Introduction to ChatGPT for Non-Developers. How to get the best results from ChatGPT with real world applications.
Requirements
No programming or prior experience needed. We will cover the basics from entry-level to advanced prompt manipulation.
Description
Are you interested in learning about ChatGPT but feel intimidated by technical jargon? Look no further! This course is designed for anyone, regardless of their technical background, seeking to gain an entry-level to advanced understanding of end-user ChatGPT expertise.
In this course, you will learn how ChatGPT works, how to train and fine-tune it to fit your needs, and how to create relevant prompts. You will be able to apply this knowledge to various fields, including academia, programming, marketing, and personal life.
With meticulously curated real-world examples, this course provides something for everyone. You will learn through specialized lectures that are straight to the point, providing necessary and relevant historical, present, and example context for efficient learning.
By the end of this course, you will be confident in your ability to refine ChatGPT into whatever task you may have, over whatever field you may be in. Join now to embark on your journey to becoming a ChatGPT expert!
We will cover the following topics to help best refine our understanding of ChatGPT and AI:
Introduction & Entry-Level Basics of ChatGPT
What is ChatGPT?
How does it work?
How do I begin?
Training and Fine-tuning of ChatGPT, and how to use that knowledge to create relevant prompts.
Understanding the Training Process (Pre-Training & Fine-Tuning)
What is Pre-Training?
What is Fine-Tuning?
Hyperparameters
Transfer Learning
Practical Examples for Fine-Tuning
Keywords and Context Usage
Real-World Applications & Examples
Examples in the following:
Academia
Programming
Marketing
Personal Life
Emerging Trends and Technologies around AI
Future Outlook and Job Creation
Ethical Concerns and Limitations of AI
Ethical Concerns
Limitations
Managing Bias (And Muddied Results as a Result Of)
Whether you’re a student, a professional, or someone who’s just curious about the capabilities of ChatGPT, this course will provide you with the tools and knowledge to take your understanding to the next level. Join our community of learners and start exploring the endless possibilities of ChatGPT today!
Who this course is for:
This entry-level course is designed for anyone interested in learning about AI language models and how to maximize their potential using ChatGPT.
A business professional looking to leverage AI for customer service or marketing
A student interested in exploring the cutting edge of AI technology
A hobbyist looking to keep up with the latest technology trends
Entrepreneurs looking for creative twists on an idea or pitch.
Anyone who is curious about AI language models and wants to learn how to use them to solve real-world problems
This course is not for developers looking to interface ChatGPT to an API
Maximize Productivity and Efficiency with the Help of ChatGPT, Google Keep and Google Calender
Requirements
A computer or smartphone with internet connection.
Description
In this course, we will dive into the world of time management and productivity using the powerful combination of ChatGPT, Google Keep and Google Calendar. You will learn how to effectively utilize these tools to identify important tasks, manage your time, and increase productivity. The course is designed to give you a step by step approach to mastering time management.
First, we will start by teaching you how to list and prioritize tasks. This is the foundation of time management and will ensure that you are focusing on the most important tasks first. You will learn how to use ChatGPT and other online tools to automate tasks, streamline your workflow and increase your productivity.
Next, we will teach you how to create a schedule that is tailored to your needs. This will help you stay organized and on track throughout the day, week, or month. We will also teach you how to eliminate distractions and focus on getting the work done.
In addition, you will learn how to use the powerful capabilities of ChatGPT, Google Keep and Google Calendar to increase your productivity and work output. We will teach you how to use these tools to automate tasks, set reminders, and stay organized.
By the end of this course, you will have the skills and knowledge to use ChatGPT, Google Keep, and Google Calendar for everyday time management and achieve greater efficiency and productivity in your personal and professional life. With this course, you will be able to manage your time more effectively, increase productivity, and achieve your goals.
Who this course is for:
This course is for anyone looking to improve their time management and productivity using ChatGPT, Google Keep, and Google Calendar or any other apps.
AI for Everyone (AI4E)® introduces anyone to modern AI technologies and applications so that you can be savvy consumers of AI products and services. You will learn how to identify opportunities and potential use cases in your work and daily lives, and build a simple AI model with online tools.
Who this course is for:
Anyone who wants to identify opportunites and potenial use of AI in thier daily work/lives
AI SEO Mastery: 7 SEO Tasks to Automate with AI & Rank #1!
5 Best FREE AI SEO Tools to Rank #1 [MIND BLOWING!]
The ChatGPT SEO Strategies that 4X’d My SEO Traffic in 42 Days!
SEO Ninja Tricks: Create FREE SEO Tools with ChatGPT (100X Productivity)!
Requirements
ChatGpt Access
A Website
A basic understanding of what SEO is
Description
Are you tired of struggling to get your website to rank high on search engine results pages?
Do you want to learn how to leverage the power of artificial intelligence (AI) to boost your SEO efforts and drive more traffic to your site?
Look no further than our Udemy course, “AI-Powered SEO Mastery: How to Rank #1 with AI SEO Tools”!
This comprehensive and practical course will teach you everything you need to know about using AI-powered SEO tools to achieve top rankings on Google and other search engines.
Here’s what you’ll learn:
Unlock the power of AI to boost your website’s SEO and drive more traffic to your site
Learn the latest and most effective AI-powered SEO tools and techniques
Achieve top rankings on Google and other search engines
Enjoy a comprehensive and practical course that covers everything you need to know about AI-powered SEO
Get expert guidance from experienced SEO professionals who have successfully leveraged AI to rank #1
Gain invaluable insights into keyword research, link building, content creation, and more
Discover how to optimize your website’s structure, meta tags, and other key elements for maximum search engine visibility
Stay ahead of the competition with cutting-edge AI-powered SEO strategies
Boost your website’s traffic, engagement, and revenue with the latest SEO trends and tools
Get lifetime access to the course content, updates, and support from our team of SEO experts.
Whether you realize it or not, we are currently entering the era of artificial intelligence. AI technologies are radically transforming our lives, our careers, and our world. However, most of us have not yet learned how to leverage the power of this new technology.
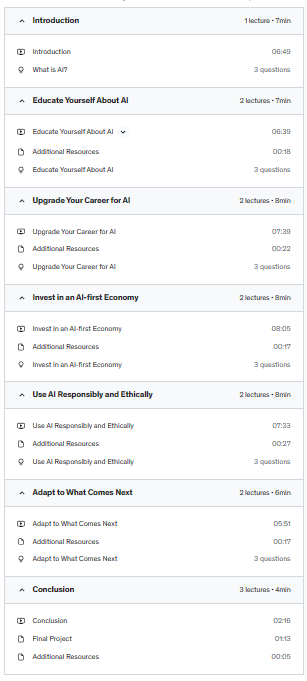
In this free course, you’ll learn the five things you should be doing today to prepare your career for the coming wave of AI-enabled automation.
Educate yourself about AI
Upgrade your career for AI
Invest in an AI-first economy
Use AI ethically and responsibly
Adapt to what comes next
The future belongs to those who are willing to invest in AI now. Don’t get left behind!
Overview of AI tools for developers and their impact on software development
Introduction to ChatGPT, a language model developed by OpenAI for code completion and generation
Integration of ChatGPT with popular IDEs and text editors
Hands-on exercises and projects to practice using ChatGPT to generate code snippets and complete code blocks
Introduction to GitHub Copilot, an AI-powered code assistant that suggests code as developers type
Setup and configuration of GitHub Copilot with popular programming languages
Practical applications of GitHub Copilot in software development
Introduction to Copilot Labs, an open-source initiative that creates powerful AI tools for developers
Contributions to Copilot Labs and use of the tools developed by the community
Hands-on exercises and projects to practice using AI tools to streamline the development workflow
Understanding of how AI works and its impact on software development
Knowledge and skills to increase productivity, build innovative applications, and further career in software development
Requirements
Students will need a computer/laptop to do the practical implementation.
