The recent revelation that Google is using machine learning to help process some of its search results is attracting interest and questions about this field within artificial intelligence. What exactly is “machine learning” and how do machines teach themselves? Here’s some background drawn from those involved with machine learning at Google itself.
Yesterday, Google held a “Machine Learning 101” event for a variety of technology journalists. I was one of those in attendance. Despite the billing as an introduction, what was covered still was fairly technical and hard to digest for me and several others in attendance.
For example, when a speaker tells you the math with machine learning is “easy” and mentions calculus in the same sentence, they have a far different definition of easy than the layperson, I’d say!
Still, I came away with a much better understanding of the process and parts involved with how machines — computers — learn to teach themselves to recognize objects, text, spoken words and more. Here’s my takeaway.
The Parts Of Machine Learning
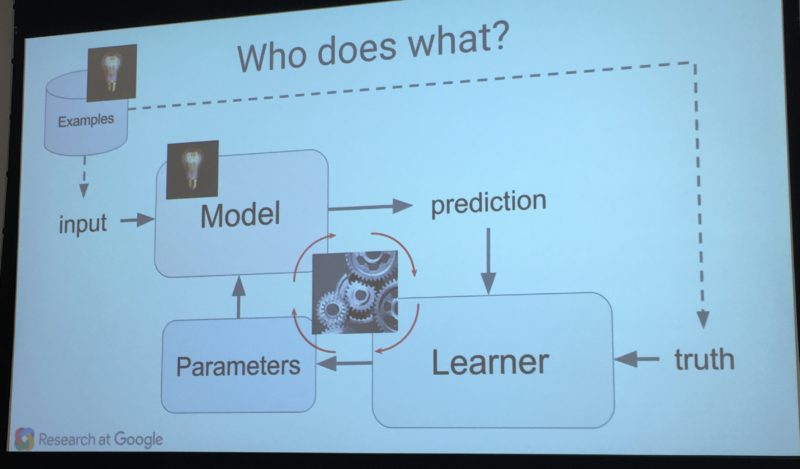
Machine learning systems are made up of three major parts, which are:
- Model: the system that makes predictions or identifications.
- Parameters: the signals or factors used by the model to form its decisions.
- Learner: the system that adjusts the parameters — and in turn the model — by looking at differences in predictions versus actual outcome.
Now let me translate that into a possible real world problem, based on something that was discussed yesterday by Greg Corrado, a senior research scientist with Google and cofounder of the company’s deep learning team.
Imagine that you’re a teacher. You want to identify the optimal amount of time students should study to get the best grade on a test. You turn to machine learning for a solution. Yes, this is overkill for this particular problem. But this is a very simplified illustration!
Making The Model
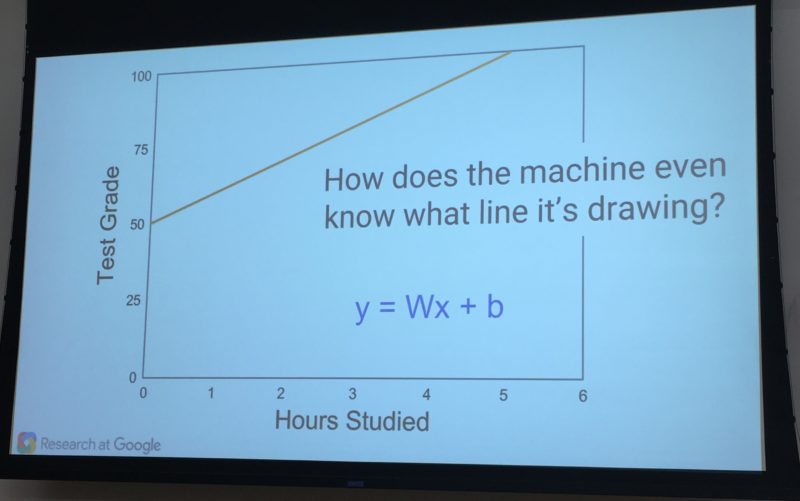
Everything starts with the model, a prediction that the machine learning system will use. The model initially has to be given to the system by a human being, at least with this particular example. In our case, the teacher will tell the machine learning model to assume that studying for five hours will lead to a perfect test score.
The model itself depends on the parameters used to make its calculations. In this example, the parameters are the hours spent studying and the test scores received. Imagine that the parameters are something like this:
- 0 hours = 50% score
- 1 hour = 60% score
- 2 hours = 70% score
- 3 hours = 80% score
- 4 hours = 90% score
- 5 hours = 100% score
The machine learning system will actually use a mathematical equation to express all this above, to effectively form a trend line of what’s expected. Here’s an example of that from yesterday’s talk:
Providing Initial Input
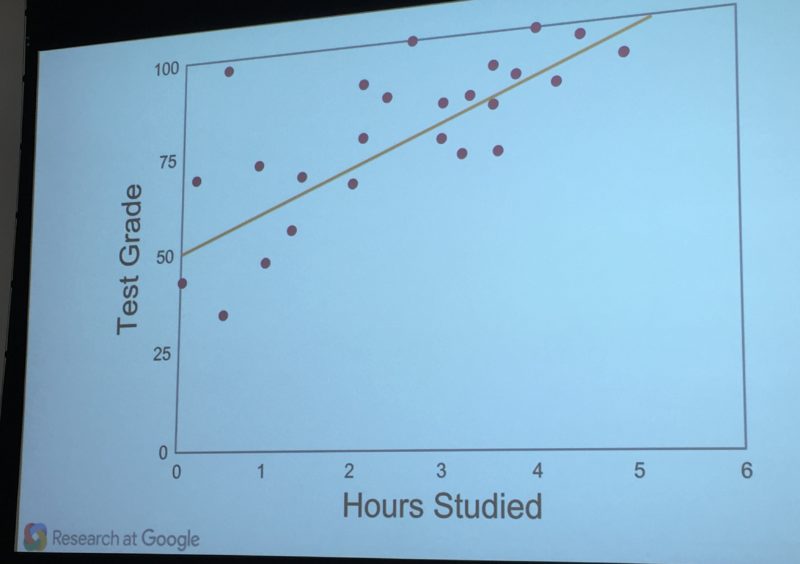
Now that the model is set, real life information is entered. Our teacher, for example, might input four test scores from different students, along with the hours they each studied.
As it turns out, the scores don’t match the model, in this example. Some are above or below the predicted trend line:

