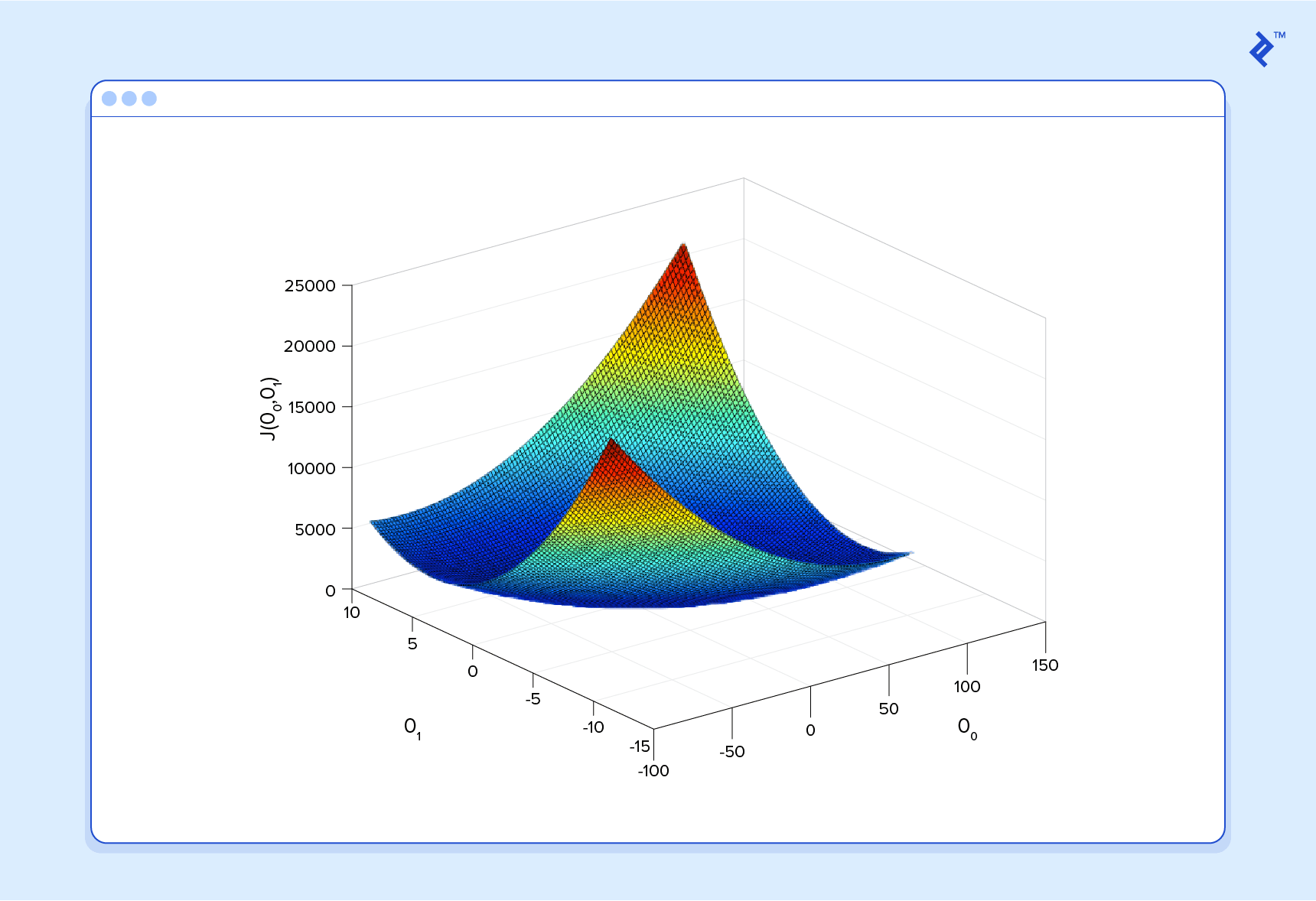
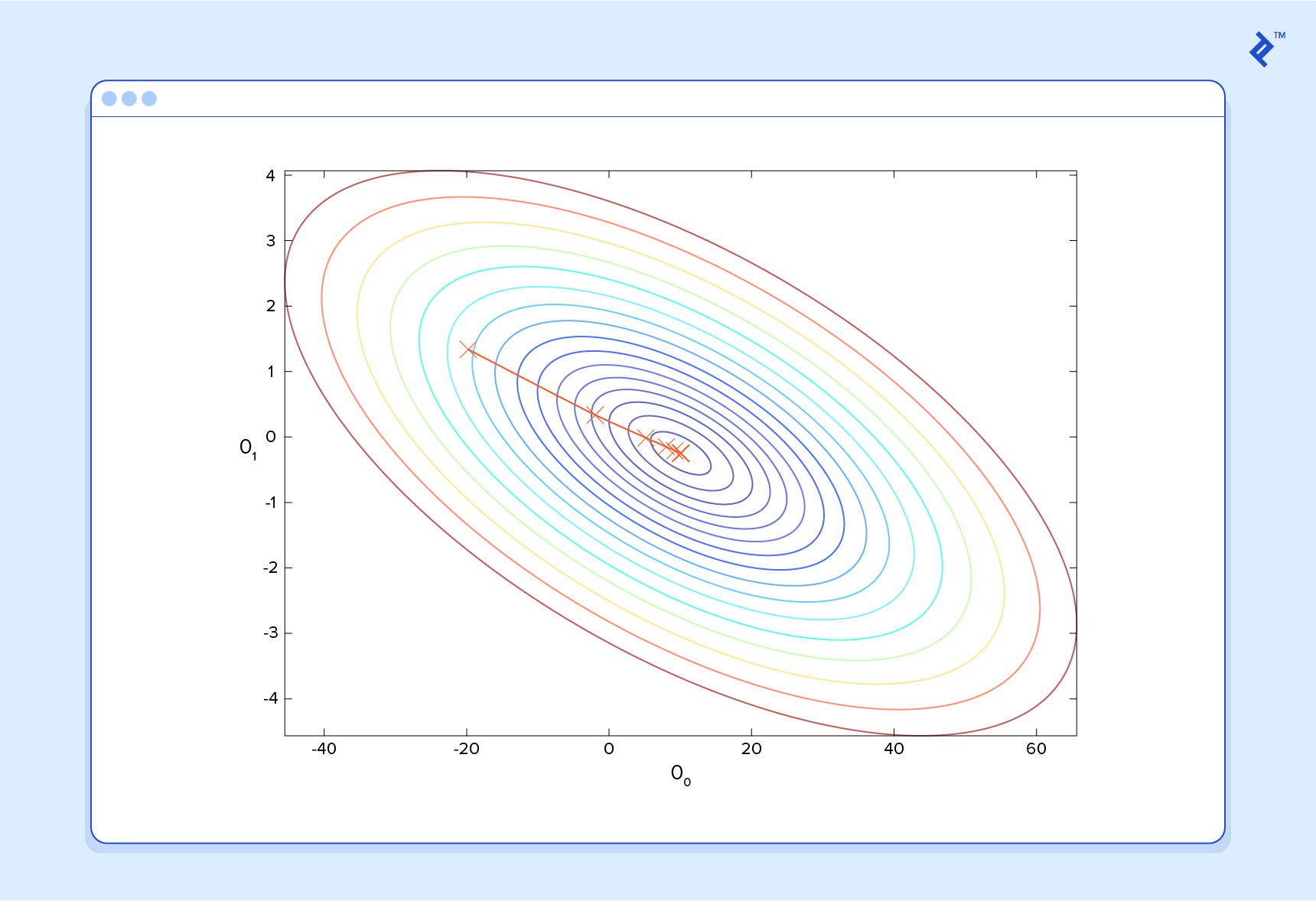
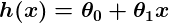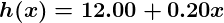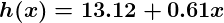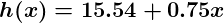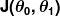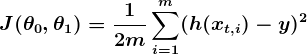Explore the foundational building blocks of language problems
Learn to use Tensorflow to process languages
Learn to build Recurrent Neural Network models to predict sentiment
Learn and explore more advanced NLP topics such as LSTM
Requirements
No prior programming experience needed. You will learn directly in this class.
Description
This course is created to follow up with the AI4ALL initiatives. The course presents coding materials at a pre-college level and introduces a fundamental pipeline for a neural network model. The course is designed for the first-time learners and the audience who only want to get a taste of a machine learning project but still uncertain whether this is the career path. We will not bored you with the unnecessary component and we will directly take you through a list of topics that are fundamental for industry practitioners and researchers to design their customized neural network model. The course follows the previous sequence where we covered Artificial Neural Network models, Convolutional Neural Network models, and Image-to-Image models. This course focuses on some of the most basical tasks in language problems and develop the basic intuition of Recurrent Neural Networks.
This instructor team is lead by Ivy League graduate students and we have had 3+ years coaching high school students. We have seen all the ups and downs. Moreover, we want to share these roadblocks with you. This course is designed for beginner students at pre-college level who just want to have a quick taste of what AI is about and efficiently build a quick Github package to showcase some technical skills. We have other longer courses for more advanced students. However, we welcome anybody to take this course!
Who this course is for:
Pre-college level students interested in recurrent neural network models
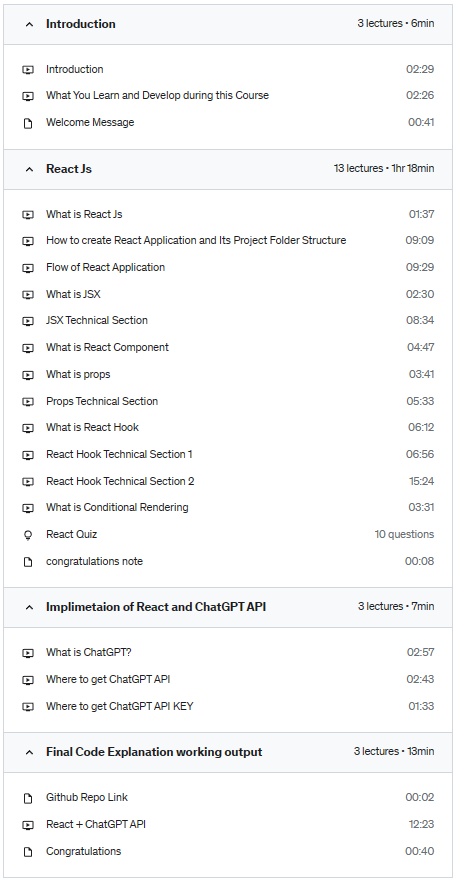
Learn to Build Chat application like ChatGPT using React
Understand how to connect React with servers using API
Learn React Core Topics which are required projects.
Implement React things to understand more about it.
Requirements
Nothing is required.
Description
Are you interested in building interactive chatbots? Do you want to learn how to use the React framework and ChatGPT API to create engaging chatbots that can understand natural language? If so, this course is for you!
In this course, you’ll learn the fundamentals of building chatbots with React and ChatGPT API. You’ll start by exploring the basics of React, including components, state, and props. Then, you’ll dive into the ChatGPT API and learn how to use its natural language processing capabilities to create intelligent and engaging chatbots.
Throughout the course, you’ll build several chatbots of increasing complexity, culminating in a fully-featured interactive chatbot that can understand and respond to natural language queries. By the end of the course, you’ll have the skills and knowledge you need to create your own chatbots and incorporate them into your own projects.
Here’s what you’ll learn:
The basics of React components, state, and props
How to use the ChatGPT API to process natural language queries
Techniques for building interactive chatbots that can understand and respond to natural language
Best practices for integrating chatbots into your projects
Whether you’re a seasoned developer looking to expand your skill set or a beginner interested in learning more about chatbots and React, this course is for you. So why wait? Enroll now and start building your own intelligent chatbots with React and ChatGPT API today!
Who this course is for:
Anyone Can learn and Build. Started from the basics.
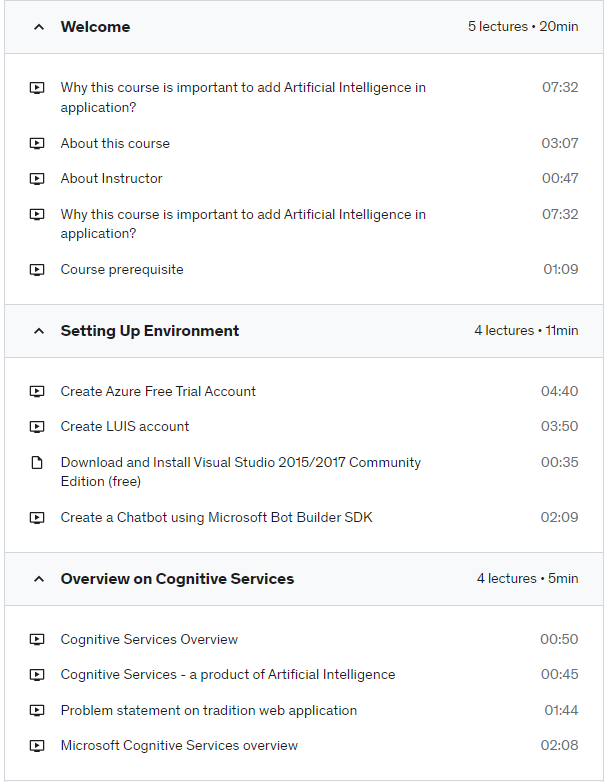
Integrate Natural Language Processing in App by Microsoft Cognitive Services Language Understanding Intelligent Service
Requirements
Experience as a C# .NET developer
Create a chatbot using Bot Builder SDK (Basic Level)
Visual Studio 2015/2017 Community Edition
Bot Framework Emulator
Azure Subscription
LUIS account
Description
Why you should enroll for this course?
Artificial Intelligence (AI) is going to be a core component of traditional applications.
Microsoft Cognitive Service APIs like LUIS API enables developers to build custom machine learning language model.
Artificial Intelligence in the form of Cognitive APIs like Language Understanding Intelligent Service (Natural Language Processing – NLP ) enables application to process natural language.
AI powered Chatbot with natural language processing capabilities will dominate traditional web and mobile app.
Microsoft Cognitive Service APIs like LUIS API is product of Artificial Intelligence, created using Machine Learning specially by Active Learning (Semi-Supervised Learning – SSL).
Course Includes:
Briefly introduced:
Overview of Microsoft Cognitive Services
Overview of Language Understanding Intelligent Service (LUIS)
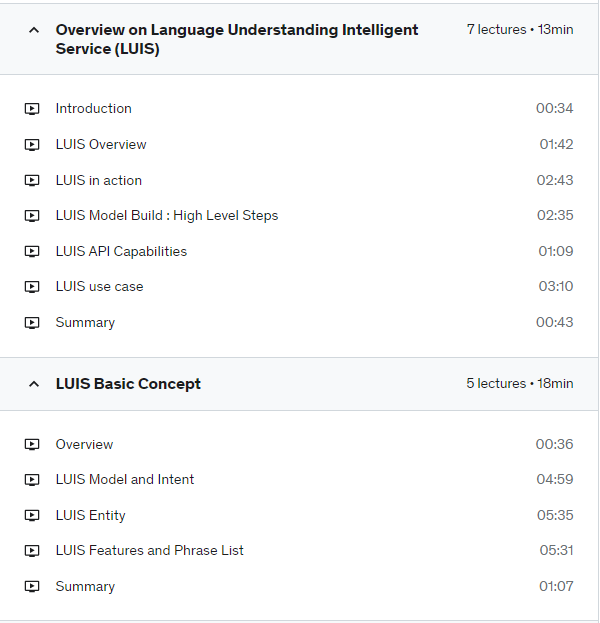
LUIS Basic concept:
Every concept of LUIS building block is explained with real-world example and hands on coding supported by extensive code walk-through
What is LUIS model, Intent?
