In this article
- Why should you choose Machine Learning?
- Essentials of Machine Learning Algorithms
- What to consider before finalizing a Machine Learning algorithm?
- The Principle behind Machine Learning Algorithms
- Types of Machine Learning Algorithms
- Most Used Machine Learning Algorithms – Explained
- How to Choose Machine Learning Algorithms in Real Time
- How to Run Machine Learning Algorithms?
- Where do we stand in Machine Learning?
- Applications of Machine Learning
- Future of Machine Learning
- Conclusion
The advancements in Science and Technology are making every step of our daily life more comfortable. Today, the use of Machine learning systems, which is an integral part of Artificial Intelligence, has spiked and is seen playing a remarkable role in every user’s life.
For instance, the widely popular, Virtual Personal Assistant being used for playing a music track or setting an alarm, face detection or voice recognition applications are awesome examples of the machine learning systems that we see every day. Here is an article on linear discriminant analysis for better understanding.
Machine learning, a subset of artificial intelligence, is the ability of a system to learn or predict the user’s needs and perform an expected task without human intervention. The inputs for the desired predictions are taken from user’s previously performed tasks or from relative examples. These are an example of practical machine learning with Python that makes prediction better.
Why Should You Choose Machine Learning?
Wonder why one should choose Machine Learning? Simply put, machine learning makes complex tasks much easier. It makes the impossible possible!
The following scenarios explain why we should opt for machine learning:

- During facial recognition and speech processing, it would be tedious to write the codes manually to execute the process, that’s where machine learning comes handy.
- For market analysis, figuring customer preferences or fraud detection, machine learning has become essential.
- For the dynamic changes that happen in real-time tasks, it would be a challenging ordeal to solve through human intervention alone.
Essentials of Machine Learning Algorithms
To state simply, machine learning is all about predictions – a machine learning, thinking and predicting what’s next. Here comes the question – what will a machine learn, how will a machine analyze, what will it predict.
You have to understand two terms clearly before trying to get answers to these questions:
- Data
- Algorithm

Data
Data is what that is fed to the machine. For example, if you are trying to design a machine that can predict the weather over the next few days, then you should input the past ‘data’ that comprise maximum and minimum air temperatures, the speed of the wind, amount of rainfall, etc. All these come under ‘data’ that your machine will learn, and then analyse later.
If we observe carefully, there will always be some pattern or the other in the input data we have. For example, the maximum and minimum ranges of temperatures may fall in the same bracket; or speeds of the wind may be slightly similar for a given season, etc. But, machine learning helps analyse such patterns very deeply. And then it predicts the outcomes of the problem we have designed it for.
Algorithm

While data is the ‘food’ to the machine, an algorithm is like its digestive system. An algorithm works on the data. It crushes it; analyses it; permutates it; finds the gaps and fills in the blanks.
Algorithms are the methods used by machines to work on the data input to them. Learners must check if these concepts are being covered in the best data science courses they are enrolled in.
What to Consider Before Finalizing a Machine Learning Algorithm?
Depending on the functionality expected from the machine, algorithms range from very basic to highly complex. You should be wise in making a selection of an algorithm that suits your ML needs. Careful consideration and testing are needed before finalizing an algorithm for a purpose.
For example, linear regression works well for simple ML functions such as speech analysis. In case, accuracy is your first choice, then slightly higher level functionalities such as Neural networks will do.
This concept is called ‘The Explainability- Accuracy Tradeoff’. The following diagram explains this better:

Image Source
Besides, with regards to commonly used machine learning algorithms, you need to remember the following aspects very clearly:No algorithm is an all-in-one solution to any type of problem; an algorithm that fits a scenario is not destined to fit in another one.
- Comparison of algorithms mostly does not make sense as each one of it has its own features and functionality. Many factors such as the size of data, data patterns, accuracy needed, the structure of the dataset, etc. play a major role in comparing two algorithms.
The Principle Behind Machine Learning Algorithms
As we learnt, an algorithm churns the given data and finds a pattern among them. Thus, all machine learning algorithms, especially the ones used for supervised learning, follow one similar principle:
If the input variables or the data is X and you expect the machine to give a prediction or output Y, the machine will work on as per learning a target function ‘f’, whose pattern is not known to us.
