e. supervised learning, unsupervised learning, semi-supervised learning) or by similarity in form or function (i.e. classification, regression, decision tree, clustering, deep learning, etc.). Regardless of learning style or function, all combinations of machine learning algorithms consist of the following:
- Representation (a set of classifiers or the language that a computer understands)
- Evaluation (aka objective/scoring function)
- Optimization (search method; often the highest-scoring classifier, for example; there are both off-the-shelf and custom optimization methods used)
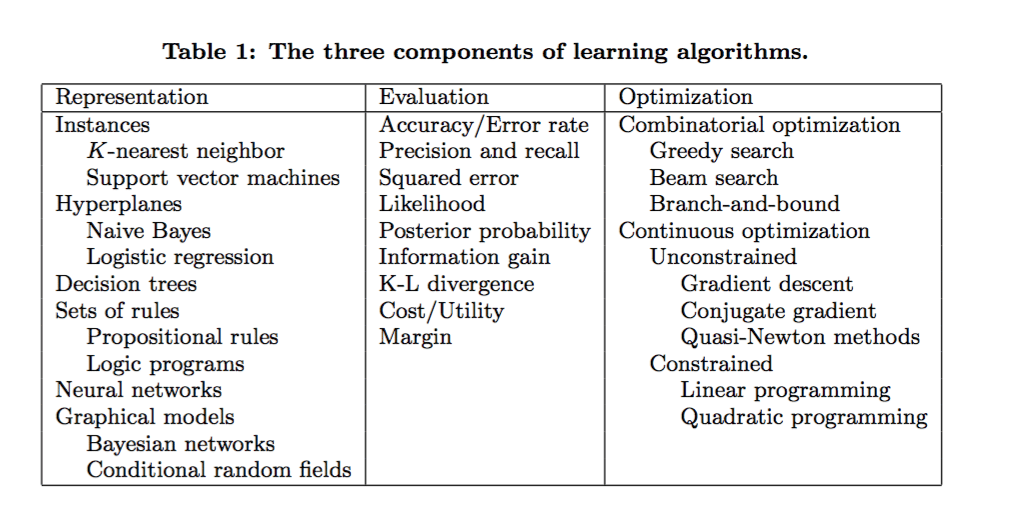
Image credit: Dr. Pedro Domingo, University of Washington
The fundamental goal of machine learning algorithms is to generalize beyond the training samples i.e. successfully interpret data that it has never ‘seen’ before.
Visual Representations of Machine Learning Models
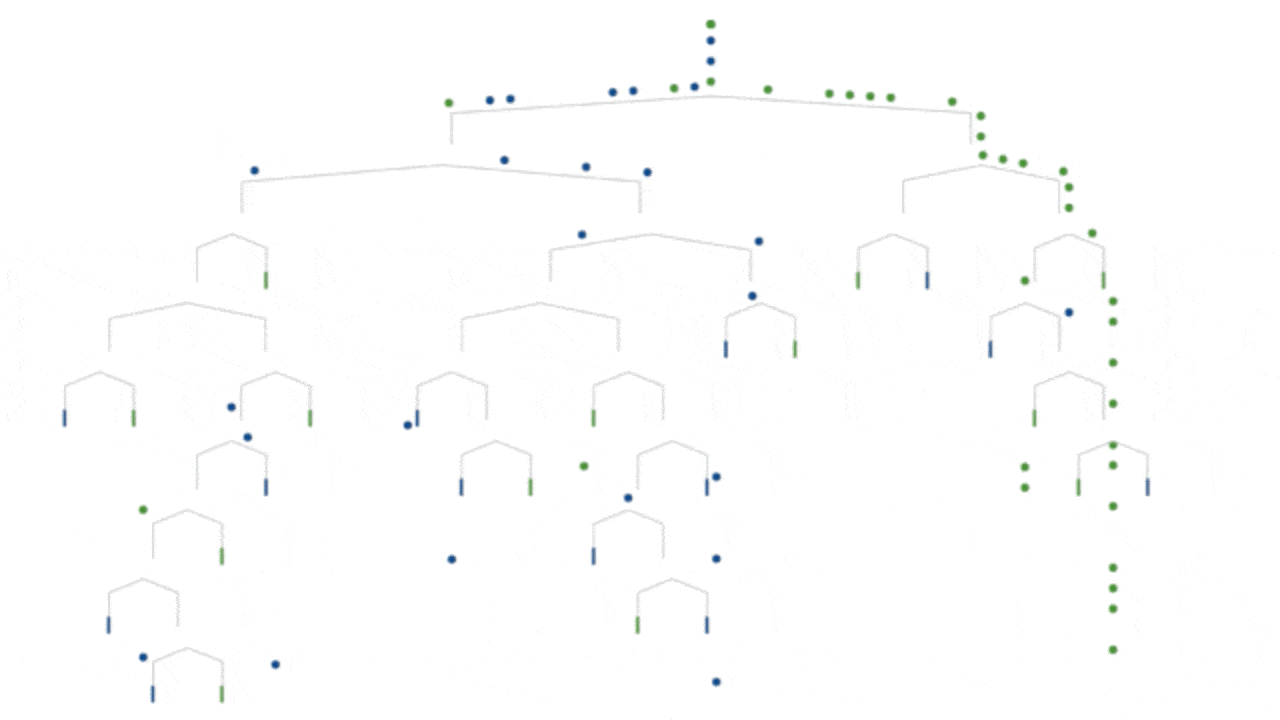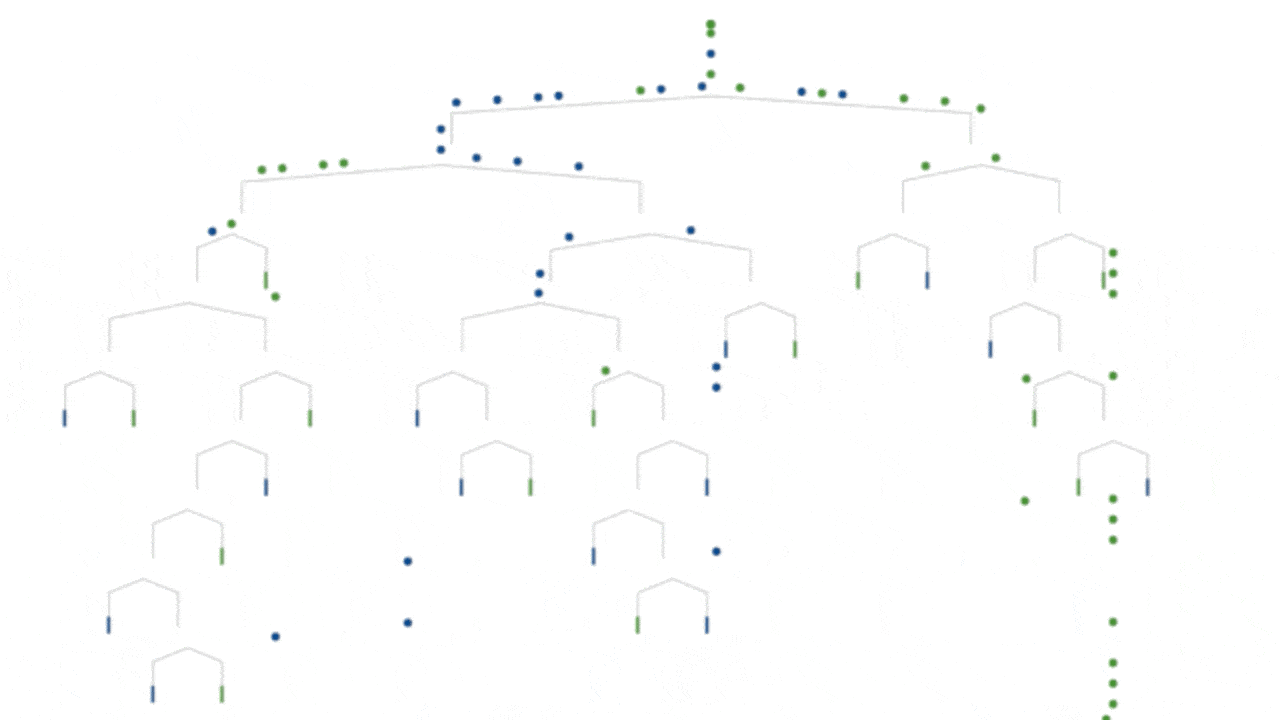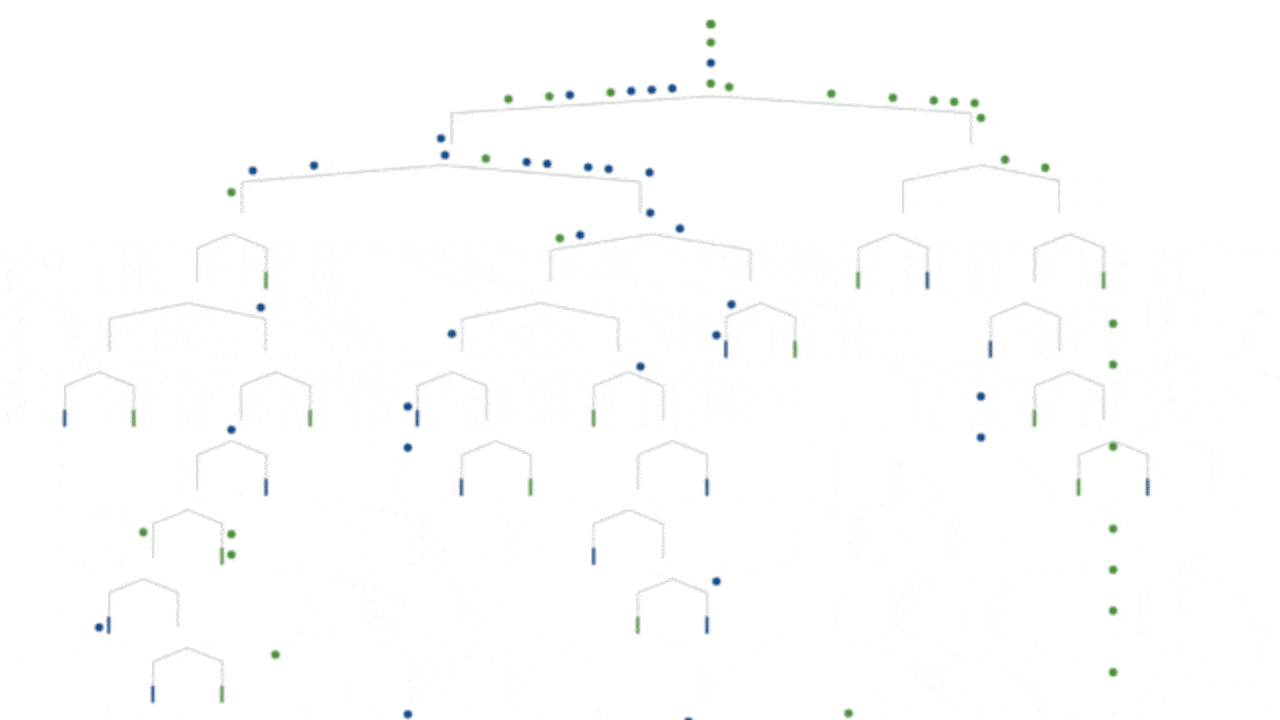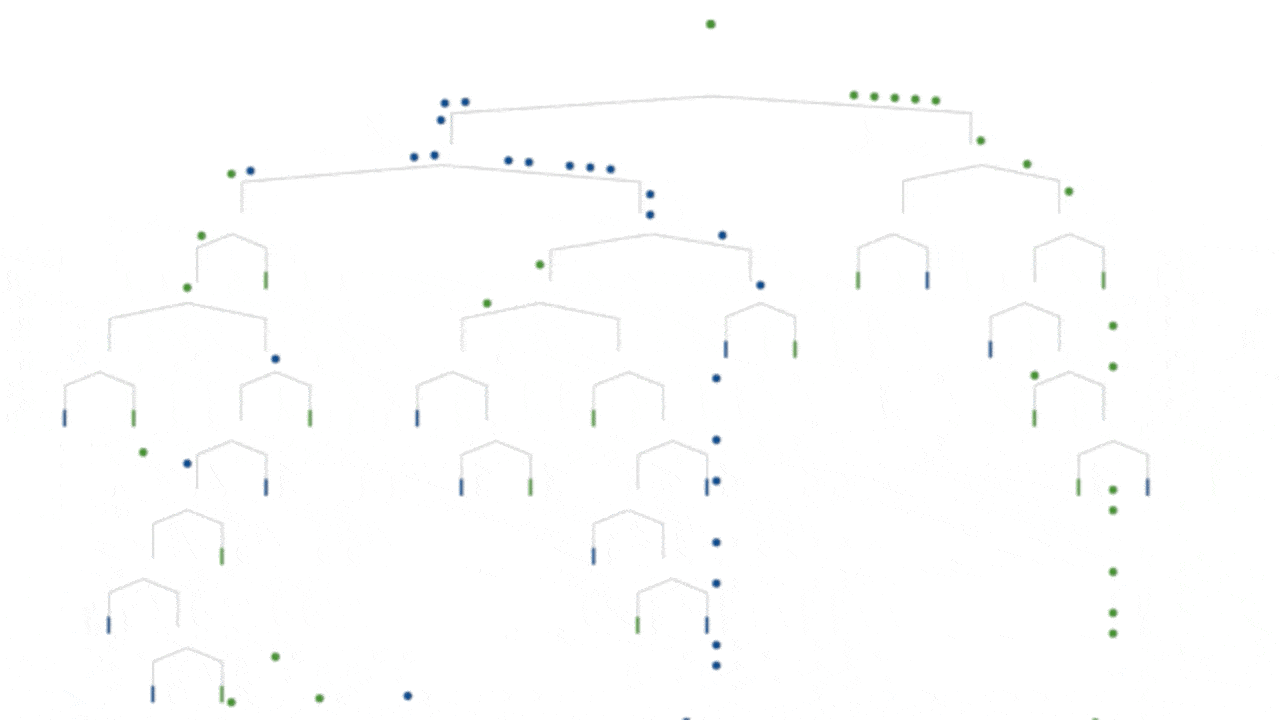
