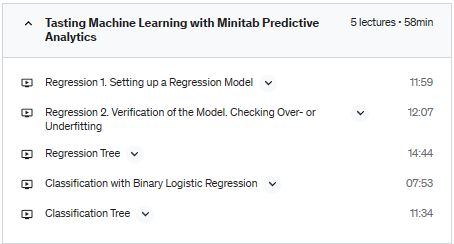
Understand the concept of regression analysis and its applications in predictive modeling.
Understand the concepts of overfitting and underfitting.
Learn how to build a regression tree using Minitab.
Learn how to set up a binary logistic regression model using Minitab.
Practice building a classification tree and using it for prediction using Minitab.
Requirements
No prior programming knowledge is required. The tutorials are based on Minitab software version 21. If you want to try it yourself on the data files provided, you will need this software. The 30-day trial is free. The course assumes basic statistical knowledge.
Description
In this mini-course, “Tasting Machine Learning with Minitab Predictive Analytics”, you will gain an introduction to the world of predictive analytics and machine learning using Minitab statistical software.
Through five lectures, you will learn about regression analysis and classification, two fundamental techniques in predictive modeling. In the first two lectures, you will learn how to set up and verify regression models, as well as how to identify and address potential issues with overfitting or underfitting. In Lecture 3, you will explore regression trees, which are a powerful alternative to linear regression when the relationship between variables is non-linear.
In Lecture 4, you will delve into binary logistic regression, which is a technique used for predicting binary outcomes (such as “yes” or “no” responses). You will learn how to set up and evaluate a binary logistic regression model. Finally, in Lecture 5, you will discover classification trees, which are a type of decision tree used to classify objects or cases into different categories. You will learn how to build and interpret classification trees, and use them for prediction.
By the end of this mini-course, you will have gained practical experience in building and evaluating regression and classification models using Minitab, and an understanding of how these techniques can be applied in various real-world scenarios. Whether you are new to machine learning or looking to expand your knowledge, this mini-course is an excellent opportunity to explore the basics of predictive analytics with Minitab.
Who this course is for:
This course is for those who want a concise taste of the 4 basic methods of machine learning before embarking on a more detailed course.
You might hear people use artificial intelligence (AI) and machine learning (ML) interchangeably, especially when discussing big data, predictive analytics, and other digital transformation topics. The confusion is understandable as artificial intelligence and machine learning are closely related. However, these trending technologies differ in several ways, including scope, applications, and more.
Increasingly AI and ML products have proliferated as businesses use them to process and analyze immense volumes of data, drive better decision-making, generate recommendations and insights in real time, and create accurate forecasts and predictions.
So, what exactly is the difference when it comes to ML vs. AI, how are ML and AI connected, and what do these terms mean in practice for organizations today?
We’ll break down AI vs. ML and explore how these two innovative concepts are related and what makes them different from each other.Get started for free
What is artificial intelligence?
Artificial intelligence is a broad field, which refers to the use of technologies to build machines and computers that have the ability to mimic cognitive functions associated with human intelligence, such as being able to see, understand, and respond to spoken or written language, analyze data, make recommendations, and more.
Although artificial intelligence is often thought of as a system in itself, it is a set of technologies implemented in a system to enable it to reason, learn, and act to solve a complex problem.
What is machine learning?
Machine learning is a subset of artificial intelligence that automatically enables a machine or system to learn and improve from experience. Instead of explicit programming, machine learning uses algorithms to analyze large amounts of data, learn from the insights, and then make informed decisions.
Machine learning algorithms improve performance over time as they are trained—exposed to more data. Machine learning models are the output, or what the program learns from running an algorithm on training data. The more data used, the better the model will get.
How are AI and ML connected?
While AI and ML are not quite the same thing, they are closely connected. The simplest way to understand how AI and ML relate to each other is:
AI is the broader concept of enabling a machine or system to sense, reason, act, or adapt like a human
ML is an application of AI that allows machines to extract knowledge from data and learn from it autonomously
One helpful way to remember the difference between machine learning and artificial intelligence is to imagine them as umbrella categories. Artificial intelligence is the overarching term that covers a wide variety of specific approaches and algorithms. Machine learning sits under that umbrella, but so do other major subfields, such as deep learning, robotics, expert systems, and natural language processing.
Differences between AI and ML
Now that you understand how they are connected, what is the main difference between AI and ML?
While artificial intelligence encompasses the idea of a machine that can mimic human intelligence, machine learning does not. Machine learning aims to teach a machine how to perform a specific task and provide accurate results by identifying patterns.
Let’s say you ask your Google Nest device, “How long is my commute today?” In this case, you ask a machine a question and receive an answer about the estimated time it will take you to drive to your office. Here, the overall goal is for the device to perform a task successfully—a task that you would generally have to do yourself in a real-world environment (for example, research your commute time).
In the context of this example, the goal of using ML in the overall system is not to enable it to perform a task. For instance, you might train algorithms to analyze live transit and traffic data to forecast the volume and density of traffic flow. However, the scope is limited to identifying patterns, how accurate the prediction was, and learning from the data to maximize performance for that specific task.