What is entity (simple, pre-built, hierarchical, composite, list)?
How a list entity helps to increase entity detection?
What is features in machine learning?
What is phrase list and how phrase list helps to improve LUIS performance?
How phrase list and list entity differs and when to use which one?
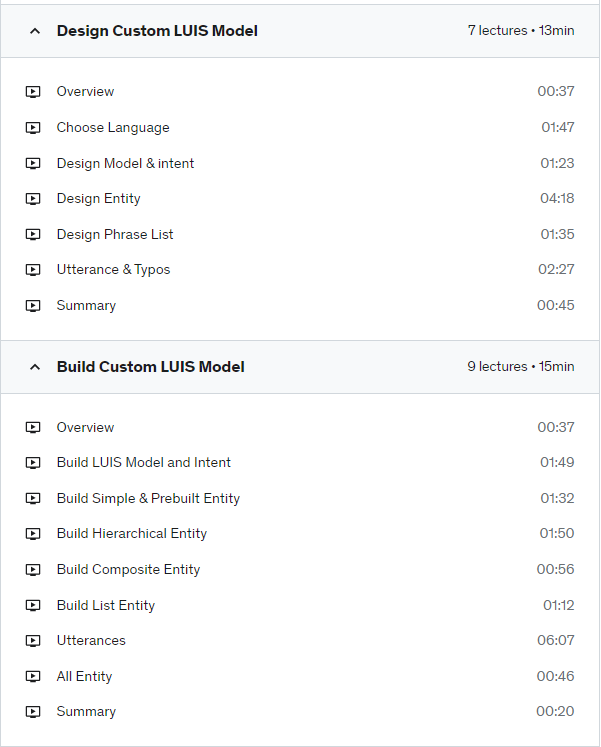
Design the custom LUIS model
Designing of custom LUIS model includes every concept and building block of LUIS with a real world use case.
Identifying model and Intent.
Identifying entities.
Identifying phrase list.
Identifying utterances and typo/misspelling consideration.
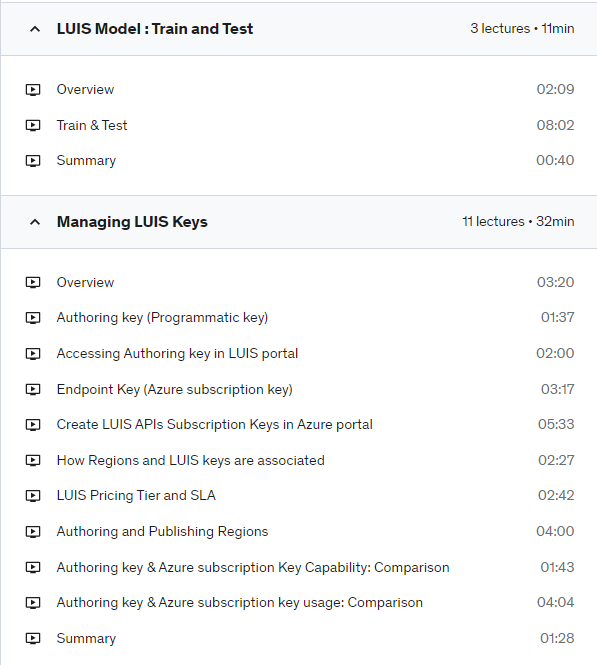
Build the custom LUIS model
Build the LUIS model by creating LUIS model, intent, entities.
Adding utterances to intent and labeling the entities.
Followed by
Train and Test the LUIS model (interactive testing)
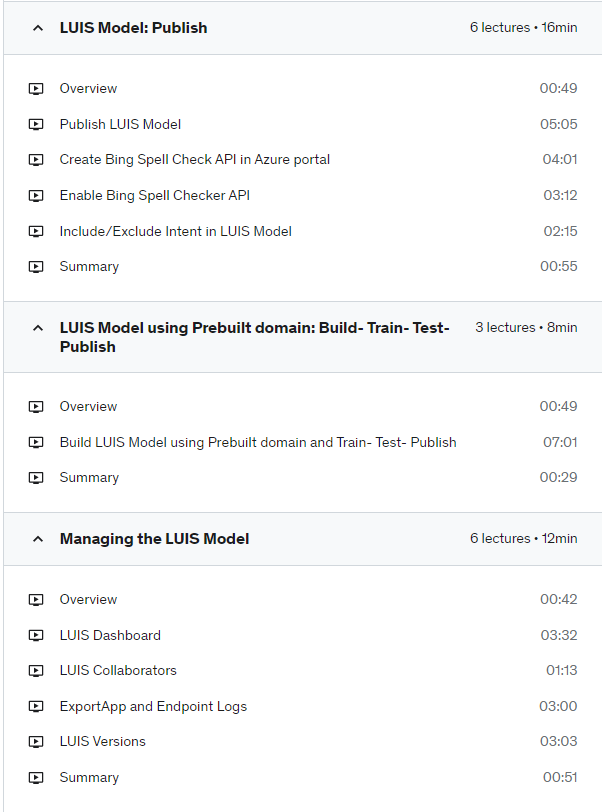
Create Bing Spell Check API in Azure portal
Adding Bing Spell Check API to correct typo/misspelling from user query/utterances.
Create Azure LUIS API in Azure portal and get endpoint key (with free/paid tier).
Publishing to HTTP endpoint using this endpoint key
How LUIS improves its performance using Phrase List and by active learning – review endpoint utterances.
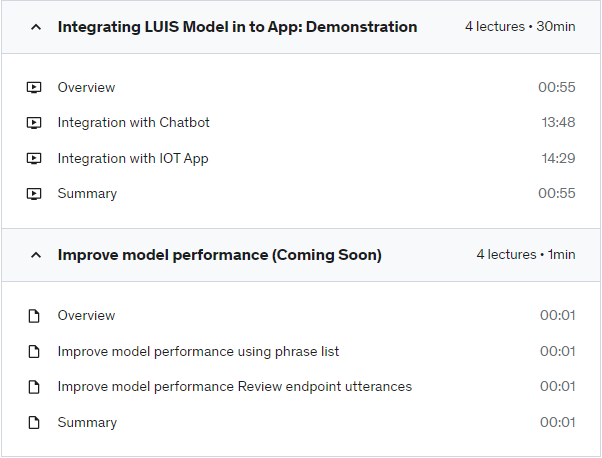
Build the LUIS model with prebuilt domain model: from model training, testing and publishing to HTTP endpoint; Integrating with IOT App.
Demonstration: integration of LUIS model with chabot and IOT app — debugging and code walk-through on how LUIS gets natural language from apps and parse query and get back to chatbot and web app.
Bonus Lecture: Improve LUIS model performance using phrase list and reviewing the endpoint utterances.
Who this course is for:
Developer/Decision maker wants to integrate natural language processing AI capabilities in Chatbot or IOT app Microsoft Cognitive Services LUIS API
C# and .NET Developers passionate about new technology and wants to up skill by learning/implementing Microsoft Cognitive Services LUIS API
College students who passionate to explore and shape their career in Artificial Intelligence, Machine Learning and Natural Language Processing
Existing Python, Java,JavaScript, Node js, PHP, Ruby developer who wants to integrate natural language processing AI capabilities in application Microsoft Cognitive Services LUIS API
Developer/Decision maker who wants to create custom machine learning model without help of data scientist.
There are no specific requirements for this course
Description
AI is changing our world. It helps Instagram choose which pictures to show us, Google find the results to our query, and Apple unlock your iPhone with your face.
At the same time, a lot of traditional organizations are investing in AI, and need people who can understand it and manage their projects.
Yet, how AI works is still a mystery to many.
The good news is that if you want to get into this field, you don’t need to invest years to learn computer science or complex math.
You can start by learning the core principles of AI and Machine Learning, and this course will help you do that in an easy, simple, and fun way.
You will learn:
The history of AI, and why this is the right moment to invest in it
How Machine Learning works, the set of techniques behind the AI revolution
How companies use AI to analyze images and build all sorts of products, from self-driving cars to unlock your iPhone with your face
How AI understands text to power products like Siri and Alexa
How recommender systems suggest you content aligned with your interests in companies like Netflix
Join this course and make your first step towards understanding AI today, for free!
Who this course is for:
Anyone interested in technology, with any background
Huge amounts of data are circulating in the digital world in the era of the Industry 5.0 revolution. Machine learning is experiencing success in several sectors such as intelligent control, decision making, speech recognition, natural language processing, computer graphics, and computer vision, despite the requirement to analyze and interpret data. Due to their amazing performance, Deep Learning and Machine Learning Techniques have recently become extensively recognized and implemented by a variety of real-time engineering applications. Knowledge of machine learning is essential for designing automated and intelligent applications that can handle data in fields such as health, cyber-security, and intelligent transportation systems. There are a range of strategies in the field of machine learning, including reinforcement learning, semi-supervised, unsupervised, and supervised algorithms. This study provides a complete study of managing real-time engineering applications using machine learning, which will improve an application’s capabilities and intelligence. This work adds to the understanding of the applicability of various machine learning approaches in real-world applications such as cyber security, healthcare, and intelligent transportation systems. This study highlights the research objectives and obstacles that Machine Learning approaches encounter while managing real-world applications. This study will act as a reference point for both industry professionals and academics, and from a technical standpoint, it will serve as a benchmark for decision-makers on a range of application domains and real-world scenarios.
1. Introduction
1.1. Machine Learning Evolution
In this digital era, the data source is becoming part of many things around us, and digital recording [1, 2] is a normal routine that is creating bulk amounts of data from real-time engineering applications. This data can be unstructured, semi-structured, and structured. In a variety of domains, intelligent applications can be built using the insights extracted from this data. For example, as in [3] author used cyber-security data for extracting insights and use those insights for building intelligent application for cyber-security which is automated and driven by data. In the article [1], the author uses mobile data for extracting insights and uses those insights for building an intelligent smart application which is aware of context. Real-time engineering applications are based on tools and techniques for managing the data and having the capability for useful knowledge or insight extraction in an intelligent and timely fashion.
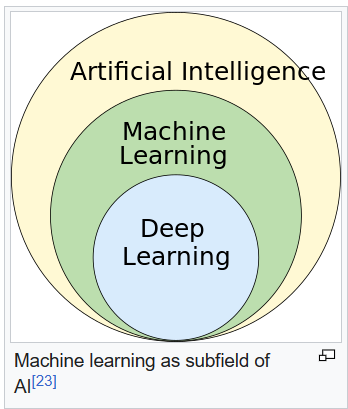
Machine Learning is a stream in Artificial Intelligence, which is gaining popularity in recent times in the field of computing and data analysis that will make applications behave intelligently [4]. In industry 4.0 (fourth industrial revolution) machine learning is considered one of the popular technologies which will allow the application to learn from experience, instead of programming specifically for the enhancement of the system [1, 3]. Traditional practices of industries and manufacturing are automated in Industry 4.0 [5] by using machine learning which is considered a smart technology and is used for exploratory data processing. So, machine learning algorithms are keys to developing intelligent real-time engineering applications for real-world problems by analyzing the data intelligently. All the machine learning techniques are categorized into the following types (a) Reinforcement Learning (b) Unsupervised Learning (c) Semi-Supervised Learning, and (d) Supervised Learning.
Based on the collected data from google trends [6], popularity of these techniques is represented in Figure 1. In Figure 1 the y-axis indicated the popularity score of the corresponding technique and the x-axis indicated the time period. As per Figure 1, the popularity score of the technique is growing day by day in recent times. Thus, it gives the motivation to perform this review on machine learning’s role in managing Real Time Engineering Applications. We may use Google Trends to find out what the most popular web subjects are at any given time and location. This could help us generate material and give us suggestions for articles that will most likely appeal to readers. Just make sure the content is relevant to our company or industry. We can look into the findings a little more carefully and investigate the reasons that may have influenced such trends because Google Trends can supply us with data about the specific regions in which our keywords drew substantial interest. With this level of data, we can figure out what’s working and what needs to be improved.
Figure 1
World wide trend analysis on machine learning techniques [6].
Machine learning algorithms’ performance and characteristics and nature of the data will decide the efficiency and effectiveness of the solution based on machine learning. The data-driven systems [7, 8] can be effectively built by using the following ML areas like reinforcement learning, association rule learning, reduction of dimensionality and feature engineering, data clustering, regression, and classification analysis. From ANN, a new technology is originated from the family of machine learning techniques called Deep Learning which is used for analyzing data intelligently [9]. Every machine learning algorithm’s purpose is different even various machine learning algorithms applied over the same category will generate different outcomes and depends on the nature and characteristics of data [10]. Hence, it’s challenging to select a learning algorithm for generating solutions to a target domain. Thus, there is a need for understanding the applicability and basic principle of ML algorithms in various Real Time Engineering Applications.
A comprehensive study on a variety of machine learning techniques is provided in this article based on the potentiality and importance of ML that can be used for the augmentation of application capability and intelligence. For industry people and academia this article will be acting as a reference manual, to research and study and build intelligent systems which are data-driven in a variety of real-time engineering applications on the basis of machine learning approaches.
1.2. Types of Machine Learning Techniques
Figure 2 shows the Machine Learning Timeline chart. There are 4 classes of machine learning approaches (a) Reinforcement Learning, (b) Semi-Supervised Learning (c) Unsupervised, and (d) Supervised Learning as shown in Figure 3. With the applicability of every ML technique in Real Time Engineering applications, we put down a brief discussion on all the four types of ML approaches as follows:(i)Reinforcement learning: in an environment-driven approach, RL allows machines and software agents to assess the optimal behavior automatically to enhance the efficiency in a particular context [11]. Penalty or rewards are the basis for RL, and the goal of this approach is to perform actions that minimize the penalty and maximize the reward by using the extracted insights from the environment [12]. RL can be used for enhancing sophisticated systems efficiency by doing operational optimization or by using automation with the help of the trained Artificial Intelligence models like supply chain logistics, manufacturing, driving autonomous tasks, robotics, etc.(ii)Semi-supervised: as this method operates on both unlabeled and labeled data [3, 7] it is considered a hybrid approach and lies between “with supervision” and “without supervision” learning approach. The author in [12] concludes that the semi-supervised approach is useful in real-time because of numerous amounts of unlabeled data and rare amounts of labeled data available in various contexts. The semi-supervised approach achieves the goal of predicting better when compared to predictions based on labeled data only. Text classification, labeling data, fraud detection, machine translation, etc., are some of the common tasks.(iii)Unsupervised: as in [7], the author defines that unsupervised approach as a process of data-driven, with minimum or no human interface, it takes datasets consisting of unlabeled data and analyzes them. The unsupervised approach is widely used for purpose of exploring data, results grouping, identifying meaningful structures and trends, and extracting general features. Detecting anomalies, association rules finding, reducing dimensionality, learning features, estimating density, and clustering are the most usual unsupervised tasks.(iv)Supervised: as in [7], author defines the supervised approach as a process of making a function to learn to map output from input. A function is inferred by using training example collection and training data which is labeled. As in [3], the author states that a supervised learning approach is a task-driven approach, which is to be initiated when certain inputs are capable to accomplish a variety of goals. The most frequently used supervised learning tasks are regression and classification.
