What is Machine Learning?
Machine learning is a field of computer science that aims to teach computers how to learn and act without being explicitly programmed. More specifically, machine learning is an approach to data analysis that involves building and adapting models, which allow programs to “learn” through experience. Machine learning involves the construction of algorithms that adapt their models to improve their ability to make predictions.
According to Tom Mitchell, professor of Computer Science and Machine Learning at Carnegie Mellon, a computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. A mathematical way of saying that a program uses machine learning if it improves at problem solving with experience.
The first uses and discussions of machine learning date back to the 1950’s and its adoption has increased dramatically in the last 10 years. Common applications of machine learning include image recognition, natural language processing, design of artificial intelligence, self-driving car technology, and Google’s web search algorithm.
Machine Learning vs Artificial Intelligence
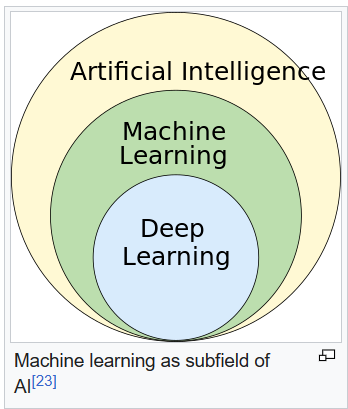
It is worth emphasizing the difference between machine learning and artificial intelligence. Machine learning is an area of study within computer science and an approach to designing algorithms. This approach to algorithm design enables the creation and design of artificially intelligent programs and machines.
Applications and Examples of Machine Learning
Machine learning is an area of study and an approach to problem solving. And there are many different applications to which machine learning methods can be applied. Below are a few of the many applications of machine learning strategies and methods:
Natural Language Processing
Natural language processing (NLP) is a field of computer science that is primarily concerned with the interactions between computers and natural (human) languages. Major emphases of natural language processing include speech recognition, natural language understanding, and natural language generation. Machine learning methods can be applied to each of these areas.
Insurance Claim Analysis
The insurance industry is applying machine learning in several ways. Most interestingly, several companies are using machine learning algorithms to make predictions about future claims which are being used to price insurance premiums. In addition, some companies in the insurance and banking industries are using machine learning to detect fraud.
Bioinformatics and Medical Diagnosis
The amount of biological data being compiled by research scientists is growing at an exponential rate. This has led to problems with efficient data storage and management as well as with the ability to pull useful information from this data. Currently machine learning methods are being developed to efficiently and usefully store biological data, as well as to intelligently pull meaning from the stored data.
Efforts are also being made to apply machine learning and pattern recognition techniques to medical records in order to classify and better understand various diseases. These approaches are also expected to help diagnose disease by identifying segments of the population that are the most at risk for certain disease.
Image Processing and Pattern Recognition
Using computers to identify patterns and identify objects within images, videos, and other media files is far less practical without machine learning techniques. Writing programs to identify objects within an image would not be very practical if specific code needed to be written for every object you wanted to identify.
Instead, image recognition algorithms, also called image classifiers, can be trained to classify images based on their content. These algorithms are trained by processing many sample images that have already been classified. Using the similarities and differences of images they’ve already processed, these programs improve by updating their models every time they process a new image. This form of machine learning used in image processing is usually done using an artificial neural network and is known as deep learning.
Search Engines
Web search also benefits from the use of deep learning by using it to improve search results and better understand user queries. By analyzing user behavior against the query and results served, companies like Google can improve their search results and understand what the best set of results are for a given query. Search suggestions and spelling corrections are also generated by using machine learning tactics on aggregated queries of all users.
Financial Market Analysis
Algorithmic trading and market analysis have become mainstream uses of machine learning and artificial intelligence in the financial markets. Fund managers are now relying on deep learning algorithms to identify changes in trends and even execute trades. Funds and traders who use this automated approach make trades faster than they possibly could if they were taking a manual approach to spotting trends and making trades.
Additional Applications of Machine Learning
Machine learning, because it is merely a scientific approach to problem solving, has almost limitless applications. In addition to the applications above, use of machine learning techniques can also be seen in genetic sciences for classification of DNA sequences, in banking for fraud detection, in online advertising for perfection of ad targeting, and in many other industries to improve efficiency and data processing capabilities.
How Does Machine Learning Work?
Clearly, there are many ways that machine learning is being used today. But how is it being used? What are these programs actually doing to solve problems more effectively? How do these approaches differ from historical methods of solving problems?
As stated above, machine learning is a field of computer science that aims to give computers the ability to learn without being explicitly programmed. The approach or algorithm that a program uses to “learn” will depend on the type of problem or task that the program is designed to complete.