Artificial intelligence
AI allows a machine to simulate human intelligence to solve problems
The goal is to develop an intelligent system that can perform complex tasks
We build systems that can solve complex tasks like a human
AI has a wide scope of applications
AI uses technologies in a system so that it mimics human decision-making
AI works with all types of data: structured, semi-structured, and unstructured
AI systems use logic and decision trees to learn, reason, and self-correct
Machine learning
ML allows a machine to learn autonomously from past data
The goal is to build machines that can learn from data to increase the accuracy of the output
We train machines with data to perform specific tasks and deliver accurate results
Machine learning has a limited scope of applications
ML uses self-learning algorithms to produce predictive models
ML can only use structured and semi-structured data
ML systems rely on statistical models to learn and can self-correct when provided with new data
Benefits of using AI and ML together
AI and ML bring powerful benefits to organizations of all shapes and sizes, with new possibilities constantly emerging. In particular, as the amount of data grows in size and complexity, automated and intelligent systems are becoming vital to helping companies automate tasks, unlock value, and generate actionable insights to achieve better outcomes.
Here are some of the business benefits of using artificial intelligence and machine learning:
Wider data ranges
Analyzing and activating a wider range of unstructured and structured data sources.
Faster decision-making
Improving data integrity, accelerating data processing, and reducing human error for more informed, faster decision-making.
Efficiency
Increasing operational efficiency and reducing costs.
Analytic integration
Empowering employees by integrating predictive analytics and insights into business reporting and applications.
Applications of AI and ML
Artificial intelligence and machine learning can be applied in many ways, allowing organizations to automate repetitive or manual processes that help drive informed decision-making.
Companies across industries are using AI and ML in various ways to transform how they work and do business. Incorporating AI and ML capabilities into their strategies and systems helps organizations rethink how they use their data and available resources, drive productivity and efficiency, enhance data-driven decision-making through predictive analytics, and improve customer and employee experiences.
Here are some of the most common applications of AI and ML:
Healthcare and life sciences
Patient health record analysis and insights, outcome forecasting and modeling, accelerated drug development, augmented diagnostics, patient monitoring, and information extraction from clinical notes.
Manufacturing
Production machine monitoring, predictive maintenance, IoT analytics, and operational efficiency.
Ecommerce and retail
Inventory and supply chain optimization, demand forecasting, visual search, personalized offers and experiences, and recommendation engines.
Financial services
Risk assessment and analysis, fraud detection, automated trading, and service processing optimization.
Telecommunications
Intelligent networks and network optimization, predictive maintenance, business process automation, upgrade planning, and capacity forecasting.
Ever since digitalization took center stage, various new-age technologies have come to the fore and benefited sectors in a dramatic manner. Though the emergence has not only enticed humankind to embrace software and applications to manage their day-to-day chores but pushed various organizations to adopt performance-driven solutions. According to a cybersecurity company, there are 8.93 million mobile applications today, with the Google Play Store having 3.553 million apps, the Apple App Store having 1.642 million apps, and Amazon having 483 thousand apps. Traditionally, the focus of IT organizations has been entirely on technology development; however, exposure to apps and software has enabled individuals and businesses to achieve a given goal and execute the function. In this context, performance testing and monitoring came to the rescue, allowing IT solution providers and enterprises working on business-specific solutions to help and resolve issues that could lead to a poor user experience and revenue loss.
The early phase of performance testing and monitoring methods was limited to manual procedures, but the advent of innovative technologies such as artificial intelligence (AI) and machine learning (ML) enhanced and transformed the testing and monitoring process for the better. Especially the introduction of ML (a subset of AI) has enabled computer systems to learn, identify patterns, and make predictions without being programmed. Machine learning algorithms can be trained on large datasets of performance data to automatically identify anomalies, predict performance issues, and suggest optimization strategies. According to Market Research, the global machine learning market is poised to reach INR 7632.45 billion by 2027 at a CAGR of 37.12% during the forecast period 2021-2027.
The utilization of machine learning in testing makes the process more competent and dependable. And provide several benefits, such as improved accuracy, limited test maintenance, aid in test case writing and API testing, test data generation, and reduced UI-based testing. As technology evolves, the way we develop and test also needs to change, and testing in production itself is possible when ML can show future disruptions in advance to mitigate. Testing in production means code coverage of exactly what is needed without additional spending on the test environment. Thus, ML has become a vital player in improving performance testing and monitoring, eradicating the need for creating long-winded test procedures and reducing the time spent maintaining tests.
Ways to Improve Performance Testing and Monitoring
During testing, an application may display a variety of performance issues, such as an increased latency, systems that hang, freeze, or crash, and a decrease in throughout. As a result, machine learning emerged as a solution and can be used to track the source of a problem in software. Furthermore, ML’s capabilities are useful for current concerns and anticipating future values, and comparing them to those acquired in real-time.
In addition, the critical advantage of ML algorithms is that they learn and improve over time. The model can automatically alter in reaction to data, assisting in defining what “normal” is from week to week or month to month. Not only on time series data but ML correlation algorithms can also be used to find code-level issues causing resource abuse. This means that we can consider new data patterns and generate predictions and projections that are more exact than those based on the original data pattern. So let’s delve into some of the ways in which machine learning can improve performance testing and monitoring.
Predictive Analytics: Machine learning algorithms can be trained to forecast future performance concerns based on the collected data. This can assist the organization in proactively identifying and mitigating potential performance issues before they affect users.
Automated Anomaly detection: Machine learning algorithms can learn regular application performance patterns by analyzing performance measures like response time, throughput, and resource utilization. Once trained, the algorithm can detect anomalies such as unexpected spikes or decreases in performance and alert developers and operators to the problem.