Figure 2
Machine learning time line.
Figure 3
Machine learning techniques.
In Table 1, we summarize various types of machine learning techniques with examples.
Table 1
ML Technique varieties with approaches and examples.
Table 2 summarizes the comparison between the current survey with existing surveys and highlights how it is different or enhanced from the existing surveys.
Table 2
Summary of important surveys on ML.
1.3. Contributions
Following are the key contributions to this article:(i)A comprehensive view on variety of ML algorithms is provided which is applicable to improve data-driven applications, task-driven applications capabilities, and intelligence(ii)To discuss and review the applicability of various solutions based on ML to a variety of real-time engineering applications(iii)By considering the data-driven application capabilities and characteristics and nature of the data, the proposed study/review scope is defined(iv)Various challenges and research directions are summarized and highlighted that fall within this current study scope
1.4. Paper Organization
The organization of the rest of the article is as follows: state of art is presented in the next section which explains and introduces real-time engineering applications and machine learning; in the next section, ML’s role in real-time engineering applications is discussed; and in the coming section, challenges and lessons learned are presented; in the penultimate section, several future directions and potential research issues are discussed and highlighted; and in the final section conclude the comprehensive study on managing Real Time Engineering Applications using Machine Learning.
2. State of the Art
2.1. Real World Issues
Computer systems can utilize all client data through machine learning. It acts according to the program’s instructions while also adapting to new situations or changes. Algorithms adapt to data and exhibit previously unprogrammed behaviors. Acquiring the ability to read and recognize context enables a digital assistant to skim emails and extract vital information. This type of learning entails the capacity to forecast future customer behaviors. This enables you to have a deeper understanding of your customers and to be proactive rather than reactive. Machine learning is applicable to a wide variety of sectors and industries and has the potential to expand throughout time. Figure 4 represents the real-world applications of machine learning.
Figure 4
Applications of machine learning.
2.2. Introduction to Cyber Security
For both, services and information, internet is most extensively exploited. In article [13], author summarizes that since 2017 as an information source Internet is utilized by almost 48% of the whole population in the world. As concluded in the article [14], this number is hiked up to 82% in advanced countries.
The interconnection of distinct devices, networks, and computers is called the Internet, whose preliminary job is to transmit information from one device to another through a network. Internet usage spiked due to the innovations and advancements in mobile device networks and computer systems. As internet is the mostly used by the majority of population as an information source so it’s more prone to cyber criminals [15]. A computer system is said to be stable when it’s offering integrity, availability, and confidentiality of information. As stated in the article [16], with intent to disturb normal activity, if an unauthorized individual enters into the network, then the computer system will be compromised with integrity and security. User assets and cyberspace can be secured from unauthorized individual attacks and access with the help of cyber security. As in article [17], the primary goal of cyber security is to keep information available, integral, and confidential.
2.3. Introduction to Healthcare
With advancements in the field of Deep Learning/Machine Learning, there are a lot of transformations happening in the areas like governance, transportation, and manufacturing. Extensive research is going on in the field of Deep Learning over the last decade. Deep Learning has been applied to lots of areas that delivered a state-of-the-art performance in variety of domains like speech processing, text analytics, and computer vision. Recently researchers started deploying Deep Learning/Machine Learning approaches to healthcare [18], and they delivered outstanding performances in the jobs like brain tumor segmentation [19], image reconstruction in medical images [20, 21] lung nodule detection [22], lung disease classification [23], identification of body parts [24], etc.
It is evident that CAD systems that provide a second opinion will help the radiologists to confirm the disease [25] and deep learning/machine learning will further enhance the performance of these CAD systems and other systems that will provide supporting decisions to the radiologists [26].
Advancement in the technologies like big data, mobile communication, edge computing, and cloud computing is also helping the deployment of deep learning/machine learning models in the domain of healthcare applications [27]. By combining they can achieve greater predictive accuracies and an intelligent solution can be facilitated which is human-centered [28].
2.4. Introduction to Intelligent Transportation Systems
In transit and transportation systems, after the deployment of sensing technologies, communication, and information, the resultant implementation is called an intelligent transportation system [29]. An intelligent transportation system is an intrinsic part of smart cities [30], which have the following services such as autonomous vehicles, public transit system management, traveler information systems, and road traffic management. These services are expected to contribute a lot to the society by curbing pollution, enhancing energy efficiency, transit and transportation efficiency is enhanced and finally, traffic and road safety is also improved.
Advances in technologies like wireless communication technology, computing, and sensing are enabling intelligent transportation systems applications and also bear a lot of challenges due to their capabilities to generate huge amounts of data, independent QoS requirements, and scalability.
Due to the recent traction in deep learning/machine learning models, approaches like RL and DL are utilized to exploit patterns and generate decisions and predictions accurately [31–33].
2.5. Introduction to Renewable Energy
Sustainable and alternative energy sources are in demand due to the effect created by burning fossil fuels in the environment and fossil fuel depletion. As in article [34], the energy market biomass, wind power, tidal waves, geothermal, solar thermal, and solar photovoltaic are growing as renewable energy resources. There will be instability in the power grids due to various reasons like when demand is more than the supply of the energy and when supply is more than the demand of the energy. Finally, environmental factors affect the energy output of the plants based on the renewable energy. To address the management and optimization of energy, machine learning is used.
2.6. Introduction to Smart Manufacturing
Manufacturing has been divided into a number of categories, one of the categories in which computer-based manufacturing is performed is called Smart Manufacturing, which performs workers’ training, digital technology, and quick changes in the design and with high adaptability. Other responsibilities include recyclability of production effectively, supply chain optimization, and demand-based quick changes in the levels of production. Enabling technologies of Smart Manufacturing are advances in robotics, services and devices connectivity in the industry, and processing capabilities in the big data.
2.7. Introduction to Smart Grid
The basic structure of the electrical power grid has remained same over time, and it has been noticed that it has become outdated and ill-suited, unable to meet demand and supply in the twenty-first century. Even though we are in the twenty-first century, electrical infrastructure has remained mostly unaltered throughout time. However, as the population and consumption have grown, so requires power.
2.7.1. Drawbacks
(i)Analyzing the demand is difficult(ii)Response time is slow
The new smart grid idea has evolved to address the issues of the old outdated electrical power system. SG is a large energy network that employs real time and intelligent monitoring, communication, control, and self-healing technologies to provide customers with a variety of alternatives while guaranteeing the stability and security of their electricity supply. By definition, SGs are sophisticated cyber-physical system. The functionality of this modern SG can be broken down into four parts.
This contemporary SG’s functionality may be split down into four components:(1)Consumption: electricity is used for a variety of reasons by various industries and inhabitants(2)Distribution: the power so that it may be distributed more widely(3)Transmission: electricity is transmitted over a high-voltage electronic infrastructure(4)Generation: during this phase, electricity is generated in a variety of methods
ML and DL functionalities in the context of SG include predicting about(1)Stability of the SG(2)Optimum schedule(3)Fraud detection(4)Security breach detection(5)Network anomaly detection(6)Sizing(7)Fault detection(8)Energy consumption(9)Price(10)Energy generation
2.8. Introduction to Computer Networks
The usefulness of ML in networking is aided by key technological advancements in networking, such as network programmability via Software-Defined Networking (SDN). Though machine learning has been widely used to solve problems such as pattern recognition, speech synthesis, and outlier identification, its use in network operations and administration has been limited. The biggest roadblocks are determining what data may be collected and what control actions can be taken on legacy network equipment. These issues are alleviated by the ability to program the network using SDN. ML-based cognition can be utilized to help automate network operation and administration chores. As a result, applying machine learning approaches to such broad and complicated networking challenges is both intriguing and challenging. As a result, ML in networking is a fascinating study area that necessitates a thorough understanding of ML techniques as well as networking issues.
2.9. Introduction to Energy Systems
A set of structured elements designed for the creation, control, and/or transformation of energy is known as an energy system [35, 36]. Mechanical, chemical, thermal, and electro-magnetical components may be combined in energy systems to span a wide variety of energy categories, including renewables and alternative energy sources [37–39]. The progress of energy systems faces difficult decision-making duties in order to meet a variety of demanding and conflicting objectives, such as functional performance, efficiency, financial burden, environmental effect, and so on [40]. The increasing use of data collectors in energy systems has resulted in an enormous quantity of data being collected. Smart sensors are increasingly widely employed in the production and consumption of energy [41–43]. Big data has produced a plethora of opportunities and problems for making well-informed decisions [44, 45]. The use of machine learning models has aided the deployment of big data technologies in a variety of applications [46–50]. Prediction approaches based on machine learning models have gained popularity in the energy sector [51–53] because they make it easier to infer functional relationships from observations. Because of their accuracy, effectiveness, and speed, ML models in energy systems are becoming crucial for predictive modeling of production, consumption, and demand analysis [54, 55]. In the context of complex human interactions, ML models provide give insight into energy system functioning [56, 57]. The use of machine learning models is in making traditional energy systems, as well as alternative and renewable energy systems.
3. Recent Works on Real-Time Engineering Applications
3.1. Machine Learning for ITS
Exposure to traffic noise, air pollution, road injuries, and traffic delays are only some of the key issues that urban inhabitants experience on a daily basis. Urban areas are experiencing severe environmental and quality-of-life difficulties as a result of rapid car expansion, insufficient transportation infrastructure, and a lack of road safety rules. For example, in many urban areas, large trucks violate the typical highways, resulting in traffic congestion and delays. In addition, many bikers have frequent near misses as a result of their clothes, posture changes, partial occlusions, and varying observation angles all posing significant challenges to the Machine Learning (ML) algorithms’ detection rates.
Over the last decade, there has been a surge in interest in using machine learning and deep learning methods to analyze and visualize massive amounts of data generated from various sources in order to improve the classification and recognition of pedestrians, bicycles, special vehicles (e.g., emergency vehicles vs. heavy trucks), and License Plate Recognition (LPR) for a safer and more sustainable environment. Although deep models are capable of capturing a wide variety of appearances, adaption to the environment is essential.
Artificial neural networks form the base for deep learning success; in artificial neural networks to mirror an image, the human brain functioning interconnected node system sets are present. The neighboring layer’s nodes will be consisting of connections with weights coming from nodes from other layers. The output value is generated by given input and weight to the activation function in a node. Figure 5 presents the ML mainstream approaches used in ITS.
Figure 5
Mainstream ML approaches.
Figure 6 shows the RL working in intelligent transportation system.
Figure 6
RL working in intelligent transportation system.
Figures 7–9 present the interaction between ITS and ML and Machine Learning Pipeline.
Figure 7
ML pipeline and interaction between ITS and ML.
Figure 8
ML pipeline.
Figure 9
Interaction between ML and ITS.
3.2. Machine Learning for HealthCare
Over time, for the actions performed as a response reward, actions and observations are given as input to policy functions, and the method that learns from this policy function is called RL [58]. There is a wide range of healthcare applications where RL can be used even RL can be used in the detection of disease based on checking symptoms ubiquitously [59]. Another potential use of RL in this domain is Gogame [60].
In semi-supervised learning, both unlabeled data and labeled data are used for training particularly greater doses of unlabeled data and little doses of labeled data are available, and then semi-supervised learning is suitable. Semi-supervised learning can be applied to a variety of healthcare applications like medical image segmentation [61, 62] using various sensors recognition of activity is proposed in [61], in [63] author used semi-supervised learning for healthcare data clustering.
In supervised learning, labeled information is used for training the model to map the input to output. In the regression output value is continuous and in classification output value is discrete. Typical application of supervised learning in the healthcare domain is the identification of organs in the body using various image modalities [19] and nodule classification in the lung images [21].
In unsupervised learning, mapping of input to the output will be done by training the model using unlabeled data:(i)Similarity is used for clustering(ii)Feature selection/dimensionality reduction(iii)Anomaly detection [64]
Unsupervised learning can be applied to a lot of healthcare applications like feature selection [65] using PCA and using Clustering [66] for heart disease prediction.
Various phases in an ML-based Healthcare system are shown in Figure 10.
Figure 10
ML-based healthcare systems phases of development.
The four major applications of healthcare that can benefit from ML/DL techniques are prognosis, diagnosis, treatment, and clinical workflow, which are described in Table
Neural networks comparison.
3.3. Machine Learning for Cyber Security
Artificial Intelligence and Machine Learning are widely accepted and utilized in various fields like Cyber Security [94–103], design and manufacturing [104], medicine [105–108], education [109], and finance [110–112]. Machine Learning techniques are used widely in the following areas of cyber security intrusion detection [113–116], dark web or deep web sites [117, 118], phishing [119–121], malware detection [122–125], fraud detection , and spam classification . As time changes there is a need for vigorous and novel techniques to address the issues of cyber security. Machine Learning is suitable for evolutionary attacks as it learns from experiences.
In article the authors analyzed and evaluated the dark web which is a hacker’s social network by using the ML approach for threat prediction in the cyberspace. In article , the author used an ML model with social network features for predicting cyberattacks on an organization during a stipulated period. This prediction uses a dataset consisting of darkweb’s 53 forum’s data in it. Advancements in recent areas can be found in .
Antivirus, firewalls, unified threat management , intrusion prevention system , and SEIM solutions are some of the classical cyber security systems. As in article , the author concluded that, in terms of post-cyber-attack response, performance, and in error rate classical cyber security systems are poor when compared with AI-based systems. As in the article , once there is cyberspace damage by the attack then only it’s identified and this situation happens in almost 60%. Both on the cyber security side and attackers’ side, there is a stronger hold by ML. On the cyber security side as specified in this article to safeguard everything from the damage done by the attackers and for detecting attacks at an early stage and finally for performance enhancement ML is used. ML is used on the attacker’s end to locate weaknesses and system vulnerabilities as well as techniques to get beyond firewalls and other defence walls As in , the author concludes that to further enhance the classification performance ML approaches are combined.
3.4. Machine Learning for Renewable Energy
Forecasting Renewable Energy Generation can be done using Machine Learning, state-of-art works are presented in Table 4.
3.5. Machine Learning for Smart Manufacturing
The following table shows the ML applicability to Smart Manufacturing. State-of-art works are presented in Table 5.
ML state-of-the-art systems in the smart manufacturing domain.
3.6. Machine Learning for Smart Grids
This subsection discusses machine learning applicability to smart grids. State-of-the-art works are presented in Table 6.
ML state-of-the-art systems in smart grids domain.