Basic programming knowledge is required.
Description
In today’s world, Artificial Intelligence (AI) is revolutionizing the way we work and live. One area where AI has made a significant impact is in software development, where it has enabled developers to create innovative applications and systems faster than ever before.
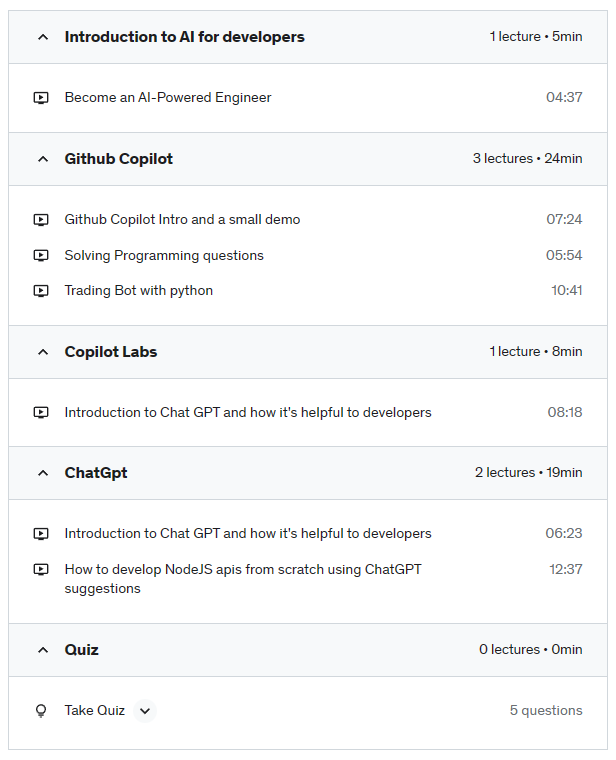
This comprehensive course, “Become an AI-Powered Engineer: ChatGPT, Github Copilot, and Copilot Labs” is designed to help developers learn how to leverage AI tools to streamline their development process. The course covers three popular AI tools: ChatGPT, GitHub Copilot, and Copilot Labs.
First, students will learn how to use ChatGPT, a language model developed by OpenAI, to generate high-quality code snippets and complete code blocks. They will learn how to integrate ChatGPT with their favorite IDEs and text editors, such as VS Code and Sublime Text.
Next, the course covers GitHub Copilot, an AI-powered code assistant that uses machine learning to suggest code as developers type. Students will learn how to set up and use GitHub Copilot with popular programming languages such as Python, JavaScript, and C#.
Finally, the course covers Copilot Labs, an open-source initiative that aims to create powerful AI tools for developers. Students will learn how to contribute to Copilot Labs and use the tools developed by the community.
Throughout the course, students will work on real-world projects and learn how to integrate AI tools into their development workflow. They will gain an understanding of how it can be used to improve software development.
By the end of the course, students will have the skills and knowledge needed to use ChatGPT, GitHub Copilot, and Copilot Labs to streamline their development process, increase productivity, and build innovative applications faster than ever before.
Who this course is for:
Developers who want to learn about the latest AI-powered tools for code completion, debugging, and more
Software engineers looking to improve their productivity and efficiency with advanced development tools
Anyone interested in exploring the intersection of AI and software development
Outsourcing: How ChatGPT DOUBLED My SEO Traffic in 12 Days With THIS SEO Strategy
5 EPIC ChatGPT SEO Prompts that Increased My SEO Traffic by 100%
How I Rank ChatGPT Content #1 Page of Google 2023
How to use the ChatGPT AI PRM Extension for SEO
Requirements
You’ll need a website and a ChatGPT account.
Description
Are you ready to discover the secrets to dominating search engine rankings with ChatGPT SEO!
With this free course, you’ll learn how to tap into the power of ChatGPT and skyrocket your SEO traffic like never before WITHOUT having to hire expensive SEOs or content writers.
Hi, my name’s Julian Goldie, and I’m not going to bore you with all the marketing hype but I’m a published author of 2 best-selling books including “Link Building Mastery”, the owner of a 7 figure SEO link building company Goldie Agency, YouTuber, podcaster, and I’ve helped thousands of websites with SEO. Now that’s enough of me boasting about my accomplishments!
In this free course, you’ll learn the PROVEN Strategies and Techniques that Will Transform Your SEO Game including:
How I Increased SEO Traffic by 50% With ChatGPT – Uncover the strategies I used to supercharge my SEO traffic by leveraging ChatGPT’s AI-powered content generation.
How I Rank Money Pages #1 on Google With ChatGPT – Learn my step-by-step process for ranking money pages on the first page of Google by harnessing ChatGPT’s AI capabilities.
Outsourcing: How ChatGPT DOUBLED My SEO Traffic in 12 Days With THIS SEO Strategy – Discover how to outsource your SEO efforts effectively and use ChatGPT to double your traffic in less than two weeks.
5 EPIC ChatGPT SEO Prompts that Increased My SEO Traffic by 100% – Get access to five game-changing prompts that will help you create content that drives massive organic traffic to your site.
How I Rank ChatGPT Content #1 Page of Google 2023 – Stay ahead of the curve with my latest techniques for ranking ChatGPT-generated content on the first page of Google in 2023.
How to use the ChatGPT AI PRM Extension for SEO – Maximize your SEO efforts with the innovative ChatGPT AI PRM extension, designed to improve your content’s search engine performance.
Don’t miss out on this opportunity to revolutionize your SEO strategy and dominate the search engine rankings!
Get FREE access to the course and start your journey to SEO mastery today!
Who this course is for:
Website Owners
Business Owners
SEOs
Bloggers and Writers
Course content
1 section • 8 lectures • 1h 26m total length
Introduction8 lectures • 1hr 26min
How I Increased SEO Traffic by 50% With ChatGPT17:28
How I Rank Money Pages #1 on Google With ChatGPT25:59
Outsourcing: How ChatGPT DOUBLED My SEO Traffic in 12 Days With THIS SEO Strateg14:29
5 EPIC ChatGPT SEO Prompts that Increased My SEO Traffic by 100%13:25
How I Rank ChatGPT Content #1 Page of Google 202306:49
How to use the ChatGPT AI PRM Extension for SEO06:11
Free Link Building Book: Link Building Mastery01:00
ChatGPT & Google BARD are advanced language model that uses artificial intelligence to generate human-like responses to user inputs. With its ability to understand natural language and context, ChatGPT & Google BARD have a wide range of potential use cases across various industries. This course will provide an introduction to ChatGPT and explore its applications in customer service, marketing, and more.
In the customer service industry, ChatGPT & Google BARD can be used to automate responses to frequently asked questions, reducing the need for human agents and improving response times.
What People Are Saying About Us:
There are many introductory courses on ChatGPT. This course is easy to digest, and there are some practical use cases that I will be able to use immediately.
-Steven Kelly-
It was very good . I learned a lot from this course . Thank You
-Disha Prajapat-
Outstanding this course
-Prem Ghosh-
In marketing, ChatGPT & Google BARD can be used to generate personalized recommendations and responses to customer inquiries, creating a more engaging and interactive customer experience. ChatGPT & Google BARD can also be used in healthcare to assist with patient consultations and medical diagnosis, and in finance to automate customer support and account management.