Concepts and bullet points can only take one so far in understanding. When people ask “What is machine learning?”, they often want to see what it is and what it does. Below are some visual representations of machine learning models, with accompanying links for further information. Even more resources can be found at the bottom of this article.
Decision tree model
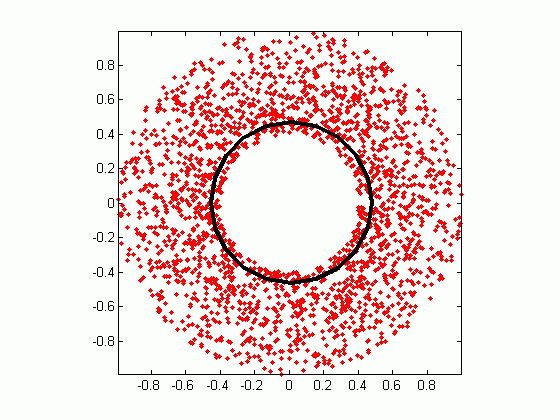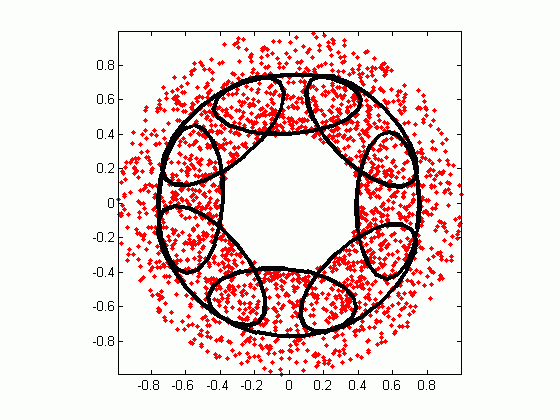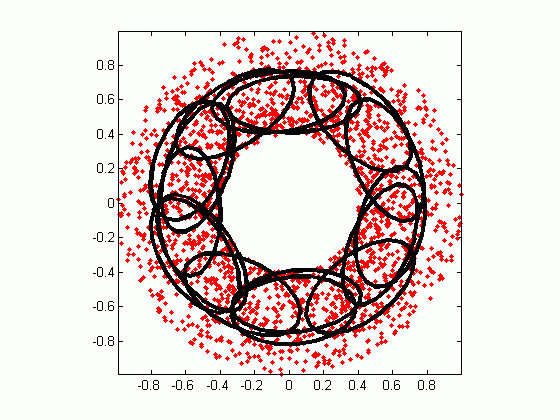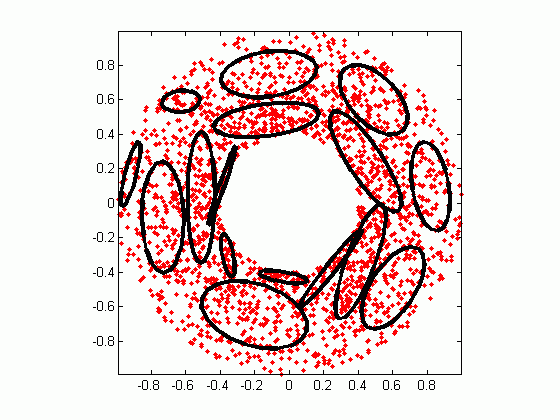
Gaussian mixture model

Dropout neural network
Merging chrominance and luminance using Convolutional Neural Networks
How We Get Machines to Learn
There are different approaches to getting machines to learn, from using basic decision trees to clustering to layers of artificial neural networks (the latter of which has given way to deep learning), depending on what task you’re trying to accomplish and the type and amount of data that you have available. This dynamic sees itself played out in applications as varying as medical diagnostics or self-driving cars.
