Understanding of traditional data management and analysis methods like SQL, data warehouses, business intelligence, OLAP, etc… Understanding of basic statistics and probability (mean, variance, probability, conditional probability, etc….)
Overview
Audience
If you try to make sense out of the data you have access to or want to analyse unstructured data available on the net (like Twitter, Linked in, etc…) this course is for you.
It is mostly aimed at decision makers and people who need to choose what data is worth collecting and what is worth analyzing.
It is not aimed at people configuring the solution, those people will benefit from the big picture though.
Delivery Mode
During the course delegates will be presented with working examples of mostly open source technologies.
Short lectures will be followed by presentation and simple exercises by the participants
Content and Software used
All software used is updated each time the course is run, so we check the newest versions possible.
It covers the process from obtaining, formatting, processing and analysing the data, to explain how to automate decision making process with machine learning.
Course Outline
Quick Overview
Data Sources
Minding Data
Recommender systems
Target Marketing
Datatypes
Structured vs unstructured
Static vs streamed
Attitudinal, behavioural and demographic data
Data-driven vs user-driven analytics
data validity
Volume, velocity and variety of data
Models
Building models
Statistical Models
Machine learning
Data Classification
Clustering
kGroups, k-means, the nearest neighbours
Ant colonies, birds flocking
Predictive Models
Decision trees
Support vector machine
Naive Bayes classification
Neural networks
Markov Model
Regression
Ensemble methods
ROI
Benefit/Cost ratio
Cost of software
Cost of development
Potential benefits
Building Models
Data Preparation (MapReduce)
Data cleansing
Choosing methods
Developing model
Testing Model
Model evaluation
Model deployment and integration
Overview of Open Source and commercial software
Selection of R-project package
Python libraries
Hadoop and Mahout
Selected Apache projects related to Big Data and Analytics
Selected commercial solution
Integration with existing software and data sources
Should have basic knowledge of business operation and data systems in Telecom in their domain
Must have basic understanding of SQL/Oracle or relational database
Basic understanding of Statistics (in Excel levels)
Overview
Overview
Communications service providers (CSP) are facing pressure to reduce costs and maximize average revenue per user (ARPU), while ensuring an excellent customer experience, but data volumes keep growing. Global mobile data traffic will grow at a compound annual growth rate (CAGR) of 78 percent to 2016, reaching 10.8 exabytes per month.
Meanwhile, CSPs are generating large volumes of data, including call detail records (CDR), network data and customer data. Companies that fully exploit this data gain a competitive edge. According to a recent survey by The Economist Intelligence Unit, companies that use data-directed decision-making enjoy a 5-6% boost in productivity. Yet 53% of companies leverage only half of their valuable data, and one-fourth of respondents noted that vast quantities of useful data go untapped. The data volumes are so high that manual analysis is impossible, and most legacy software systems can’t keep up, resulting in valuable data being discarded or ignored.
With Big Data & Analytics’ high-speed, scalable big data software, CSPs can mine all their data for better decision making in less time. Different Big Data products and techniques provide an end-to-end software platform for collecting, preparing, analyzing and presenting insights from big data. Application areas include network performance monitoring, fraud detection, customer churn detection and credit risk analysis. Big Data & Analytics products scale to handle terabytes of data but implementation of such tools need new kind of cloud based database system like Hadoop or massive scale parallel computing processor ( KPU etc.)
This course work on Big Data BI for Telco covers all the emerging new areas in which CSPs are investing for productivity gain and opening up new business revenue stream. The course will provide a complete 360 degree over view of Big Data BI in Telco so that decision makers and managers can have a very wide and comprehensive overview of possibilities of Big Data BI in Telco for productivity and revenue gain.
Course objectives
Main objective of the course is to introduce new Big Data business intelligence techniques in 4 sectors of Telecom Business (Marketing/Sales, Network Operation, Financial operation and Customer Relation Management). Students will be introduced to following:
Introduction to Big Data-what is 4Vs (volume, velocity, variety and veracity) in Big Data- Generation, extraction and management from Telco perspective
How Big Data analytic differs from legacy data analytic
In-house justification of Big Data -Telco perspective
Introduction to Hadoop Ecosystem- familiarity with all Hadoop tools like Hive, Pig, SPARC –when and how they are used to solve Big Data problem
How Big Data is extracted to analyze for analytics tool-how Business Analysis’s can reduce their pain points of collection and analysis of data through integrated Hadoop dashboard approach
Basic introduction of Insight analytics, visualization analytics and predictive analytics for Telco
Customer Churn analytic and Big Data-how Big Data analytic can reduce customer churn and customer dissatisfaction in Telco-case studies
Network failure and service failure analytics from Network meta-data and IPDR
Financial analysis-fraud, wastage and ROI estimation from sales and operational data
Customer acquisition problem-Target marketing, customer segmentation and cross-sale from sales data
Introduction and summary of all Big Data analytic products and where they fit into Telco analytic space
Conclusion-how to take step-by-step approach to introduce Big Data Business Intelligence in your organization
Target Audience
Network operation, Financial Managers, CRM managers and top IT managers in Telco CIO office.