Root Cause Analysis and Optimization: Performance data can be analyzed by machine learning techniques to pinpoint the underlying causes of performance problems. This can save time and effort for developers and operators who would otherwise need to detect and fix the problem manually. Thus, it can help teams optimize resource usage and improve performance.
Correlation and Causation: ML correlation and causation techniques can identify and quantify the relationship between resources and help build a causal graph to show how they affect performance.
Real-time Monitoring: Real-time performance data analysis by machine learning algorithms can predict performance problems in advance and alert. Firms can respond to concerns more rapidly and with less impact on users.
In addition, to implement machine learning for performance testing and monitoring, businesses must gather and store vast volumes of performance data, filter data for accuracy, train machine learning models, and deploy them as needed. It is critical to highlight that machine learning is not a panacea and should be augmented with traditional performance testing and monitoring approaches to achieve the best outcomes.
Technology: Pathway to Boost Performance
In the modern era, with the growing number of software and applications, businesses are discovering that software performance at par is not just a perk for customers but a necessity. The inability to achieve the desired outcome can result in financial loss and poor customer experience that should not be overlooked. This is where the need for machine learning has become essential, which can significantly improve performance testing and monitoring by automating anomaly detection, providing predictive analytics, enabling root cause analysis, optimizing resource usage, and enabling real-time monitoring. Furthermore, as software systems become more sophisticated, machine learning will become an increasingly important tool for ensuring optimal performance and user experience.
The machine learning market is growing in leaps and bounds, and experts project continued growth. A report by McKinsey indicates that AI has a large potential to be a significant driver of economic growth. Amid relentless competition, organizations are turning to machine learning to improve business efficiencies and reduce expenses.
Supply chain management is one of the key areas that affect businesses’ bottom lines. Organizations can gain a competitive edge and maximize their profits by leveraging the power of technology to increase efficiency in their supply chain operations. By leveraging the power of ML, businesses can reduce costs and increase profits, all while providing a better customer experience.
This article looks at the common applications of machine learning that offer excellent solutions in supply chain management.
What is machine Learning?
Machine learning is a type of artificial intelligence (AI) that enables computer systems to learn from data, identify patterns, and make decisions without being programmed. By analyzing large amounts of historical data, machine learning algorithms can identify patterns and trends that would otherwise be difficult or impossible for humans to recognize. Your business can use these insights to make more informed decisions, quickly and accurately, about your supply chain management processes.
Supply chain management
Most firms’ core competencies include their supply chains. The supply chain consists of all the steps needed to get a good or service from its beginnings to its final consumers. People, information, channels, resources, and means of transportation, as separate groups are all part of the supply chain and connected. Supply chain management integrates all supply chain activities; from original suppliers in procurement through fulfillment to the end users.
Pain points in supply chain management
There are a few problems faced by supply chains that machine learning algorithms can solve. Some of the distinct challenges include:
• Poor supply chain relationships management
• Inferior resource planning
• Low quality and safety standard maintenance
• High transportation costs
• Unmet customer needs
• Cost inefficiencies
How machine learning techniques can help
Many studies have investigated the various applications of machine learning in parts of the supply chains. Some of these applications include supplier selection, predicting financial and supply chain risks, and automating SCM frameworks. ML applications help improve the efficiency of supply chain operations, thus reducing costs, minimizing delays, and improving customer satisfaction.
Let’s examine some standard uses of machine learning applications in supply chain management.
1. Automation of SCM framework. ML can automate certain supply chain tasks such as inventory management, demand forecasting, and order fulfillment. Task automation can aid in reducing costs and improving efficiency by streamlining processes and eliminating manual labor. ML algorithms can help automate customer service tasks such as order tracking and query resolution, freeing up staff resources for more value-adding tasks such as marketing or product development.
2. Predictive analytics. One way in which supply chain management can apply machine learning is through predictive analytics. ML algorithms can predict and forecast customer demand and optimize production planning by analyzing historical data and customer trends. Companies can better predict future orders and plan their stock levels. Once your organization adopts an intelligent forecasting system, you can expect optimized performance, reduced costs, and increased sales and profit.
3. Risk management. ML algorithms can analyze historical data to identify potential risks in the supply chain, such as delivery delays or product defects way before they occur. Organizations can take proactive measures to mitigate these risks before they cause any disruption in the supply chain process.
Machine learning algorithms can also predict financial risks by raising alarms about fraudulent activities. Business managers can tighten security by setting alerts including duplicate payments to suppliers. In this way, they can reduce the chances of potential fraud charges.
4. Optimization of the supply chain process. Organizations can optimize the entire supply chain process from the start to the end-user delivery. ML algorithms can help identify areas where improvements should be made for greater efficiency and cost savings. Businesses that optimize their supply chains can select their best options and in turn improve efficiency.
5. Transportation and logistics optimization. Machine learning algorithms can be used to optimize transport routes and schedules. For instance, you can analyze real-time traffic data to determine the most efficient delivery routes. Companies can reduce fuel costs and ensure that deliveries are on time. ML algorithms can also track goods during transit. Historical data can precisely predict the lead times and reduce any errors.
Supply chain managers can control and improve operations and enhance customer satisfaction by having an accurate delivery time prediction
6. Inventory management. Inventory management is one of the critical areas of ML applications in supply chains. Machine learning improves inventory management by predicting demand for certain products and forecasting when items need restocking. Inventory planning is essential to track and optimize the demand and supply schedule. Planning helps prevent overstocking products that are not needed or running out of stock too quickly. Inventory planning ensures that customers always have access to the products they need when they need them.
