What is machine learning?
Machine learning (ML) is a type of artificial intelligence (AI) that allows software applications to become more accurate at predicting outcomes without being explicitly programmed to do so. Machine learning algorithms use historical data as input to predict new output values.
Recommendation engines are a common use case for machine learning. Other popular uses include fraud detection, spam filtering, malware threat detection, business process automation (BPA) and Predictive maintenance.
Why is machine learning important?
Machine learning is important because it gives enterprises a view of trends in customer behavior and business operational patterns, as well as supports the development of new products. Many of today’s leading companies, such as Facebook, Google and Uber, make machine learning a central part of their operations. Machine learning has become a significant competitive differentiator for many companies.
What are the different types of machine learning?
Classical machine learning is often categorized by how an algorithm learns to become more accurate in its predictions. There are four basic approaches:supervised learning, unsupervised learning, semi-supervised learning and reinforcement learning. The type of algorithm data scientists choose to use depends on what type of data they want to predict.
Supervised learning: In this type of machine learning, data scientists supply algorithms with labeled training data and define the variables they want the algorithm to assess for correlations. Both the input and the output of the algorithm is specified.
Unsupervised learning: This type of machine learning involves algorithms that train on unlabeled data. The algorithm scans through data sets looking for any meaningful connection. The data that algorithms train on as well as the predictions or recommendations they output are predetermined.
Semi-supervised learning: This approach to machine learning involves a mix of the two preceding types. Data scientists may feed an algorithm mostly labeled training data, but the model is free to explore the data on its own and develop its own understanding of the data set.
Reinforcement learning: Data scientists typically use reinforcement learning to teach a machine to complete a multi-step process for which there are clearly defined rules. Data scientists program an algorithm to complete a task and give it positive or negative cues as it works out how to complete a task. But for the most part, the algorithm decides on its own what steps to take along the way.
How does supervised machine learning work?
Supervised machine learning requires the data scientist to train the algorithm with both labeled inputs and desired outputs. Supervised learning algorithms are good for the following tasks:
Binary classification: Dividing data into two categories.
Multi-class classification: Choosing between more than two types of answers.
Regression modeling: Predicting continuous values.
Ensembling: Combining the predictions of multiple machine learning models to produce an accurate prediction.
How does unsupervised machine learning work?
Unsupervised machine learning algorithms do not require data to be labeled. They sift through unlabeled data to look for patterns that can be used to group data points into subsets. Most types of deep learning, including neural networks, are unsupervised algorithms. Unsupervised learning algorithms are good for the following tasks:
Clustering: Splitting the dataset into groups based on similarity.
Anomaly detection: Identifying unusual data points in a data set.
Association mining: Identifying sets of items in a data set that frequently occur together.
Dimensionality reduction: Reducing the number of variables in a data set.
How does semi-supervised learning work?
Semi-supervised learning works by data scientists feeding a small amount of labeled training data to an algorithm. From this, the algorithm learns the dimensions of the data set, which it can then apply to new, unlabeled data. The performance of algorithms typically improves when they train on labeled data sets. But labeling data can be time consuming and expensive. Semi-supervised learning strikes a middle ground between the performance of supervised learning and the efficiency of unsupervised learning. Some areas where semi-supervised learning is used include:
- Machine translation: Teaching algorithms to translate language based on less than a full dictionary of words.
- Fraud detection: Identifying cases of fraud when you only have a few positive examples.
- Labelling data: Algorithms trained on small data sets can learn to apply data labels to larger sets automatically.
How does reinforcement learning work?
Reinforcement learning works by programming an algorithm with a distinct goal and a prescribed set of rules for accomplishing that goal. Data scientists also program the algorithm to seek positive rewards — which it receives when it performs an action that is beneficial toward the ultimate goal — and avoid punishments — which it receives when it performs an action that gets it farther away from its ultimate goal. Reinforcement learning is often used in areas such as:
- Robotics: Robots can learn to perform tasks the physical world using this technique.