Business Analysts in Telco
CFO office managers/analysts
Operational managers
QA managers
Course Outline
Breakdown of topics on daily basis: (Each session is 2 hours)
Day-1: Session -1: Business Overview of Why Big Data Business Intelligence in Telco.
Case Studies from T-Mobile, Verizon etc.
Big Data adaptation rate in North American Telco & and how they are aligning their future business model and operation around Big Data BI
Broad Scale Application Area
Network and Service management
Customer Churn Management
Data Integration & Dashboard visualization
Fraud management
Business Rule generation
Customer profiling
Localized Ad pushing
Day-1: Session-2 : Introduction of Big Data-1
Main characteristics of Big Data-volume, variety, velocity and veracity. MPP architecture for volume.
Data Warehouses – static schema, slowly evolving dataset
MPP Databases like Greenplum, Exadata, Teradata, Netezza, Vertica etc.
Hadoop Based Solutions – no conditions on structure of dataset.
Typical pattern : HDFS, MapReduce (crunch), retrieve from HDFS
Day-3 : Sesion-1 : Network Operation analytic- root cause analysis of network failures, service interruption from meta data, IPDR and CRM:
CPU Usage
Memory Usage
QoS Queue Usage
Device Temperature
Interface Error
IoS versions
Routing Events
Latency variations
Syslog analytics
Packet Loss
Load simulation
Topology inference
Performance Threshold
Device Traps
IPDR ( IP detailed record) collection and processing
Use of IPDR data for Subscriber Bandwidth consumption, Network interface utilization, modem status and diagnostic
HFC information
Day-3: Session-2: Tools for Network service failure analysis:
Network Summary Dashboard: monitor overall network deployments and track your organization’s key performance indicators
Peak Period Analysis Dashboard: understand the application and subscriber trends driving peak utilization, with location-specific granularity
Routing Efficiency Dashboard: control network costs and build business cases for capital projects with a complete understanding of interconnect and transit relationships
Real-Time Entertainment Dashboard: access metrics that matter, including video views, duration, and video quality of experience (QoE)
IPv6 Transition Dashboard: investigate the ongoing adoption of IPv6 on your network and gain insight into the applications and devices driving trends
Case-Study-1: The Alcatel-Lucent Big Network Analytics (BNA) Data Miner
Multi-dimensional mobile intelligence (m.IQ6)
Day-3 : Session 3: Big Data BI for Marketing/Sales –Understanding sales/marketing from Sales data: ( All of them will be shown with a live predictive analytic demo )
To identify highest velocity clients
To identify clients for a given products
To identify right set of products for a client ( Recommendation Engine)
Market segmentation technique
Cross-Sale and upsale technique
Client segmentation technique
Sales revenue forecasting technique
Day-3: Session 4: BI needed for Telco CFO office:
Overview of Business Analytics works needed in a CFO office
Risk analysis on new investment
Revenue, profit forecasting
New client acquisition forecasting
Loss forecasting
Fraud analytic on finances ( details next session )
Day-4 : Session-1: Fraud prevention BI from Big Data in Telco-Fraud analytic:
Bandwidth leakage / Bandwidth fraud
Vendor fraud/over charging for projects
Customer refund/claims frauds
Travel reimbursement frauds
Day-4 : Session-2: From Churning Prediction to Churn Prevention:
3 Types of Churn : Active/Deliberate , Rotational/Incidental, Passive Involuntary
3 classification of churned customers: Total, Hidden, Partial
Understanding CRM variables for churn
Customer behavior data collection
Customer perception data collection
Customer demographics data collection
Cleaning CRM Data
Unstructured CRM data ( customer call, tickets, emails) and their conversion to structured data for Churn analysis
Social Media CRM-new way to extract customer satisfaction index
Case Study-1 : T-Mobile USA: Churn Reduction by 50%
Day-4 : Session-3: How to use predictive analysis for root cause analysis of customer dis-satisfaction :
Case Study -1 : Linking dissatisfaction to issues – Accounting, Engineering failures like service interruption, poor bandwidth service
Case Study-2: Big Data QA dashboard to track customer satisfaction index from various parameters such as call escalations, criticality of issues, pending service interruption events etc.
