
Course content
- Introduction
- About Sentiment analysis
- Implementation for a chatbot – 1 example
- Implementation for a chatbot – 2 example
- Platforms, NLP & Libraries for Voice Bots & Chatbots
- Conclusion

Advance knowledge at NLP
Understand NLP
Advance knowledge at DL
Understand DL
I am Nitsan Soffair, A Deep RL researcher at BGU.
In this course you will learn NLP with vector spaces.
You will
Syllabus
Vector space model or term vector model is an algebraic model for representing text documents (and any objects, in general) as vectors of identifiers (such as index terms). It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a “reasonable” way (see inductive bias). This statistical quality of an algorithm is measured through the so-called generalization error.
The parallel task in human and animal psychology is often referred to as concept learning.
Resources

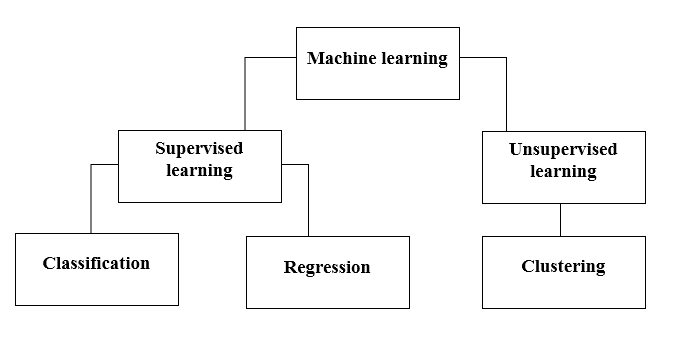
Machine Learning Methods are used to make the system learn using methods like Supervised learning and Unsupervised Learning which are further classified in methods like Classification, Regression and Clustering. This selection of methods entirely depends on the type of dataset that is available to train the model, as the dataset can be labeled, unlabelled, large. There are various applications (like image classification, Predictive analysis, Spam detection) that uses these different machine learning methods.
There are various methods to do that. Which method to follow completely depends on the problem statement. Depending on the dataset, and our problem, there are two different ways to go deeper. One is supervised learning and the other is unsupervised learning. The following chart explains the further classification of machine learning methods. We will discuss them one by one.
Take a look at the following chart!
Let’s understand what does Supervised Learning means.
As the name suggests, imagine a teacher or a supervisor helping you to learn. The same goes for machines. We train or teach the machine using data that is labeled.
Some of the coolest supervised learning applications are:
Now, supervised learning is further divided into classification and regression. Let’s, understand this.
Classification is the process of finding a model that helps to separate the data into different categorical classes. In this process, data is categorized under different labels according to some parameters given in input and then the labels are predicted for the data. Categorical means the output variable is a category, i.e red or black, spam or not spam, diabetic or non-diabetic, etc.
Classification models include Support vector machine(SVM),K-nearest neighbor(KNN),Naive Bayes etc.
a) Support vector machine classifier (SVM)
SVM is a supervised learning method that looks at the data and sorts it into one of two categories. I use a hyperplane to categorize the data. A linear discriminative classifier attempts to draw a straight line separating the two sets of data and thereby create a model for classification. It simply tries to find a line or curve (in two dimensions) or a manifold (in multiple dimensions) that divides the classes from each other.
Note: For multiclass classification SVM makes use of ‘one vs rest’, that means calculating different SVM for each class.
b) K-nearest neighbor classifier (KNN)
c) Naive Bayes classifier
Now let’s move on to the other side of our supervised learning method, which is a regression.
Regression is the process of finding a model that helps to differentiate the data using continuous values. In this, the nature of the predicted data is ordered. Some of the most widely used regression models include Linear regression, Random forest(Decision trees), Neural networks.
Linear regression
Unsupervised Learning applications are:
a) K means Clustering
b) Hierarchical Clustering
Hierarchical clustering is nearly similar to that of normal clustering unless you want to build a hierarchy of clusters. This can come handy when you want to decide the number of clusters. For example, suppose you are creating groups of different items on the online grocery store. On the front home page, you want a few broad items and once you click on one of the items, specific categories, that is more specific clusters opens up.