Now it’s time for that learning part of machine learning!
The Learner Learns
That set of scores that were entered? Data like this given to a machine learning system is often called a “training set” or “training data” because it’s used by the learner in the machine learning system to train itself to create a better model.
The learner looks at the scores and see how far off they were from the model. It then uses more math to adjust the initial assumptions. For example, the list from above might effectively be altered like this:
- 0 hours = 45% score
- 1 hour = 55% score
- 2 hours = 65% score
- 3 hours = 75% score
- 4 hours = 85% score
- 5 hours = 95% score
- 6 hours = 100% score
The new prediction is reworked so that more study time is projected to earn that prefect score.
This is just an example of the process, one that’s completely made up. The most important takeaway is simply to understand that the learner makes very small adjustments to the parameters, to refine the model. I’ll come back to this in a moment.
Rinse & Repeat
Now the system is run again, this time with a new set of scores. Those real scores are compared against the revised model by the learner. If successful, the scores will be closer to the prediction:
These won’t be perfect, however. So, the learner will once again adjust the parameters, to reshape the model. Another set of test data will be inputted. A comparison will happen again, and the learner will again adjust the model.
The cycle will keep repeating until there’s a high degree of confidence in the ultimate model, that it really is predicting the outcome of scores based on hours of study.
Gradient Descent: How Machine Learning Keeps From Falling Down