Thus, Y= f(X) fits well for every supervised machine learning algorithm. This is otherwise also called Predictive Modeling or Predictive Analysis, which ultimately provides us with the best ever prediction possible with utmost accuracy.
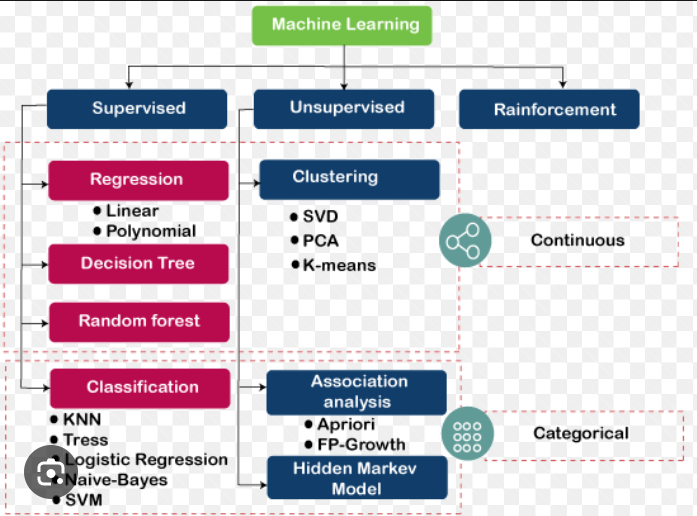
Types of Machine Learning Algorithms
Diving further into machine learning, we will first discuss the types of algorithms it has. Machine learning algorithms can be classified as:
- Supervised, and
- Unsupervised
- Semi-supervised algorithms
- Reinforcement algorithms
A brief description of the types of algorithms is given below:
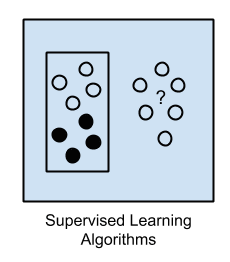
1. Supervised machine learning algorithms
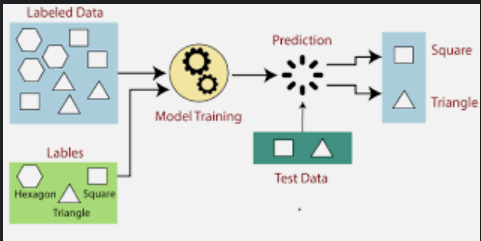
In this method, to get the output for a new set of user’s input, a model is trained to predict the results by using an old set of inputs and its relative known set of outputs. In other words, the system uses the examples used in the past.
A data scientist trains the system on identifying the features and variables it should analyze. After training, these models compare the new results to the old ones and update their data accordingly to improve the prediction pattern.
An example: If there is a basket full of fruits, based on the earlier specifications like color, shape and size given to the system, the model will be able to classify the fruits.
There are 2 techniques in supervised machine learning and a technique to develop a model is chosen based on the type of data it has to work on.
A) Techniques used in Supervised learning
Supervised algorithms use either of the following techniques to develop a model based on the type of data.
- Regression
- Classification
1. Regression Technique
- In a given dataset, this technique is used to predict a numeric value or continuous values (a range of numeric values) based on the relation between variables obtained from the dataset.
- An example would be guessing the price of a house based after a year, based on the current price, total area, locality and number of bedrooms.
- Another example is predicting the room temperature in the coming hours, based on the volume of the room and current temperature.
2. Classification Technique
- This is used if the input data can be categorized based on patterns or labels.
- For example, an email classification like recognizing a spam mail or face detection which uses patterns to predict the output.
In summary, the regression technique is to be used when predictable data is in quantity and Classification technique is to be used when predictable data is about predicting a label.
B) Algorithms that use Supervised Learning
Some of the machine learning algorithms which use supervised learning method are:
- Linear Regression
- Logistic Regression
- Random Forest
- Gradient Boosted Trees
- Support Vector Machines (SVM)
- Neural Networks
- Decision Trees
- Naive Bayes
We shall discuss some of these algorithms in detail as we move ahead in this post.