7. Supplier selection. One of the main functions of supply chains is to select the ideal vendors for your business. Getting the correct vendors takes a lot of time and is also costly. Machine learning techniques can be used to find the correct factors in selecting and evaluating your vendors. Organizations can use historical data, market performance, and seasonal variations to find the correct factors in selecting and evaluating vendors.
Embracing AI and machine Learning
Machine learning techniques are used across industries in various areas of the supply chain. It is important to note that there are several applications of ML depending on the nature of the industry, the type, and the volume of data the business has. All these factors have a significant effect on selecting a suitable algorithm. Machine learning techniques will definitely increase in use in the future. As more and more businesses embrace AI and ML to improve their supply chains, they will likely increase their capacity, knowledge, and business insights.
In machine learning, there’s something called the “No Free Lunch” theorem. In a nutshell, it states that no one machine learning algorithm works best for every problem, and it’s especially relevant for supervised learning (i.e. predictive modeling).
For example, you can’t say that neural networks are always better than decision trees or vice versa. There are many factors at play, such as the size and structure of your dataset.
As a result, you should try many different algorithms for your problem, while using a hold-out “test set” of data to evaluate performance and select the winner.
Of course, the algorithms you try must be appropriate for your problem, which is where picking the right machine learning task comes in. As an analogy, if you need to clean your house, you might use a vacuum, a broom, or a mop, but you wouldn’t bust out a shovel and start digging.
THE BIG PRINCIPLE BEHIND MACHINE LEARNING ALGORITHMS
However, there is a common principle that underlies all supervised machine learning algorithms for predictive modeling.
Machine learning algorithms are described as learning a target function (f) that best maps input variables (X) to an output variable (Y): Y = f(X)
This is a general learning task where we would like to make predictions in the future (Y) given new examples of input variables (X). We don’t know what the function (f) looks like or its form. If we did, we would use it directly and we would not need to learn it from data using machine learning algorithms.
The most common type of machine learning is to learn the mapping Y = f(X) to make predictions of Y for new X. This is called predictive modeling or predictive analytics and our goal is to make the most accurate predictions possible.
Most Common Machine Learning Algorithms
For machine learning newbies who are eager to understand the basics of machine learning, here is a quick tour on the top 10 machine learning algorithms used by data scientists.
TOP MACHINE LEARNING ALGORITHMS YOU SHOULD KNOW
Linear Regression
Logistic Regression
Linear Discriminant Analysis
Classification and Regression Trees
Naive Bayes
K-Nearest Neighbors (KNN)
Learning Vector Quantization (LVQ)
Support Vector Machines (SVM)
Random Forest
Boosting
AdaBoost
1. LINEAR REGRESSION
Linear regression is perhaps one of the most well-known and well-understood algorithms in statistics and machine learning.
Predictive modeling is primarily concerned with minimizing the error of a model or making the most accurate predictions possible, at the expense of explainability. We will borrow, reuse and steal algorithms from many different fields, including statistics and use them towards these ends.
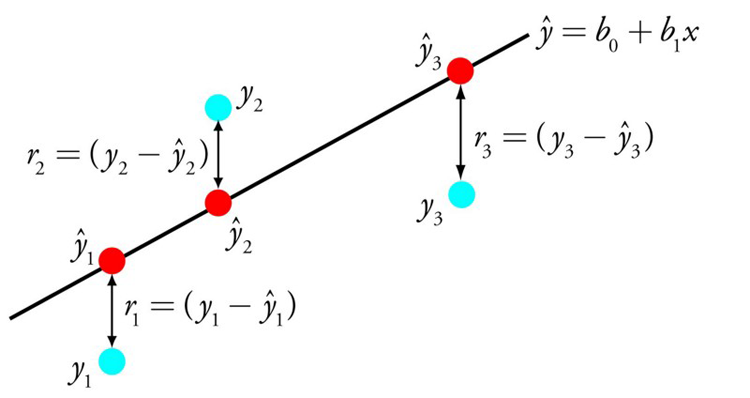
The representation of linear regression is an equation that describes a line that best fits the relationship between the input variables (x) and the output variables (y), by finding specific weightings for the input variables called coefficients (B).
Linear Regression
For example: y = B0 + B1 * x
We will predict y given the input x and the goal of the linear regression learning algorithm is to find the values for the coefficients B0 and B1.
Different techniques can be used to learn the linear regression model from data, such as a linear algebra solution for ordinary least squares and gradient descent optimization.
Linear regression has been around for more than 200 years and has been extensively studied. Some good rules of thumb when using this technique are to remove variables that are very similar (correlated) and to remove noise from your data, if possible. It is a fast and simple technique and a good first algorithm to try.
2. LOGISTIC REGRESSION
Logistic regression is another technique borrowed by machine learning from the field of statistics. It is the go-to method for binary classification problems (problems with two class values).
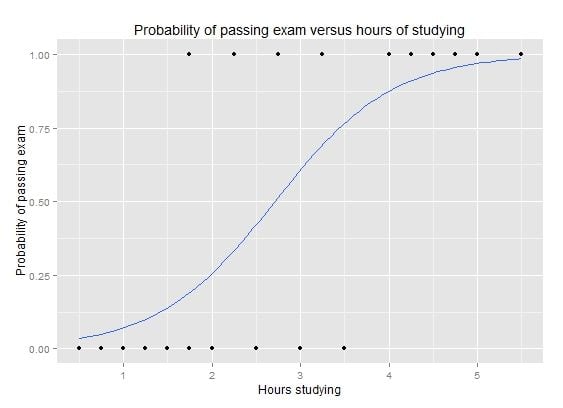
Logistic regression is like linear regression in that the goal is to find the values for the coefficients that weight each input variable. Unlike linear regression, the prediction for the output is transformed using a nonlinear function called the logistic function.