Day-4: Session-4: Big Data Dashboard for quick accessibility of diverse data and display :
Integration of existing application platform with Big Data Dashboard
Big Data management
Case Study of Big Data Dashboard: Tableau and Pentaho
Use Big Data app to push location based Advertisement
Tracking system and management
Day-5 : Session-1: How to justify Big Data BI implementation within an organization:
Defining ROI for Big Data implementation
Case studies for saving Analyst Time for collection and preparation of Data –increase in productivity gain
Case studies of revenue gain from customer churn
Revenue gain from location based and other targeted Ad
An integrated spreadsheet approach to calculate approx. expense vs. Revenue gain/savings from Big Data implementation.
Day-5 : Session-2: Step by Step procedure to replace legacy data system to Big Data System:
Understanding practical Big Data Migration Roadmap
What are the important information needed before architecting a Big Data implementation
What are the different ways of calculating volume, velocity, variety and veracity of data
How to estimate data growth
Case studies in 2 Telco
Day-5: Session 3 & 4: Review of Big Data Vendors and review of their products. Q/A session:
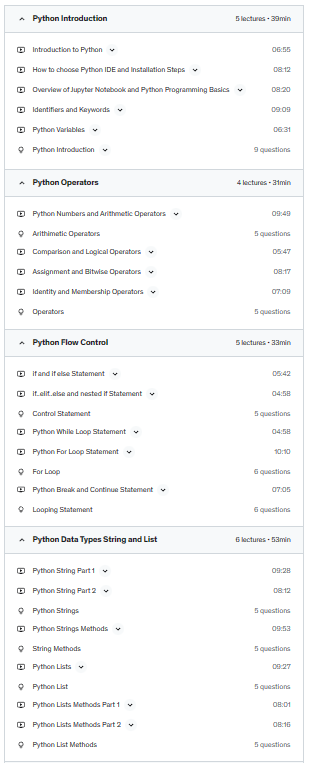
Introduction to Python: For absolute beginners: by Saima Aziz
Learn Python Fundamentals for data science: by Saima Aziz
Laptop or PC with Internet Connection
Motivation to learn
Description
Welcome to Data Analysis using Python. My name is Saima Aziz and I will be the instructor for this course. I have more than 25 years of teaching experience.
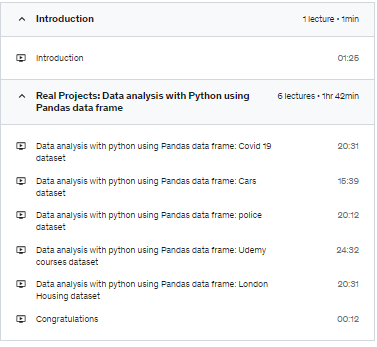
In this course, you will apply your coding skills to a wide range of datasets to solve real world projects using Pandas Data Frame, such as:
Covid-19 datasets,
London housing datasets,
Car datasets,
Police datasets,
Udemy courses datasets.
You will increase your chances of success in data science by experimenting with Python projects. That way, you’re learning by actually doing instead of just watching videos.
Building projects will help you tie together everything you are learning. Once you start building projects, you will immediately feel like you are making progress.
Where should I start? What makes a good project? What do I do when I get stuck?
I have carefully designed the content of the course to be comprehensive and fully compatible with industrial requirements and easy to understand.
If you get stuck, don’t give up! There is enough material in the course to help you solve the problems, and your hard work will pay off.
Who this course is for:
Those who are curious about data science and want to become data scientist.
Acquire the prerequisite Python skills to move into specific branches – Data Science(Machine Learning/Deep Learning) , Big Data , Automation Testing, Web development etc..
Have the skills and understanding of Python to confidently apply for Python programming jobs.
Requirements
Passion to learn alone is enough to start this course
A Laptop/Computer- Windows, Mac, and Linux are all supported. Setup and installation instructions are included in the video course
Access to the internet. Of course all the videos are downloadable . You can study in offline mode also.
Recommended : Laptop/Computer the best way to learn this course. Because after completing each topic , practicing it simultaneously in Jupyter notebook makes you to remember each topic easily
Description
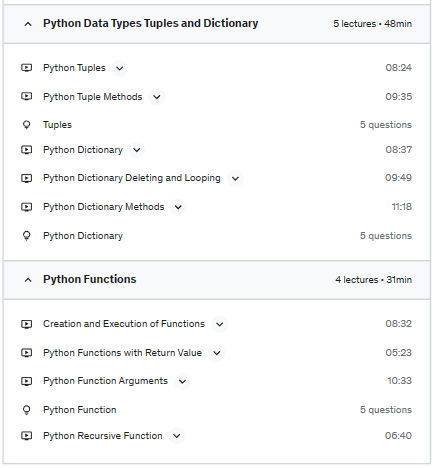
This course specifically created for A.I Aspirants ( Data Science/Deep Learning/Machine Learning students). It covers all the PYTHON BASICS topics. But still this course can also be learnt by other fields aspirants like Automation, Chatbots, WebDevelopers etc. Because for all the fields this course will create basic knowledge and with this you can self learn python library easily.