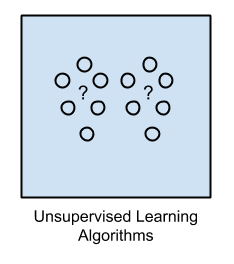
2. Unsupervised machine learning algorithms
This method does not involve training the model based on old data, I.e. there is no “teacher” or “supervisor” to provide the model with previous examples.
The system is not trained by providing any set of inputs and relative outputs. Instead, the model itself will learn and predict the output based on its own observations.
For example, consider a basket of fruits which are not labeled/given any specifications this time. The model will only learn and organize them by comparing Color, Size and shape.
A. Techniques used in unsupervised learning
We are discussing these techniques used in unsupervised learning as under:
- Clustering
- Dimensionality Reduction
- Anomaly detection
- Neural networks
1. Clustering
- It is the method of dividing or grouping the data in the given data set based on similarities.
- Data is explored to make groups or subsets based on meaningful separations.
- Clustering is used to determine the intrinsic grouping among the unlabeled data present.
- An example where clustering principle is being used is in digital image processing where this technique plays its role in dividing the image into distinct regions and identifying image border and the object.
2. Dimensionality reduction
- In a given dataset, there can be multiple conditions based on which data has to be segmented or classified.
- These conditions are the features that the individual data element has and may not be unique.
- If a dataset has too many numbers of such features, it makes it a complex process to segregate the data.
- To solve such type of complex scenarios, dimensional reduction technique can be used, which is a process that aims to reduce the number of variables or features in the given dataset without loss of important data.
- This is done by the process of feature selection or feature extraction.
- Email Classification can be considered as the best example where this technique was used.
3. Anomaly Detection
- Anomaly detection is also known as Outlier detection.
- It is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data.
