It is undeniably, machine learning and artificial intelligence have become immensely notorious over the past few years. Also, at the moment, big data is gaining notoriety in the tech industry where machine learning is amazingly powerful for delivering predictions or forecasting recommendations, relied on the huge amount of data.
What are Machine Learning Algorithms?
Being a subset of Artificial Intelligence, Machine Learning is the technique that trains computers/systems to work independently, without being programmed explicitly.
And, during this process of training and learning, various algorithms come into the picture, that helps such systems in order to train themselves in a superior way with time, are referred as Machine Learning Algorithms.
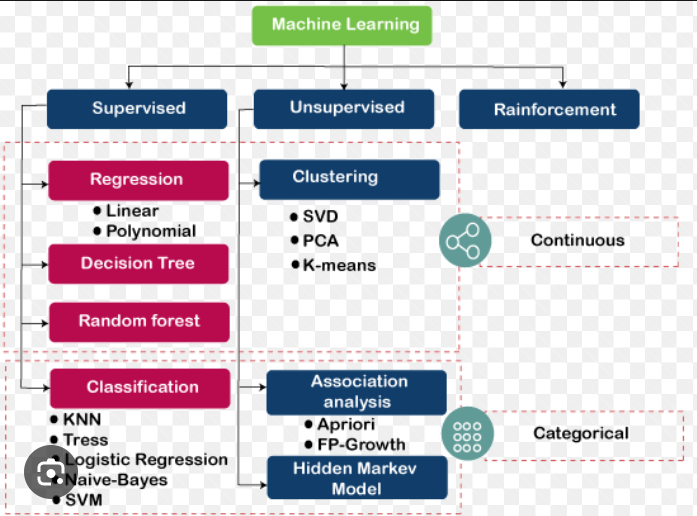
Machine learning algorithms work on the concept of three ubiquitous learning models: supervised learning, unsupervised learning, and reinforcement learning. These are essentially the types of machine learning;
- Supervised learning is deployed in cases where a label data is available for specific datasets and identifies patterns within values labels assigned to data points.
- Unsupervised learning is implemented in cases where the difficulty is to determine implicit connections in a given unlabeled dataset.
- Reinforcement learning selects an action, relied on each data point and after that learn how good the action was.
(Related blog: Fundamentals to Reinforcement Learning)
Machine Learning Algorithm
In the intense dynamic time, several machine learning algorithms have been developed in order to solve real-world problems; they are extremely automated and self-correcting as embracing the potential of improving over time while exploiting growing amounts of data and demanding minimal human intervention.
Let’s learn about some of the fascinating machine learning algorithms;
- Decision Tree
The decision tree is the decision supporting tool that practices a tree-like graph or model of decisions along with their feasible outcomes, like the chance-event outcome, resource costs and implementation.
Being a supervised learning algorithm, decision trees are the best choice for classifying both categorical and continuous dependent variables. In this algorithm, the population is split into two or more homogeneous datasets, relying on the most significant characteristics or independent variables.
Over the graphical representation of the decision tree, the internal node highlights a test on the attribute, each individual branch denotes the outcome of the test, and leaf node signifies a specific class label, therefore the decision is made after computing all the attributes.
Fundamentally, decision trees are of two types;
- Classification Trees– Accounted as the default kind of decision trees, classification trees are adapted to distinct the dataset into various classes on the basis of the response variable, and preferred when the response variable is categorical in nature.
- Regression Trees– In opposite to the classification tree, regression trees are chosen when the response or target variable is continuous or numerical in nature and adapted in predictive based problems.
- Naive Bayes Classifier
A Naive Bayes classifier believes that the appearance of a selective feature in a class is irrelevant to the appearance of any other feature. It considers all the properties independent while calculating the probability of a particular outcome, even if each feature are related to each other.
The model involves two types of probabilities
- Probability of each class, and
- Conditional Probability for each class, given each x value.
Both the probabilities can be measured directly from training data, once calculated, the probability model can be deployed for making predictions for new data via Bayes Theorem.
Some of the real-world cases of naive Bayes classifiers are to label an email as spam or not, to categorize a new article in technology, politics or sports group, to identify a text stating positive or negative emotions, and in face and voice recognition software.
- Ordinary Least Square Regression
Under statistics computation, Least Square is the method to perform linear regression. In order to establish the connection between a dependent variable and an independent variable, the ordinary least squares method is like- draw a straight line, later for each data point, calculate the vertical distance amidst the point and the line and summed these up.
The fitted line would be the one where the sum of distances is as small as possible. Least squares are referring to the sort of errors metric that are minimized.
- Linear Regression
Linear Regression describes the impact on the dependent variable while the independent variable gets altered, as a consequence an independent variable is known as the explanatory variable whereas the dependent variable is named as the factor of interest.
It shows the connection amid an independent and a dependent variable and deals with prediction/estimations in continuous values. E.g. it can be used for risk assessment in the insurance domain, to identify the number of applications for multiple ages users.
The linear regression can be described in terms of a best fit relationship among the input variable (x) and output variable (y) through identifying the specific weights for the input variables, named as coefficients (B), that is
y= B0 + B1*x
- Logistic Regression
Logistic regression is a powerful statistical tool of modelling a binomial outcome with one or more explanatory variables. It computes the association amid the categorical dependent variable and one or more independent variables through measuring probabilities by a logistic function (or cumulative logistics distribution).