Note: Very soon Python Libraries such as NumPy, Pandas and Matplotlib courses will be launched. But for all these advanced course , this “Python For Data Science” course will be the basement for it.
” 9 main reasons to Learn Python !!! “
1. Python’s popularity
When compared to all other programming language, python is extremely simple, easy to learn, interpret and implement. Due to this reason it became very popular and trending programming right now.
2. High salary
The job demand for python programmers are high. Python engineers have some of the highest salaries in the industry.
The average Python developer salary in the US is $110,021 and $123,743 per year according to the survey conducted by Gooroo and Indeed respectively
3. Python is used in Data Science
There are plenty of Python scientific packages for data visualization, machine learning, natural language processing, complex data analysis and more. All of these factors make Python a great tool for scientific computing and a solid alternative for commercial packages such as MatLab. The most popular libraries and tools for data science are Pandas, matplotlib, NumPy, scikit-learn, Mlpy, NetworkX, Theano, SymPy and TensorFlow
4. Python is used in Automation
IT industries are now moving towards Artificial Intelligence in Automation. So Python with Robot framework combination is the best alternative for Selenium Webdriver with Java as it is easier road map with no programming background.
5. Python used with Big Data
Pydoop is a Python interface to Hadoop that allows you to write a MapReduce program in Python and process data present in the HDFS cluster.
Its features such as a rich HDFS API; a MapReduce API that allows to write pure Python record readers / writers, partitioners and combiners, transparent Avro (de)serialization, and easy installation-free usage.
6. Chat Bots
A chat bot is an artificial intelligence-powered piece of software in a device (Siri, Alexa, Google Assistant etc), application, website or other networks that try to gauge consumer’s needs and then assist them to perform a particular task like a commercial transaction, hotel booking, form submission etc.
NLTK(Natural Language Toolkit) library is a leading platform for building Python programs to work with human language data.
7. Python in Web Development
Python has a wide range of frameworks for developing websites. The most popular frameworks are Django, Flask, Web2Py, Turbo Gears, etc. These frameworks are written in Python, so it’s easier to implement and use it for web development.
8. Computer Graphics in Python
Python is largely used to build GUI and desktop applications. The Python Computer Graphics Kit is a generic 3D package that can be useful in any domain where you have to deal with 3D data of any kind, be it for visualization, creating photorealistic images, Virtual Reality or even games
9. Game Developer
Python libraries such as PyGame, Pyglet , PyOpenGL etc. are used to develop 2D, 3D games with easy coding. Learning any one of these package can able to create rapid game prototyping or for beginners learning how to make simple games.
Who this course is for:
Data Science / Artificial Intelligence/ Machine Learning / Deep Learning Aspirants
Chat Bots Developer
Automation Testers
Big Data Aspirants
Web Development Aspirants
Game Developers
People interested in programming who have no prior programming experience
Anyone who wants to learn BASIC PYTHON
Existing programmers who want to improve their career options by learning the Python programming language
Students taking a Python class in school who want a supplementary learning source
Note 1 : SPECIFICALLY CREATED FOR DATA SCIENCE / AI / ML / DL ASPIRANTS AND COVERS BASICS PYTHON ONLY
Note 2: This course is NOT for experienced Python programmers
Note 3: All the videos are explained in Indian English Slang. In case if you think, its tough to understand my pronunciation and also for Non-English speaking students, I enabled the Auto Caption now. But still the text won’t 100% accurate.
Note 4: Based on students interest and request , I will be adding few more python topics to this course
Understanding how AI, Big Data, IoT and Cloud Computing is working together to build Metaverses.
Requirements
This is good for anyone who wishes to understand the basics of how new age technology is wrapped around our day to day lives.
Description
As organizations adopt new ways of working in the Covid era, there is a growing dependency on technology to smoothly transition into a Post-Covid era of work. Tech-based solutions towards making individuals safe and organizations secure have emerged, and continue to adapt to evolving situations across the globe. Then there are solutions that promise to optimize the use of real estate and building services. However, organizations need to tread with caution and not resort to ‘off-the-shelf’ buying when it comes to such new-age solutions. Solutions need to support organizational goals and be integrated with the organizations’ vision and respective post-Covid strategy thereof.
Most of the solutions out there are based on Artificial Intelligence or Big Data analysis or Cloud Computing or Internet of Things or a combination of some of these. What do these terms really mean? Learn the basics of these in a simple format, with examples. If you are looking to adopt new-age technology to bring about efficiencies or improve safety/security, knowing the basics will enable you to relate to the solutions better and make an informed decision. If you are generally interested in understanding the base-level tech on which businesses run today, you will secure a better appreciation of how technology can boost business in the new era.