Throughout the course, learners will gain a thorough understanding of how Google BARD & ChatGPT work and how they can be implemented in various settings. Students will learn how it can be implemented in their daily lives from assignment help to creating a Standard Operating Procedure (SOP) for a particular piece of machinery. For ChatGPT students they will learn how it can be used in:
Canva,
MS Powerpoint
MS Excel
YouTube
This course covers some of the applications to using ChatGPT & Google BARD in modern day contexts!
Who this course is for:
Individuals with an interest in improving there life through using these applications!
Business Owners
Digital Marketers
Content Creators
Social Media Users
Course content
14 sections • 23 lectures • 1h 27m total lengthExpand all sections
Large language models have captured the news cycle, but there are many other kinds of machine learning and deep learning with many different use cases.
Amid all the hype and hysteria about ChatGPT, Bard, and other generative large language models (LLMs), it’s worth taking a step back to look at the gamut of AI algorithms and their uses. After all, many “traditional” machine learning algorithms have been solving important problems for decades—and they’re still going strong. Why should LLMs get all the attention?
Before we dive in, recall that machine learning is a class of methods for automatically creating predictive models from data. Machine learning algorithms are the engines of machine learning, meaning it is the algorithms that turn a data set into a model. Which kind of algorithm works best (supervised, unsupervised, classification, regression, etc.) depends on the kind of problem you’re solving, the computing resources available, and the nature of the data.
In the next section, I’ll briefly survey the different kinds of machine learning and the different kinds of machine learning models. Then I’ll discuss 14 of the most commonly used machine learning and deep learning algorithms, and explain how those algorithms relate to the creation of models for prediction, classification, image processing, language processing, game-playing and robotics, and generative AI.
[ Also on InfoWorld: The best software development, cloud computing, data analytics, and machine learning products of 2022 ]
Table of Contents
Kinds of machine learning
Popular machine learning algorithms
Popular deep learning algorithms
Kinds of machine learning
Machine learning can solve non-numeric classification problems (e.g., “predict whether this applicant will default on his loan”) and numeric regression problems (e.g., “predict the sales of food processors in our retail locations for the next three months”). Both kinds of models are primarily trained using supervised learning, which means the training data has already been tagged with the answers.
0 seconds of 30 secondsVolume 0%
Tagging training data sets can be expensive and time-consuming, so supervised learning is often enhanced with semi-supervised learning. Semi-supervised learning applies the supervised learning model from a small tagged data set to a larger untagged data set, and adds whatever predicted data that has a high probability of being correct to the model for further predictions. Semi-supervised learning can sometimes go off the rails, so you can improve the process with human-in-the-loop (HITL) review of questionable predictions.
While the biggest problem with supervised learning is the expense of labeling the training data, the biggest problem with unsupervised learning (where the data is not labeled) is that it often doesn’t work very well. Nevertheless, unsupervised learning does have its uses: It can sometimes be good for reducing the dimensionality of a data set, exploring the data’s patterns and structure, finding groups of similar objects, and detecting outliers and other noise in the data.
The potential of an agent that learns for the sake of learning is far greater than a system that reduces complex pictures to a binary decision (e.g., dog or cat). Uncovering patterns rather than carrying out a pre-defined task can yield surprising and useful results, as demonstrated when researchers at Lawrence Berkeley Lab ran a text processing algorithm (Word2vec) on several million material science abstracts to predict discoveries of new thermoelectric materials.Nominations are open for the 2024 Best Places to Work in IT
Reinforcement learning trains an actor or agent to respond to an environment in a way that maximizes some value, usually by trial and error. That’s different from supervised and unsupervised learning, but is often combined with them. It has proven useful for training computers to play games and for training robots to perform tasks.
Neural networks, which were originally inspired by the architecture of the biological visual cortex, consist of a collection of connected units, called artificial neurons, organized in layers. The artificial neurons often use sigmoid or ReLU (rectified linear unit) activation functions, as opposed to the step functions used for the early perceptrons. Neural networks are usually trained with supervised learning.
Deep learning uses neural networks that have a large number of “hidden” layers to identify features. Hidden layers come between the input and output layers. The more layers in the model, the more features can be identified. At the same time, the more layers in the model, the longer it takes to train. Hardware accelerators for neural networks include GPUs, TPUs, and FPGAs.
Fine-tuning can speed up the customization of models significantly by training a few final layers on new tagged data without modifying the weights of the rest of the layers. Models that lend themselves to fine-tuning are called base models or foundational models.
Vision models often use deep convolutional neural networks. Vision models can identify the elements of photographs and video frames, and are usually trained on very large photographic data sets.
Language models sometimes use convolutional neural networks, but recently tend to use recurrent neural networks, long short-term memory, or transformers. Language models can be constructed to translate from one language to another, to analyze grammar, to summarize text, to analyze sentiment, and to generate text. Language models are usually trained on very large language data sets.
Popular machine learning algorithms
The list that follows is not comprehensive, and the algorithms are ordered roughly from simplest to most complex.
Linear regression
Linear regression, also called least squares regression, is the simplest supervised machine learning algorithm for predicting numeric values. In some cases, linear regression doesn’t even require an optimizer, since it is solvable in closed form. Otherwise, it is easily optimized using gradient descent (see below). The assumption of linear regression is that the objective function is linearly correlated with the independent variables. That may or may not be true for your data.
To the despair of data scientists, business analysts often blithely apply linear regression to prediction problems and then stop, without even producing scatter plots or calculating correlations to see if the underlying assumption is reasonable. Don’t fall into that trap. It’s not that hard to do your exploratory data analysis and then have the computer try all the reasonable machine learning algorithms to see which ones work the best. By all means, try linear regression, but treat the result as a baseline, not a final answer.
Gradient descent
Optimization methods for machine learning, including neural networks, typically use some form of gradient descent algorithm to drive the back propagation, often with a mechanism to help avoid becoming stuck in local minima, such as optimizing randomly selected mini-batches (stochastic gradient descent) and applying momentum corrections to the gradient. Some optimization algorithms also adapt the learning rates of the model parameters by looking at the gradient history (AdaGrad, RMSProp, and Adam).
Logistic regression
Classification algorithms can find solutions to supervised learning problems that ask for a choice (or determination of probability) between two or more classes. Logistic regression is a method for solving categorical classification problems that uses linear regression inside a sigmoid or logit function, which compresses the values to a range of 0 to 1 and gives you a probability. Like linear regression for numerical prediction, logistic regression is a good first method for categorical prediction, but shouldn’t be the last method you try.
Support vector machines
Support vector machines (SVMs) are a kind of parametric classification model, a geometric way of separating and classifying two label classes. In the simplest case of well-separated classes with two variables, an SVM finds the straight line that best separates the two groups of points on a plane.
In more complicated cases, the points can be projected into a higher-dimensional space and the SVM finds the plane or hyperplane that best separates the classes. The projection is called a kernel, and the process is called the kernel trick. After you reverse the projection, the resulting boundary is often nonlinear.
When there are more than two classes, SVMs are used on the classes pairwise. When classes overlap, you can add a penalty factor for points that are misclassified; this is called a soft margin.
Decision tree
Decision trees (DTs) are a non-parametric supervised learning method used for both classification and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. A tree can be seen as a piecewise constant approximation.
Decision trees are easy to interpret and cheap to deploy, but computationally expensive to train and prone to overfitting.
Random forest
The random forest model produces an ensemble of randomized decision trees, and is used for both classification and regression. The aggregated ensemble either combines the votes modally or averages the probabilities from the decision trees. Random forest is a kind of bagging ensemble.