- Video gameplay: Reinforcement learning has been used to teach bots to play a number of video games.
- Resource management: Given finite resources and a defined goal, reinforcement learning can help enterprises plan out how to allocate resources.
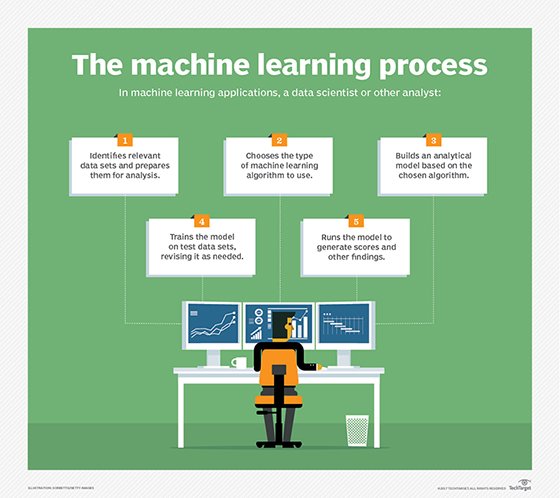
Who’s using machine learning and what’s it used for?
Today, machine learning is used in a wide range of applications. Perhaps one of the most well-known examples of machine learning in action is the recommendation engine that powers Facebook’s news feed.
Facebook uses machine learning to personalize how each member’s feed is delivered. If a member frequently stops to read a particular group’s posts, the recommendation engine will start to show more of that group’s activity earlier in the feed.
Behind the scenes, the engine is attempting to reinforce known patterns in the member’s online behavior. Should the member change patterns and fail to read posts from that group in the coming weeks, the news feed will adjust accordingly.
In addition to recommendation engines, other uses for machine learning include the following:
- Customer relationship management. CRM software can use machine learning models to analyze email and prompt sales team members to respond to the most important messages first. More advanced systems can even recommend potentially effective responses.
- Business intelligence. BI and analytics vendors use machine learning in their software to identify potentially important data points, patterns of data points and anomalies.
- Human resource information systems. HRIS systems can use machine learning models to filter through applications and identify the best candidates for an open position.
- Self-driving cars. Machine learning algorithms can even make it possible for a semi-autonomous car to recognize a partially visible object and alert the driver.
- Virtual assistants. Smart assistants typically combine supervised and unsupervised machine learning models to interpret natural speech and supply context.
What are the advantages and disadvantages of machine learning?
Machine learning has seen use cases ranging from predicting customer behavior to forming the operating system for self-driving cars.
When it comes to advantages, machine learning can help enterprises understand their customers at a deeper level. By collecting customer data and correlating it with behaviors over time, machine learning algorithms can learn associations and help teams tailor product development and marketing initiatives to customer demand.
Some companies use machine learning as a primary driver in their business models. Uber, for example, uses algorithms to match drivers with riders. Google uses machine learning to surface the ride advertisements in searches.
But machine learning comes with disadvantages. First and foremost, it can be expensive. Machine learning projects are typically driven by data scientists, who command high salaries. These projects also require software infrastructure that can be expensive.
There is also the problem of machine learning bias. Algorithms trained on data sets that exclude certain populations or contain errors can lead to inaccurate models of the world that, at best, fail and, at worst, are discriminatory. When an enterprise bases core business processes on biased models it can run into regulatory and reputational harm.
How to choose the right machine learning model
The process of choosing the right machine learning model to solve a problem can be time consuming if not approached strategically.
Step 1: Align the problem with potential data inputs that should be considered for the solution. This step requires help from data scientists and experts who have a deep understanding of the problem.
Step 2: Collect data, format it and label the data if necessary. This step is typically led by data scientists, with help from data wranglers.
Step 3: Chose which algorithm(s) to use and test to see how well they perform. This step is usually carried out by data scientists.