This course guides you through the basics of Artificial Intelligence, Big Data, Cloud Computing, and the Internet of Things in the first four lectures….and much more towards the end, about how humans will soon work and live off the metaverse.
Soon, most organizations may expect employees to work from metaverses. What is the metaverse all about? How will different technologies be at play? How will it make life easier for employees and businesses alike? The last lesson looks at how technology is evolving to build a new way of working and living for humans.
You might hear people use artificial intelligence (AI) and machine learning (ML) interchangeably, especially when discussing big data, predictive analytics, and other digital transformation topics. The confusion is understandable as artificial intelligence and machine learning are closely related. However, these trending technologies differ in several ways, including scope, applications, and more.
Increasingly AI and ML products have proliferated as businesses use them to process and analyze immense volumes of data, drive better decision-making, generate recommendations and insights in real time, and create accurate forecasts and predictions.
So, what exactly is the difference when it comes to ML vs. AI, how are ML and AI connected, and what do these terms mean in practice for organizations today?
We’ll break down AI vs. ML and explore how these two innovative concepts are related and what makes them different from each other.Get started for free
What is artificial intelligence?
Artificial intelligence is a broad field, which refers to the use of technologies to build machines and computers that have the ability to mimic cognitive functions associated with human intelligence, such as being able to see, understand, and respond to spoken or written language, analyze data, make recommendations, and more.
Although artificial intelligence is often thought of as a system in itself, it is a set of technologies implemented in a system to enable it to reason, learn, and act to solve a complex problem.
What is machine learning?
Machine learning is a subset of artificial intelligence that automatically enables a machine or system to learn and improve from experience. Instead of explicit programming, machine learning uses algorithms to analyze large amounts of data, learn from the insights, and then make informed decisions.
Machine learning algorithms improve performance over time as they are trained—exposed to more data. Machine learning models are the output, or what the program learns from running an algorithm on training data. The more data used, the better the model will get.
How are AI and ML connected?
While AI and ML are not quite the same thing, they are closely connected. The simplest way to understand how AI and ML relate to each other is:
AI is the broader concept of enabling a machine or system to sense, reason, act, or adapt like a human
ML is an application of AI that allows machines to extract knowledge from data and learn from it autonomously
One helpful way to remember the difference between machine learning and artificial intelligence is to imagine them as umbrella categories. Artificial intelligence is the overarching term that covers a wide variety of specific approaches and algorithms. Machine learning sits under that umbrella, but so do other major subfields, such as deep learning, robotics, expert systems, and natural language processing.
Differences between AI and ML
Now that you understand how they are connected, what is the main difference between AI and ML?
While artificial intelligence encompasses the idea of a machine that can mimic human intelligence, machine learning does not. Machine learning aims to teach a machine how to perform a specific task and provide accurate results by identifying patterns.
Let’s say you ask your Google Nest device, “How long is my commute today?” In this case, you ask a machine a question and receive an answer about the estimated time it will take you to drive to your office. Here, the overall goal is for the device to perform a task successfully—a task that you would generally have to do yourself in a real-world environment (for example, research your commute time).
In the context of this example, the goal of using ML in the overall system is not to enable it to perform a task. For instance, you might train algorithms to analyze live transit and traffic data to forecast the volume and density of traffic flow. However, the scope is limited to identifying patterns, how accurate the prediction was, and learning from the data to maximize performance for that specific task.
Artificial intelligence
AI allows a machine to simulate human intelligence to solve problems
The goal is to develop an intelligent system that can perform complex tasks
We build systems that can solve complex tasks like a human
AI has a wide scope of applications
AI uses technologies in a system so that it mimics human decision-making
AI works with all types of data: structured, semi-structured, and unstructured
AI systems use logic and decision trees to learn, reason, and self-correct
Machine learning
ML allows a machine to learn autonomously from past data
The goal is to build machines that can learn from data to increase the accuracy of the output
We train machines with data to perform specific tasks and deliver accurate results
Machine learning has a limited scope of applications
ML uses self-learning algorithms to produce predictive models
ML can only use structured and semi-structured data
ML systems rely on statistical models to learn and can self-correct when provided with new data
Benefits of using AI and ML together
AI and ML bring powerful benefits to organizations of all shapes and sizes, with new possibilities constantly emerging. In particular, as the amount of data grows in size and complexity, automated and intelligent systems are becoming vital to helping companies automate tasks, unlock value, and generate actionable insights to achieve better outcomes.
Here are some of the business benefits of using artificial intelligence and machine learning:
Wider data ranges
Analyzing and activating a wider range of unstructured and structured data sources.
Faster decision-making
Improving data integrity, accelerating data processing, and reducing human error for more informed, faster decision-making.
Efficiency
Increasing operational efficiency and reducing costs.
Analytic integration
Empowering employees by integrating predictive analytics and insights into business reporting and applications.