XGBoost
XGBoost (eXtreme Gradient Boosting) is a scalable, end-to-end, tree-boosting system that has produced state-of-the-art results on many machine learning challenges. Bagging and boosting are often mentioned in the same breath. The difference is that instead of generating an ensemble of randomized trees (RDFs), gradient tree boosting starts with a single decision or regression tree, optimizes it, and then builds the next tree from the residuals of the first tree.
K-means clustering
The k-means clustering problem attempts to divide n observations into k clusters using the Euclidean distance metric, with the objective of minimizing the variance (sum of squares) within each cluster. It is an unsupervised method of vector quantization, and is useful for feature learning, and for providing a starting point for other algorithms.
Lloyd’s algorithm (iterative cluster agglomeration with centroid updates) is the most common heuristic used to solve the problem. It is relatively efficient, but doesn’t guarantee global convergence. To improve that, people often run the algorithm multiple times using random initial cluster centroids generated by the Forgy or random partition methods.
K-means assumes spherical clusters that are separable so that the mean converges towards the cluster center, and also assumes that the ordering of the data points does not matter. The clusters are expected to be of similar size, so that the assignment to the nearest cluster center is the correct assignment.
Principal component analysis
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated numeric variables into a set of values of linearly uncorrelated variables called principal components. Karl Pearson invented PCA in 1901. PCA can be accomplished by eigenvalue decomposition of a data covariance (or correlation) matrix, or singular value decomposition (SVD) of a data matrix, usually after a normalization step applied to the initial data.
Popular deep learning algorithms
There are a number of very successful and widely adopted deep learning paradigms, the most recent being the transformer architecture behind today’s generative AI models.
Convolutional neural networks
Convolutional neural networks (CNNs) are a type of deep neural network often used for machine vision. They have the desirable property of being position-independent.
The understandable summary of a convolution layer when applied to images is that it slides over the image spatially, computing dot products; each unit in the layer shares one set of weights. A convnet typically uses multiple convolution layers, interspersed with activation functions. CNNs can also have pooling and fully connected layers, although there is a trend toward getting rid of these types of layers.
Recurrent neural networks
While convolutional neural networks do a good job of analyzing images, they don’t really have a mechanism that accounts for time series and sequences, as they are strictly feed-forward networks. Recurrent neural networks (RNNs), another kind of deep neural network, explicitly include feedback loops, which effectively gives them some memory and dynamic temporal behavior and allows them to handle sequences, such as speech.
That doesn’t mean that CNNs are useless for natural language processing; it does mean that RNNs can model time-based information that escapes CNNs. And it doesn’t mean that RNNs can only process sequences. RNNs and their derivatives have a variety of application areas, including language translation, speech recognition and synthesis, robot control, time series prediction and anomaly detection, and handwriting recognition.
While in theory an ordinary RNN can carry information over an indefinite number of steps, in practice it generally can’t go many steps without losing the context. One of the causes of the problem is that the gradient of the network tends to vanish over many steps, which interferes with the ability of a gradient-based optimizer such as stochastic gradient descent (SGD) to converge.
Long short-term memory
Long short-term memory networks (LSTMs) were explicitly designed to avoid the vanishing gradient problem and allow for long-term dependencies. The design of an LSTM adds some complexity compared to the cell design of an RNN, but works much better for long sequences.
Machine learning is enabling computers to tackle tasks that have, until now, only been carried out by people.
From driving cars to translating speech, machine learning is driving an explosion in the capabilities of artificial intelligence – helping software make sense of the messy and unpredictable real world.
But what exactly is machine learning and what is making the current boom in machine learning possible?
What is machine learning?
At a very high level, machine learning is the process of teaching a computer system how to make accurate predictions when fed data.
Those predictions could be answering whether a piece of fruit in a photo is a banana or an apple, spotting people crossing the road in front of a self-driving car, whether the use of the word book in a sentence relates to a paperback or a hotel reservation, whether an email is spam, or recognizing speech accurately enough to generate captions for a YouTube video.
The key difference from traditional computer software is that a human developer hasn’t written code that instructs the system how to tell the difference between the banana and the apple.
Instead a machine-learning model has been taught how to reliably discriminate between the fruits by being trained on a large amount of data, in this instance likely a huge number of images labelled as containing a banana or an apple.
Data, and lots of it, is the key to making machine learning possible.
Keeping data flowing could soon cost billions, business warned
10 tech predictions that could mean huge changes ahead
This powerful new supercomputer will let scientists ask ‘the right questions’
The algorithms are watching us, but who is watching the algorithms?
What is the difference between AI and machine learning?
artificial intelligence
How I used ChatGPT and AI art tools to launch my Etsy business fast
ChatGPT and the new AI are wreaking havoc on cybersecurity in exciting and frightening ways
Is this the snarkiest AI chatbot so far? I tried HuggingChat and it was weird
Meet the post-AI developer: More creative, more business-focused
Machine learning may have enjoyed enormous success of late, but it is just one method for achieving artificial intelligence.
At the birth of the field of AI in the 1950s, AI was defined as any machine capable of performing a task that would typically require human intelligence.
SEE: Managing AI and ML in the enterprise 2020: Tech leaders increase project development and implementation (TechRepublic Premium)
AI systems will generally demonstrate at least some of the following traits: planning, learning, reasoning, problem solving, knowledge representation, perception, motion, and manipulation and, to a lesser extent, social intelligence and creativity.
Alongside machine learning, there are various other approaches used to build AI systems, including evolutionary computation, where algorithms undergo random mutations and combinations between generations in an attempt to “evolve” optimal solutions, and expert systems, where computers are programmed with rules that allow them to mimic the behavior of a human expert in a specific domain, for example an autopilot system flying a plane.
What are the main types of machine learning?
Machine learning is generally split into two main categories: supervised and unsupervised learning.
What is supervised learning?
This approach basically teaches machines by example.
During training for supervised learning, systems are exposed to large amounts of labelled data, for example images of handwritten figures annotated to indicate which number they correspond to. Given sufficient examples, a supervised-learning system would learn to recognize the clusters of pixels and shapes associated with each number and eventually be able to recognize handwritten numbers, able to reliably distinguish between the numbers 9 and 4 or 6 and 8.
However, training these systems typically requires huge amounts of labelled data, with some systems needing to be exposed to millions of examples to master a task.
As a result, the datasets used to train these systems can be vast, with Google’s Open Images Dataset having about nine million images, its labeled video repository YouTube-8M linking to seven million labeled videos and ImageNet, one of the early databases of this kind, having more than 14 million categorized images. The size of training datasets continues to grow, with Facebook announcing it had compiled 3.5 billion images publicly available on Instagram, using hashtags attached to each image as labels. Using one billion of these photos to train an image-recognition system yielded record levels of accuracy – of 85.4% – on ImageNet’s benchmark.
The laborious process of labeling the datasets used in training is often carried out using crowdworking services, such as Amazon Mechanical Turk, which provides access to a large pool of low-cost labor spread across the globe. For instance, ImageNet was put together over two years by nearly 50,000 people, mainly recruited through Amazon Mechanical Turk. However, Facebook’s approach of using publicly available data to train systems could provide an alternative way of training systems using billion-strong datasets without the overhead of manual labeling.
Explainable AI: From the peak of inflated expectations to the pitfalls of interpreting machine learning models
What is AI? Everything you need to know about Artificial Intelligence
How machine learning can be used to catch a hacker (TechRepublic)
Scientists built this Raspberry Pi-powered, 3D-printed robot-lab to study flies
What is unsupervised learning?
In contrast, unsupervised learning tasks algorithms with identifying patterns in data, trying to spot similarities that split that data into categories.
An example might be Airbnb clustering together houses available to rent by neighborhood, or Google News grouping together stories on similar topics each day.