While emphasis is often placed on choosing the best learning algorithm, researchers have found that some of the most interesting questions arise out of none of the available machine learning algorithms performing to par. Most of the time this is a problem with training data, but this also occurs when working with machine learning in new domains.
Research done when working on real applications often drives progress in the field, and reasons are twofold: 1. Tendency to discover boundaries and limitations of existing methods 2. Researchers and developers working with domain experts and leveraging time and expertise to improve system performance.
Sometimes this also occurs by “accident.” We might consider model ensembles, or combinations of many learning algorithms to improve accuracy, to be one example. Teams competing for the 2009 Netflix Price found that they got their best results when combining their learners with other team’s learners, resulting in an improved recommendation algorithm (read Netflix’s blog for more on why they didn’t end up using this ensemble).
One important point (based on interviews and conversations with experts in the field), in terms of application within business and elsewhere, is that machine learning is not just, or even about, automation, an often misunderstood concept. If you think this way, you’re bound to miss the valuable insights that machines can provide and the resulting opportunities (rethinking an entire business model, for example, as has been in industries like manufacturing and agriculture).
Machines that learn are useful to humans because, with all of their processing power, they’re able to more quickly highlight or find patterns in big (or other) data that would have otherwise been missed by human beings. Machine learning is a tool that can be used to enhance humans’ abilities to solve problems and make informed inferences on a wide range of problems, from helping diagnose diseases to coming up with solutions for global climate change.
Challenges and Limitations
“Machine learning can’t get something from nothing…what it does is get more from less.” – Dr. Pedro Domingo, University of Washington
The two biggest, historical (and ongoing) problems in machine learning have involved overfitting (in which the model exhibits bias towards the training data and does not generalize to new data, and/or variance i.e. learns random things when trained on new data) and dimensionality (algorithms with more features work in higher/multiple dimensions, making understanding the data more difficult). Having access to a large enough data set has in some cases also been a primary problem.
One of the most common mistakes among machine learning beginners is testing training data successfully and having the illusion of success; Domingo (and others) emphasize the importance of keeping some of the data set separate when testing models, and only using that reserved data to test a chosen model, followed by learning on the whole data set.