Google’s Corrado stressed that a big part of most machine learning is a concept known as “gradient descent” or “gradient learning.” It means that the system makes those little adjustments over and over, until it gets things right.
Corrado likened it to climbing down a steep mountain. You don’t want to jump or run, because that’s dangerous. You’ll more likely make a mistake and fall. Instead, you inch your way down, carefully, a little at a time.
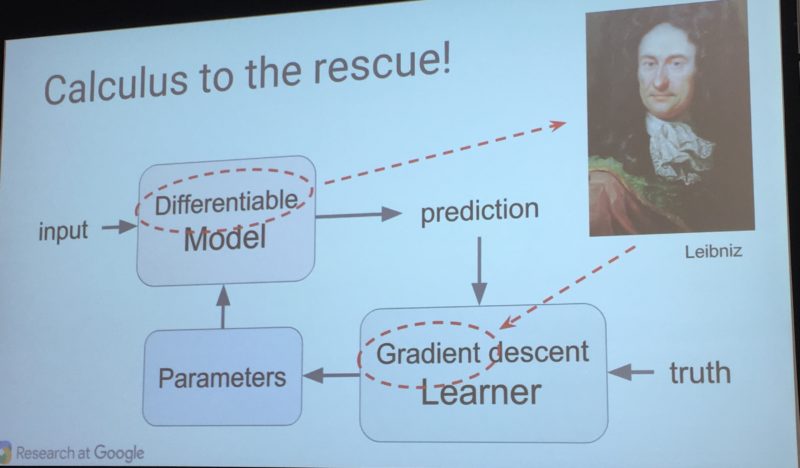
Remember that “the math is easy” line I mentioned above? Apparently for those who know calculus and mathematics, it really is easy, the equations involved.
The real challenge, instead, has been the computing horsepower. It takes a long time for machines to learn, to go through all these steps. But as our computers have gotten faster and bigger, machine learning that seemed impossible years ago is now becoming almost commonplace.
Getting Fancy: Identifying Cats
The example above is very simplistic. As said, it’s overkill for a teacher to use a machine learning system to predict test scores. But the same basic system is used to do very complex things, such as identifying pictures of cats.
Computers can’t see as humans can. So how can they identify objects, in the way that Google Photos picks out many objects in my photos:

Machine learning to the rescue! The same principle applies. You build a model of likely factors that might help identify what’s a cat in images, colors, shapes and so on. Then you feed in a training set of known pictures of cats and see how well the model works.
The learner then makes adjustments, and the training cycle continues. But cats or any object identification is complicated. There are many parameters used as part of forming the model, and you even have parameters within parameters all designed to translate pictures into patterns that the system can match to objects.
For example, here’s how the system might ultimately view a cat on a carpet:

That almost painting-like image has become known as a deep dream, based on the DeepDream code that Google released, which in turn came out of information it shared on how its machine learning systems were building patterns to recognize objects.
The image is really an illustration of the type of patterns that the computer is looking for, when it identifies a cat, rather than being part of the actual learning process. But if the machine could really see, it’s a hint toward how it would actually do so.
By the way, a twist with image recognition from our initial example is that the model itself is initially created by machines, rather than humans. They try to figure out for themselves what an object is making initial groupings of colors, shapes and other features, then use the training data to refine that.
Identifying Events
For a further twist on how complicated all this can be, consider if you want to identify not just objects but events. Google explained that you have to help add in some common sense rules, some human guidance that allows the machine learning process to understand how various objects might add up to an event.
For example, consider this:

As illustrated, a machine learning system sees a tiny human, a basket and an egg. But a human being sees all these and recognizes this as an Easter egg hunt.
What About RankBrain?
How does all this machine learning apply to RankBrain? Google didn’t get into the specifics of that at all, In fact, it wasn’t even mentioned during the formal discussions and little more was revealed in talks during breaks than has already been released.
Why? Basically, competition. Google shares a lot generally about how it does machine learning. It even shares lots of specifics in terms of some fields. But it’s staying pretty quiet on what exactly is going on with machine learning in search, to avoid giving away things it believes are pretty important and unique.