Unsupervised learning algorithms aren’t designed to single out specific types of data, they simply look for data that can be grouped by similarities, or for anomalies that stand out.
What is semi-supervised learning?
The importance of huge sets of labelled data for training machine-learning systems may diminish over time, due to the rise of semi-supervised learning.
As the name suggests, the approach mixes supervised and unsupervised learning. The technique relies upon using a small amount of labelled data and a large amount of unlabelled data to train systems. The labelled data is used to partially train a machine-learning model, and then that partially trained model is used to label the unlabelled data, a process called pseudo-labelling. The model is then trained on the resulting mix of the labelled and pseudo-labelled data.
SEE: What is AI? Everything you need to know about Artificial Intelligence
The viability of semi-supervised learning has been boosted recently by Generative Adversarial Networks (GANs), machine-learning systems that can use labelled data to generate completely new data, which in turn can be used to help train a machine-learning model.
Were semi-supervised learning to become as effective as supervised learning, then access to huge amounts of computing power may end up being more important for successfully training machine-learning systems than access to large, labelled datasets.
What is reinforcement learning?
A way to understand reinforcement learning is to think about how someone might learn to play an old-school computer game for the first time, when they aren’t familiar with the rules or how to control the game. While they may be a complete novice, eventually, by looking at the relationship between the buttons they press, what happens on screen and their in-game score, their performance will get better and better.
An example of reinforcement learning is Google DeepMind’s Deep Q-network, which has beaten humans in a wide range of vintage video games. The system is fed pixels from each game and determines various information about the state of the game, such as the distance between objects on screen. It then considers how the state of the game and the actions it performs in game relate to the score it achieves.
Over the process of many cycles of playing the game, eventually the system builds a model of which actions will maximize the score in which circumstance, for instance, in the case of the video game Breakout, where the paddle should be moved to in order to intercept the ball.
How does supervised machine learning work?
Everything begins with training a machine-learning model, a mathematical function capable of repeatedly modifying how it operates until it can make accurate predictions when given fresh data.
Before training begins, you first have to choose which data to gather and decide which features of the data are important.
A hugely simplified example of what data features are is given in this explainer by Google, where a machine-learning model is trained to recognize the difference between beer and wine, based on two features, the drinks’ color and their alcoholic volume (ABV).
cloud
What is digital transformation? Everything you need to know
The best cloud providers compared: AWS, Azure, Google Cloud, and more
The top 6 cheap web hosting services: Find an affordable option
What is cloud computing? Here’s everything you need to know
Each drink is labelled as a beer or a wine, and then the relevant data is collected, using a spectrometer to measure their color and a hydrometer to measure their alcohol content.
An important point to note is that the data has to be balanced, in this instance to have a roughly equal number of examples of beer and wine.
SEE: Guide to Becoming a Digital Transformation Champion(TechRepublic Premium)
The gathered data is then split, into a larger proportion for training, say about 70%, and a smaller proportion for evaluation, say the remaining 30%. This evaluation data allows the trained model to be tested, to see how well it is likely to perform on real-world data.
Before training gets underway there will generally also be a data-preparation step, during which processes such as deduplication, normalization and error correction will be carried out.
The next step will be choosing an appropriate machine-learning model from the wide variety available. Each have strengths and weaknesses depending on the type of data, for example some are suited to handling images, some to text, and some to purely numerical data.
Predictions made using supervised learning are split into two main types, classification, where the model is labelling data as predefined classes, for example identifying emails as spam or not spam, and regression, where the model is predicting some continuous value, such as house prices.
Getting there: Structured data, semantics, robotics, and the future of AI
Blockchain aims to solve AI ethics and bias issues
Who’s the greatest golfer of all time? This data-led project might have the answer
Facebook is creating a network filled with bad bots to help it understand real scammers
How does supervised machine-learning training work?
Basically, the training process involves the machine-learning model automatically tweaking how it functions until it can make accurate predictions from data, in the Google example, correctly labeling a drink as beer or wine when the model is given a drink’s color and ABV.
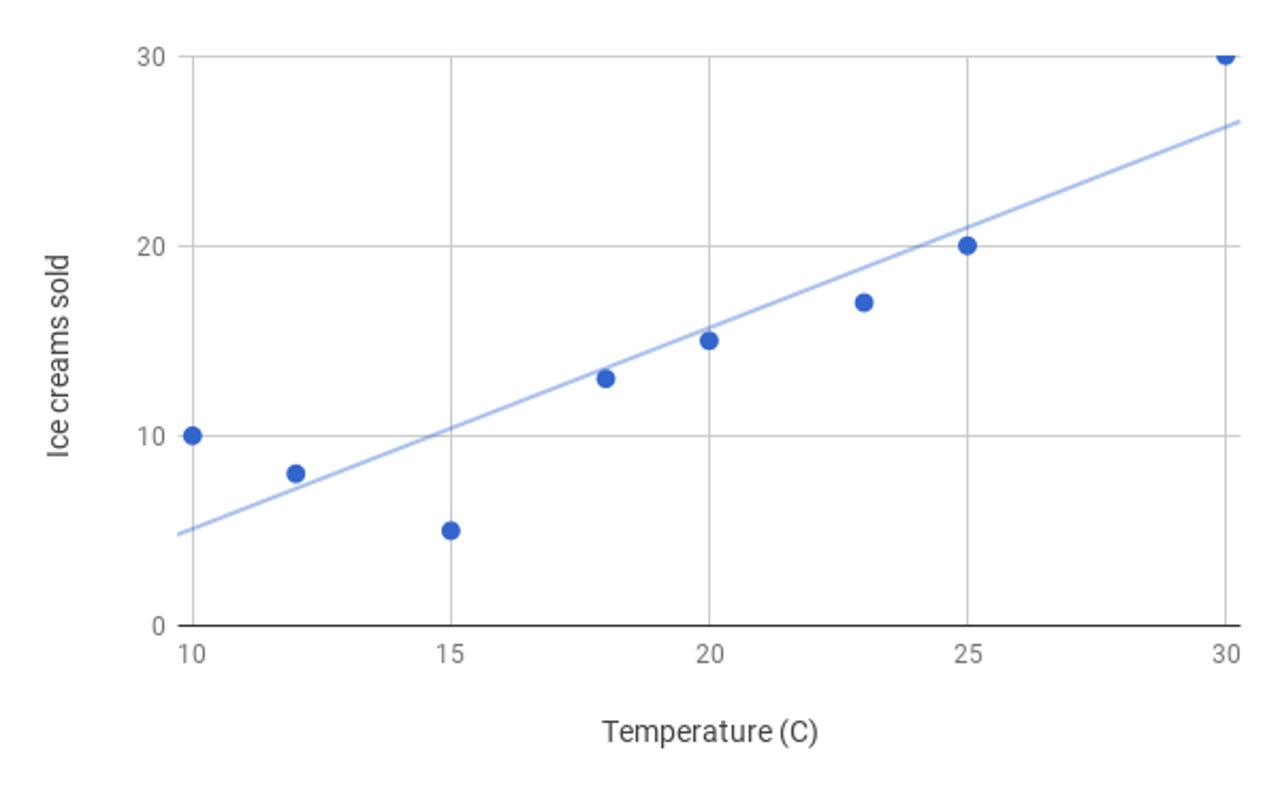
A good way to explain the training process is to consider an example using a simple machine-learning model, known as linear regression with gradient descent. In the following example, the model is used to estimate how many ice creams will be sold based on the outside temperature.
Imagine taking past data showing ice cream sales and outside temperature, and plotting that data against each other on a scatter graph – basically creating a scattering of discrete points.