Dimensionality reduction can be considered as compression of a file. It means, taking out the information which is not relevant. It reduces the complexity of data and tries to keep the meaningful data. For example, in image compression, we reduce the dimensionality of the space in which the image stays as it is without destroying too much of the meaningful content in the image.
Principal component analysis (PCA) is a dimension reduction method that can be useful to visualize your data. PCA is used to compress higher dimensional data to lower-dimensional data, that is, we can use PCA to reduce a four-dimensional data into three or 2 dimensions so that we can visualize and get a better understanding of the data.
Our ability to learn and become better at everyday activities through experience is a basic characteristic of our human nature.
When we are born we don’t really know how to do things, but day by day we learn more and more both on our own and with the help of others.
Something similar happens with machines – or computers in simpler terms – which collect enough data and information to be able to draw conclusions on their own. This is the main meaning of Machine Learning.
In this article we will see:
Machine Learning is a part of Artificial Intelligence, based on the idea that computers/machines can learn from the data they collect in order to recognize patterns and make their own decisions.
All this with little or no human intervention.
In other words, engineering algorithms are “trained” through situations and examples, where they learn and analyze data in order to make predictions about the future.
Interesting, isn’t it?
Although we will see detailed examples later in the article, it is worth mentioning one briefly to make Machine Learning fully understandable.
You may have heard of something called Sentiment Analysis. It’s about identifying the emotional tone behind words.
When we read a text online it is not always easy to know what emotion is behind it, there are tools that have been trained with data to do the job.

But how does this help?
Sentiment Analysis mainly helps companies understand the intent behind a text, a user’s Tweet, and even a video where the machine learns to “read” emotions by analyzing a person’s expressions.
Of course, the more data the machine “reads”, the more chances it has to be more accurate in its decisions.
Although we could go deeper into this part, it is a good example of Machine Learning.
With the exponential increase in the amount of data we have nowadays, there is an urgent need for systems that can process this complex data.
This large and complex data is known as Big Data and is usually managed by Machine Learning models such as Deep Learning.
As mentioned earlier, in Machine Learning, the algorithms are fed with various data to analyse it, draw their conclusions and then keep this data to improve and be able to get more and more accurate results every time.
Almost any task can be automated with the help of machines, which is pushing more and more companies to learn what is Machine Learning and transform their processes to be done automatically, faster and more accurately.
After all, data science has become a part of our daily lives that for most companies its adoption is mandatory.
It is now worth mentioning the 2 main machine learning methods :
The first method is Supervised Learning.
What does it mean?
The machines are trying to draw conclusions based on past data they have collected. This process is similar to the way humans think. We use past experiences and knowledge to make better decisions in the present or even “predict” a future outcome.
A good example of Supervised Machine Learning is the personalized product recommendations that for example, Amazon suggests to each user, based on the products they have bought or simply viewed in the past.
The first method is Unsupervised Learning.
In this method, the algorithms try to identify various unknown patterns in the data without having labeled data.
For example, this method can be applied when we want to estimate the likely market size for a new product where we do not have enough data.
So, the algorithm will work with as much data as it has to group them into clusters and present them visually (K-Means Clustering).

Source: ml-science.com
Now that we’ve seen what Machine Learning is and how it works, let’s look at some examples to make it easier to understand.
As mentioned, in this section we’ll look at real examples of Machine Learning, some of which you’ve probably heard of.
Let’s start with the first one.
Facebook (or Meta) is a good example of a company using machine learning.
In particular, Facebook has applied artificial intelligence to its infrastructure so that various companies can create chatbots that talk to users on their own.
A user can ask a question and the system will answer it automatically, without human intervention.
In the image above you can see a Gatwick Airport chatbot where visitors can ask and get information about their flight, available restaurants, shops and more.
All this has been made possible by the application of machine learning!
Let’s move on to the next example.
Apple undoubtedly needs no introduction, as it is one of the world’s largest technology companies.
What you may not know is that Apple has applied AI and Machine Learning, particularly in 2 cases.
The first case is Siri. Siri is the digital voice assistant that receives data from us in audio form and performs various commands, such as answering questions or even calling someone.
The second case is face recognition. A technology that recognizes a person by “seeing” their face, after collecting various data on facial features and structure.
