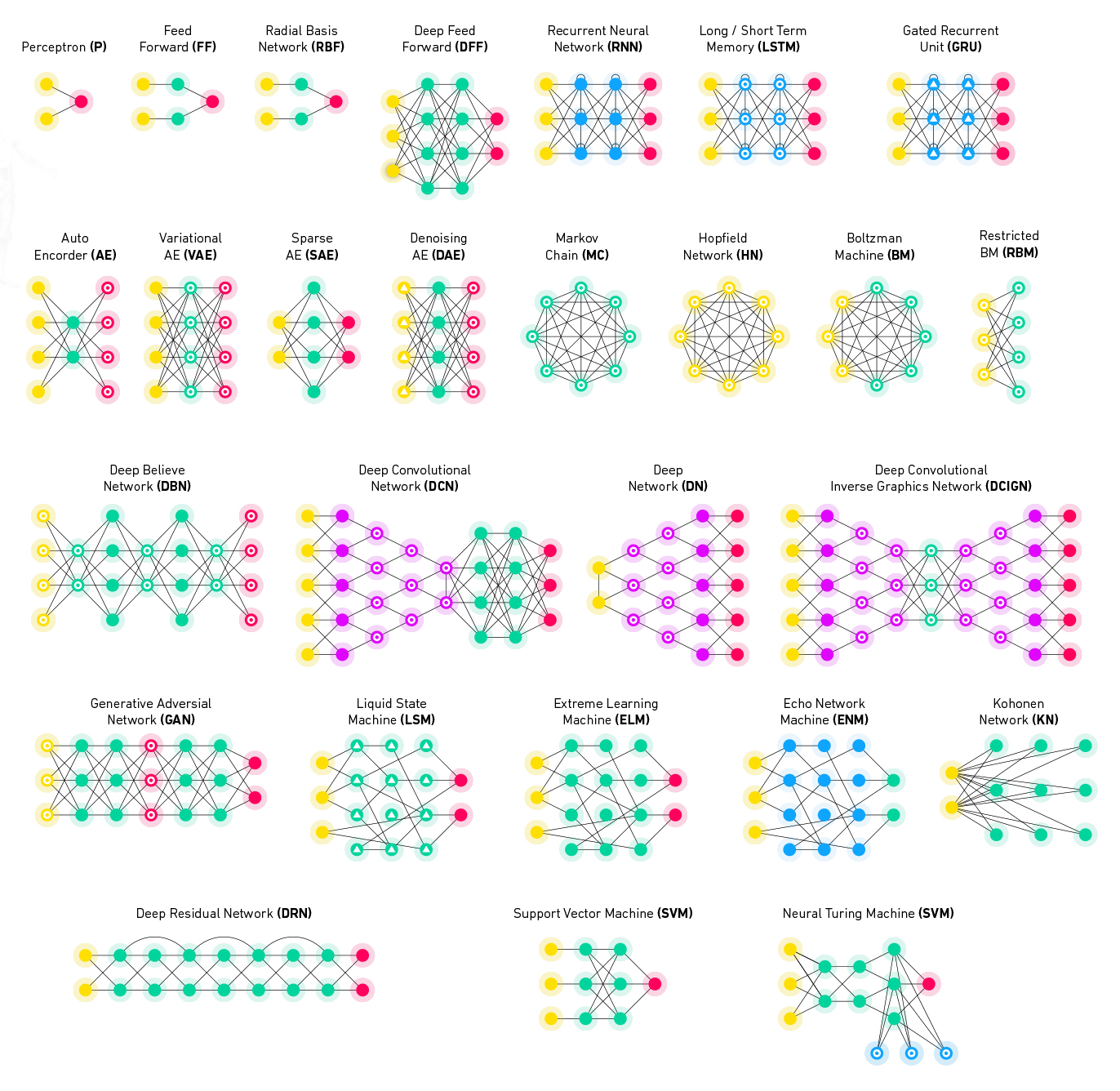
What Is a model?
The output from model training may be used for inference, which means making predictions on new data. A model is a distilled representation of what a machine learning system has learned. Machine learning models are akin to mathematical functions — they take a request in the form of input data, make a prediction on that input data, and then serve a response.