To predict how many ice creams will be sold in future based on the outdoor temperature, you can draw a line that passes through the middle of all these points, similar to the illustration below.
Image: Nick Heath / ZDNet
Once this is done, ice cream sales can be predicted at any temperature by finding the point at which the line passes through a particular temperature and reading off the corresponding sales at that point.
Bringing it back to training a machine-learning model, in this instance training a linear regression model would involve adjusting the vertical position and slope of the line until it lies in the middle of all of the points on the scatter graph.
At each step of the training process, the vertical distance of each of these points from the line is measured. If a change in slope or position of the line results in the distance to these points increasing, then the slope or position of the line is changed in the opposite direction, and a new measurement is taken.
In this way, via many tiny adjustments to the slope and the position of the line, the line will keep moving until it eventually settles in a position which is a good fit for the distribution of all these points. Once this training process is complete, the line can be used to make accurate predictions for how temperature will affect ice cream sales, and the machine-learning model can be said to have been trained.
While training for more complex machine-learning models such as neural networks differs in several respects, it is similar in that it can also use a gradient descent approach, where the value of “weights”, variables that are combined with the input data to generate output values, are repeatedly tweaked until the output values produced by the model are as close as possible to what is desired.
Machine learning vs payment fraud: Transparency and humans in the loop to minimize customer insults
Deep learning godfathers Bengio, Hinton, and LeCun say the field can fix its flaws
To master artificial intelligence, don’t forget people and process
How Adobe moves AI, machine learning research to the product pipeline
How do you evaluate machine-learning models?
Once training of the model is complete, the model is evaluated using the remaining data that wasn’t used during training, helping to gauge its real-world performance.
When training a machine-learning model, typically about 60% of a dataset is used for training. A further 20% of the data is used to validate the predictions made by the model and adjust additional parameters that optimize the model’s output. This fine tuning is designed to boost the accuracy of the model’s prediction when presented with new data.
For example, one of those parameters whose value is adjusted during this validation process might be related to a process called regularisation. Regularisation adjusts the output of the model so the relative importance of the training data in deciding the model’s output is reduced. Doing so helps reduce overfitting, a problem that can arise when training a model. Overfitting occurs when the model produces highly accurate predictions when fed its original training data but is unable to get close to that level of accuracy when presented with new data, limiting its real-world use. This problem is due to the model having been trained to make predictions that are too closely tied to patterns in the original training data, limiting the model’s ability to generalise its predictions to new data. A converse problem is underfitting, where the machine-learning model fails to adequately capture patterns found within the training data, limiting its accuracy in general.
The final 20% of the dataset is then used to test the output of the trained and tuned model, to check the model’s predictions remain accurate when presented with new data.
Why is domain knowledge important?
Another important decision when training a machine-learning model is which data to train the model on. For example, if you were trying to build a model to predict whether a piece of fruit was rotten you would need more information than simply how long it had been since the fruit was picked. You’d also benefit from knowing data related to changes in the color of that fruit as it rots and the temperature the fruit had been stored at. Knowing which data is important to making accurate predictions is crucial. That’s why domain experts are often used when gathering training data, as these experts will understand the type of data needed to make sound predictions.
What are neural networks and how are they trained?
A very important group of algorithms for both supervised and unsupervised machine learning are neural networks. These underlie much of machine learning, and while simple models like linear regression used can be used to make predictions based on a small number of data features, as in the Google example with beer and wine, neural networks are useful when dealing with large sets of data with many features.
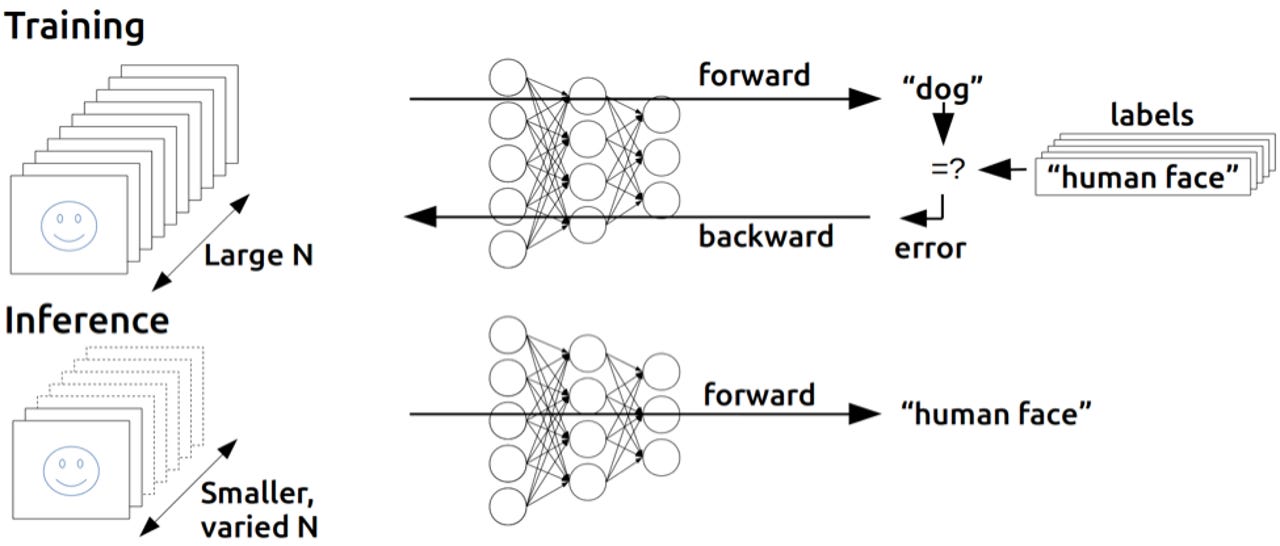
Neural networks, whose structure is loosely inspired by that of the brain, are interconnected layers of algorithms, called neurons, which feed data into each other, with the output of the preceding layer being the input of the subsequent layer.
Each layer can be thought of as recognizing different features of the overall data. For instance, consider the example of using machine learning to recognize handwritten numbers between 0 and 9. The first layer in the neural network might measure the intensity of the individual pixels in the image, the second layer could spot shapes, such as lines and curves, and the final layer might classify that handwritten figure as a number between 0 and 9.
SEE:Special report: How to implement AI and machine learning
The network learns how to recognize the pixels that form the shape of the numbers during the training process, by gradually tweaking the importance of data as it flows between the layers of the network. This is possible due to each link between layers having an attached weight, whose value can be increased or decreased to alter that link’s significance. At the end of each training cycle the system will examine whether the neural network’s final output is getting closer or further away from what is desired – for instance, is the network getting better or worse at identifying a handwritten number 6. To close the gap between between the actual output and desired output, the system will then work backwards through the neural network, altering the weights attached to all of these links between layers, as well as an associated value called bias. This process is called back-propagation.
Eventually this process will settle on values for these weights and the bias that will allow the network to reliably perform a given task, such as recognizing handwritten numbers, and the network can be said to have “learned” how to carry out a specific task.
An illustration of the structure of a neural network and how training works.Image: Nvidia
What is deep learning and what are deep neural networks?
A subset of machine learning is deep learning, where neural networks are expanded into sprawling networks with a large number of layers containing many units that are trained using massive amounts of data. It is these deep neural networks that have fuelled the current leap forward in the ability of computers to carry out task like speech recognition and computer vision.