3.7. Machine Learning for Computer Networks
3.7.1. Traffic Prediction
As networks are day by day becoming diverse and complex, it becomes difficult to manage and perform network operations so huge importance is given to traffic forecast in the network to properly manage and perform network operations. Time Series Forecasting is forecasting the traffic in near future.
3.7.2. Traffic Prediction
To manage and perform network operations, it’s quite important to perform classification of the network traffic which includes provisioning of the resource, monitoring of the performance, differentiation of the service and quality of service, intrusion detection and security, and finally capacity planning.
3.7.3. Congestion Control
In a network, excess packets will be throttled using the concept called congestion control. It makes sure the packet loss ratio is in an acceptable range, utilization of resources is at a fair level, and stability of the network is managed.
Table 7 presents ML state of art systems in networking.
ML state-of-the-art systems in computer networking domain.
3.7.4. Machine Learning for Civil Engineering
The first uses of ML programs in Civil Engineering involved testing different existing tools on simple programs [210–213], more difficult problems are addressed in .
3.7.5. Machine Learning for Energy Systems
Hybrid ML models, ensembles, Deep Learning, Decision Trees, ANFIS, WNN, SVM, ELM, MLP, ANN are among the ten key ML models often employed in energy systems, according to the approach.
Table 8 presents ML state of art systems in the Energy Systems domain.
ML state-of-the-art systems in energy systems domain.
4. Current Challenges on Machine Learning Technology
While machine learning offers promise and is already proving beneficial to businesses around the world, it is not without its hurdles and issues. For instance, machine learning is useful for spotting patterns, but it performs poorly at generalizing knowledge. There is also the issue of “algorithm weariness” among users.
In ML, for model training, decent amount of data and resources that provide high performances are needed. This challenge is addressed by involving multiple GPU’s. In Real Time Engineering Applications, an ML approach is needed which is modeled to address a particular problem robustly. As the same model designed to address one task in real-time engineering application cannot address all the tasks in a variety of domains, so there is a need to design a model for each task in the Real Time Engineering Applications.
ML approaches should have the skill to prevent issues in the early stages as this is an important challenge to address in most real-time engineering applications. In the medical domain, ML can be used in predicting diseases and ML techniques can also be used for forecasting the detection of terrorism attacks. As in , the catastrophic consequences cannot be avoided by having faith blindly in the ML predictions. As in article , author states that ML approaches are used in various domains, but in some domains as an alternative to accuracy and speed ML approaches require correctness at very high levels. To convert a model into trustworthy, there is a need to avoid a shift in dataset, which means the model is to be trained and tested on the same dataset which can be ensured by avoiding data leakages .
Moving object’s location can be identified by using the enabling technologies like GPS and cell phones and this information to be maintained securely as tamper-proof is one of the crucial tasks for ML. As in article , author states that an object’s location information from multiple sources is compared and tries to find the similarity, and as in article author confirms that due to network delays the location change of the objects there is always ambiguousness in the location information gathered from multiple sources and the trustworthiness of such information needs to be addressed using ML techniques.
In a connected web system, to have interaction between consumers and service providers with trustworthiness an ontology of trust is proposed in the article . In text classification also trustworthiness is used. As in article author states that in semantic and practical terms where the meaning of the text is interpreted trustworthiness can be fused. In article author validates the software’s trustworthiness using a metric model. As in article , the author states that in companies and data centers the consumption of power can be mitigated by utilizing ML approaches for designing strategies that are power-aware. To reduce the consumption in its entirety, it’s better to turn off the machines dynamically. Which machine to be turned off will be decided by the forecasting model and it’s very important to have trust in this forecasting model before setting up the machine to be switched off.
Fatigue in the alarm is generating false alarms at higher rates. This will reduce the response time of the security staff and this issue is an interesting area in cyber security .
Some concerns associated with machine learning have substantial repercussions that are already manifesting now. One is the absence of explainability and interpretability, also known as the “black box problem.” Even its creators are unable to comprehend how machine learning models generate their own judgments and behaviors. This makes it difficult to correct faults and ensure that a model’s output is accurate and impartial. When it was discovered that Apple’s credit card algorithm offered women much lesser credit lines than men, for instance, the corporation was unable to explain the reason or address the problem.
This pertains to the most serious problem affecting the field: data and algorithmic bias. Since the debut of the technology, machine learning models have been frequently and largely constructed using data that was obtained and labeled in a biassed manner, sometimes on intentionally. It has been discovered that algorithms are frequently biased towards women, African Americans, and individuals of other ethnicities. Google’s DeepMind, one of the world’s leading AI labs, issued a warning that the technology poses a threat to queer individuals.
This issue is pervasive and well-known, yet there is resistance to taking the substantial action that many experts in the field insist is necessary. Timnit Gebru and Margaret Mitchell, co-leaders of Google’s ethical AI team, were sacked in retaliation for Gebru’s refusal to retract research on the dangers of deploying huge language models, according to tens of thousands of Google employees. In a survey of researchers, policymakers, and activists, the majority expressed concern that the progress of AI by 2030 will continue to prioritize profit maximization and societal control over ethics. The nation as a whole is currently debating and enacting AI-related legislation, particularly with relation to immediately and blatantly damaging applications, like facial recognition for law enforcement. These discussions will probably continue. And the evolving data privacy rules will soon influence data collecting and, by extension, machine learning.
5. Machine Learning Applications
Because of its ability to make intelligent decisions and its potential to learn from the past, machine learning techniques are more popular in industry 4.0.
Here we discuss and summarize various machine learning techniques application areas.
5.1. Intelligent Decision-Making and Predictive Analytics
By making use of data-driven predictive analytics, intelligent decisions are made by applying machine learning techniques . To predict the unknown outcomes by relying on the earlier events by exploiting and capturing the relationship between the predicted variables and explanatory variables is the basis for predictive analytics , for example, credit card fraud identification and criminal identification after a crime. In the retail industry, predictive analytics and intelligent decision-making can be used for out-of-stock situation avoidance, inventory management, behavior, and preferences of the consumer are better understood and logistics and warehouse are optimized. Support Vector Machines, Decision Trees, and ANN are the most widely used techniques in the above areas . Predicting the outcome accurately can help every organization like social networking, transportation, sales and marketing, healthcare, financial services, banking services, telecommunication, e-commerce, industries, etc., to improve.
5.2. Cyber-Security and Threat Intelligence
Protecting data, hardware, systems, and networks is the responsibility of cyber-security and this is an important area in Industry 4.0 . In cyber-security, one of the crucial technologies is machine learning which provides protection by securing cloud data, while browsing keeps people safe, foreseen the bad people online, insider threats are identified and malware is detected in the traffic. Machine learning classification models , deep learning-based security models , and association rule learning techniques are used in cyber-security and threat intelligence.
5.3. Smart Cities
In IoT, all objects are converted into things by equipping objects with transmitting capabilities for transferring the information and performing jobs with no user intervention.
Some of the applications of IoT are business, healthcare, agriculture, retail, transportation, communication, education, smart home, smart governance , and smart cities . Machine learning has become a crucial technology in the internet of things because of its ability to analyze the data and predict future events . For instance, congestion can be predicted in smart cities, take decisions based on the surroundings knowledge, energy estimation for a particular period, and predicting parking availability.
5.4. Transportation and Traffic Prediction
Generally, transportation networks have been an important part of every country’s economy. Yet, numerous cities across the world are witnessing an enormous amount of traffic volume, leading to severe difficulties such as a decrease in the quality of life in modern society, crises, accidents, CO2 pollution increased, higher fuel prices, traffic congestion, and delays . As a result, an ITS, that predicts traffic and is critical, and it is an essential component of the smart city. Absolute forecasting of traffic based on deep learning and machine learning models can assist to mitigate problems . For instance, machine learning may aid transportation firms in identifying potential difficulties that may arise on certain routes and advising that their clients choose an alternative way based on their history of travel and pattern of travel by taking variety of routes. Finally, by predicting and visualizing future changes, these solutions will assist to optimize flow of the traffic, enhance the use and effectiveness of sustainable forms of transportation, and reduce real-world disturbance.
5.5. Healthcare and COVID-19 Pandemic
In a variety of medical-related application areas, like prediction of illness, extraction of medical information, data regularity identification, management of patient data, and so on, machine learning may assist address diagnostic and prognostic issues . Here in this article , coronavirus is considered as an infectious disease by the WHO. Learning approaches have recently been prominent in the fight against COVID-19 .
Learning approaches are being utilized to categorize the death rate, patients at high risk, and various abnormalities in the COVID-19 pandemic . It may be utilized to fully comprehend the virus’s origins, predict the outbreak of COVID-19, and diagnose and treat the disease . Researchers may use machine learning to predict where and when COVID-19 will spread, and then inform those locations to make the necessary preparations. For COVID 19 pandemic , to address the medical image processing problems, deep learning can provide better solutions. Altogether, deep and machine learning approaches can aid in the battle against the COVID-19 virus and pandemic, and perhaps even the development of intelligent clinical judgments in the healthcare arena.
5.6. Product Recommendations in E-commerce
One of the most prominent areas in e-commerce where machine learning techniques are used is suggesting products to the users of the e-commerce. Technology of machine learning can help e-commerce websites to analyze their customers’ purchase histories and provide personalized product recommendations based on their behavior and preferences for their next purchase. By monitoring browsing tendencies and click-through rates of certain goods, e-commerce businesses, for example, may simply place product suggestions and offers. Most merchants, such as flipkart and amazon, can avert out-of-stock problems, manage better inventory, optimize storage, and optimize transportation by using machine learning-based predictive models. Future of marketing and sales is to improve the personalized experience of the users while purchasing the products by collecting their data and analyzing the data and use them to improve the experience of the users. In addition, to attract new customers and also to retain the existing ones the e-commerce website will build packages to attract the customers and keep the existing ones.
5.7. Sentiment Analysis and NLP (Natural Language Processing)
An act of using a computer system to read and comprehend spoken or written language is called Natural Language Processing. Thus, NLP aids computers in reading texts, hearing speech, interpreting it, analyzing sentiment, and determining which elements are important, all of which may be done using machine learning techniques. Some of the examples of NLP are machine translation, language translation, document description, speech recognition, chatbot, and virtual personal assistant. Collecting data and generating views and mood of the public from news, forums, social media, reviews, and blogs is the responsibility of sentiment analysis which is a sub-field of NLP. In sentiment analysis, texts are analyzed by using machine learning tasks to identify the polarity like neutral, negative and positive and emotions like not interested, have interest, angry, very sad, sad, happy, and very happy.
5.8. Image, Speech and Pattern Recognition
Machine Learning is widely used in the image recognition whose task is to detect the object in an image. Some of the instances of image recognition are social media suggestions tagging, face detection, character recognition and cancer label on an X-ray image. Alexa, Siri, Cortana, Google Assistant etc., are the famous linguistic and sound models in speech recognition [286282]. The automatic detection of patterns and data regularities, such as picture analysis, is characterized as pattern recognition . Several machine learning approaches are employed in this field, including classification, feature selection, clustering, and sequence labeling.
5.9. Sustainable Agriculture
Agriculture is necessary for all human activities to survive . Sustainable agriculture techniques increase agricultural output while decreasing negative environmental consequences. In article authors convey those emerging technologies like mobile devices, mobile technologies, Internet of Things can be used to capture the huge amounts of data to encourage the adoption of practices of sustainable agriculture by encouraging knowledge transfer among farmers. By using technologies, skills, information knowledge-intensive supply chains are developed in sustainable agriculture. Various techniques of machine learning can be applied in processing phase of the agriculture, production phase and preproduction phase, distribution phases like consumer analysis, inventory management, production planning, demand estimation of livestock, soil nutrient management, weed detection, disease detection, weather prediction, irrigation requirements, soil properties, and crop yield prediction.
5.10. Context-Aware and Analytics of User Behavior
Capturing information or knowledge about the surrounding is called context-awareness and tunes the behaviors of the system accordingly . Hardware and software are used in context-aware computing for automating the collection and interpreting of the data.
From the historical data machine learning will derive knowledge by using their learning capabilities which is used for bringing tremendous changes in the mobile app development environment.
Smart apps can be developed by the programmers, using which uses can be entertained, support is provided for the user and human behavior is understood and can build a variety of context-aware systems based on data-driven approaches like context-aware smart searching, smart interruption management, smart mobile recommendation, etc., for instance, as in phone call app can be created by using association rules with context awareness. Clustering approaches are used and classification methods are used for predicting future events and for capturing users’ behavior.
6. Challenges and Future Research Directions
In this review, quite a few research issues are raised by studying the applicability of variety of ML approaches in the analysis of applications and intelligent data. Here, opportunities in research and potential future directions are summarized and discussed.
Research directions are summarized as follows:(i)While dealing with real-world data, there is a need for focusing on the in-detail study of the capturing techniques of data(ii)There is a huge requirement for fine-tuning the preprocessing techniques or to have novel data preprocessing techniques to deal with real-world data associated with application domains(iii)Identifying the appropriate machine learning technique for the target application is also one of the research interests(iv)There is a huge interest in the academia in existing machine learning hybrid algorithms enhancement or modification and also in proposing novel hybrid algorithms for their applicability to the target applications domain
Machine learning techniques’ performance over the data and the data’s nature and characteristics will decide the efficiency and effectiveness of the machine learning solutions. Data collection in various application domains like agriculture, healthcare, cyber-security etc., is complicated because of the generation of huge amounts of data in very less time by these application domains. To proceed further in the analysis of the data in machine learning-based applications relevant data collection is the key factor. So, while dealing with real-world data, there is a need for focusing on the more deep investigation of the data collection methods.
There may be many outliers, missing values, and ambiguous values in the data that is already existing which will impact the machine learning algorithms training. Thus, there is a requirement for the cleansing of collected data from variety of sources which is a difficult task. So, there is a need for preprocessing methods to be fine-tuned and novel preprocessing techniques to be proposed that can make machine learning algorithms to be used effectively.
Choosing an appropriate machine learning algorithm best suited for the target application, for the extraction insights, and for analyzing the data is a challenging task, because the characteristics and nature of the data may have an impact on the outcome of the different machine learning techniques [10]. Inappropriate machine learning algorithm will generate unforeseen results which might reduce the accuracy and effectiveness of the model. For this purpose, the focus is on hybrid models, and these models are fine-tuned for the target application domains or novel techniques are to be proposed.
Machine learning algorithms and the nature of the data will decide the ultimate success of the applications and their corresponding machine learning-based solutions. Machine Learning models will generate less accuracy and become useless when the data is the insufficient quantity for training, irrelevant features, poor quality, and non-representative and bad data to learn. For an intelligent application to be built, there are two important factors i.e., various learning techniques handling and effective processing of data.
Our research into machine learning algorithms for intelligent data analysis and applications raises a number of new research questions in the field. As a result, we highlight the issues addressed, as well as prospective research possibilities and future initiatives, in this section.