The logistic function looks like a big S and will transform any value into the range 0 to 1. This is useful because we can apply a rule to the output of the logistic function to snap values to 0 and 1 (e.g. IF less than 0.5 then output 1) and predict a class value.
Logistic Regression: Graph of a logistic regression curve showing probability of passing an exam versus hours studying
Because of the way that the model is learned, the predictions made by logistic regression can also be used as the probability of a given data instance belonging to class 0 or class 1. This can be useful for problems where you need to give more rationale for a prediction.
Like linear regression, logistic regression does work better when you remove attributes that are unrelated to the output variable as well as attributes that are very similar (correlated) to each other. It’s a fast model to learn and effective on binary classification problems.
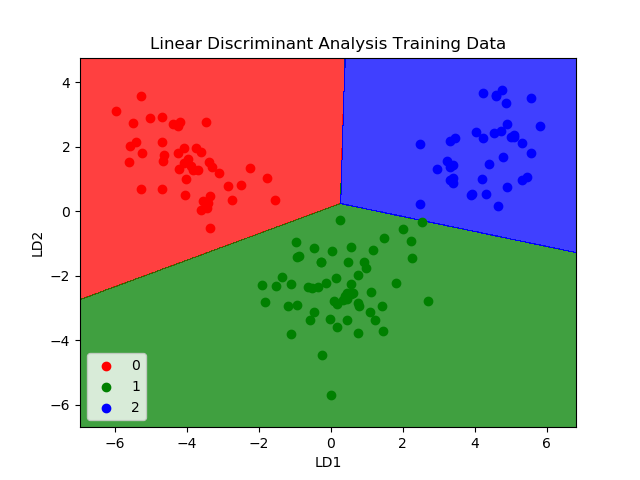
3. LINEAR DISCRIMINANT ANALYSIS
Logistic Regression is a classification algorithm traditionally limited to only two-class classification problems. If you have more than two classes then the Linear Discriminant Analysis algorithm is the preferred linear classification technique.
The representation of LDA is pretty straightforward. It consists of statistical properties of your data, calculated for each class. For a single input variable this includes:
The mean value for each class.
The variance calculated across all classes.
Linear Discriminant Analysis
Predictions are made by calculating a discriminant value for each class and making a prediction for the class with the largest value. The technique assumes that the data has a Gaussian distribution (bell curve), so it is a good idea to remove outliers from your data beforehand. It’s a simple and powerful method for classification predictive modeling problems.
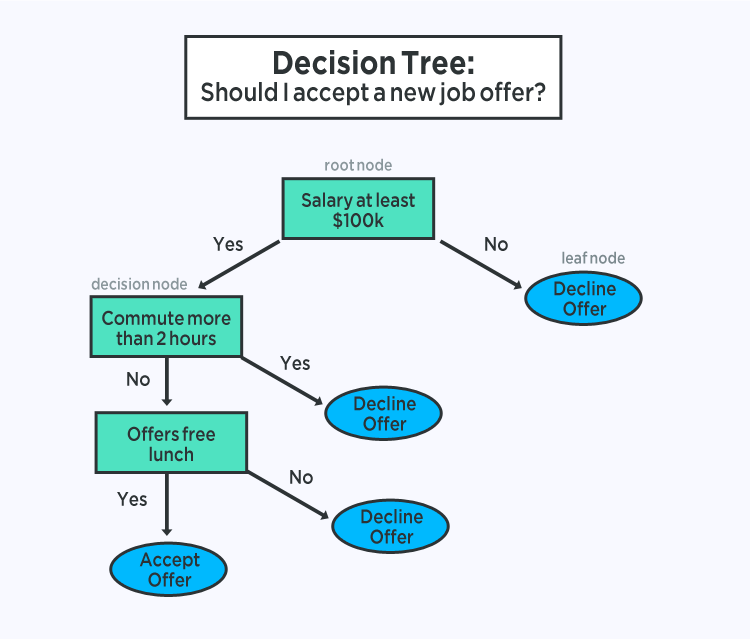
4. CLASSIFICATION AND REGRESSION TREES
Decision trees are an important type of algorithm for predictive modeling machine learning.
The representation of the decision tree model is a binary tree. This is your binary tree from algorithms and data structures, nothing too fancy. Each node represents a single input variable (x) and a split point on that variable (assuming the variable is numeric).
Decision Tree
The leaf nodes of the tree contain an output variable (y) which is used to make a prediction. Predictions are made by walking the splits of the tree until arriving at a leaf node and output the class value at that leaf node.
Trees are fast to learn and very fast for making predictions. They are also often accurate for a broad range of problems and do not require any special preparation for your data.
5. NAIVE BAYES
Naive Bayes is a simple but surprisingly powerful algorithm for predictive modeling.
The model consists of two types of probabilities that can be calculated directly from your training data: 1) The probability of each class; and 2) The conditional probability for each class given each x value. Once calculated, the probability model can be used to make predictions for new data using Bayes Theorem. When your data is real-valued it is common to assume a Gaussian distribution (bell curve) so that you can easily estimate these probabilities.