There are various types of neural networks, with different strengths and weaknesses. Recurrent neural networks are a type of neural net particularly well suited to language processing and speech recognition, while convolutional neural networks are more commonly used in image recognition. The design of neural networks is also evolving, with researchers recently devising a more efficient design for an effective type of deep neural network called long short-term memory or LSTM, allowing it to operate fast enough to be used in on-demand systems like Google Translate.
The AI technique of evolutionary algorithms is even being used to optimize neural networks, thanks to a process called neuroevolution. The approach was showcased by Uber AI Labs, which released papers on using genetic algorithms to train deep neural networks for reinforcement learning problems.
What should the world look like? Some neural nets have their own answer, find researchers
As AI pops up in more and more scientific computing, a new time test measures how fast a neural net can be trained
Neural network trained to control anesthetic doses, keep patients under during surgery
The state of AI in 2020: Biology and healthcare’s AI moment, ethics, predictions, and graph neural networks
Is machine learning carried out solely using neural networks?
Not at all. There are an array of mathematical models that can be used to train a system to make predictions.
A simple model is logistic regression, which despite the name is typically used to classify data, for example spam vs not spam. Logistic regression is straightforward to implement and train when carrying out simple binary classification, and can be extended to label more than two classes.
Another common model type are Support Vector Machines (SVMs), which are widely used to classify data and make predictions via regression. SVMs can separate data into classes, even if the plotted data is jumbled together in such a way that it appears difficult to pull apart into distinct classes. To achieve this, SVMs perform a mathematical operation called the kernel trick, which maps data points to new values, such that they can be cleanly separated into classes.
The choice of which machine-learning model to use is typically based on many factors, such as the size and the number of features in the dataset, with each model having pros and cons.
Why is machine learning so successful?
While machine learning is not a new technique, interest in the field has exploded in recent years.
This resurgence follows a series of breakthroughs, with deep learning setting new records for accuracy in areas such as speech and language recognition, and computer vision.
What’s made these successes possible are primarily two factors; one is the vast quantities of images, speech, video and text available to train machine-learning systems.
But even more important has been the advent of vast amounts of parallel-processing power, courtesy of modern graphics processing units (GPUs), which can be clustered together to form machine-learning powerhouses.
Today anyone with an internet connection can use these clusters to train machine-learning models, via cloud services provided by firms like Amazon, Google and Microsoft.
As the use of machine learning has taken off, so companies are now creating specialized hardware tailored to running and training machine-learning models. An example of one of these custom chips is Google’s Tensor Processing Unit (TPU), which accelerates the rate at which machine-learning models built using Google’s TensorFlow software library can infer information from data, as well as the rate at which these models can be trained.
These chips are not just used to train models for Google DeepMind and Google Brain, but also the models that underpin Google Translate and the image recognition in Google Photo, as well as services that allow the public to build machine learning models using Google’s TensorFlow Research Cloud. The third generation of these chips was unveiled at Google’s I/O conference in May 2018, and have since been packaged into machine-learning powerhouses called pods that can carry out more than one hundred thousand trillion floating-point operations per second (100 petaflops).
In 2020, Google said its fourth-generation TPUs were 2.7 times faster than previous gen TPUs in MLPerf, a benchmark which measures how fast a system can carry out inference using a trained ML model. These ongoing TPU upgrades have allowed Google to improve its services built on top of machine-learning models, for instance halving the time taken to train models used in Google Translate.
As hardware becomes increasingly specialized and machine-learning software frameworks are refined, it’s becoming increasingly common for ML tasks to be carried out on consumer-grade phones and computers, rather than in cloud datacenters. In the summer of 2018, Google took a step towards offering the same quality of automated translation on phones that are offline as is available online, by rolling out local neural machine translation for 59 languages to the Google Translate app for iOS and Android.
The great data science hope: Machine learning can cure your terrible data hygiene
Machine learning as a service: Can privacy be taught?
Five ways your company can get started implementing AI and ML
Why AI and machine learning need to be part of your digital transformation plans
What is AlphaGo?
Perhaps the most famous demonstration of the efficacy of machine-learning systems is the 2016 triumph of the Google DeepMind AlphaGo AI over a human grandmaster in Go, a feat that wasn’t expected until 2026. Go is an ancient Chinese game whose complexity bamboozled computers for decades. Go has about 200 possible moves per turn, compared to about 20 in Chess. Over the course of a game of Go, there are so many possible moves that searching through each of them in advance to identify the best play is too costly from a computational standpoint. Instead, AlphaGo was trained how to play the game by taking moves played by human experts in 30 million Go games and feeding them into deep-learning neural networks.
Training the deep-learning networks needed can take a very long time, requiring vast amounts of data to be ingested and iterated over as the system gradually refines its model in order to achieve the best outcome.
big data
How to find out if you are involved in a data breach (and what to do next)
Fighting bias in AI starts with the data
Fair forecast? How 180 meteorologists are delivering ‘good enough’ weather data
Cancer therapies depend on dizzying amounts of data. Here’s how it’s sorted in the cloud
However, more recently Google refined the training process with AlphaGo Zero, a system that played “completely random” games against itself, and then learnt from the results. At the Neural Information Processing Systems (NIPS) conference in 2017, Google DeepMind CEO Demis Hassabis revealed AlphaZero, a generalized version of AlphaGo Zero, had also mastered the games of chess and shogi.
SEE: Tableau business analytics platform: A cheat sheet (TechRepublic)
DeepMind continue to break new ground in the field of machine learning. In July 2018, DeepMind reported that its AI agents had taught themselves how to play the 1999 multiplayer 3D first-person shooter Quake III Arena, well enough to beat teams of human players. These agents learned how to play the game using no more information than available to the human players, with their only input being the pixels on the screen as they tried out random actions in game, and feedback on their performance during each game.
More recently DeepMind demonstrated an AI agent capable of superhuman performance across multiple classic Atari games, an improvement over earlier approaches where each AI agent could only perform well at a single game. DeepMind researchers say these general capabilities will be important if AI research is to tackle more complex real-world domains.
The most impressive application of DeepMind’s research came in late 2020, when it revealed AlphaFold 2, a system whose capabilities have been heralded as a landmark breakthrough for medical science.
AlphaFold 2 is an attention-based neural network that has the potential to significantly increase the pace of drug development and disease modelling. The system can map the 3D structure of proteins simply by analysing their building blocks, known as amino acids. In the Critical Assessment of protein Structure Prediction contest, AlphaFold 2 was able to determine the 3D structure of a protein with an accuracy rivalling crystallography, the gold standard for convincingly modelling proteins. However, while it takes months for crystallography to return results, AlphaFold 2 can accurately model protein structures in hours.
Pharma companies are counting on cloud computing and AI to make drug development faster and cheaper
DeepMind AI breakthrough in protein folding will accelerate medical discoveries
Google’s AlphaGo retires after beating Chinese Go champion
DeepMind AlphaGo Zero learns on its own without meatbag intervention
What is machine learning used for?
Machine learning systems are used all around us and today are a cornerstone of the modern internet.
Machine-learning systems are used to recommend which product you might want to buy next on Amazon or which video you might want to watch on Netflix.
Every Google search uses multiple machine-learning systems, to understand the language in your query through to personalizing your results, so fishing enthusiasts searching for “bass” aren’t inundated with results about guitars. Similarly Gmail’s spam and phishing-recognition systems use machine-learning trained models to keep your inbox clear of rogue messages.
One of the most obvious demonstrations of the power of machine learning are virtual assistants, such as Apple’s Siri, Amazon’s Alexa, the Google Assistant, and Microsoft Cortana.
Each relies heavily on machine learning to support their voice recognition and ability to understand natural language, as well as needing an immense corpus to draw upon to answer queries.