Step 4: Continue to fine tune outputs until they reach an acceptable level of accuracy. This step is usually carried out by data scientists with feedback from experts who have a deep understanding of the problem.
Importance of human interpretable machine learning
Explaining how a specific ML model works can be challenging when the model is complex. There are some vertical industries where data scientists have to use simple machine learning models because it’s important for the business to explain how every decision was made. This is especially true in industries with heavy compliance burdens such as banking and insurance.
Complex models can produce accurate predictions, but explaining to a lay person how an output was determined can be difficult.
What is the future of machine learning?
While machine learning algorithms have been around for decades, they’ve attained new popularity as artificial intelligence has grown in prominence. Deep learning models, in particular, power today’s most advanced AI applications.
Machine learning platforms are among enterprise technology’s most competitive realms, with most major vendors, including Amazon, Google, Microsoft, IBM and others, racing to sign customers up for platform services that cover the spectrum of machine learning activities, including data collection, data preparation, data classification, model building, training and application deployment.
As machine learning continues to increase in importance to business operations and AI becomes more practical in enterprise settings, the machine learning platform wars will only intensify.
Continued research into deep learning and AI is increasingly focused on developing more general applications. Today’s AI models require extensive training in order to produce an algorithm that is highly optimized to perform one task. But some researchers are exploring ways to make models more flexible and are seeking techniques that allow a machine to apply context learned from one task to future, different tasks.
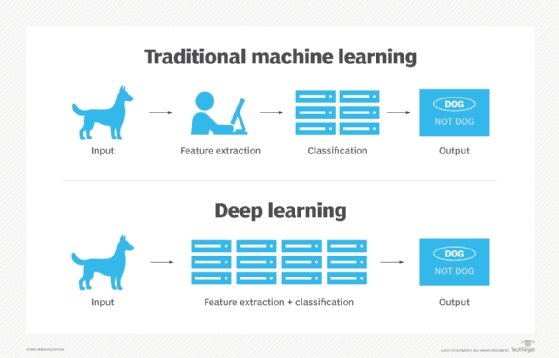
How has machine learning evolved?
1642 – Blaise Pascal invents a mechanical machine that can add, subtract, multiply and divide.
1679 – Gottfried Wilhelm Leibniz devises the system of binary code.
1834 – Charles Babbage conceives the idea for a general all-purpose device that could be programmed with punched cards.
1842 – Ada Lovelace describes a sequence of operations for solving mathematical problems using Charles Babbage’s theoretical punch-card machine and becomes the first programmer.
1847 – George Boole creates Boolean logic, a form of algebra in which all values can be reduced to the binary values of true or false.
1936 – English logician and cryptanalyst Alan Turing proposes a universal machine that could decipher and execute a set of instructions. His published proof is considered the basis of computer science.
1952 – Arthur Samuel creates a program to help an IBM computer get better at checkers the more it plays.
1959 – MADALINE becomes the first artificial neural network applied to a real-world problem: removing echoes from phone lines.
1985 – Terry Sejnowski’s and Charles Rosenberg’s artificial neural network taught itself how to correctly pronounce 20,000 words in one week.
1997 – IBM’s Deep Blue beat chess grandmaster Garry Kasparov.
1999 – A CAD prototype intelligent workstation reviewed 22,000 mammograms and detected cancer 52% more accurately than radiologists did.
2006 – Computer scientist Geoffrey Hinton invents the term deep learning to describe neural net research.
2012 – An unsupervised neural network created by Google learned to recognize cats in YouTube videos with 74.8% accuracy.
2014 – A chatbot passes the Turing Test by convincing 33% of human judges that it was a Ukrainian teen named Eugene Goostman.
2014 – Google’s AlphaGo defeats the human champion in Go, the most difficult board game in the world.
2016 – LipNet, DeepMind’s artificial intelligence system, identifies lip-read words in video with an accuracy of 93.4%.
2019 – Amazon controls 70% of the market share for virtual assistants in the U.S.

This was last updated in March 2021