- Examples of the usage are identifying a structural defect, errors in text and medical problems.
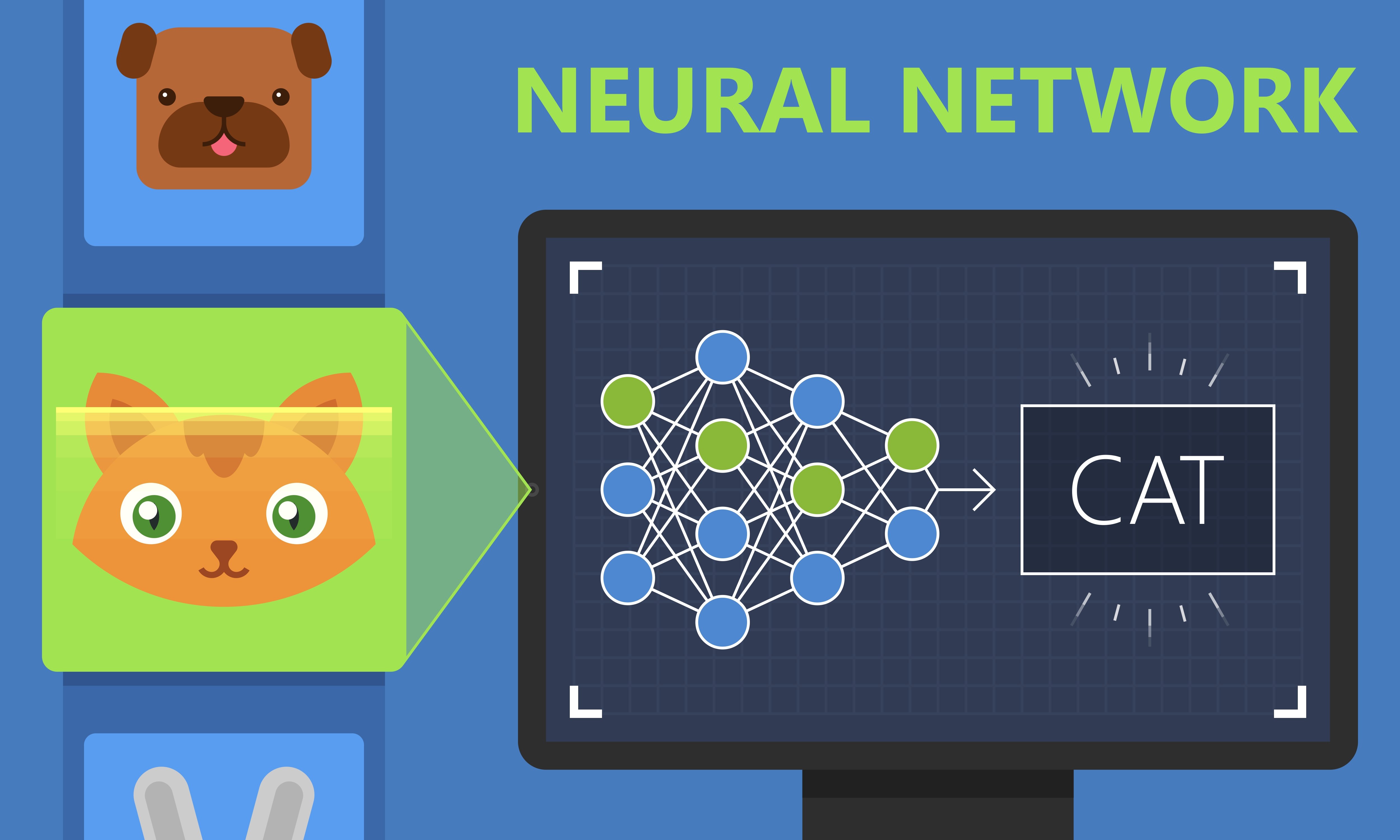
4. Neural Networks
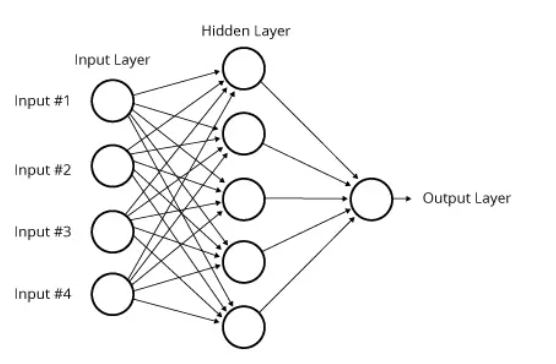
- A Neural network is a framework for many different machine learning algorithms to work together and process complex data inputs.
- It can be thought of as a “complex function” which gives some output when an input is given.
- The Neural Network consists of 3 parts which are needed in the construction of the model.
- Units or Neurons
- Connections or Parameters.
- Biases.
Neural networks are into a wide range of applications such as coastal engineering, hydrology and medicine where they are being used in identifying certain types of cancers.
B. Algorithms that use unsupervised learning
Some of the most common algorithms in unsupervised learning are:
- hierarchical clustering,
- k-means
- mixture models
- DBSCAN
- OPTICS algorithm
- Autoencoders
- Deep Belief Nets
- Hebbian Learning
- Generative Adversarial Networks
- Self-organizing map
We shall discuss some of these algorithms in detail as we move ahead in this post.
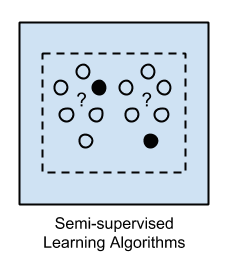
3.Semi Supervised Algorithms
In case of semi-supervised algorithms, as the name goes, it is a mix of both supervised and unsupervised algorithms. Here both labelled and unlabelled examples exist, and in many scenarios of semi-supervised learning, the count of unlabelled examples is more than that of labelled ones.
Classification and regression form typical examples for semi-supervised algorithms.
The algorithms under semi-supervised learning are mostly extensions of other methods, and the machines that are trained in the semi-supervised method make assumptions when dealing with unlabelled data.
Examples of Semi Supervised Learning:
Google Photos are the best example of this model of learning. You must have observed that at first, you define the user name in the picture and teach the features of the user by choosing a few photos. Then the algorithm sorts the rest of the pictures accordingly and asks you in case it gets any doubts during classification.