So a good way to understand how machine learning works, is to understand what types of problems machine learning attempts to solve and then look at how it tries to solve those problems. First, a list of the types of problems machine learning aims to solve:
Types of Machine Learning Tasks
Machine learning algorithms all aim to learn and improve their accuracy as they process more datasets. One way that we can classify the tasks that machine learning algorithms solve is by how much feedback they present to the system. In some scenarios, the computer is provided a significant amount of labelled training data is provided, which is called supervised learning. In other cases, no labelled data is provided and this is known as unsupervised learning. Lastly, in semi-supervised learning, some labelled training data is provided, but most of the training data is unlabelled. Let’s review each type in more detail:
Supervised Learning
Supervised learning is the most practical and widely adopted form of machine learning. It involves creating a mathematical function that relates input variables to the preferred output variables. A large amount of labeled training datasets are provided which provide examples of the data that the computer will be processing.
Supervised learning tasks can further be categorized as “classification” or “regression” problems. Classification problems use statistical classification methods to output a categorization, for instance, “hot dog” or “not hot dog”. Regression problems, on the other hand, use statistical regression analysis to provide numerical outputs.
Semi-supervised Learning
Semi-supervised learning is actually the same as supervised learning except that of the training data provided, only a limited amount is labelled.
Image recognition is a good example of semi-supervised learning. In this example, we might provide the system with several labelled images containing objects we wish to identify, then process many more unlabelled images in the training process.
Unsupervised Learning
In unsupervised learning problems, all input is unlabelled and the algorithm must create structure out of the inputs on its own. Clustering problems (or cluster analysis problems) are unsupervised learning tasks that seek to discover groupings within the input datasets. Examples of this could be patterns in stock data or consumer trends. Neural networks are also commonly used to solve unsupervised learning problems.
Machine Learning Algorithms and Approaches to Problem Solving
An algorithm is an approach to solving a problem, and machine learning offers many different approaches to solve a wide variety of problems. Below is a list of some of the most common and useful algorithms and approaches used in machine learning applications today. Keep in mind that applications will often use many of these approaches together to solve a given problem:
Artificial Neural Networks
An artificial neural network is a computational model based on biological neural networks, like the human brain. It uses a series of functions to process an input signal or file and translate it over several stages into the expected output. This method is often used in image recognition, language translation, and other common applications today.
Deep Learning
Deep learning refers to a family of machine learning algorithms that make heavy use of artificial neural networks. In a 2016 Google Tech Talk, Jeff Dean describes deep learning algorithms as using very deep neural networks, where “deep” refers to the number of layers, or iterations between input and output. As computing power is becoming less expensive, the learning algorithms in today’s applications are becoming “deeper.”
Cluster Analysis
A cluster analysis attempts to group objects into “clusters” of items that are more similar to each other than items in other clusters. The way that the items are similar depends on the data inputs that are provided to the computer program. Because cluster analyses are most often used in unsupervised learning problems, no training is provided.
The program will use whatever data points are provided to describe each input object and compare the values to data about objects that it has already analyzed. Once enough objects have been analyze to spot groupings in data points and objects, the program can begin to group objects and identify clusters.
Clustering is not actually one specific algorithm; in fact, there are many different paths to performing a cluster analysis. It is a common task in statistical analysis and data mining.
Bayesian Networks
A Bayesian network is a graphical model of variables and their dependencies on one another. Machine learning algorithms might use a bayesian network to build and describe its belief system. One example where bayesian networks are used is in programs designed to compute the probability of given diseases. Symptoms can be taken as input and the probability of diseases output.
Reinforcement Learning
Reinforcement learning refers to an area of machine learning where the feedback provided to the system comes in the form of rewards and punishments, rather than being told explicitly, “right” or “wrong”. This comes into play when finding the correct answer is important, but finding it in a timely manner is also important.
So a large element of reinforcement learning is finding a balance between “exploration” and “exploitation”. How often should the program “explore” for new information versus taking advantage of the information that it already has available? By “rewarding” the learning agent for behaving in a desirable way, the program can optimize its approach to acheive the best balance between exploration and exploitation.
Decision Tree Learning
Decision tree learning is a machine learning approach that processes inputs using a series of classifications which lead to an output or answer. Typically such decision trees, or classification trees, output a discrete answer; however, using regression trees, the output can take continuous values (usually a real number).
Rule-based Machine Learning
Rule-based machine learning refers to a class of machine learning methods that generates “rules” to analyze models, applies those rules while analyzing models, and adapts the rules to improve performance (learn). This technique is used in artificial immune systems and to create associate rule learning algorithms, which is covered next.
Association Rule Learning
Association rule learning is a method of machine learning focused on identifying relationships between variables in a database. One example of applied association rule learning is the case where marketers use large sets of super market transaction data to determine correlations between different product purchases. For instance, “customers buying pickles and lettuce are also likely to buy sliced cheese.” Correlations or “association rules” like this can be discovered using association rule learning.
Inductive Logic Programming
To understand inductive logic programming, it is important to first understand “logic programming”. Logic programming is a paradigm in computer programming in which programs are written as a set of expressions which state facts or rules, often in “if
this, then that” form. Understanding that “logic programming” revolves around using a set of logical rules, we can begin to understand inductive logic programming.
Inductive logic programming is an area of research that makes use of both machine learning and logic programming. In ILP problems, the background knowledge that the program uses is remembered as a set of logical rules, which the program uses to derive its hypothesis for solving problems.
Applications of inductive logic programming today can be found in natural language processing and bioinformatics.