The Logistic Regression Algorithm works for discrete values, it is well suitable for binary classification where if an event occurs successfully, it is classified as 1, and 0, if not. Therefore, the probability of occurring of a specific event is estimated in the basis of provided predictor variables.
It has the real world applications as;
- Credit scoring
- Estimating success rates of marketing campaigns
- Anticipating the revenues generated by a certain product or service.
- In politics, whether a particular candidate wins or loses the election.
- Support Vector Machines
In SVM, a hyperplane (a line that divides the input variable space) is selected to separate appropriately the data points across input variables space by their respective class either 0 or 1.
Basically, the SVM algorithm determines the coefficients that yield in the suitable separation of the various classes through the hyperplane, where the distance amid the hyperplane and the closest data points is referred to as the margin. However, the optimal hyperplane, that can depart the two classes, is the line that holds the largest margin.
Only such points are applicable in determining the hyperplane and the construction of the classifier and are termed as the support vectors as they support or define the hyperplane.
More specifically, SVM renders appropriate classification for classification problems upon the training data, and extra efficiency for accurate classification of the future and also doesn’t overfit the data.
SVM is greatly used for stock market forecasting, for instance, one can use it to check the relative performance of the one stocks when compared to the other stocks under the same market. Thereby, with the help of the relative comparison of stocks, one can manage investment and make decisions depending upon the classifications made by SVM algorithm.
- Clustering Algorithms
Being an unsupervised learning problem, clustering approach is used as a data analysis technique for identifying informative data patterns, such as groups of customers based on their behavior or locations. Clustering descibes a class of problem and a class of methods, take a look at Clustering Methods and Applications.
Clustering Algorithms refer to the group task of clustering, i.e. grouping an assemblage of objects in such a way that each object is more identical to each other under the same group (cluster) in comparison to those in separate groups.
There are various kinds of clustering algorithms that use similarity or distance measures amid examples in the feature space to find out dense regions of observations. Therefore, it is a good attempt to scale data previously for using clustering algorithms. However, each clustering algorithm is different, some of them are connectivity-based algorithms, dimensionality reduction, neural networks, probabilistic, etc.
- Gradient Boosting & AdaBoost
Boosting algorithms are used while dealing with massive quantities of data for making a prediction with great accuracy. It is an ensemble learning algorithm that integrates the predictive potential of diversified base estimators in order to enhance robustness, i.e. it blends the various vulnerable and mediocre predictors for developing strong predictor/estimator.
In simple terms, Boosting is the learning algorithm that makes an active classifier/predictor from a weak or average classifier. This process is achieved through creating a model from training data, and then constructing another second model in order to correct the errors from the first model. Also, until the training set is precisely predicted, models are added or until the maximum number of models are joined.
These algorithms usually fit well in data science competitions like Kaggle, Hackathons, etc. As treated most preferred ML algorithms, these can be used with Python and R programming for obtaining accurate outcomes.
AdaBoost was the first competitive boosting algorithm that was constructed for binary classification. It can be considered as the initial step for learning and understanding boosting. Most of the modern boosting methods are constructed over AdaBoost, preferably on stochastic gradient boosting machines.
The video below explains the AdaBoost which is just the simple twist on decision trees and random forests.
- Principal Component Analysis
Dimensionality reduction algorithms are among the most important algorithms in machine learning that can be used when a data has multiple dimensions.
Consider a dataset that has “n” dimension, for instance a data professionlist is working on financial data that has the attributes as a credit score, personal details, personnel salary, etc. Now, in order to understand the important labels for building a required model, he/she can use dimensionality reduction method, and PCA is the appropriate algorithm for reducing dimensions.
PCA is a statistical approach that deploys an orthogonal transformation for reforming an array of observations of likely correlated variables into a set of observations of linearly uncorrelated variables, is known as principal components.
Using PCA, one can decrease the quantity of dimensions while retaining the important labels of the model. Since PCA is heavily relied on the number of dimensions, each PCA is perpendicular to the other and their dot product is zero.
Its applications include analysing data for smooth learning, and visualization. Since all the components of PCA have a very high variance, it is not an appropriate approach for noisy data.
- Deep Learning Algorithms
Deep learning algorithms heavily rely on the nervous system of a human and are generally designed on the neural networks that use plentiful computational resources. All these algorithms use different types of neural networks to perform particular tasks.
They train computers by learning from examples and industries such as healthcare, eCommerce, entertainment, and advertising commonly use deep learning algorithms.
Since, the deep learning algorithms signify self-learning representations, they basically coin ton ANNs that reflect the way a human brain functions and computes information. While the training process starts, algorithms intakes unknown components as the input data for extracting out features, group objects, and find out useful and hidden data patterns.
These algorithms make use of several algorithms where no one single network is considered perfect and some algorithms are perfect fitted to perform specific tasks. However, in order to choose the correct ones, one should have a strong understanding of all primary algorithms
Some popular deep learning algorithms are Convolutional Neural Network (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory Networks (LSTM), etc.
Conclusion
From the above discussion, it can be concluded that Machine learning algorithms are programs/ models that learn from data and improve from experience regardless of the intervention of human being.
Google’s self-driving cars and robots get a lot of press, but the company’s real future is in machine learning, the technology that enables computers to get smarter and more personal. – Eric Schmidt (Google Chairman)
Some popular examples, where ML algorithms are being deployed, are Netflix’s algorithms that recommend movies based on the movies (or movie genre) we have watched in past, or Amazon’s algorithms that suggest an item, based on review or purchase history.