The nature and qualities of the data, as well as the performance of the learning algorithms, determine the effectiveness and efficiency of a machine learning-based solution. To gather information in a specific domain, such as cyber security, IoT, healthcare, agriculture, and so on. As a result, data for the target machine learning-based applications is collected. When working with real-world data, a thorough analysis of data collection methodologies is required. Furthermore, historical data may contain a large number of unclear values, missing values, outliers, and data that has no meaning.
Many machine learning algorithms exist to analyze data and extract insights; however, the ultimate success of a machine learning-based solution and its accompanying applications is largely dependent on both the data and the learning algorithms. Produce reduced accuracy if the data is bad to learn, such as non-representative, poor-quality, irrelevant features, or insufficient amount for training. As a result, establishing a machine learning-based solution and eventually building intelligent applications, correctly processing the data, and handling the various learning algorithms is critical.
7. Conclusion and Future Scopre
In this study on machine learning algorithms, a comprehensive review is conducted for applications and intelligent analysis of data. Here, the real-world issues and how solutions are prepared by using a variety of learning algorithms are discussed briefly. Machine Learning techniques’ performance and characteristics of the data will decide the machine learning model’s success. To generate intelligent decision-making, machine learning algorithms need to be acquainted with target application knowledge and trained with data collected from various real-world situations. For highlighting the applicability of ML approaches to variety of issues in the real world and variety of application areas are discussed in this review. At last, research directions and other challenges are discussed and summarized. All the challenges in the target applications domain must be addressed by using solutions effectively. For both industry professionals and academia, this study will serve as a reference point and from the technical perspective, this study also works as a benchmark for the decision makers on a variety of application domains and various real-world situations. Machine Learning’s application is not restricted to any one sector. Rather, it is spreading across a wide range of industries, including banking and finance, information technology, media and entertainment, gaming, and the automobile sector. Because the breadth of Machine Learning is so broad, there are several areas where academics are trying to revolutionize the world in the future.
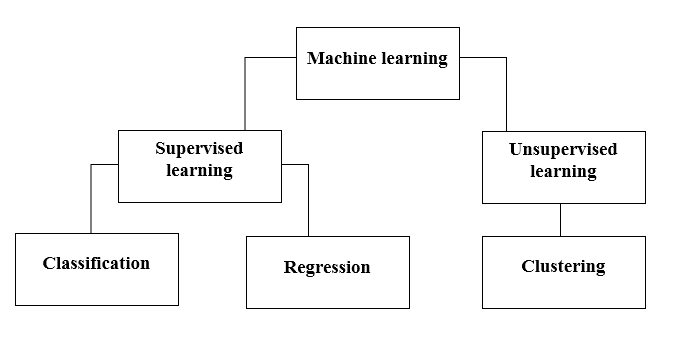
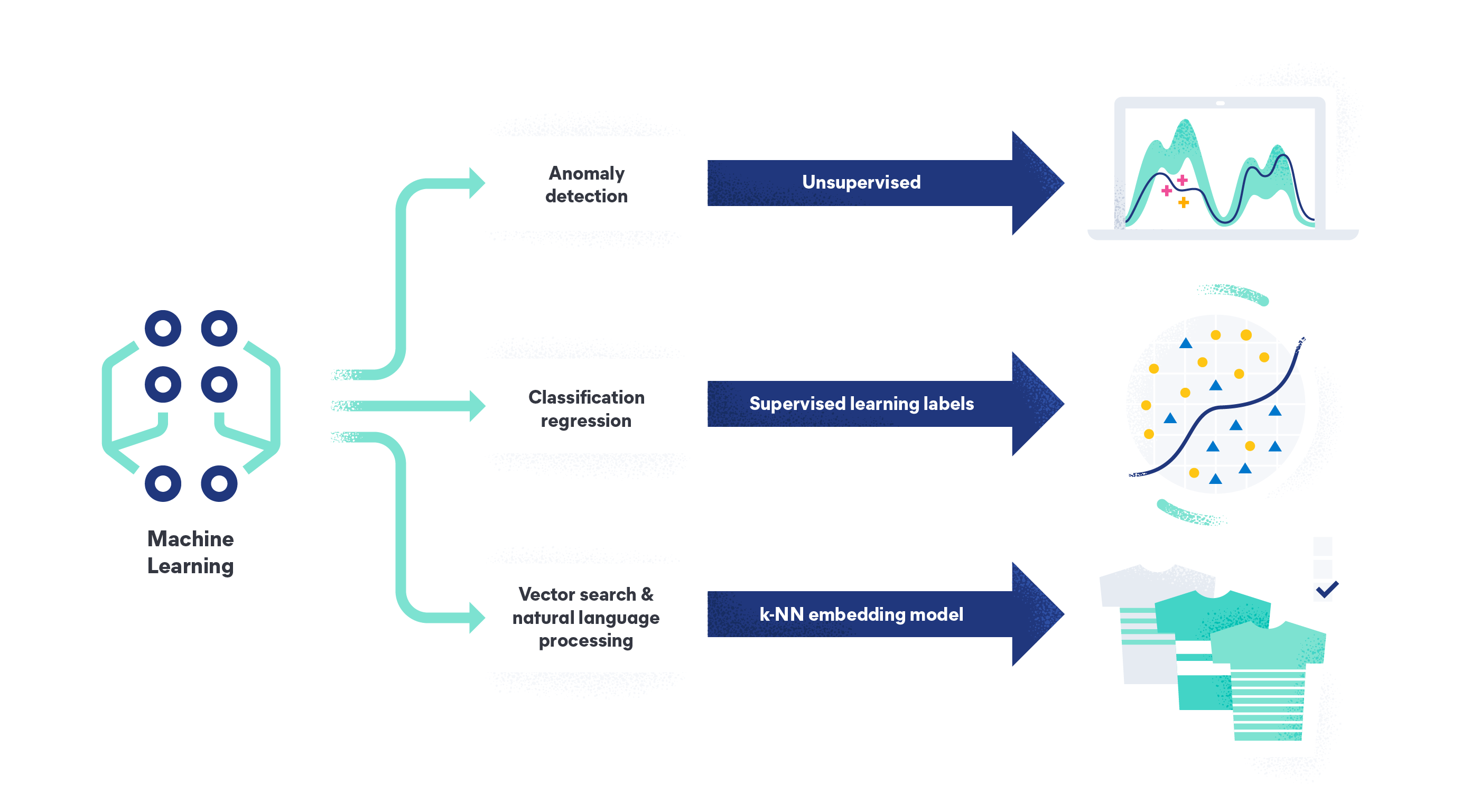
Machine Learning Methods are used to make the system learn using methods like Supervised learning and Unsupervised Learning which are further classified in methods like Classification, Regression and Clustering. This selection of methods entirely depends on the type of dataset that is available to train the model, as the dataset can be labeled, unlabelled, large. There are various applications (like image classification, Predictive analysis, Spam detection) that uses these different machine learning methods.
How do Machines learn?
There are various methods to do that. Which method to follow completely depends on the problem statement. Depending on the dataset, and our problem, there are two different ways to go deeper. One is supervised learning and the other is unsupervised learning. The following chart explains the further classification of machine learning methods. We will discuss them one by one.
Take a look at the following chart!
Let’s understand what does Supervised Learning means.
Supervised Learning
As the name suggests, imagine a teacher or a supervisor helping you to learn. The same goes for machines. We train or teach the machine using data that is labeled.
Some of the coolest supervised learning applications are:
Now, supervised learning is further divided into classification and regression. Let’s, understand this.
Classification
Classification is the process of finding a model that helps to separate the data into different categorical classes. In this process, data is categorized under different labels according to some parameters given in input and then the labels are predicted for the data. Categorical means the output variable is a category, i.e red or black, spam or not spam, diabetic or non-diabetic, etc.
Classification models include Support vector machine(SVM),K-nearest neighbor(KNN),Naive Bayes etc.
a) Support vector machine classifier (SVM)
SVM is a supervised learning method that looks at the data and sorts it into one of two categories. I use a hyperplane to categorize the data. A linear discriminative classifier attempts to draw a straight line separating the two sets of data and thereby create a model for classification. It simply tries to find a line or curve (in two dimensions) or a manifold (in multiple dimensions) that divides the classes from each other.
Note: For multiclass classification SVM makes use of ‘one vs rest’, that means calculating different SVM for each class.
b) K-nearest neighbor classifier (KNN)
If you read carefully, the name itself suggests what the algorithm does. KNN considers the data points which are closer, are much more similar in terms of features and hence more likely to belong to the same class as the neighbor. For any new data point, the distance to all other data points is calculated and the class is decided based on K nearest neighbors. Yes, it may sound lame, but for some of the classification, it works like anything.
A data point is classified by the maximum number vote of its neighbors, then the data point is assigned to the class nearest among its k-neighbors.
In KNN, no learning of the model is required and all of the work happens at the time a prediction is requested. That’s why KNN is often referred to as a lazy learning algorithm.
c) Naive Bayes classifier
Naive Bayes is a machine learning algorithm that is highly recommended for text classification problems. It is based on Bayes’ probability theorem. These classifiers are called naive because they assume that features variables are independent of each other. That means, for example, we have a full sentence for input, then Naive Bayes assumes every word in a sentence is independent of the other ones. And then classify them accordingly. I know, it looks pretty naive, but it’s a great choice for text classification problems and it’s a popular choice for spam email classification.
It provides different types of Naive Bayes Algorithms like BernoulliNB, GaussianNB, MultinomialNB.
It considers all the features to be unrelated, so it cannot learn the relationship between features. For example, Let’s say, Varun likes to eat burgers, he also likes to eat French fries with coke. But he doesn’t like to eat a burger and a combination of French fries with coke together. Here, Naive Bayes can not learn the relation between two features but only learns individual feature importance only.
Now let’s move on to the other side of our supervised learning method, which is a regression.
Regression
Regression is the process of finding a model that helps to differentiate the data using continuous values. In this, the nature of the predicted data is ordered. Some of the most widely used regression models include Linear regression, Random forest(Decision trees), Neural networks.
Linear regression
One of the simplest approaches in supervised learning, which is useful in predicting the quantitative response.
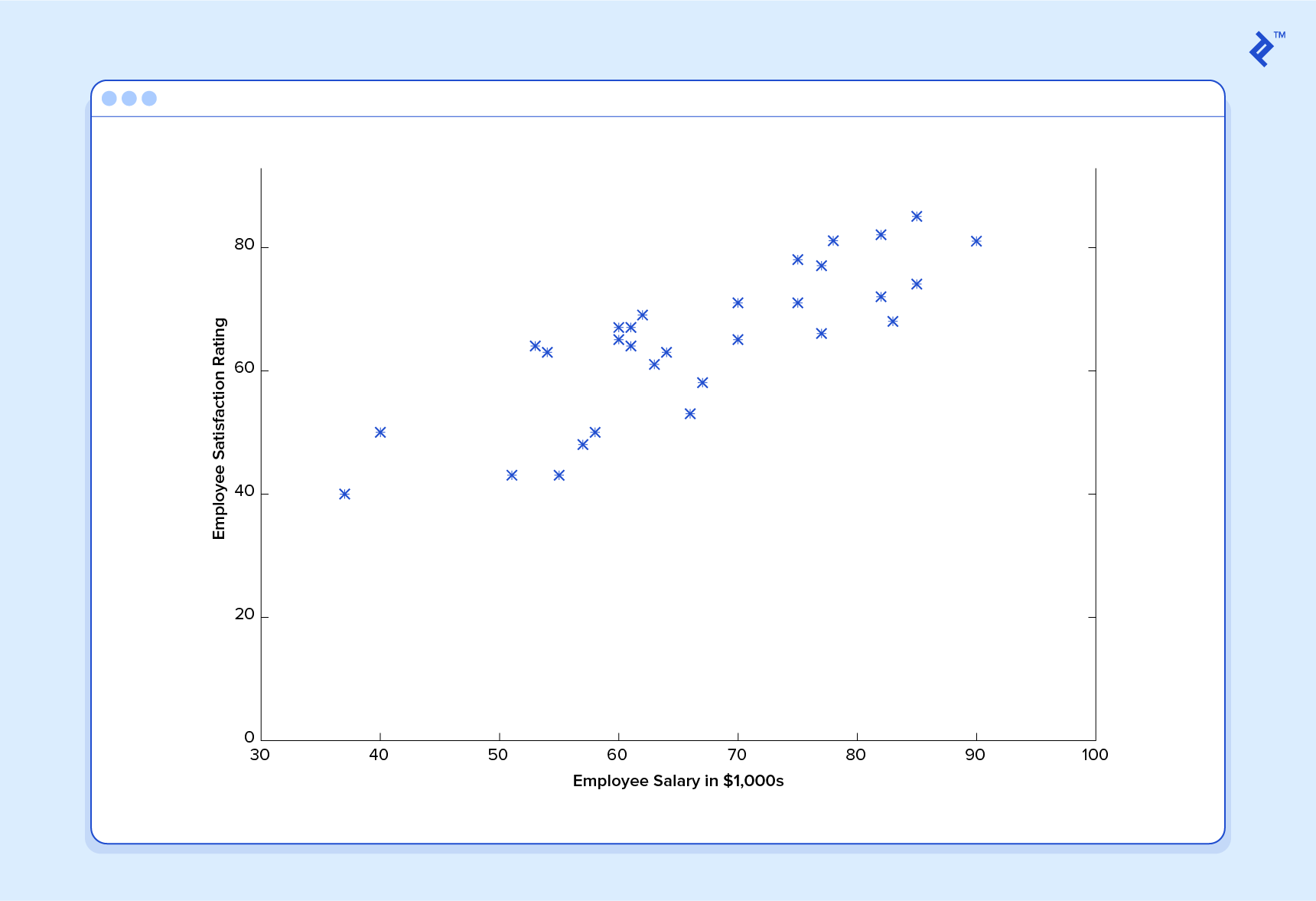
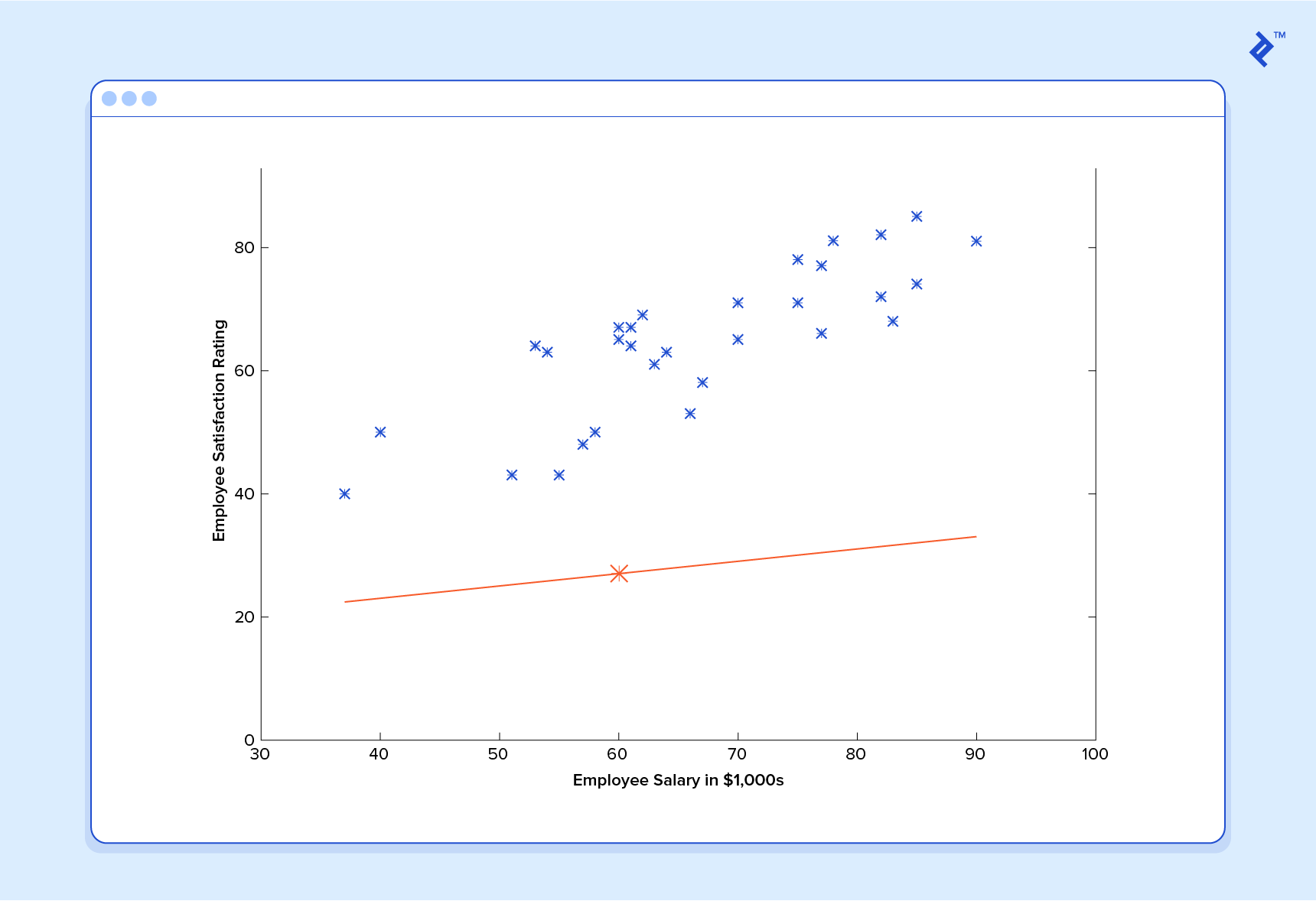
Linear regression includes finding the best-fitting straight line through the points. The best-fitting line is called a regression line. The best fit line doesn’t exactly pass through all the data points but instead tries it’s best to get close to them.