When a learning algorithm (i.e. learner) is not working, often the quicker path to success is to feed the machine more data, the availability of which is by now well-known as a primary driver of progress in machine and deep learning algorithms in recent years; however, this can lead to issues with scalability, in which we have more data but time to learn that data remains an issue.
In terms of purpose, machine learning is not an end or a solution in and of itself. Furthermore, attempting to use it as a blanket solution i.e. “BLANK” is not a useful exercise; instead, coming to the table with a problem or objective is often best driven by a more specific question – “BLANK”.
Deep Learning and Modern Developments in Neural Networks
Deep learning involves the study and design of machine algorithms for learning good representation of data at multiple levels of abstraction (ways of arranging computer systems). Recent publicity of deep learning through DeepMind, Facebook, and other institutions has highlighted it as the “next frontier” of machine learning.
The International Conference on Machine Learning (ICML) is widely regarded as one of the most important in the world. This year’s took place in June in New York City, and it brought together researchers from all over the world who are working on addressing the current challenges in deep learning:
- Unsupervised learning in small data sets
- Simulation-based learning and transferability to the real world
Deep-learning systems have made great gains over the past decade in domains like bject detection and recognition, text-to-speech, information retrieval and others. Research is now focused on developing data-efficient machine learning i.e. deep learning systems that can learn more efficiently, with the same performance in less time and with less data, in cutting-edge domains like personalized healthcare, robot reinforcement learning, sentiment analysis, and others.
Key Takeaways in Applying Machine Learning
Below is a selection of best-practices and concepts of applying machine learning that we’ve collated from our interviews for out podcast series, and from select sources cited at the end of this article. We hope that some of these principles will clarify how ML is used, and how to avoid some of the common pitfalls that companies and researchers might be vulnerable to in starting off on an ML-related project.
- Arguably the most important factor in successful machine learning projects is the features used to describe the data (which are domain-specific), and having adequate data to train your models in the first place
- Most of the time when algorithms don’t perform well, it’s due a to a problem with the training data (i.e. insufficient amounts/skewed data; noisy data; or insufficient features describing the data for making decisions
- “Simplicity does not imply accuracy” – there is (according to Domingo) no given connection between number of parameters of a model and tendency to overfit
- Obtaining experimental data (as opposed to observational data, over which we have no control) should be done if possible (for example, data gleaned from sending different variations of an email to a random audience sampling)
- Whether or not we label data causal or correlative, the more important point is to predict the effects of our actions
- Always set aside a portion of your training data set for cross validation; you want your chosen classifier or learning algorithm to perform well on fresh data
Emerj For Enterprise Leaders
Emerj helps businesses get started with artificial intelligence and machine learning. Using our AI Opportunity Landscapes, clients can discover the largest opportunities for automation and AI at their companies and pick the highest ROI first AI projects. Instead of wasting money on pilot projects that are destined to fail, Emerj helps clients do business with the right AI vendors for them and increase their AI project success rate.
Works Cited
1 – http://homes.cs.washington.edu/~pedrod/papers/cacm12.pd
2 – http://videolectures.net/deeplearning2016_precup_machine_learning/
3 – http://www.aaai.org/ojs/index.php/aimagazine/article/view/2367/2272
4 – https://research.facebook.com/blog/facebook-researchers-focus-on-the-most-challenging-machine-learning-questions-at-icml-2016/
5 – https://sites.google.com/site/dataefficientml/
6 – http://www.cl.uni-heidelberg.de/courses/ws14/deepl/BengioETAL12.pdf
Related Machine Learning Interviews on Emerj
One of the best ways to learn about artificial intelligence concepts is to learn from the research and applications of the smartest minds in the field. Below is a brief list of some of our interviews with machine learning researchers, many of which may be of interest for readers who want to explore these topics further:
- The Science of Machine Learning with Dr. Yoshua Bengio (one of the world’s foremost ML experts)
- UPENN’s Dr. Lyle Ungar on Using Machine Learning to See Patterns and Meaning on Social Media
- Silicon Valley AI Consultant Lorien Pratt on the Business Use Cases of Machine Learning