Comparing with the previous supervised and unsupervised types of learning models, we can make the following inferences for semi-supervised learning:
- Labels are entirely present in case of supervised learning, while for unsupervised learning they are totally absent. Semi-supervised is thus a hybrid mix of both these two.
- The semi-supervised model fits well in cases where cost constraints are present for machine learning modelling. One can label the data as per cost requirements and leave the rest of the data to the machine to take up.
- Another advantage of semi-supervised learning methods is that they have the potential to exploit the unlabelled data of a group in cases where data carries important unexploited information.
4. Reinforcement Learning
In this type of learning, the machine learns from the feedback it has received. It constantly learns and upgrades its existing skills by taking the feedback from the environment it is in.
Markov’s Decision process is the best example of reinforcement learning.
In this mode of learning, the machine learns iteratively the correct output. Based on the reward obtained from each iteration,the machine knows what is right and what is wrong. This iteration keeps going till the full range of probable outputs are covered.
Process of Reinforcement Learning
The steps involved in reinforcement learning are as shown below:
- Input state is taken by the agent
- A predefined function indicates the action to be performed
- Based on the action, the reward is obtained by the machine
- The resulting pair of feedback and action is stored for future purposes
Examples of Reinforcement Learning Algorithms
- Computer based games such as chess
- Artificial hands that are based on robotics
- Driverless cars/ self-driven cars
Most Used Machine Learning Algorithms – Explained
In this section, let us discuss the following most widely used machine learning algorithms in detail:
- Decision Trees
- Naive Bayes Classification
- The Autoencoder
- Self-organizing map
- Hierarchical clustering
- OPTICS algorithm
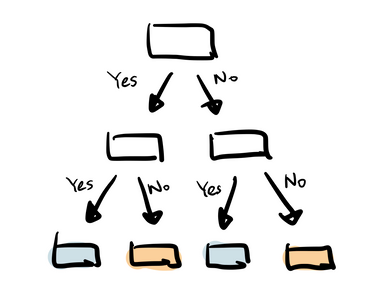
1. Decision Trees
- This algorithm is an example of supervised learning.
- A Decision tree is a pictorial representation or a graphical representation which depicts every possible outcome of a decision.
- The various elements involved here are node, branch and leaf where ‘node’ represents an ‘attribute’, ‘branch’ representing a ‘decision’ and ‘leaf’ representing an ‘outcome’ of the feature after applying that particular decision.
- A decision tree is just an analogy of how a human thinks to take a decision with yes/no questions.
- The below decision tree explains a school admission procedure rule, where Age is primarily checked, and if age is < 5, admission is not given to them. And for the kids who are eligible for admission, a check is performed on Annual income of parents where if it is < 3 L p.a. the students are further eligible to get a concession on the fees.

2. Naive Bayes Classification
- This supervised machine learning algorithm is a powerful and fast classifying algorithm, using the Bayes rule in determining the conditional probability and to predict the results.
- Its popular uses are, face recognition, filtering spam emails, predicting the user inputs in chat by checking communicated text and to label news articles as sports, politics etc.
- Bayes Rule: The Bayes theorem defines a rule in determining the probability of occurrence of an “Event” when information about “Tests” is provided.

- “Event” can be considered as the patient having a Heart disease while “tests” are the positive conditions that match with the event
3. The Autoencoder
- It comes under the category of unsupervised learning using neural networking techniques.
- An autoencoder is intended to learn or encode a representation for a given data set.
- This also involves the process of dimensional reduction which trains the network to remove the “noise” signal.
- In hand, with the reduction, it also works in reconstruction where the model tries to rebuild or generate a representation from the reduced encoding which is equivalent to the original input.
- I.e. without the loss of important and needed information from the given input, an Autoencoder removes or ignores the unnecessary noise and also works on rebuilding the output.

Pic source
- The most common use of Autoencoder is an application that converts black and white image to color. Based on the content and object in the image (like grass, water, sky, face, dress) coloring is processed.
4. Self-organizing map
- This comes under the unsupervised learning method.