Applications of AI and ML
Artificial intelligence and machine learning can be applied in many ways, allowing organizations to automate repetitive or manual processes that help drive informed decision-making.
Companies across industries are using AI and ML in various ways to transform how they work and do business. Incorporating AI and ML capabilities into their strategies and systems helps organizations rethink how they use their data and available resources, drive productivity and efficiency, enhance data-driven decision-making through predictive analytics, and improve customer and employee experiences.
Here are some of the most common applications of AI and ML:
Healthcare and life sciences
Patient health record analysis and insights, outcome forecasting and modeling, accelerated drug development, augmented diagnostics, patient monitoring, and information extraction from clinical notes.
Manufacturing
Production machine monitoring, predictive maintenance, IoT analytics, and operational efficiency.
Ecommerce and retail
Inventory and supply chain optimization, demand forecasting, visual search, personalized offers and experiences, and recommendation engines.
Financial services
Risk assessment and analysis, fraud detection, automated trading, and service processing optimization.
Telecommunications
Intelligent networks and network optimization, predictive maintenance, business process automation, upgrade planning, and capacity forecasting.
Artificial intelligence is a technology that is already impacting how users interact with, and are affected by the Internet. In the near future, its impact is likely to only continue to grow. AI has the potential to vastly change the way that humans interact, not only with the digital world, but also with each other, through their work and through other socioeconomic institutions – for better or for worse.
If we are to ensure that the impact of artificial intelligence will be positive, it will be essential that all stakeholders participate in the debates surrounding AI.
In this paper, we seek to provide an introduction to AI to policymakers and other stakeholders in the wider Internet ecosystem.
The paper explains the basics of the technology behind AI, identifies the key considerations and challenges surrounding the technology, and provides several high-level principles and recommendations to follow when dealing with the technology.
If more stakeholders bring their points of view and expertise to the discussions surrounding AI, we are confident that its challenges can be addressed and the vast benefits the technology offers can be realized.
Executive Summary
Artificial Intelligence (AI) is a rapidly advancing technology, made possible by the Internet, that may soon have significant impacts on our everyday lives. AI traditionally refers to an artificial creation of human-like intelligence that can learn, reason, plan, perceive, or process natural language[1] . These traits allow AI to bring immense socioeconomic opportunities, while also posing ethical and socio-economic challenges.
As AI is an Internet enabled technology, the Internet Society recognizes that understanding the opportunities and challenges associated with AI is critical to developing an Internet that people can trust.
This policy paper offers a look at key considerations regarding AI, including a set of guiding principles and recommendations to help those involved in policy making make sound decisions. Of specific focus is machine learning, a particular approach to AI and the driving force behind recent developments. Instead of programming the computer every step of the way, machine learning makes use of learning algorithms that make inferences from data to learn new tasks.
As machine learning is used more often in products and services, there are some significant considerations when it comes to users’ trust in the Internet. Several issues must be considered when addressing AI, including, socio-economic impacts; issues of transparency, bias, and accountability; new uses for data, considerations of security and safety, ethical issues; and, how AI facilitates the creation of new ecosystems.
At the same time, in this complex field, there are specific challenges facing AI, which include: a lack of transparency and interpretability in decision-making; issues of data quality and potential bias; safety and security implications; considerations regarding accountability; and, its potentially disruptive impacts on social and economic structures.
In evaluating the different considerations and understanding the various challenges, the Internet Society has developed a set of principles and recommendations in reference to what we believe are the core “abilities”[2] that underpin the value the Internet provides.
While the deployment of AI in Internet based services is not new, the current trend points to AI as an increasingly important factor in the Internet’s future development and use. As such, these guiding principles and recommendations are a first attempt to guide the debate going forward. They include: ethical considerations in deployment and design; ensuring the “Interpretability” of AI systems; empowering the consumer; responsibility in the deployment of AI systems; ensuring accountability; and, creating a social and economic environment that is formed through the open participation of different stakeholders.
Introduction
Artificial intelligence (AI) has received increased attention in recent years. Innovation, made possible through the Internet, has brought AI closer to our everyday lives. These advances, alongside interest in the technology’s potential socio-economic and ethical impacts, brings AI to the forefront of many contemporary debates. Industry investments in AI are rapidly increasing [3], and governments are trying to understand what the technology could mean for their citizens. [4]
The collection of “Big Data” and the expansion of the Internet of Things (IoT), has made a perfect environment for new AI applications and services to grow. Applications based on AI are already visible in healthcare diagnostics, targeted treatment, transportation, public safety, service robots, education and entertainment, but will be applied in more fields in the coming years. Together with the Internet, AI changes the way we experience the world and has the potential to be a new engine for economic growth.