It is the widely used algorithm for continuous data. However, it only focuses on the mean of the dependent variable and limits itself to a linear relationship.
Linear regression can be used for Time series, trend forecasting. It can predict future sales, based on the previous data.
Unsupervised Learning
Unsupervised learning is based on the approach that can be thought of as the absence of a teacher and therefore of absolute error measures. It’s useful when it’s required to learn clustering or grouping of elements. Elements can be grouped (clustered) according to their similarity.
In unsupervised learning, data is unlabeled, not categorized and the system’s algorithms act on the data without prior training. Unsupervised learning algorithms can perform more complex tasks than supervised learning algorithms.
Unsupervised learning includes clustering which can be done by using K means clustering, hierarchical, Gaussian mixture, hidden Markov model.
Unsupervised Learning applications are:
Similarity detection
Automatic labeling
Object segmentation (such as Person, Animal, Films)
Clustering
Clustering is an unsupervised learning technique that is used for data analytics in many fields. The clustering algorithm comes handy when we want to gain detailed insights about our data.
A real-world example of clustering would be Netflix’s genre clusters, which are divided for different target customers including interests, demographics, lifestyles, etc. Now you can think about how useful clustering is when companies want to understand their customer base and target new potential customers.
a) K means Clustering
K means clustering algorithm tries to divide the given unknown data into clusters. It randomly selects ‘k’ clusters centroid, calculates the distance between data points and clusters centroid and then finally assigns the data point to cluster centroid whose distance is minimum of all cluster centroids.
In k-means, groups are defined by the closest centroid for every group. This centroid acts as ‘Brain’ of the algorithm, they acquire the data points which are closest to them and then add them to the clusters.
b) Hierarchical Clustering
Hierarchical clustering is nearly similar to that of normal clustering unless you want to build a hierarchy of clusters. This can come handy when you want to decide the number of clusters. For example, suppose you are creating groups of different items on the online grocery store. On the front home page, you want a few broad items and once you click on one of the items, specific categories, that is more specific clusters opens up.
Dimensionality reduction
Dimensionality reduction can be considered as compression of a file. It means, taking out the information which is not relevant. It reduces the complexity of data and tries to keep the meaningful data. For example, in image compression, we reduce the dimensionality of the space in which the image stays as it is without destroying too much of the meaningful content in the image.
PCA for Data Visualization
Principal component analysis (PCA) is a dimension reduction method that can be useful to visualize your data. PCA is used to compress higher dimensional data to lower-dimensional data, that is, we can use PCA to reduce a four-dimensional data into three or 2 dimensions so that we can visualize and get a better understanding of the data.
Healthcare is an industry that is constantly evolving. New technologies and treatments are being developed all the time, which can make it difficult for healthcare professionals to keep up. In recent years, machine learning in healthcare has become one of the most popular buzzwords. But what is machine learning in healthcare exactly? Why is machine learning so important for patient data? And what are some of the benefits of machine learning in healthcare?
What is Machine Learning?
Machine learning is a specific type of artificial intelligence that allows systems to learn from data and detect patterns without much human intervention. Instead of being told what to do, computers that use machine learning are shown patterns and data which then allows them to reach their own conclusions.
Machine learning algorithms have a variety of functions, like helping to filter email, identify objects in images and analyze large volumes of increasingly complex data sets. Computers use machine learning systems to automatically go through emails and find spam, as well as recognize things in pictures and process big data.
Machine learning in healthcare is a growing field of research in precision medicine with many potential applications. As patient data becomes more readily available, machine learning in healthcare will become increasingly important to healthcare professionals and health systems for extracting meaning from medical information.
Why is Machine Learning Important for Healthcare Organizations?
For the healthcare industry, machine learning algorithms are particularly valuable because they can help us make sense of the massive amounts of healthcare data that is generated every day within electronic health records. Using machine learning in healthcare like machine learning algorithms can help us find patterns and insights in medical data that would be impossible to find manually.
As machine learning in healthcare gains widespread adoption, healthcare providers have an opportunity to take a more predictive approach to precision medicine that creates a more unified system with improved care delivery, better patient outcomes and more efficient patient-based processes.
The most common use cases for machine learning in healthcare among healthcare professionals are automating medical billing, clinical decision support and the development of clinical practice guidelines within health systems. There are many notable high-level examples of machine learning and healthcare concepts being applied in science and medicine. At MD Anderson, data scientists have developed the first deep learning in healthcare algorithm using machine learning to predict acute toxicities in patients receiving radiation therapy for head and neck cancers. In clinical workflows, the medical data generated by deep learning in healthcare can identify complex patterns automatically, and offer a primary care provider clinical decision support at the point of care within the electronic health record.
Large volumes of unstructured healthcare data for machine learning represent almost 80% of the information held or “locked” in electronic health record systems. These are not data elements but relevant data documents or text files with patient information, which in the past could not be analyzed by healthcare machine learning but required a human to read through the medical records.
Human language, or “natural language,” is very complex, lacking uniformity and incorporates an enormous amount of ambiguity, jargon, and vagueness. In order to convert these documents into more useful and analyzable data, machine learning in healthcare often relies on artificial intelligence like natural language processing programs. Most deep learning in healthcare applications that use natural language processing require some form of healthcare data for machine learning.
What Are the Benefits for Healthcare Providers and Patient Data?
As you can see, there are a wide range of potential uses for machine learning technologies in healthcare from improving patient data, medical research, diagnosis and treatment, to reducing costs and making patient safety more efficient. Here’s a list of just some of the benefits machine learning applications in healthcare can bring healthcare professionals in the healthcare industry:
Improving diagnosis
Machine learning in healthcare can be used by medical professionals to develop better diagnostic tools to analyze medical images. For example, a machine learning algorithm can be used in medical imaging (such as X-rays or MRI scans) using pattern recognition to look for patterns that indicate a particular disease. This type of machine learning algorithm could potentially help doctors make quicker, more accurate diagnoses leading to improved patient outcomes.
Developing new treatments / drug discovery / clinical trials
A deep learning model can also be used by healthcare organizations and pharmaceutical companies to identify relevant information in data that could lead to drug discovery, the development of new drugs by pharmaceutical companies and new treatments for diseases. For example, machine learning in healthcare could be used to analyze data and medical research from clinical trials to find previously unknown side-effects of drugs. This type of healthcare machine learning in clinical trials could help to improve patient care, drug discovery, and the safety and effectiveness of medical procedures.
Reducing costs
Machine learning technologies can be used by healthcare organizations to improve the efficiency of healthcare, which could lead to cost savings. For example, machine learning in healthcare could be used to develop better algorithms for managing patient records or scheduling appointments. This type of machine learning could potentially help to reduce the amount of time and resources that are wasted on repetitive tasks in the healthcare system.
Improving care
Machine learning in healthcare can also be used by medical professionals to improve the quality of patient care. For example, deep learning algorithms could be used by the healthcare industry to develop systems that proactively monitor patients and provide alerts to medical devices or electronic health records when there are changes in their condition. This type of data collection machine learning could help to ensure that patients receive the right care at the right time.
Machine learning applications in healthcare are already having a positive impact, and the potential of machine learning to deliver care is still in the early stages of being realized. In the future, machine learning in healthcare will become increasingly important as we strive to make sense of ever-growing clinical data sets.
At ForeSee Medical, machine learning medical data consists of training our AI-powered risk adjustment software to analyze the speech patterns of our physician end users and determine context (hypothetical, negation) of important medical terms. Our robust negation engine can identify not only key terms, but also all four negation types: hypothetical (could be, differential), negative (denies), history (history of) and family history (mom, wife) are the four important negation types. With over 500 negation terms our machine learning technology is able to achieve accuracy rates that are greater than 97%.
Additionally, our proprietary medical algorithms use machine learning to process and analyze your clinical practice data and notes. This is a dynamic set of machine learned algorithms that play a key role in data collection and are always being reviewed and improved upon by our clinical informatics team. Within our clinical algorithms we’ve developed unique uses of machine learning in healthcare such as proprietary concepts, terms and our own medical dictionary. The ForeSee Medical Disease Detector’s natural language processing engine extracts your clinical data and notes, it’s then analyzed by our clinical rules and machine learning algorithms. Natural language processing performance is constantly improving for better outcomes because we continuously feed our “machine” patient healthcare data for machine learning that makes our natural language processing performance more precise.
But not everything is done by artificial intelligence systems or artificial intelligence technologies like machine learning. The data for machine learning in healthcare has to be prepared in such a way that the computer can more easily find patterns and inferences. This statistical technique is usually done by humans that tag elements of the dataset for data quality which is called an annotation over the input. Our team of clinical experts are performing this function as well as analyzing results, writing new rules and improving machine learning performance. However, in order for the machine learning applications in healthcare to learn efficiently and effectively, the annotation done on the patient data must be accurate, and relevant to our task of extracting key concepts with proper context.
ForeSee Medical and its team of clinicians are using machine learning and healthcare data to power our proprietary rules and language processing intelligence with the ultimate goal of superior disease detection. This is the critical driving force behind precision medicine and properly documenting your patients’ HCC risk adjustment coding at the point of care – getting you the accurate reimbursements you deserve.
The Elasticsearch Platform natively integrates powerful machine learning and AI into solutions — helping you build applications users crave and get work done faster.
Everyone can find answers and insights with Elastic machine learning
Get immediate value from machine learning with domain-specific use cases built right into Elasticsearch. With observability, search, and security solutions, DevOps engineers, SREs, and security analysts can get started right away. No prior experience with machine learning required.
Teams can automate anomaly detection and root cause analysis, reducing mean time to repair (MTTR). In addition, built-in capabilities such as natural language processing (NLP) and vector search help teams implement search experiences that are easier for end users.
Use Elastic machine learning to:
Identify unusually slow response times directly from the APM service map
Discover unusual behavior and proactively address security threats
Customize anomaly detection for any type of data with easy-to-use wizard-based workflows
Enhance search experiences by enriching the ingested data with predictions
Automate alerts and identify root cause in observability
Accelerate problem detection and resolution with automated anomaly detection, correlations, and other AIOps capabilities built into Elastic Observability. DevOps and SRE teams can identify unusually slow response times directly from the APM service map. You can apply machine learning without having to configure models.
Threat hunting powered by Machine learning
Machine learning powers threat detection in Elastic Security. You can reduce mean time to resolution (MTTR) by automatically identifying unusual activity in the SIEM app. For threats that are difficult to identify, supervised models can disambiguate suspicious from benign activity, for example for living off the land attacks or domain generated algorithms.
Take search experiences to the next level
With Elasticsearch, you can build search-powered applications using natively run vector search and NLP to achieve superior search relevance, performance, and personalization. Reference the models while configuring the ingestion pipeline, as shown on the right.
Actionable insights in minutes with Elasticsearch machine learning
Apply Elastic machine learning to your data to:
Natively integrate machine learning on a scalable and performant platform
Apply unsupervised learning and preconfigured models that identify observability and security issues without having to worry about how to train an AI model
Leverage actionable analytics that proactively surface threats and anomalies, accelerate problem resolution, identify customer behavioral trends, and improve your digital experiences
To apply Elastic machine learning, you don’t need to have a data science team or design a system architecture. Our machine learning capabilities allow you to quickly get started! There’s no need to move data to a third-party framework for model training.
For those use cases that require custom models and optimized performance, our tools let you adjust parameters and import optimized models from the PyTorch framework.
Ingest, understand and build models with your data
Elastic’s out-of-the-box integrations make data ingestion and connecting to other data sources easy. Once your data is in Elasticsearch, you can visualize and gain initial insights in minutes.
Elastic’s open, common data model, Elastic Common Schema (ECS), gives you the flexibility to collect, store, and visualize any data. This includes metrics, logs, traces, content, and events from your apps and infrastructure. To start, choose your ingest method. Options include Elastic Agent, web crawler, data connectors, and APIs, and we have native integrations with all major cloud providers. Once your data is in Elastic, built-in tools — like Data Visualizer — help you identify fields in your data that would pair well with machine learning.
No experience applying machine learning? Apply the preconfigured models for observability and security. If those don’t work well enough on your data, in-tool wizards guide you through the few steps needed to configure custom anomaly detection and train supervised learning.
Ingestion
Data Visualizer
Machine Learning Wizards
Accurate anomaly and outlier detection out-of-the-box
Unsupervised machine learning with Elastic helps you find patterns in your data. Use time series modeling to detect anomalies in single or multiple time series, population data, and forecast trends based on historical data.