Thanks to the development of AI, machine learning, and Deep Learning, face recognition technologies are growing rapidly!
Let’s have a look at another example before summarizing.
The reason Netflix is on this list is similar to the reason we mentioned Amazon earlier, as they do a great job of recommending movies/series to users.
Netflix collects data from what each user watches on the platform to draw conclusions about their preferences and suggest relevant things they are likely to be interested in.
This is an excellent example of a Machine Learning application that you have surely experienced yourself if you use the service.
As you can see, we experience the effects of machine learning daily, even if we don’t realize it.
That’s what’s so impressive about data science that so many companies and professionals are rushing to train in it.
Artificial intelligence and machine learning are very closely related and connected. Because of this relationship, when you look into AI vs. machine learning, you’re really looking into their interconnection.
Artificial intelligence is the capability of a computer system to mimic human cognitive functions such as learning and problem-solving. Through AI, a computer system uses math and logic to simulate the reasoning that people use to learn from new information and make decisions.
While AI and machine learning are very closely connected, they’re not the same. Machine learning is considered a subset of AI.
Machine learning is an application of AI. It’s the process of using mathematical models of data to help a computer learn without direct instruction. This enables a computer system to continue learning and improving on its own, based on experience.
An “intelligent” computer uses AI to think like a human and perform tasks on its own. Machine learning is how a computer system develops its intelligence.
One way to train a computer to mimic human reasoning is to use a neural network, which is a series of algorithms that are modeled after the human brain. The neural network helps the computer system achieve AI through deep learning. This close connection is why the idea of AI vs. machine learning is really about the ways that AI and machine learning work together.
When you’re looking into the difference between artificial intelligence and machine learning, it’s helpful to see how they interact through their close connection. This is how AI and machine learning work together:
An AI system is built using machine learning and other techniques.
Machine learning models are created by studying patterns in the data.
Data scientists optimize the machine learning models based on patterns in the data.
The process repeats and is refined until the models’ accuracy is high enough for the tasks that need to be done.
Companies in almost every industry are discovering new opportunities through the connection between AI and machine learning. These are just a few capabilities that have become valuable in helping companies transform their processes and products:
This capability helps companies predict trends and behavioral patterns by discovering cause-and-effect relationships in data.
With recommendation engines, companies use data analysis to recommend products that someone might be interested in.
Speech recognition enables a computer system to identify words in spoken language, and natural language understanding recognizes meaning in written or spoken language.
These capabilities make it possible to recognize faces, objects, and actions in images and videos, and implement functionalities such as visual search.
A computer system uses sentiment analysis to identify and categorize positive, neutral, and negative attitudes that are expressed in text.
The connection between artificial intelligence and machine learning offers powerful benefits for companies in almost every industry—with new possibilities emerging constantly. These are just a few of the top benefits that companies have already seen:
AI and machine learning enable companies to discover valuable insights in a wider range of structured and unstructured data sources.
Companies use machine learning to improve data integrity and use AI to reduce human error—a combination that leads to better decisions based on better data.
With AI and machine learning, companies become more efficient through process automation, which reduces costs and frees up time and resources for other priorities.
Companies in several industries are building applications that take advantage of the connection between artificial intelligence and machine learning. These are just a few ways that AI and machine learning are helping companies transform their processes and products:
Retailers use AI and machine learning to optimize their inventories, build recommendation engines, and enhance the customer experience with visual search.
Health organizations put AI and machine learning to use in applications such as image processing for improved cancer detection and predictive analytics for genomics research.
In financial contexts, AI and machine learning are valuable tools for purposes such as detecting fraud, predicting risk, and providing more proactive financial advice.
Sales and marketing teams use AI and machine learning for personalized offers, campaign optimization, sales forecasting, sentiment analysis, and prediction of customer churn.
AI and machine learning are powerful weapons for cybersecurity, helping organizations protect themselves and their customers by detecting anomalies.
Companies in a wide range of industries use chatbots and cognitive search to answer questions, gauge customer intent, and provide virtual assistance.
AI and machine learning are valuable in transportation applications, where they help companies improve the efficiency of their routes and use predictive analytics for purposes such as traffic forecasting.
Manufacturing companies use AI and machine learning for predictive maintenance and to make their operations more efficient than ever.