In supervised and unsupervised machine learning, the model describes the signal in the noise or the pattern detected from the training data.
In reinforcement learning, the model describes the best possible course of action given a specific situation.
The final set of trainable parameters (the information the model contains) depends on the specific type of model — in deep neural networks, a model is the final state of the trained weights of the network, in regression it contains coefficients, and in decision trees it contains the split locations.
Algorithms
Neural Networks
There are many different types of models such as GANs, LSTMs & RNNs, CNNs, Autoencoders, and Deep Reinforcement Learning models. Deep neural networks are used for object detection, speech recognition and synthesis , image processing, style transfer , and machine translation, and can replace most classical machine learning algorithms (see below) . This modern method can learn extremely complex patterns and is especially successful on unstructured datasets such as images, video, and audio.
Ensemble Methods
Ensemble techniques like Random Forests and Gradient Boosting can achieve superior performance over classical machine learning techniques by aggregating weaker models and learning non-linear relationships.
Classical Machine Learning
Popular ML algorithms include: linear regression, logistic regression, SVMs, nearest neighbor, decision trees, PCA, naive Bayes classifier, and k-means clustering. Classical machine learning algorithms are used for a wide range of applications.
Types of Supervised Learning Models
Classification
Deep neural networks, classification trees (ensembles), and logistic regression (classical machine learning) are all used to perform regression tasks.
Popular use cases: Spam filtering , language detection , a search of similar documents , sentiment analysis , recognition of handwritten characters, and fraud detection.
Binary Classification Goal: Predict a binary outcome.
Examples
- “Is this email spam or not spam?”
- “Is this user fraudulent or not?”
- “Is this picture a cat or not?”
Multi-class Classification Goal: Predict one out of two or more discrete outcomes.
Examples
- “Which genre does this user prefer?”
- “Is this mail is spam or important or a promotion?”
- “Is this picture a cat or a dog or a fox?”
Regression
Deep neural networks, regression trees (ensembles), and linear regression (classical machine learning) are all used to perform regression tasks.
Popular use cases: Forecasting stock prices, predicting sales volume, etc .
Goal: Predict a numeric value.
Examples
- “What will the temperature be in NYC tomorrow?”
- “What is the price of house in this specific neighborhood?”
Types of Unsupervised Learning models
Neural Networks
Deep neural network architectures such as autoencoders and GANs can be applied to a wide variety of unsupervised learning problems.
Clustering (Classical ML)
Popular use cases: For customer segmentation , labeling data , detecting anomalous behavior, etc .
Popular algorithms: K-means, Mean-Shift, DBSCAN
Goal: Group similar things together.
Examples
- “Cluster different news articles into different types of news”
Association Rule (Classical ML)
Popular use cases: Helping stores cross-sell products , uncovering how items are related or complementary, and understanding which symptoms are likely to co-occur in a patient (comorbidity).
Popular algorithms: Apriori, Euclat, FP-growth
Goal: Infer patterns (associations) in data.
Examples
- “If you bought a phone, you are likely to buy a phone case.”
Dimensionality Reduction (Classical ML)
Popular use-cases: Recommender systems, topic modeling, modeling semantics, document search, face recognition, and anomaly detection.
Popular algorithms: Principal Component Analysis (PCA), Singular Value Decomposition (SVD), Latent Dirichlet Allocation (LDA), Latent Semantic Analysis (LSA, pLSA, GLSA), and t-SNE.
Goal: To generalize data and distill the relevant information.
Examples
- “Intelligently group and combine similar features into higher-level abstractions.”
Types of Reinforcement Learning Models
Popular use-cases: Robotic motion, recommender systems, autonomous transport, text mining, trade execution in finance, and optimization for treatment policies in healthcare.
Popular algorithms: Q-Learning, SARSA, DQN, A3C
Goal: Perform complex tasks without training data.
Examples
- “Robotic motion control learned by trial and error.”
Imitation Learning is an exciting area in Reinforcement Learning, designed to overcome some of the challenges or shortcomings inherent in Reinforcement Learning techniques. These techniques are often used together.