You can also detect anomalies in logs by grouping messages, and uncover root causes by reviewing anomaly influencers or fields correlated with deviations from baselines.
Supervised machine learning with operational ease
To categorize your data and make predictions, train classification or regression models using data frame analytics in Elastic. Supervised models get you closer to the root cause of issues and can drive intelligent decisions in your applications.
You can use continuous index to convert application logs index into a user-centric activity view and build a fraud detection model using classification. Then you can apply your models to your incoming data at ingest, all without ever leaving Elastic.
Vector search and modern natural language processing
Vector semantic search lets your users find what they mean, instead of being limited to keywords. They can search through textual data, images, and other unstructured data.
With Elastic machine learning, you can implement semantic search to make digital experiences more intuitive and results more relevant. Examples include:
Ecommerce product similarity search that displays relevant alternative products
Job recommendation and online dating — match based on profile compatibility, while restricting search by geolocation
Patent search — retrieve patents whose textual descriptions are similar
To get started, Elastic lets you import pre-trained BERT-like PyTorch models from hubs, like Huggingface.co, or the CLIP model from OpenAI. Learn more about implementing image similarity with Elastic.
What is Machine Learning? Machine learning is a field of computer science that aims to teach computers how to learn and act without being explicitly programmed. More specifically, machine learning is an approach to data analysis that involves building and adapting models, which allow programs to “learn” through experience. Machine learning involves the construction of algorithms that adapt their models to improve their ability to make predictions.
According to Tom Mitchell, professor of Computer Science and Machine Learning at Carnegie Mellon, a computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. A mathematical way of saying that a program uses machine learning if it improves at problem solving with experience.
The first uses and discussions of machine learning date back to the 1950’s and its adoption has increased dramatically in the last 10 years. Common applications of machine learning include image recognition, natural language processing, design of artificial intelligence, self-driving car technology, and Google’s web search algorithm.
Machine Learning vs Artificial Intelligence It is worth emphasizing the difference between machine learning and artificial intelligence. Machine learning is an area of study within computer science and an approach to designing algorithms. This approach to algorithm design enables the creation and design of artificially intelligent programs and machines.
Applications and Examples of Machine Learning Machine learning is an area of study and an approach to problem solving. And there are many different applications to which machine learning methods can be applied. Below are a few of the many applications of machine learning strategies and methods:
Natural Language Processing Natural language processing (NLP) is a field of computer science that is primarily concerned with the interactions between computers and natural (human) languages. Major emphases of natural language processing include speech recognition, natural language understanding, and natural language generation. Machine learning methods can be applied to each of these areas.
Insurance Claim Analysis The insurance industry is applying machine learning in several ways. Most interestingly, several companies are using machine learning algorithms to make predictions about future claims which are being used to price insurance premiums. In addition, some companies in the insurance and banking industries are using machine learning to detect fraud.
Bioinformatics and Medical Diagnosis The amount of biological data being compiled by research scientists is growing at an exponential rate. This has led to problems with efficient data storage and management as well as with the ability to pull useful information from this data. Currently machine learning methods are being developed to efficiently and usefully store biological data, as well as to intelligently pull meaning from the stored data.
Efforts are also being made to apply machine learning and pattern recognition techniques to medical records in order to classify and better understand various diseases. These approaches are also expected to help diagnose disease by identifying segments of the population that are the most at risk for certain disease.
Image Processing and Pattern Recognition Using computers to identify patterns and identify objects within images, videos, and other media files is far less practical without machine learning techniques. Writing programs to identify objects within an image would not be very practical if specific code needed to be written for every object you wanted to identify.
Instead, image recognition algorithms, also called image classifiers, can be trained to classify images based on their content. These algorithms are trained by processing many sample images that have already been classified. Using the similarities and differences of images they’ve already processed, these programs improve by updating their models every time they process a new image. This form of machine learning used in image processing is usually done using an artificial neural network and is known as deep learning.
Search Engines Web search also benefits from the use of deep learning by using it to improve search results and better understand user queries. By analyzing user behavior against the query and results served, companies like Google can improve their search results and understand what the best set of results are for a given query. Search suggestions and spelling corrections are also generated by using machine learning tactics on aggregated queries of all users.
Financial Market Analysis Algorithmic trading and market analysis have become mainstream uses of machine learning and artificial intelligence in the financial markets. Fund managers are now relying on deep learning algorithms to identify changes in trends and even execute trades. Funds and traders who use this automated approach make trades faster than they possibly could if they were taking a manual approach to spotting trends and making trades.
Additional Applications of Machine Learning Machine learning, because it is merely a scientific approach to problem solving, has almost limitless applications. In addition to the applications above, use of machine learning techniques can also be seen in genetic sciences for classification of DNA sequences, in banking for fraud detection, in online advertising for perfection of ad targeting, and in many other industries to improve efficiency and data processing capabilities.
How Does Machine Learning Work? Clearly, there are many ways that machine learning is being used today. But how is it being used? What are these programs actually doing to solve problems more effectively? How do these approaches differ from historical methods of solving problems?
As stated above, machine learning is a field of computer science that aims to give computers the ability to learn without being explicitly programmed. The approach or algorithm that a program uses to “learn” will depend on the type of problem or task that the program is designed to complete.
So a good way to understand how machine learning works, is to understand what types of problems machine learning attempts to solve and then look at how it tries to solve those problems. First, a list of the types of problems machine learning aims to solve:
Types of Machine Learning Tasks Machine learning algorithms all aim to learn and improve their accuracy as they process more datasets. One way that we can classify the tasks that machine learning algorithms solve is by how much feedback they present to the system. In some scenarios, the computer is provided a significant amount of labelled training data is provided, which is called supervised learning. In other cases, no labelled data is provided and this is known as unsupervised learning. Lastly, in semi-supervised learning, some labelled training data is provided, but most of the training data is unlabelled. Let’s review each type in more detail:
Supervised Learning Supervised learning is the most practical and widely adopted form of machine learning. It involves creating a mathematical function that relates input variables to the preferred output variables. A large amount of labeled training datasets are provided which provide examples of the data that the computer will be processing.
Supervised learning tasks can further be categorized as “classification” or “regression” problems. Classification problems use statistical classification methods to output a categorization, for instance, “hot dog” or “not hot dog”. Regression problems, on the other hand, use statistical regression analysis to provide numerical outputs.
Semi-supervised Learning Semi-supervised learning is actually the same as supervised learning except that of the training data provided, only a limited amount is labelled.
Image recognition is a good example of semi-supervised learning. In this example, we might provide the system with several labelled images containing objects we wish to identify, then process many more unlabelled images in the training process.
Unsupervised Learning In unsupervised learning problems, all input is unlabelled and the algorithm must create structure out of the inputs on its own. Clustering problems (or cluster analysis problems) are unsupervised learning tasks that seek to discover groupings within the input datasets. Examples of this could be patterns in stock data or consumer trends. Neural networks are also commonly used to solve unsupervised learning problems.
Machine Learning Algorithms and Approaches to Problem Solving An algorithm is an approach to solving a problem, and machine learning offers many different approaches to solve a wide variety of problems. Below is a list of some of the most common and useful algorithms and approaches used in machine learning applications today. Keep in mind that applications will often use many of these approaches together to solve a given problem:
Artificial Neural Networks An artificial neural network is a computational model based on biological neural networks, like the human brain. It uses a series of functions to process an input signal or file and translate it over several stages into the expected output. This method is often used in image recognition, language translation, and other common applications today.
Deep Learning Deep learning refers to a family of machine learning algorithms that make heavy use of artificial neural networks. In a 2016 Google Tech Talk, Jeff Dean describes deep learning algorithms as using very deep neural networks, where “deep” refers to the number of layers, or iterations between input and output. As computing power is becoming less expensive, the learning algorithms in today’s applications are becoming “deeper.”
Cluster Analysis A cluster analysis attempts to group objects into “clusters” of items that are more similar to each other than items in other clusters. The way that the items are similar depends on the data inputs that are provided to the computer program. Because cluster analyses are most often used in unsupervised learning problems, no training is provided.
The program will use whatever data points are provided to describe each input object and compare the values to data about objects that it has already analyzed. Once enough objects have been analyze to spot groupings in data points and objects, the program can begin to group objects and identify clusters.
Clustering is not actually one specific algorithm; in fact, there are many different paths to performing a cluster analysis. It is a common task in statistical analysis and data mining.
Bayesian Networks A Bayesian network is a graphical model of variables and their dependencies on one another. Machine learning algorithms might use a bayesian network to build and describe its belief system. One example where bayesian networks are used is in programs designed to compute the probability of given diseases. Symptoms can be taken as input and the probability of diseases output.
Reinforcement Learning Reinforcement learning refers to an area of machine learning where the feedback provided to the system comes in the form of rewards and punishments, rather than being told explicitly, “right” or “wrong”. This comes into play when finding the correct answer is important, but finding it in a timely manner is also important.
So a large element of reinforcement learning is finding a balance between “exploration” and “exploitation”. How often should the program “explore” for new information versus taking advantage of the information that it already has available? By “rewarding” the learning agent for behaving in a desirable way, the program can optimize its approach to acheive the best balance between exploration and exploitation.
Decision Tree Learning Decision tree learning is a machine learning approach that processes inputs using a series of classifications which lead to an output or answer. Typically such decision trees, or classification trees, output a discrete answer; however, using regression trees, the output can take continuous values (usually a real number).
Rule-based Machine Learning Rule-based machine learning refers to a class of machine learning methods that generates “rules” to analyze models, applies those rules while analyzing models, and adapts the rules to improve performance (learn). This technique is used in artificial immune systems and to create associate rule learning algorithms, which is covered next.
Association Rule Learning Association rule learning is a method of machine learning focused on identifying relationships between variables in a database. One example of applied association rule learning is the case where marketers use large sets of super market transaction data to determine correlations between different product purchases. For instance, “customers buying pickles and lettuce are also likely to buy sliced cheese.” Correlations or “association rules” like this can be discovered using association rule learning.
Inductive Logic Programming To understand inductive logic programming, it is important to first understand “logic programming”. Logic programming is a paradigm in computer programming in which programs are written as a set of expressions which state facts or rules, often in “if
this, then that” form. Understanding that “logic programming” revolves around using a set of logical rules, we can begin to understand inductive logic programming. Inductive logic programming is an area of research that makes use of both machine learning and logic programming. In ILP problems, the background knowledge that the program uses is remembered as a set of logical rules, which the program uses to derive its hypothesis for solving problems.
Applications of inductive logic programming today can be found in natural language processing and bioinformatics.
Support Vector Machines Support vector machines are a supervised learning tool commonly used in classification and regression problems. An computer program that uses support vector machines may be asked to classify an input into one of two classes. The program will be provided with training examples of each class that can be represented as mathematical models plotted in a multidimensional space (with the number of dimensions being the number of features of the input that the program will assess).
The program plots representations of each class in the multidimensional space and identifies a “hyperplane” or boundary which separates each class. When a new input is analyzed, its output will fall on one side of this hyperplane. The side of the hyperplane where the output lies determines which class the input is. This hyperplane is the support vector machine.
Representation Learning Representation learning, also called feature learning, is a set of techniques within machine learning that enables the system to automatically create representations of objects that will best allow them to recognize and detect features and then distinguish different objects. So the features are also used to perform analysis after they are identified by the system.
Feature learning is very common in classification problems of images and other media. Because images, videos, and other kinds of signals don’t always have mathematically convenient models, it is usually beneficial to allow the computer program to create its own representation with which to perform the next level of analysis.
Similarity Learning Similarity learning is a representation learning method and an area of supervised learning that is very closely related to classification and regression. However, the goal of a similarity learning algorithm is to identify how similar or different two or more objects are, rather than merely classifying an object. This has many different applications today, including facial recognition on phones, ranking/recommendation systems, and voice verification.
Sparse Dictionary Learning Sparse dictionary learning is merely the intersection of dictionary learning and sparse representation, or sparse coding. The computer program aims to build a representation of the input data, which is called a dictionary. By applying sparse representation principles, sparse dictionary learning algorithms attempt to maintain the most succinct possible dictionary that can still completing the task effectively.
Genetic and Evolutionary Algorithms Although machine learning has been very helpful in studying the human genome and related areas of science, the phrase “genetic algorithms” refers to a class of machine learning algorithms and the approach they take to problem solving, and not the genetics-related applications of machine learning. Genetic algorithms actually draw inspiration from the biological process of natural selection. These algorithms use mathematical equivalents of mutation, selection, and crossover to build many variations of possible solutions.
History of Machine Learning Machine learning provides humans with an enormous number of benefits today, and the number of uses for machine learning is growing faster than ever. However, it has been a long journey for machine learning to reach the mainstream.
Early History and the Foundation of Research The term “machine learning” was first coined by artificial intelligence and computer gaming pioneer Arthur Samuel in 1959. However, Samuel actually wrote the first computer learning program while at IBM in 1952. The program was a game of checkers in which the computer improved each time it played, analyzing which moves composed a winning strategy.
In 1957, Frank Rosenblatt created the first artificial computer neural network, also known as a perceptron, which was designed to simulate the thought processes of the human brain.
In 1967, the “nearest neighbor” algorithm was designed which marks the beginning of basic pattern recognition using computers.
These early discoveries were significant, but a lack of useful applications and limited computing power of the era led to a long period of stagnation in machine learning and AI until the 1980s.
Machine Learning Expands Away from AI Until the 80s and early 90s, machine learning and artificial intelligence had been almost one in the same. But around the early 90s, researchers began to find new, more practical applications for the problem solving techniques they’d created working toward AI.
Looking toward more practical uses of machine learning opened the door to new approaches that were based more in statistics and probability than they were human and biological behavior. Machine learning had now developed into its own field of study, to which many universities, companies, and independent researchers began to contribute.
Modern Day Machine Learning Today, machine learning is embedded into a significant number of applications and affects millions (if not billions) of people everyday. The massive amount of research toward machine learning resulted in the development of many new approaches being developed, as well as a variety of new use cases for machine learning. In reality, machine learning techniques can be used anywhere a large amount of data needs to be analyzed, which is a common need in business.
Three main reasons have lead to a mass adoption of machine learning in business and research applications: (1) computing power has increased significantly and become much less expensive over the last several decades, (2) information about the powers and use cases of machine learning has spread with the expansion of the internet, and (3) open source machine learning tools have become more widely available.
Companies in biomedical, internet/technology, logistics, and almost every other industry are making use of the awesome power of machine learning. Here are a few examples where machine learning is used today:
Google uses machine learning to better understand its users’ search queries. Google also uses machine learning to improve its results by measuring engagement with the results it returns. Medical research organizations are using machine learning to analyze enormous amounts of human health record data in attempts to identify patterns in diseases and conditions and improve healthcare. Ride-sharing apps like Lyft make use of machine learning to optimize routes and pricing by time of day and location. Email programs use machine learning techniques to figure out what belongs in the Spam folder. Banks are using machine learning to spot transactions and behavior that may be suspicious or fraudulent. These are just a handful of thousands of examples of where machine learning techniques are used today. Machine learning is an exciting and rapidly expanding field of study, and the applications are seemingly endless. As more people and companies learn about the uses of the technology and the tools become increasingly available and easy to use, expect to see machine learning become an even bigger part of every day life.