Current Uses of AI:
Although artificial intelligence evokes thoughts of science fiction, artificial intelligence already has many uses today, for example:
Email filtering: Email services use artificial intelligence to filter incoming emails. Users can train their spam filters by marking emails as “spam”.
Personalization: Online services use artificial intelligence to personalize your experience. Services, like Amazon or Netflix, “learn” from your previous purchases and the purchases of other users in order to recommend relevant content for you.
Fraud detection: Banks use artificial intelligence to determine if there is strange activity on your account. Unexpected activity, such as foreign transactions, could be flagged by the algorithm.
Speech recognition: Applications use artificial intelligence to optimize speech recognition functions. Examples include intelligent personal assistants, e.g. Amazon’s “Alexa” or Apple’s “Siri”.
The Internet Society recognizes that understanding the opportunities and challenges associated with AI is critical to developing an Internet that people trust. This is particularly important as the Internet is key for the technology behind AI and is the main platform for its deployment; including significant new means of interacting with the network. This policy paper offers a look at the key things to think about when it comes to AI, including a set of guiding principles and recommendations to help make sound policy decisions. Of particular focus is machine learning, a specific approach to AI and the driving force behind recent developments.
Artificial Intelligence – What it’s all about
Artificial intelligence (AI) traditionally refers to an artificial creation of human-like intelligence that can learn, reason, plan, perceive, or process natural language. [5]
Artificial intelligence is further defined as “narrow AI” or “general AI”. Narrow AI, which we interact with today, is designed to perform specific tasks within a domain (e.g. language translation). General AI is hypothetical and not domain specific, but can learn and perform tasks anywhere. This is outside the scope of this paper. This paper focuses on advances in narrow AI, particularly on the development of new algorithms and models in a field of computer science referred to as machine learning.
Machine learning – Algorithms that generate Algorithms
Algorithms are a sequence of instructions used to solve a problem. Algorithms, developed by programmers to instruct computers in new tasks, are the building blocks of the advanced digital world we see today. Computer algorithms organize enormous amounts of data into information and services, based on certain instructions and rules. It’s an important concept to understand, because in machine learning, learning algorithms – not computer programmers – create the rules.
Instead of programming the computer every step of the way, this approach gives the computer instructions that allow it to learn from data without new step-by-step instructions by the programmer. This means computers can be used for new, complicated tasks that could not be manually programmed. Things like photo recognition applications for the visually impaired, or translating pictures into speech. [6]
The basic process of machine learning is to give trainingdata to a learning algorithm. The learning algorithm then generates a new set of rules, based on inferences from the data. This is in essence generating a new algorithm, formally referred to as the machine learning model. By using different training data, the same learning algorithm could be used to generate different models. For example, the same type of learning algorithm could be used to teach the computer how to translate languages or predict the stock market.
Inferring new instructions from data is the core strength of machine learning. It also highlights the critical role of data: the more data available to train the algorithm, the more it learns. In fact, many recent advances in AI have not been due to radical innovations in learning algorithms, but rather by the enormous amount of data enabled by the Internet.
How machines learn: Although a machine learning model may apply a mix of different techniques, the methods for learning can typically be categorized as three general types:
Supervised learning: The learning algorithm is given labeled data and the desired output. For example, pictures of dogs labeled “dog” will help the algorithm identify the rules to classify pictures of dogs.
Unsupervised learning: The data given to the learning algorithm is unlabeled, and the algorithm is asked to identify patterns in the input data. For example, the recommendation system of an e-commerce website where the learning algorithm discovers similar items often bought together.
Reinforcement learning: The algorithm interacts with a dynamic environment that provides feedback in terms of rewards and punishments. For example, self-driving cars being rewarded to stay on the road.1
Why now?
Machine learning is not new. Many of the learning algorithms that spurred new interest in the field, such as neural networks [7], are based on decades old research. [8] The current growth in AI and machine learning is tied to developments in three important areas:
Data availability: Just over 3 billion people are online with an estimated 17 billion connected devices or sensors. [9] That generates a large amount of data which, combined with decreasing costs of data storage, is easily available for use. Machine learning can use this as training data for learning algorithms, developing new rules to perform increasingly complex tasks.
Computing power: Powerful computers and the ability to connect remote processing power through the Internet make it possible for machine-learning techniques that process enormous amounts of data. [10]
Algorithmic innovation: New machine learning techniques, specifically in layered neural networks – also known as “deep learning” – have inspired new services, but is also spurring investments and research in other parts of the field. [11]
Key Considerations
As machine learning algorithms are used in more and more products and services, there are some serious factors must be considered when addressing AI, particularly in the context of people’s trust in the Internet:
Socio-economic impacts. The new functions and services of AI are expected to have significant socio-economic impacts. The ability of machines to exhibit advanced cognitive skills to process natural language, to learn, to plan and to perceive, makes it possible for new tasks to be performed by intelligent systems, sometimes with more success than humans. [12] New applications of AI could open up exciting opportunities for more effective medical care, safer industries and services, and boost productivity on a massive scale.
