Like humans, machines are capable of learning in different ways. When it comes to machine learning, the most common learning strategies are supervised learning, unsupervised learning, and reinforcement learning. This post will focus on unsupervised learning and supervised learning algorithms, and provide typical examples of each.
What Is Supervised Learning In Machine Learning?
As the name indicates, supervised learning involves machine learning algorithms that learn under the presence of a supervisor.
Learning under supervision directly translates to being under guidance and learning from an entity that is in charge of providing feedback through this process. When training a machine, supervised learning refers to a category of methods in which we teach or train a machine learning algorithm using data, while guiding the algorithm model with labels associated with the data. However, it is essential for data scientists and machine learning engineers to understand algorithm models and which ones should be applied in particular circumstances.
As humans, we consume a lot of information, but often don’t notice these data points. When we see a photo of an animal, for example, we instantly know what the animal is based on our prior experience. But what happens when the learner doesn’t instantly recognize the animal?
When the learner makes a guess and predicts what the animal might be, we have the opportunity to objectively evaluate if the learner has given a correct answer or not. This is possible because we have the correct labels of input.
From now on, we’ll be referring to the machine learning algorithm as “the model.” Now, if the model gave a correct answer, then there is nothing for us to do. Our job is to correct the model when the output of the model is wrong. If this is the case, we need to make sure that the model makes necessary updates so that the next time a cat image is shown to the model, it can correctly identify the image.
The formal supervised learning process involves input variables, which we call (X), and an output variable, which we call (Y). We use an algorithm to learn the mapping function from the input to the output. In simple mathematics, the output (Y) is a dependent variable of input (X) as illustrated by:
Y = f(X)
Here, our end goal is to try to approximate the mapping function (f), so that we can predict the output variables (Y) when we have new input data (X).
Examples of Supervised Learning
Now that we’ve covered supervised learning, it is time to look at classic examples of supervised learning algorithms.
In supervised learning, our goal is to learn the mapping function (f), which refers to being able to understand how the input (X) should be matched with output (Y) using available data.
Here, the machine learning model learns to fit mapping between examples of input features with their associated labels. When models are trained with these examples, we can use them to make new predictions on unseen data.
The predicted labels can be both numbers or categories. For instance, if we are predicting house prices, then the output is a number. In this case, the model is a regression model. If we are predicting if an email is spam or not, the output is a category and the model is a classification model.
Example: House prices
One practical example of supervised learning problems is predicting house prices. How is this achieved?
First, we need data about the houses: square footage, number of rooms, features, whether a house has a garden or not, and so on. We then need to know the prices of these houses, i.e. the corresponding labels. By leveraging data coming from thousands of houses, their features and prices, we can now train a supervised machine learning model to predict a new house’s price based on the examples observed by the model.
Example: Is it a cat or a dog?
Image classification is a popular problem in the computer vision field. Here, the goal is to predict what class an image belongs to. In this set of problems, we are interested in finding the class label of an image. More precisely: is the image of a car or a plane? A cat or a dog?
Example: How’s the weather today?
One particularly interesting problem which requires considering a lot of different parameters is predicting weather conditions in a particular location. To make correct predictions for the weather, we need to take into account various parameters, including historical temperature data, precipitation, wind, humidity, and so on.
This particularly interesting and challenging problem may require developing complex supervised models that include multiple tasks. Predicting today’s temperature is a regression problem, where the output labels are continuous variables. By contrast, predicting whether it is going to snow or not tomorrow is a binary classification problem.
Want to learn more? Check out our post on How an ML Algorithm Helped Make Hurricane Damage Assessments Safer, Cheaper, and More Effective.
Example: Who are the unhappy customers?
Another great example of supervised learning is text classification problems. In this set of problems, the goal is to predict the class label of a given piece of text.
One particularly popular topic in text classification is to predict the sentiment of a piece of text, like a tweet or a product review. This is widely used in the e-commerce industry to help companies to determine negative comments made by customers.