Naive Bayes: Bayes Theorem
Naive Bayes is called naive because it assumes that each input variable is independent. This is a strong assumption and unrealistic for real data, nevertheless, the technique is very effective on a large range of complex problems.
HIRING NOWView All Remote Data Science Jobs
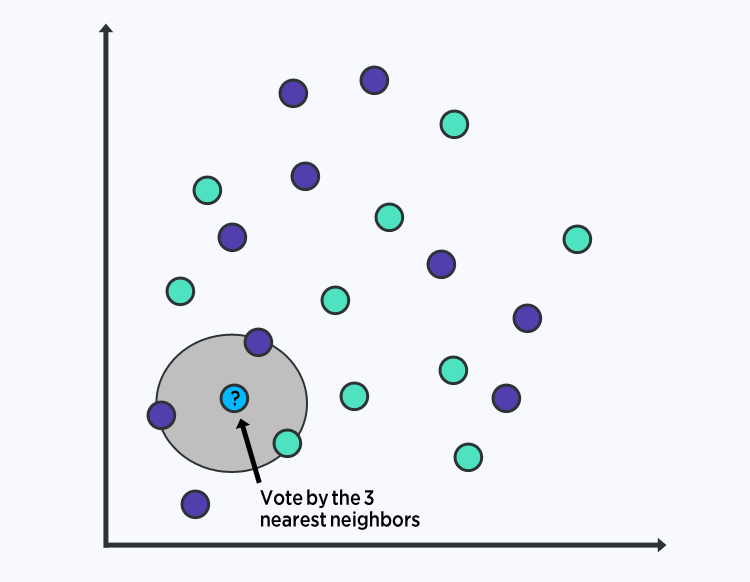
6. K-NEAREST NEIGHBORS
The KNN algorithm is very simple and very effective. The model representation for KNN is the entire training dataset. Simple right?
Predictions are made for a new data point by searching through the entire training set for the K most similar instances (the neighbors) and summarizing the output variable for those K instances. For regression problems, this might be the mean output variable, for classification problems this might be the mode (or most common) class value.
The trick is in how to determine the similarity between the data instances. The simplest technique if your attributes are all of the same scale (all in inches for example) is to use the Euclidean distance, a number you can calculate directly based on the differences between each input variable.
K-Nearest Neighbors
KNN can require a lot of memory or space to store all of the data, but only performs a calculation (or learn) when a prediction is needed, just in time. You can also update and curate your training instances over time to keep predictions accurate.
The idea of distance or closeness can break down in very high dimensions (lots of input variables) which can negatively affect the performance of the algorithm on your problem. This is called the curse of dimensionality. It suggests you only use those input variables that are most relevant to predicting the output variable.
7. LEARNING VECTOR QUANTIZATION
A downside of K-Nearest Neighbors is that you need to hang on to your entire training dataset. The Learning Vector Quantization algorithm (or LVQ for short) is an artificial neural network algorithm that allows you to choose how many training instances to hang onto and learns exactly what those instances should look like.
Learning Vector Quantization
The representation for LVQ is a collection of codebook vectors. These are selected randomly in the beginning and adapted to best summarize the training dataset over a number of iterations of the learning algorithm. After learning, the codebook vectors can be used to make predictions just like K-Nearest Neighbors. The most similar neighbor (best matching codebook vector) is found by calculating the distance between each codebook vector and the new data instance. The class value or (real value in the case of regression) for the best matching unit is then returned as the prediction. Best results are achieved if you rescale your data to have the same range, such as between 0 and 1.
If you discover that KNN gives good results on your dataset try using LVQ to reduce the memory requirements of storing the entire training dataset.
8. SUPPORT VECTOR MACHINES
Support Vector Machines are perhaps one of the most popular and talked about machine learning algorithms.
A hyperplane is a line that splits the input variable space. In SVM, a hyperplane is selected to best separate the points in the input variable space by their class, either class 0 or class 1. In two-dimensions, you can visualize this as a line and let’s assume that all of our input points can be completely separated by this line. The SVM learning algorithm finds the coefficients that result in the best separation of the classes by the hyperplane.
Support Vector Machine
The distance between the hyperplane and the closest data points is referred to as the margin. The best or optimal hyperplane that can separate the two classes is the line that has the largest margin. Only these points are relevant in defining the hyperplane and in the construction of the classifier. These points are called the support vectors. They support or define the hyperplane. In practice, an optimization algorithm is used to find the values for the coefficients that maximizes the margin.
SVM might be one of the most powerful out-of-the-box classifiers and worth trying on your dataset.
9. BAGGING AND RANDOM FOREST
Random forest is one of the most popular and most powerful machine learning algorithms. It is a type of ensemble machine learning algorithm called Bootstrap Aggregation or bagging.
The bootstrap is a powerful statistical method for estimating a quantity from a data sample. Such as a mean. You take lots of samples of your data, calculate the mean, then average all of your mean values to give you a better estimation of the true mean value.
In bagging, the same approach is used, but instead for estimating entire statistical models, most commonly decision trees. Multiple samples of your training data are taken then models are constructed for each data sample. When you need to make a prediction for new data, each model makes a prediction and the predictions are averaged to give a better estimate of the true output value.
Random Forest
Random forest is a tweak on this approach where decision trees are created so that rather than selecting optimal split points, suboptimal splits are made by introducing randomness.