- Self-Organizing Map uses the data visualization technique by operating on a given high dimensional data.
- The Self-Organizing Map is a two-dimensional array of neurons: M = {m1,m2,……mn}
- It reduces the dimensions of the data to a map, representing the clustering concept by grouping similar data together.
- SOM reduces data dimensions and displays similarities among data.
- SOM uses clustering technique on data without knowing the class memberships of the input data where several units compete for the current object.
- In short, SOM converts complex, nonlinear statistical relationships between high-dimensional data into simple geometric relationships on a low-dimensional display.
5. Hierarchical clustering
- Hierarchical clustering uses one of the below clustering techniques to determine a hierarchy of clusters.
- Thus produced hierarchy resembles a tree structure which is called a “Dendrogram”.
- The techniques used in hierarchical clustering are:
- K-Means,
- DBSCAN,
- Gaussian Mixture Models.
- The 2 methods in finding hierarchical clusters are:
- Agglomerative clustering
- Divisive clustering
- Agglomerative clustering
- This is a bottom-up approach, where each data point starts in its own cluster.
- These clusters are then joined greedily, by taking the two most similar clusters together and merging them.
- Divisive clustering
- Inverse to Agglomerative, this uses a top-down approach, wherein all data points start in the same cluster after which a parametric clustering algorithm like K-Means is used to divide the cluster into two clusters.
- Each cluster is further divided into two clusters until a desired number of clusters are hit.
6. OPTICS algorithm
- OPTICS is an abbreviation for ordering points to identify the clustering structure.
- OPTICS works in principle like an extended DB Scan algorithm for an infinite number for a distance parameter which is smaller than a generating distance.
- From a wide range of parameter settings, OPTICS outputs a linear list of all objects under analysis in clusters based on their density.
How to Choose Machine Learning Algorithms in Real Time
When implementing algorithms in real time, you need to keep in mind three main aspects: Space, Time, and Output.
Besides, you should clearly understand the aim of your algorithm:
- Do you want to make predictions for the future?
- Are you just categorizing the given data?
- Is your targeted task simple or comprises of multiple sub-tasks?
The following table will show you certain real-time scenarios and help you to understand which algorithm is best suited to each scenario:
| Real time scenario | Best suited algorithm | Why this algorithm is the best fit? |
|---|---|---|
| Simple straightforward data set with no complex computations | Linear Regression | It takes into account all factors involved and predicts the result with simple error rate explanation.For simple computations, you need not spend much computational power; and linear regression runs with minimal computational power. |
| Classifying already labeled data into sub-labels | Logistic Regression | This algorithm looks at every data point into two subcategories, hence best for sub-labeling.Logistic regression model works best when you have multiple targets. |
| Sorting unlabelled data into groups | K-Means clustering algorithm | This algorithm groups and clusters data by measuring the spatial distance between each point.You can choose from its sub-types – Mean-Shift algorithm and Density-Based Spatial Clustering of Applications with Noise |
| Supervised text classification (analyzing reviews, comments, etc.) | Naive Bayes | Simplest model that can perform powerful pre-processing and cleaning of textRemoves filler stop words effectivelyComputationally in-expensive |
| Logistic regression | Sorts words one by one and assigns a probabilityRanks next to Naïve Bayes in simplicity | |
| Linear Support Vector Machine algorithm | Can be chosen when performance matters | |
| Bag-of-words model | Suits best when vocabulary and the measure of known words is known. | |
| Image classification | Convolutional neural network | Best suited for complex computations such as analyzing visual cortexesConsumes more computational power and gives the best results |
| Stock market predictions | Recurrent neural network | Best suited for time-series analysis with well-defined and supervised data.Works efficiently in taking into account the relation between data and its time distribution. |
How to Run Machine Learning Algorithms?
Till now you have learned in detail about various algorithms of machine learning, their features, selection and application in real time.
When implementing the algorithm in real time, you can do it in any programming language that works well for machine learning.
All that you need to do is use the standard libraries of the programming language that you have chosen and work on them, or program everything from scratch.
Need more help? You can check these links for more clarity on coding machine learning algorithms in various programming languages.