If you are a developer, or would simply like to learn more about machine learning, take a look at some of the machine learning and artificial intelligence resources available on DeepAI.
This Machine Learning tutorial introduces the basics of ML theory, laying down the common themes and concepts, making it easy to follow the logic and get comfortable with the topic.
Machine learning (ML) is coming into its own, with a growing recognition that ML can play a key role in a wide range of critical applications, such as data mining, natural language processing, image recognition, and expert systems. ML provides potential solutions in all these domains and more, and likely will become a pillar of our future civilization.
The supply of expert ML designers has yet to catch up to this demand. A major reason for this is that ML is just plain tricky. This machine learning tutorial introduces the basic theory, laying out the common themes and concepts, and making it easy to follow the logic and get comfortable with machine learning basics.
Machine Learning Basics: What Is Machine Learning?
So what exactly is “machine learning” anyway? ML is a lot of things. The field is vast and is expanding rapidly, being continually partitioned and sub-partitioned into different sub-specialties and types of machine learning.
There are some basic common threads, however, and the overarching theme is best summed up by this oft-quoted statement made by Arthur Samuel way back in 1959: “[Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed.”
In 1997, Tom Mitchell offered a “well-posed” definition that has proven more useful to engineering types: “A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”
“A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.” — Tom Mitchell, Carnegie Mellon University
So if you want your program to predict, for example, traffic patterns at a busy intersection (task T), you can run it through a machine learning algorithm with data about past traffic patterns (experience E) and, if it has successfully “learned,” it will then do better at predicting future traffic patterns (performance measure P).
The highly complex nature of many real-world problems, though, often means that inventing specialized algorithms that will solve them perfectly every time is impractical, if not impossible.
Real-world examples of machine learning problems include “Is this cancer?”, “What is the market value of this house?”, “Which of these people are good friends with each other?”, “Will this rocket engine explode on take off?”, “Will this person like this movie?”, “Who is this?”, “What did you say?”, and “How do you fly this thing?” All of these problems are excellent targets for an ML project; in fact ML has been applied to each of them with great success.
ML solves problems that cannot be solved by numerical means alone.
Among the different types of ML tasks, a crucial distinction is drawn between supervised and unsupervised learning:
Supervised machine learning is when the program is “trained” on a predefined set of “training examples,” which then facilitate its ability to reach an accurate conclusion when given new data.
Unsupervised machine learning is when the program is given a bunch of data and must find patterns and relationships therein.
We will focus primarily on supervised learning here, but the last part of the article includes a brief discussion of unsupervised learning with some links for those who are interested in pursuing the topic.
Supervised Machine Learning
In the majority of supervised learning applications, the ultimate goal is to develop a finely tuned predictor function h(x) (sometimes called the “hypothesis”). “Learning” consists of using sophisticated mathematical algorithms to optimize this function so that, given input data x about a certain domain (say, square footage of a house), it will accurately predict some interesting value h(x) (say, market price for said house).
In practice, x almost always represents multiple data points. So, for example, a housing price predictor might consider not only square footage (x1) but also number of bedrooms (x2), number of bathrooms (x3), number of floors (x4), year built (x5), ZIP code (x6), and so forth. Determining which inputs to use is an important part of ML design. However, for the sake of explanation, it is easiest to assume a single input value.
Let’s say our simple predictor has this form:
where
and
are constants. Our goal is to find the perfect values of
and
to make our predictor work as well as possible.
Optimizing the predictor h(x) is done using training examples. For each training example, we have an input value x_train, for which a corresponding output, y, is known in advance. For each example, we find the difference between the known, correct value y, and our predicted value h(x_train). With enough training examples, these differences give us a useful way to measure the “wrongness” of h(x). We can then tweak h(x) by tweaking the values of
and
to make it “less wrong”. This process is repeated until the system has converged on the best values for
and
. In this way, the predictor becomes trained, and is ready to do some real-world predicting.
Machine Learning Examples
We’re using simple problems for the sake of illustration, but the reason ML exists is because, in the real world, problems are much more complex. On this flat screen, we can present a picture of, at most, a three-dimensional dataset, but ML problems often deal with data with millions of dimensions and very complex predictor functions. ML solves problems that cannot be solved by numerical means alone.
With that in mind, let’s look at another simple example. Say we have the following training data, wherein company employees have rated their satisfaction on a scale of 1 to 100:
First, notice that the data is a little noisy. That is, while we can see that there is a pattern to it (i.e., employee satisfaction tends to go up as salary goes up), it does not all fit neatly on a straight line. This will always be the case with real-world data (and we absolutely want to train our machine using real-world data). How can we train a machine to perfectly predict an employee’s level of satisfaction? The answer, of course, is that we can’t. The goal of ML is never to make “perfect” guesses because ML deals in domains where there is no such thing. The goal is to make guesses that are good enough to be useful.
It is somewhat reminiscent of the famous statement by George E. P. Box, the British mathematician and professor of statistics: “All models are wrong, but some are useful.”
The goal of ML is never to make “perfect” guesses because ML deals in domains where there is no such thing. The goal is to make guesses that are good enough to be useful.
Machine learning builds heavily on statistics. For example, when we train our machine to learn, we have to give it a statistically significant random sample as training data. If the training set is not random, we run the risk of the machine learning patterns that aren’t actually there. And if the training set is too small (see the law of large numbers), we won’t learn enough and may even reach inaccurate conclusions. For example, attempting to predict companywide satisfaction patterns based on data from upper management alone would likely be error-prone.
With this understanding, let’s give our machine the data we’ve been given above and have it learn it. First we have to initialize our predictor h(x) with some reasonable values of
and
. Now, when placed over our training set, our predictor looks like this:
If we ask this predictor for the satisfaction of an employee making $60,000, it would predict a rating of 27:
It’s obvious that this is a terrible guess and that this machine doesn’t know very much.
Now let’s give this predictor all the salaries from our training set, and note the differences between the resulting predicted satisfaction ratings and the actual satisfaction ratings of the corresponding employees. If we perform a little mathematical wizardry (which I will describe later in the article), we can calculate, with very high certainty, that values of 13.12 for
and 0.61 for
are going to give us a better predictor.
And if we repeat this process, say 1,500 times, our predictor will end up looking like this:
At this point, if we repeat the process, we will find that
and
will no longer change by any appreciable amount, and thus we see that the system has converged. If we haven’t made any mistakes, this means we’ve found the optimal predictor. Accordingly, if we now ask the machine again for the satisfaction rating of the employee who makes $60,000, it will predict a rating of ~60.
Now we’re getting somewhere.
Machine Learning Regression: A Note on Complexity
The above example is technically a simple problem of univariate linear regression, which in reality can be solved by deriving a simple normal equation and skipping this “tuning” process altogether. However, consider a predictor that looks like this:
This function takes input in four dimensions and has a variety of polynomial terms. Deriving a normal equation for this function is a significant challenge. Many modern machine learning problems take thousands or even millions of dimensions of data to build predictions using hundreds of coefficients. Predicting how an organism’s genome will be expressed or what the climate will be like in 50 years are examples of such complex problems.
Many modern ML problems take thousands or even millions of dimensions of data to build predictions using hundreds of coefficients.
Fortunately, the iterative approach taken by ML systems is much more resilient in the face of such complexity. Instead of using brute force, a machine learning system “feels” its way to the answer. For big problems, this works much better. While this doesn’t mean that ML can solve all arbitrarily complex problems—it can’t—it does make for an incredibly flexible and powerful tool.
Gradient Descent: Minimizing “Wrongness”
Let’s take a closer look at how this iterative process works. In the above example, how do we make sure
and
are getting better with each step, not worse? The answer lies in our “measurement of wrongness”, along with a little calculus. (This is the “mathematical wizardry” mentioned to previously.)
The wrongness measure is known as the cost function (aka loss function),
. The input
represents all of the coefficients we are using in our predictor. In our case,
is really the pair
and
.
gives us a mathematical measurement of the wrongness of our predictor is when it uses the given values of
and
.
The choice of the cost function is another important piece of an ML program. In different contexts, being “wrong” can mean very different things. In our employee satisfaction example, the well-established standard is the linear least squares function:
With least squares, the penalty for a bad guess goes up quadratically with the difference between the guess and the correct answer, so it acts as a very “strict” measurement of wrongness. The cost function computes an average penalty across all the training examples.
Now we see that our goal is to find
and
for our predictor h(x) such that our cost function
is as small as possible. We call on the power of calculus to accomplish this.
Consider the following plot of a cost function for some particular machine learning problem:
Here we can see the cost associated with different values of
and
. We can see the graph has a slight bowl to its shape. The bottom of the bowl represents the lowest cost our predictor can give us based on the given training data. The goal is to “roll down the hill” and find
and
corresponding to this point.
This is where calculus comes in to this machine learning tutorial. For the sake of keeping this explanation manageable, I won’t write out the equations here, but essentially what we do is take the gradient of
, which is the pair of derivatives of
(one over
and one over
). The gradient will be different for every different value of
and
, and defines the “slope of the hill” and, in particular, “which way is down” for these particular
s. For example, when we plug our current values of
into the gradient, it may tell us that adding a little to
and subtracting a little from
will take us in the direction of the cost function-valley floor. Therefore, we add a little to
, subtract a little from
, and voilà! We have completed one round of our learning algorithm. Our updated predictor, h(x) =
+
x, will return better predictions than before. Our machine is now a little bit smarter.
This process of alternating between calculating the current gradient and updating the
s from the results is known as gradient descent.
That covers the basic theory underlying the majority of supervised machine learning systems. But the basic concepts can be applied in a variety of ways, depending on the problem at hand.
Classification Problems in Machine Learning
Under supervised ML, two major subcategories are:
Regression machine learning systems – Systems where the value being predicted falls somewhere on a continuous spectrum. These systems help us with questions of “How much?” or “How many?”
Classification machine learning systems – Systems where we seek a yes-or-no prediction, such as “Is this tumor cancerous?”, “Does this cookie meet our quality standards?”, and so on.
As it turns out, the underlying machine learning theory is more or less the same. The major differences are the design of the predictor h(x) and the design of the cost function
.
Our examples so far have focused on regression problems, so now let’s take a look at a classification example.
Here are the results of a cookie quality testing study, where the training examples have all been labeled as either “good cookie” (y = 1) in blue or “bad cookie” (y = 0) in red.
In classification, a regression predictor is not very useful. What we usually want is a predictor that makes a guess somewhere between 0 and 1. In a cookie quality classifier, a prediction of 1 would represent a very confident guess that the cookie is perfect and utterly mouthwatering. A prediction of 0 represents high confidence that the cookie is an embarrassment to the cookie industry. Values falling within this range represent less confidence, so we might design our system such that a prediction of 0.6 means “Man, that’s a tough call, but I’m gonna go with yes, you can sell that cookie,” while a value exactly in the middle, at 0.5, might represent complete uncertainty. This isn’t always how confidence is distributed in a classifier but it’s a very common design and works for the purposes of our illustration.
It turns out there’s a nice function that captures this behavior well. It’s called the sigmoid function, g(z), and it looks something like this:
z is some representation of our inputs and coefficients, such as:
so that our predictor becomes:
Notice that the sigmoid function transforms our output into the range between 0 and 1.
The logic behind the design of the cost function is also different in classification. Again we ask “What does it mean for a guess to be wrong?” and this time a very good rule of thumb is that if the correct guess was 0 and we guessed 1, then we were completely wrong—and vice-versa. Since you can’t be more wrong than completely wrong, the penalty in this case is enormous. Alternatively, if the correct guess was 0 and we guessed 0, our cost function should not add any cost for each time this happens. If the guess was right, but we weren’t completely confident (e.g., y = 1, but h(x) = 0.8), this should come with a small cost, and if our guess was wrong but we weren’t completely confident (e.g., y = 1 but h(x) = 0.3), this should come with some significant cost but not as much as if we were completely wrong.
This behavior is captured by the log function, such that:
Again, the cost function
gives us the average cost over all of our training examples.
So here we’ve described how the predictor h(x) and the cost function
differ between regression and classification, but gradient descent still works fine.
A classification predictor can be visualized by drawing the boundary line; i.e., the barrier where the prediction changes from a “yes” (a prediction greater than 0.5) to a “no” (a prediction less than 0.5). With a well-designed system, our cookie data can generate a classification boundary that looks like this:
Now that’s a machine that knows a thing or two about cookies!
An Introduction to Neural Networks
No discussion of Machine Learning would be complete without at least mentioning neural networks. Not only do neural networks offer an extremely powerful tool to solve very tough problems, they also offer fascinating hints at the workings of our own brains and intriguing possibilities for one day creating truly intelligent machines.
Neural networks are well suited to machine learning models where the number of inputs is gigantic. The computational cost of handling such a problem is just too overwhelming for the types of systems we’ve discussed. As it turns out, however, neural networks can be effectively tuned using techniques that are strikingly similar to gradient descent in principle.
A thorough discussion of neural networks is beyond the scope of this tutorial, but I recommend checking out previous post on the subject.
Unsupervised Machine Learning
Unsupervised machine learning is typically tasked with finding relationships within data. There are no training examples used in this process. Instead, the system is given a set of data and tasked with finding patterns and correlations therein. A good example is identifying close-knit groups of friends in social network data.
The machine learning algorithms used to do this are very different from those used for supervised learning, and the topic merits its own post. However, for something to chew on in the meantime, take a look at clustering algorithms such as k-means, and also look into dimensionality reduction systems such as principle component analysis. You can also read our article on semi-supervised image classification.
Putting Theory Into Practice
We’ve covered much of the basic theory underlying the field of machine learning but, of course, we have only scratched the surface.
Keep in mind that to really apply the theories contained in this introduction to real-life machine learning examples, a much deeper understanding of these topics is necessary. There are many subtleties and pitfalls in ML and many ways to be lead astray by what appears to be a perfectly well-tuned thinking machine. Almost every part of the basic theory can be played with and altered endlessly, and the results are often fascinating. Many grow into whole new fields of study that are better suited to particular problems.
Clearly, machine learning is an incredibly powerful tool. In the coming years, it promises to help solve some of our most pressing problems, as well as open up whole new worlds of opportunity for data science firms. The demand for machine learning engineers is only going to grow, offering incredible chances to be a part of something big. I hope you will consider getting in on the action!
Acknowledgement
This article draws heavily on material taught by Stanford professor Dr. Andrew Ng in his free and open “Supervised Machine Learning” course. It covers everything discussed in this article in great depth, and gives tons of practical advice to ML practitioners. I cannot recommend it highly enough for those interested in further exploring this fascinating field.
Further Reading on the Toptal Blog:
Machine Learning Video Analysis: Identifying Fish
A Deep Learning Tutorial: From Perceptrons to Deep Networks
Adversarial Machine Learning: How to Attack and Defend ML Models
Machine Learning Number Recognition: From Zero to Application
Getting Started With TensorFlow: A Machine Learning Tutorial