The models created for each sample of the data are therefore more different than they otherwise would be, but still accurate in their unique and different ways. Combining their predictions results in a better estimate of the true underlying output value.
If you get good results with an algorithm with high variance (like decision trees), you can often get better results by bagging that algorithm.
10. BOOSTING AND ADABOOST
Adaboost
Boosting is an ensemble technique that attempts to create a strong classifier from a number of weak classifiers. This is done by building a model from the training data, then creating a second model that attempts to correct the errors from the first model. Models are added until the training set is predicted perfectly or a maximum number of models are added.
AdaBoost was the first really successful boosting algorithm developed for binary classification. It is the best starting point for understanding boosting. Modern boosting methods build on AdaBoost, most notably stochastic gradient boosting machines.
https://www.youtube.com/embed/LsK-xG1cLYA?autoplay=0&start=0&rel=0Explanation of AdaBoost
AdaBoost is used with short decision trees. After the first tree is created, the performance of the tree on each training instance is used to weight how much attention the next tree that is created should pay attention to each training instance. Training data that is hard to predict is given more weight, whereas easy to predict instances are given less weight. Models are created sequentially one after the other, each updating the weights on the training instances that affect the learning performed by the next tree in the sequence. After all the trees are built, predictions are made for new data, and the performance of each tree is weighted by how accurate it was on training data.
Because so much attention is put on correcting mistakes by the algorithm it is important that you have clean data with outliers removed.
Which Machine Learning Algorithm Should I Use?
A typical question asked by a beginner, when facing a wide variety of machine learning algorithms, is “which algorithm should I use?” The answer to the question varies depending on many factors, including: (1) The size, quality, and nature of data; (2) The available computational time; (3) The urgency of the task; and (4) What you want to do with the data.
Even an experienced data scientist cannot tell which algorithm will perform the best before trying different algorithms. Although there are many other machine learning algorithms, these are the most popular ones. If you’re a newbie to machine learning, these would be a good starting point to learn.
Machine learning is a modern innovation that has enhanced many industrial and professional processes as well as our daily lives. It’s a subset of artificial intelligence (AI), which focuses on using statistical techniques to build intelligent computer systems to learn from available databases.
With machine learning, computer systems can take all the customer data and utilise it. It operates on what’s been programmed while also adjusting to new conditions or changes. Algorithms adapt to data, developing behaviours that were not programmed in advance.
Learning to read and recognise context means a digital assistant could scan emails and extract the essential information. Inherent in this learning is the ability to make predictions about future customer behaviours. This helps you understand your customers more intimately and not just be responsive, but proactive.
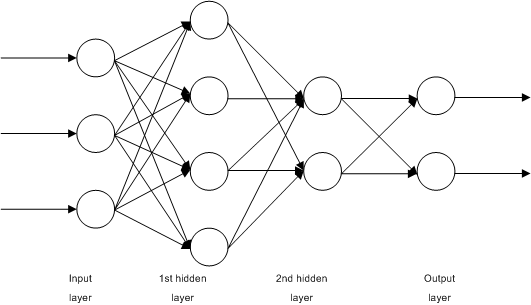
Deep learning is a segment of machine learning. In essence, it’s an artificial neural network with three or more layers. Neural networks with only one layer can make estimated predictions. The addition of more layers can assist with increasing optimisation and accuracy.
Machine learning is relevant in many fields, industries, and has the capability to grow over time. Here are six real-life examples of how machine learning is being used.
1. Image recognition
Image recognition is a well-known and widespread example of machine learning in the real world. It can identify an object as a digital image, based on the intensity of the pixels in black and white images or colour images.
Real-world examples of image recognition:
Label an x-ray as cancerous or not
Assign a name to a photographed face (aka “tagging” on social media)
Recognise handwriting by segmenting a single letter into smaller images
Machine learning is also frequently used for facial recognition within an image. Using a database of people, the system can identify commonalities and match them to faces. This is often used in law enforcement.
2. Speech recognition
Machine learning can translate speech into text. Certain software applications can convert live voice and recorded speech into a text file. The speech can be segmented by intensities on time-frequency bands as well.
Real-world examples of speech recognition:
Voice search
Voice dialling
Appliance control
Some of the most common uses of speech recognition software are devices like Google Home or Amazon Alexa.
3. Medical diagnosis
Machine learning can help with the diagnosis of diseases. Many physicians use chatbots with speech recognition capabilities to discern patterns in symptoms.
Real-world examples for medical diagnosis:
Assisting in formulating a diagnosis or recommends a treatment option
Oncology and pathology use machine learning to recognise cancerous tissue
Analyse bodily fluids
In the case of rare diseases, the joint use of facial recognition software and machine learning helps scan patient photos and identify phenotypes that correlate with rare genetic diseases.
4. Statistical arbitrage
Arbitrage is an automated trading strategy that’s used in finance to manage a large volume of securities. The strategy uses a trading algorithm to analyse a set of securities using economic variables and correlations.
Real-world examples of statistical arbitrage:
Algorithmic trading which analyses a market microstructure
Analyse large data sets
Identify real-time arbitrage opportunities
Machine learning optimises the arbitrage strategy to enhance results.
5. Predictive analytics
Machine learning can classify available data into groups, which are then defined by rules set by analysts. When the classification is complete, the analysts can calculate the probability of a fault.