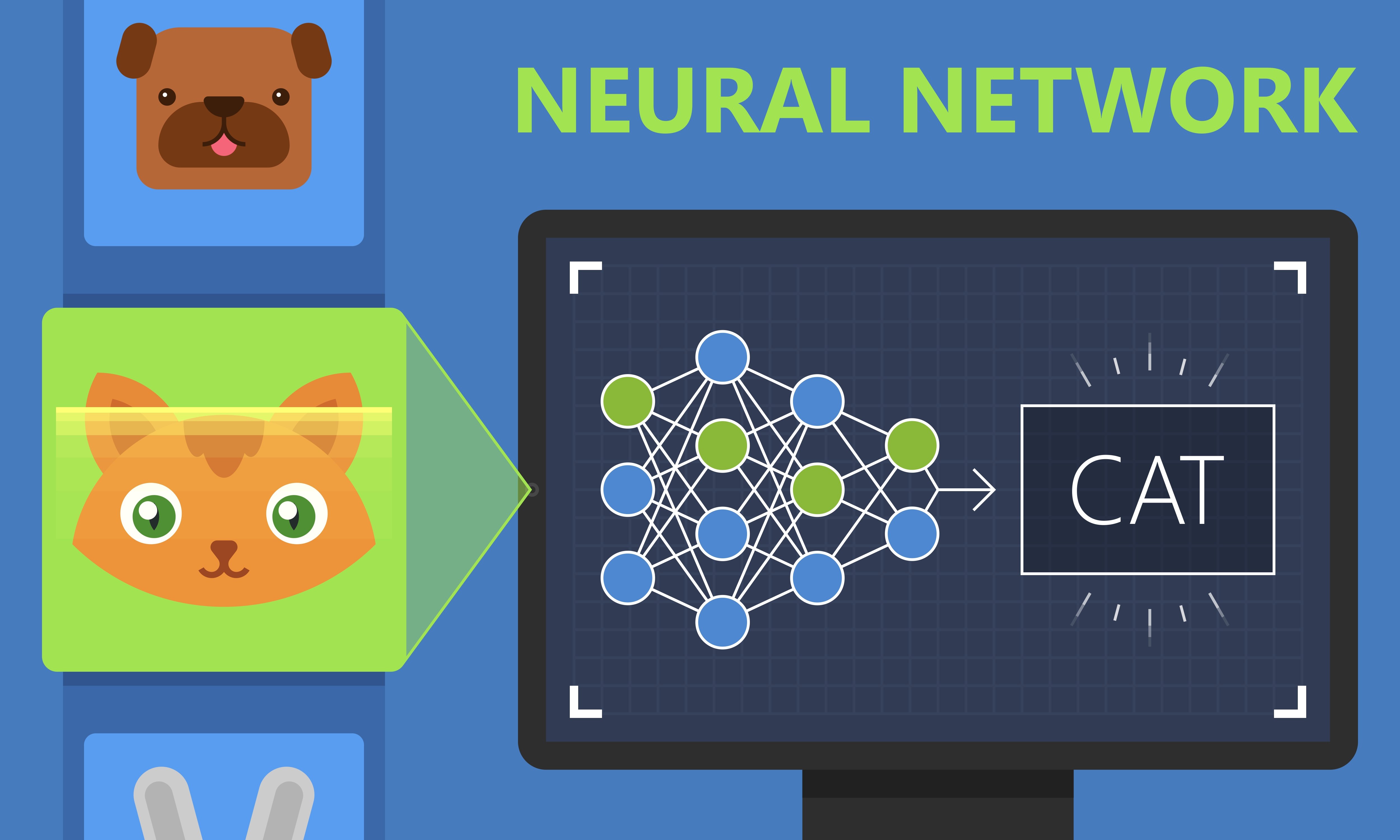
What Is Unsupervised Learning?
In supervised learning, the main idea is to learn under supervision, where the supervision signal is named as target value or label. In unsupervised learning, we lack this kind of signal. Therefore, we need to find our way without any supervision or guidance. This simply means that we are alone and need to figure out what is what by ourselves.
However, we are not totally in the dark. We do this kind of learning every day. In unsupervised learning, even though we do not have any labels for data points, we do have the actual data points. This means we can draw references from observations in the input data.
Imagine you are in a foreign country and you are visiting a food market, for example. You see a stall selling a fruit that you cannot identify. You don’t know the name of this fruit. However, you have your observations to rely on, and you can use these as a reference. In this case, you can easily the fruit apart from nearby vegetables or other food by identifying its various features like its shape, color, or size.
This is roughly how unsupervised learning happens. We use the data points as references to find meaningful structure and patterns in the observations. Unsupervised learning is commonly used for finding meaningful patterns and groupings inherent in data, extracting generative features, and exploratory purposes.
Examples of Unsupervised Learning
There are a few different types of unsupervised learning. We’ll review three common approaches below.
Example: Finding customer segments
Clustering is an unsupervised technique where the goal is to find natural groups or clusters in a feature space and interpret the input data. There are many different clustering algorithms in the field of data science. One common approach is to divide the data points in a way that each data point falls into a group that is similar to other data points in the same group based on a predefined similarity or distance metric in the feature space.
Clustering is commonly used for determining customer segments in marketing data. Being able to determine different segments of customers helps marketing teams approach these customer segments in unique ways. (Think of features like gender, location, age, education, income bracket, and so on.)

Example: Reducing the complexity of a problem
Dimensionality reduction is a commonly used unsupervised learning technique where the goal is to reduce the number of random variables under consideration. It has several practical applications. One of the most common uses of dimensionality reduction is to reduce the complexity of a problem by projecting the feature space to a lower-dimensional space so that less correlated variables are considered in a machine learning system.
The most common approaches used in dimensionality reduction are PCA, t-SNE, and UMAP algorithms. They are especially useful for reducing the complexity of a problem and also visualizing the data instances in a better way. Before going into more detail about feature projection, let’s look at another important concept in machine learning: feature selection.
Example: Feature selection
Even though feature selection and dimensionality reduction aim toward reducing the number of features in the original set of features, understanding how feature selection works helps us get a better understanding of dimensionality reduction.
Assume that we want to predict how capable an applicant is of repaying a loan from the perspective of a bank. Here, we need to help the bank set up a machine learning system so that each loan can be given to applicants who can repay the loan. We need a lot of information about each application to make predictions. A few important attributes about applicants are the applicant’s average monthly income, debt, credit history, and so on.
Typically, however, banks collect much more information from applicants when taking their applications. Not all of it is relevant for predicting an applicant’s credit risk score. For instance, does an applicant’s age make any difference when deciding whether the applicant can repay the loan? Is the applicant’s gender important for determining the credit risk score? Probably not.
It is important to understand that not every feature adds value to solving the problem. Therefore, eliminating these features is an essential part of machine learning. In feature selection, we try to eliminate a subset of the original set of features.
In dimensionality reduction, we still discard features but do that in a way that the feature space is projected onto a smaller feature space, therefore eliminating less important information during this process.