Support Vector Machines
Support vector machines are a supervised learning tool commonly used in classification and regression problems. An computer program that uses support vector machines may be asked to classify an input into one of two classes. The program will be provided with training examples of each class that can be represented as mathematical models plotted in a multidimensional space (with the number of dimensions being the number of features of the input that the program will assess).
The program plots representations of each class in the multidimensional space and identifies a “hyperplane” or boundary which separates each class. When a new input is analyzed, its output will fall on one side of this hyperplane. The side of the hyperplane where the output lies determines which class the input is. This hyperplane is the support vector machine.
Representation Learning
Representation learning, also called feature learning, is a set of techniques within machine learning that enables the system to automatically create representations of objects that will best allow them to recognize and detect features and then distinguish different objects. So the features are also used to perform analysis after they are identified by the system.
Feature learning is very common in classification problems of images and other media. Because images, videos, and other kinds of signals don’t always have mathematically convenient models, it is usually beneficial to allow the computer program to create its own representation with which to perform the next level of analysis.
Similarity Learning
Similarity learning is a representation learning method and an area of supervised learning that is very closely related to classification and regression. However, the goal of a similarity learning algorithm is to identify how similar or different two or more objects are, rather than merely classifying an object. This has many different applications today, including facial recognition on phones, ranking/recommendation systems, and voice verification.
Sparse Dictionary Learning
Sparse dictionary learning is merely the intersection of dictionary learning and sparse representation, or sparse coding. The computer program aims to build a representation of the input data, which is called a dictionary. By applying sparse representation principles, sparse dictionary learning algorithms attempt to maintain the most succinct possible dictionary that can still completing the task effectively.
Genetic and Evolutionary Algorithms
Although machine learning has been very helpful in studying the human genome and related areas of science, the phrase “genetic algorithms” refers to a class of machine learning algorithms and the approach they take to problem solving, and not the genetics-related applications of machine learning. Genetic algorithms actually draw inspiration from the biological process of natural selection. These algorithms use mathematical equivalents of mutation, selection, and crossover to build many variations of possible solutions.
History of Machine Learning
Machine learning provides humans with an enormous number of benefits today, and the number of uses for machine learning is growing faster than ever. However, it has been a long journey for machine learning to reach the mainstream.
Early History and the Foundation of Research
The term “machine learning” was first coined by artificial intelligence and computer gaming pioneer Arthur Samuel in 1959. However, Samuel actually wrote the first computer learning program while at IBM in 1952. The program was a game of checkers in which the computer improved each time it played, analyzing which moves composed a winning strategy.
In 1957, Frank Rosenblatt created the first artificial computer neural network, also known as a perceptron, which was designed to simulate the thought processes of the human brain.
In 1967, the “nearest neighbor” algorithm was designed which marks the beginning of basic pattern recognition using computers.
These early discoveries were significant, but a lack of useful applications and limited computing power of the era led to a long period of stagnation in machine learning and AI until the 1980s.
Machine Learning Expands Away from AI
Until the 80s and early 90s, machine learning and artificial intelligence had been almost one in the same. But around the early 90s, researchers began to find new, more practical applications for the problem solving techniques they’d created working toward AI.
Looking toward more practical uses of machine learning opened the door to new approaches that were based more in statistics and probability than they were human and biological behavior. Machine learning had now developed into its own field of study, to which many universities, companies, and independent researchers began to contribute.
Modern Day Machine Learning
Today, machine learning is embedded into a significant number of applications and affects millions (if not billions) of people everyday. The massive amount of research toward machine learning resulted in the development of many new approaches being developed, as well as a variety of new use cases for machine learning. In reality, machine learning techniques can be used anywhere a large amount of data needs to be analyzed, which is a common need in business.
Three main reasons have lead to a mass adoption of machine learning in business and research applications: (1) computing power has increased significantly and become much less expensive over the last several decades, (2) information about the powers and use cases of machine learning has spread with the expansion of the internet, and (3) open source machine learning tools have become more widely available.
Companies in biomedical, internet/technology, logistics, and almost every other industry are making use of the awesome power of machine learning. Here are a few examples where machine learning is used today:
Google uses machine learning to better understand its users’ search queries.
Google also uses machine learning to improve its results by measuring engagement with the results it returns.
Medical research organizations are using machine learning to analyze enormous amounts of human health record data in attempts to identify patterns in diseases and conditions and improve healthcare.
Ride-sharing apps like Lyft make use of machine learning to optimize routes and pricing by time of day and location.
Email programs use machine learning techniques to figure out what belongs in the Spam folder.
Banks are using machine learning to spot transactions and behavior that may be suspicious or fraudulent.
These are just a handful of thousands of examples of where machine learning techniques are used today. Machine learning is an exciting and rapidly expanding field of study, and the applications are seemingly endless. As more people and companies learn about the uses of the technology and the tools become increasingly available and easy to use, expect to see machine learning become an even bigger part of every day life.
If you are a developer, or would simply like to learn more about machine learning, take a look at some of the machine learning and artificial intelligence resources available on DeepAI.