Real-world examples of predictive analytics:
Predicting whether a transaction is fraudulent or legitimate
Improve prediction systems to calculate the possibility of fault
Predictive analytics is one of the most promising examples of machine learning. It’s applicable for everything; from product development to real estate pricing.
6. Extraction
Machine learning can extract structured information from unstructured data. Organisations amass huge volumes of data from customers. A machine learning algorithm automates the process of annotating datasets for predictive analytics tools.
Real-world examples of extraction:
Generate a model to predict vocal cord disorders
Develop methods to prevent, diagnose, and treat the disorders
Help physicians diagnose and treat problems quickly
Typically, these processes are tedious. But machine learning can track and extract information to obtain billions of data samples.
Machine learning in the future
Machine learning is a remarkable technology in the field of artificial intelligence. Even in its earliest uses, machine learning has already improved our daily lives and the future..
If you’re ready to apply machine learning to your business strategy and create customised experiences, check out the Personalisation Builder. Use the power of predictive analytics and modelling to understand each customer’s preferences!
Personalization Builder
Use the power of predictive analytics and modeling to understand each customer’s preferences and automatically tailor content delivered in email and on the web.
Interested in artificial intelligence and how it’s affecting the global business landscape? Discover the benefits of AI for businesses in every industry.
Artificial intelligence and machine learning are very closely related and connected. Because of this relationship, when you look into AI vs. machine learning, you’re really looking into their interconnection.
What is artificial intelligence (AI)?
Artificial intelligence is the capability of a computer system to mimic human cognitive functions such as learning and problem-solving. Through AI, a computer system uses math and logic to simulate the reasoning that people use to learn from new information and make decisions.
Are AI and machine learning the same?
While AI and machine learning are very closely connected, they’re not the same. Machine learning is considered a subset of AI.
What is machine learning?
Machine learning is an application of AI. It’s the process of using mathematical models of data to help a computer learn without direct instruction. This enables a computer system to continue learning and improving on its own, based on experience.
How are AI and machine learning connected?
An “intelligent” computer uses AI to think like a human and perform tasks on its own. Machine learning is how a computer system develops its intelligence.
One way to train a computer to mimic human reasoning is to use a neural network, which is a series of algorithms that are modeled after the human brain. The neural network helps the computer system achieve AI through deep learning. This close connection is why the idea of AI vs. machine learning is really about the ways that AI and machine learning work together.
How AI and machine learning work together
When you’re looking into the difference between artificial intelligence and machine learning, it’s helpful to see how they interact through their close connection. This is how AI and machine learning work together:
Step 1
An AI system is built using machine learning and other techniques.
Step 2
Machine learning models are created by studying patterns in the data.
Step 3
Data scientists optimize the machine learning models based on patterns in the data.
Step 4
The process repeats and is refined until the models’ accuracy is high enough for the tasks that need to be done.
Capabilities of AI and machine learning
Companies in almost every industry are discovering new opportunities through the connection between AI and machine learning. These are just a few capabilities that have become valuable in helping companies transform their processes and products:
Predictive analytics
This capability helps companies predict trends and behavioral patterns by discovering cause-and-effect relationships in data.
Recommendation engines
With recommendation engines, companies use data analysis to recommend products that someone might be interested in.
Speech recognition and natural language understanding
Speech recognition enables a computer system to identify words in spoken language, and natural language understanding recognizes meaning in written or spoken language.
Image and video processing
These capabilities make it possible to recognize faces, objects, and actions in images and videos, and implement functionalities such as visual search.
Sentiment analysis
A computer system uses sentiment analysis to identify and categorize positive, neutral, and negative attitudes that are expressed in text.
Benefits of AI and machine learning
The connection between artificial intelligence and machine learning offers powerful benefits for companies in almost every industry—with new possibilities emerging constantly. These are just a few of the top benefits that companies have already seen:
More sources of data input
AI and machine learning enable companies to discover valuable insights in a wider range of structured and unstructured data sources.
Better, faster decision-making
Companies use machine learning to improve data integrity and use AI to reduce human error—a combination that leads to better decisions based on better data.
Increased operational efficiency
With AI and machine learning, companies become more efficient through process automation, which reduces costs and frees up time and resources for other priorities.
Applications of AI and machine learning
Companies in several industries are building applications that take advantage of the connection between artificial intelligence and machine learning. These are just a few ways that AI and machine learning are helping companies transform their processes and products:
Retail
Retailers use AI and machine learning to optimize their inventories, build recommendation engines, and enhance the customer experience with visual search.
Healthcare
Health organizations put AI and machine learning to use in applications such as image processing for improved cancer detection and predictive analytics for genomics research.
Banking and finance
In financial contexts, AI and machine learning are valuable tools for purposes such as detecting fraud, predicting risk, and providing more proactive financial advice.
Sales and marketing
Sales and marketing teams use AI and machine learning for personalized offers, campaign optimization, sales forecasting, sentiment analysis, and prediction of customer churn.
Cybersecurity
AI and machine learning are powerful weapons for cybersecurity, helping organizations protect themselves and their customers by detecting anomalies.
Customer service
Companies in a wide range of industries use chatbots and cognitive search to answer questions, gauge customer intent, and provide virtual assistance.
Transportation
AI and machine learning are valuable in transportation applications, where they help companies improve the efficiency of their routes and use predictive analytics for purposes such as traffic forecasting.
Manufacturing
Manufacturing companies use AI and machine learning for predictive maintenance and to make their operations more efficient than ever.