But beyond these very visible manifestations of machine learning, systems are starting to find a use in just about every industry. These exploitations include: computer vision for driverless cars, drones and delivery robots; speech and language recognition and synthesis for chatbots and service robots; facial recognition for surveillance in countries like China; helping radiologists to pick out tumors in x-rays, aiding researchers in spotting genetic sequences related to diseases and identifying molecules that could lead to more effective drugs in healthcare; allowing for predictive maintenance on infrastructure by analyzing IoT sensor data; underpinning the computer vision that makes the cashierless Amazon Go supermarket possible, offering reasonably accurate transcription and translation of speech for business meetings – the list goes on and on.
In 2020, OpenAI’s GPT-3 (Generative Pre-trained Transformer 3) made headlines for its ability to write like a human, about almost any topic you could think of.
GPT-3 is a neural network trained on billions of English language articles available on the open web and can generate articles and answers in response to text prompts. While at first glance it was often hard to distinguish between text generated by GPT-3 and a human, on closer inspection the system’s offerings didn’t always stand up to scrutiny.
Deep-learning could eventually pave the way for robots that can learn directly from humans, with researchers from Nvidia creating a deep-learning system designed to teach a robot to how to carry out a task, simply by observing that job being performed by a human.
What is GPT-3? Everything your business needs to know about OpenAI’s breakthrough AI language program
OpenAI’s gigantic GPT-3 hints at the limits of language models for AI
Startup uses AI and machine learning for real-time background checks
How ubiquitous AI will permeate everything we do without our knowledge
Are machine-learning systems objective?
As you’d expect, the choice and breadth of data used to train systems will influence the tasks they are suited to. There is growing concern over how machine-learning systems codify the human biases and societal inequities reflected in their training data.
For example, in 2016 Rachael Tatman, a National Science Foundation Graduate Research Fellow in the Linguistics Department at the University of Washington, found that Google’s speech-recognition system performed better for male voices than female ones when auto-captioning a sample of YouTube videos, a result she ascribed to ‘unbalanced training sets’ with a preponderance of male speakers.
Facial recognition systems have been shown to have greater difficultly correctly identifying women and people with darker skin. Questions about the ethics of using such intrusive and potentially biased systems for policing led to major tech companies temporarily halting sales of facial recognition systems to law enforcement.
In 2018, Amazon also scrapped a machine-learning recruitment tool that identified male applicants as preferable.
As machine-learning systems move into new areas, such as aiding medical diagnosis, the possibility of systems being skewed towards offering a better service or fairer treatment to particular groups of people is becoming more of a concern. Today research is ongoing into ways to offset bias in self-learning systems.
What about the environmental impact of machine learning?
The environmental impact of powering and cooling compute farms used to train and run machine-learning models was the subject of a paper by the World Economic Forum in 2018. One 2019 estimate was that the power required by machine-learning systems is doubling every 3.4 months.
As the size of models and the datasets used to train them grow, for example the recently released language prediction model GPT-3 is a sprawling neural network with some 175 billion parameters, so does concern over ML’s carbon footprint.
There are various factors to consider, training models requires vastly more energy than running them after training, but the cost of running trained models is also growing as demands for ML-powered services builds. There is also the counter argument that the predictive capabilities of machine learning could potentially have a significant positive impact in a number of key areas, from the environment to healthcare, as demonstrated by Google DeepMind’s AlphaFold 2.
Which are the best machine-learning courses?
A widely recommended course for beginners to teach themselves the fundamentals of machine learning is this free Stanford University and Coursera lecture series by AI expert and Google Brain founder Andrew Ng.
More recently Ng has released his Deep Learning Specialization course, which focuses on a broader range of machine-learning topics and uses, as well as different neural network architectures.
If you prefer to learn via a top-down approach, where you start by running trained machine-learning models and delve into their inner workings later, then fast.ai’s Practical Deep Learning for Coders is recommended, preferably for developers with a year’s Python experience according to fast.ai. Both courses have their strengths, with Ng’s course providing an overview of the theoretical underpinnings of machine learning, while fast.ai’s offering is centred around Python, a language widely used by machine-learning engineers and data scientists.
Another highly rated free online course, praised for both the breadth of its coverage and the quality of its teaching, is this EdX and Columbia University introduction to machine learning, although students do mention it requires a solid knowledge of math up to university level.
How do I get started with machine learning?
Technologies designed to allow developers to teach themselves about machine learning are increasingly common, from AWS’ deep-learning enabled camera DeepLens to Google’s Raspberry Pi-powered AIY kits.
Which services are available for machine learning?
All of the major cloud platforms – Amazon Web Services, Microsoft Azure and Google Cloud Platform – provide access to the hardware needed to train and run machine-learning models, with Google letting Cloud Platform users test out its Tensor Processing Units – custom chips whose design is optimized for training and running machine-learning models.
This cloud-based infrastructure includes the data stores needed to hold the vast amounts of training data, services to prepare that data for analysis, and visualization tools to display the results clearly.
Newer services even streamline the creation of custom machine-learning models, with Google offering a service that automates the creation of AI models, called Cloud AutoML. This drag-and-drop service builds custom image-recognition models and requires the user to have no machine-learning expertise, similar to Microsoft’s Azure Machine Learning Studio. In a similar vein, Amazon has its own AWS services designed to accelerate the process of training machine-learning models.
For data scientists, Google Cloud’s AI Platform is a managed machine-learning service that allows users to train, deploy and export custom machine-learning models based either on Google’s open-sourced TensorFlow ML framework or the open neural network framework Keras, and which can be used with the Python library sci-kit learn and XGBoost.
Database admins without a background in data science can use Google’s BigQueryML, a beta service that allows admins to call trained machine-learning models using SQL commands, allowing predictions to be made in database, which is simpler than exporting data to a separate machine learning and analytics environment.
For firms that don’t want to build their own machine-learning models, the cloud platforms also offer AI-powered, on-demand services – such as voice, vision, and language recognition.
Meanwhile IBM, alongside its more general on-demand offerings, is also attempting to sell sector-specific AI services aimed at everything from healthcare to retail, grouping these offerings together under its IBM Watson umbrella.
Early in 2018, Google expanded its machine-learning driven services to the world of advertising, releasing a suite of tools for making more effective ads, both digital and physical.
While Apple doesn’t enjoy the same reputation for cutting-edge speech recognition, natural language processing and computer vision as Google and Amazon, it is investing in improving its AI services, with Google’s former chief of machine learning in charge of AI strategy across Apple, including the development of its assistant Siri and its on-demand machine learning service Core ML.
In September 2018, NVIDIA launched a combined hardware and software platform designed to be installed in datacenters that can accelerate the rate at which trained machine-learning models can carry out voice, video and image recognition, as well as other ML-related services.
The NVIDIA TensorRT Hyperscale Inference Platform uses NVIDIA Tesla T4 GPUs, which delivers up to 40x the performance of CPUs when using machine-learning models to make inferences from data, and the TensorRT software platform, which is designed to optimize the performance of trained neural networks.
Amazon AWS unveils RedShift ML to ‘bring machine learning to more builders’
Microsoft releases preview of Lobe training app for machine-learning
IBM hopes to power US Open’s digital experiences with Watson’s natural language processing
Informatica buys AI startup for entity and schema matching
Which software libraries are available for getting started with machine learning?
There are a wide variety of software frameworks for getting started with training and running machine-learning models, typically for the programming languages Python, R, C++, Java and MATLAB, with Python and R being the most widely used in the field.
Famous examples include Google’s TensorFlow, the open-source library Keras, the Python library scikit-learn, the deep-learning framework CAFFE and the machine-learning library Torch.