How To Get Started With Machine Learning Algorithms in R
How to Run Your First Classifier in Weka
Machine Learning Algorithm Recipes in scikit-learn
Where do We Stand in Machine Learning?
Machine learning is slowly making strides into as many fields in our daily life as possible. Some businesses are making it strict to have transparent algorithms that do not affect their business privacy or data security. They are even framing regulations and performing audit trails to check if there is any discrepancy in the above-said data policies.
The point to note here is that a machine working on machine learning principles and algorithms give output after processing the data through many nonlinear computations. If one needs to understand how a machine predicts, perhaps it can be possible only through another machine learning algorithm!
Applications of Machine Learning

Currently, the role of Machine learning and Artificial Intelligence in human life is intertwined. With the advent of evolving technologies, AI and ML have marked their existence in all possible aspects.
Machine learning finds a plethora of applications in several domains of our day to day life. An exhaustive list of fields where machine learning is currently in use now is shown in the diagram here. An explanation for the same follows further below:
- Financial Services: Banks and financial services are increasingly relying on machine learning to identify financial fraud, portfolio management, identify and suggest good options for investment for customers.
- Police Department: Apps based on facial recognition and other techniques of machine learning are being used by the police to identify and get hold of criminals.
- Online Marketing and Sales: Machine learning is helping companies a great deal in studying the shopping and spending patterns of customers and in making personalized product recommendations to them. Machine learning also eases customer support, product recommendations and advertising ideas for e-commerce.
- Healthcare: Doctors are using machine learning to predict and analyze the health status and disease progress of patients. Machine learning has proven its accuracy in detecting health condition, heartbeat, blood pressure and in identifying certain types of cancer. Advanced techniques of machine learning are being implemented in robotic surgery too.
- Household Applications: Household appliances that use face detection and voice recognition are gaining popularity as security devices and personal virtual assistants at homes.
- Oil and Gas: In analyzing underground minerals and carrying out the exploration and mining, geologists and scientists are using machine learning for improved accuracy and reduced investments.
- Transport: Machine learning can be used to identify the vehicles that are moving in prohibited zones for traffic control and safety monitoring purposes.
- Social Media: In social media, spam is a big nuisance. Companies are using machine learning to filter spam. Machine learning also aptly solves the purpose of sentiment analysis in social media.
- Trading and Commerce: Machine learning techniques are being implemented in online trading to automate the process of trading. Machines learn from the past performances of trading and use this knowledge to make decisions about future trading options.
Future of Machine Learning
Machine learning is already making a difference in the way businesses are offering their services to us, the customers. Voice-based search and preferences based ads are just basic functionalities of how machine learning is changing the face of businesses.
ML has already made an inseparable mark in our lives. With more advancement in various fields, ML will be an integral part of all AI systems. ML algorithms are going to be made continuously learning with the day-to-day updating information.
With the rapid rate at which ongoing research is happening in this field, there will be more powerful machine learning algorithms to make the way we live even more sophisticated!
From 2013- 2017, the patents in the field of machine learning has recorded a growth of 34%, according to IFI Claims Patent Services (Patent Analytics). Also, 60% of the companies in the world are using machine learning for various purposes.
A peek into the future trends and growth of machine learning through the reports of Predictive Analytics and Machine Learning (PAML) market shows a 21% CAGR by 2021.
Conclusion

Ultimately, machine learning should be designed as an aid that would support mankind. The notion that automation and machine learning are threats to jobs and human workforce is pretty prevalent. It should always be remembered that machine learning is just a technology that has evolved to ease the life of humans by reducing the needed manpower and to offer increased efficiency at lower costs that too in a shorter time span. The onus of using machine learning in a responsible manner lies in the hands of those who work on/with it.
However, stay tuned to an era of artificial intelligence and machine learning that makes the impossible possible and makes you witness the unseen! Want to execute what you have learned in this blog, enroll in KnowledgeHut practical machine learning with Python and work with data science projects that deal with complex machine learning algorithms.


















.jpg)
.jpg)
.jpg)
.jpg)
.jpg)