Transparency, bias and accountability. AI-made decisions can have serious impacts in people’s lives. AI may discriminate against some individuals or make errors due to biased training data. How a decision is made by AI is often hard to understand, making problems of bias harder to solve and ensuring accountability much more difficult.
New uses for data. Machine learning algorithms have proved efficient in analyzing and identifying patterns in large amounts of data, commonly referred to as “Big Data”. Big Data is used to train learning algorithms to increase their performance. This generates an increasing demand for data, encouraging data collection and raising risks of oversharing of information at the expense of user privacy.
Security and safety. Advancements in AI and its use will also create new security and safety challenges. These include unpredictable and harmful behavior of the AI agent, but also adversarial learning by malicious actors.
Ethics. AI may make choices that could be deemed unethical, yet also be a logical outcome of the algorithm, emphasizing the importance to build in ethical considerations into AI systems and algorithms.
New ecosystems. Like the impact of mobile Internet, AI makes new applications, services, and new means of interacting with the network possible. For example, through speech and smart agents, which may create new challenges to how open or accessible the Internet becomes.
Challenges
Many factors contribute to the challenges faced by stakeholders with the development of AI, including:
Decision-making: transparency and “interpretability”. With artificial intelligence performing tasks ranging from self-driving cars to managing insurance payouts, it’s critical we understand decisions made by an AI agent. But transparency around algorithmic decisions is sometimes limited by things like corporate or state secrecy or technical literacy. Machine learning further complicates this since the internal decision logic of the model is not always understandable, even for the programmer. [13]
While the learning algorithm may be open and transparent, the model it produces may not be. This has implications for the development of machine learning systems, but more importantly for its safe deployment and accountability. There is a need to understand why a self-driving car chooses to take specific actions not only to make sure the technology works, but also to determine liability in the case of an accident.
Data Quality and Bias. In machine learning, the model’s algorithm will only be as good as the data it trains on – commonly described as “garbage in, garbage out”. This means biased data will result in biased decisions. For example, algorithms performing “risk assessments” are in use by some legal jurisdictions in the United States to determine an offenders risk of committing a crime in the future. If these algorithms are trained on racially biased data, they may assign greater risk to individuals of a certain race over others. [14] Reliable data is critical, but greater demand for training data encourages data collection. This, combined with AI’s ability to identify new patterns or re-identify anonymized information, may pose a risk to users’ fundamental rights as it makes it possible for new types of advanced profiling, possibly discriminating against particular individuals or groups.
The problem of minimizing bias is also complicated by the difficulty in understanding how a machine learning model solves a problem, particularly when combined with a vast number of inputs. As a result, it may be difficult to pinpoint the specific data causing the issue in order to adjust it. If people feel a system is biased, it undermines the confidence in the technology.
Safety and Security. As the AI agent learns and interacts with its environment, there are many challenges related to its safe deployment. They can stem from unpredictable and harmful behavior, including indifference to the impact of its actions. One example is the risk of “reward hacking” where the AI agent finds a way of doing something that might make it easier to reach the goal, but does not correspond with the designer’s intent, such as a cleaning robot sweeping dirt under a carpet. [15]
The safety of an AI agent may also be limited by how it learns from its environment. In reinforcement learning this stems from the so-called exploration/exploit dilemma. This means an AI agent may depart from a successful strategy of solving a problem in order to explore other options that could generate a higher payoff. [16] This could have devastating consequences, such as a self-driving car exploring the payoff from driving on the wrong side of the road.
There is also a risk that autonomous systems are exploited by malicious actors trying to manipulate the algorithm. The case of “Tay”, a chatbot deployed on Twitter to learn from interactions with other users, is a good example. It was manipulated through a coordinated attack by Twitter users, training it to engage in racist behavior. [17] Other examples of so-called “adversarial learning” include attacks that try to influence the training data of spam filters or systems for abnormal network traffic detection, so as to mislead the learning algorithm for subsequent exploitation. [18]
The ability to manipulate the training data, or exploit the behavior of an AI agent also highlights issues around transparency of the machine learning model. Disclosing detailed information about the training data and the techniques involved may make an AI agent vulnerable to adversarial learning. Safety and security considerations must be taken into account in the debate around transparency of algorithmic decisions.
Accountability. The strength and efficiency of learning algorithms is based on their ability to generate rules without step-by–step instructions. While the technique has proved efficient in accomplishing complex tasks such as facerecognition or interpreting natural language, it is also one of the sources of concern.
When a machine learns on its own, programmers have less control. While non-machine learning algorithms may reflect biases, the reasoning behind an algorithm’s specific output can often be explained. It is not so simple with machine learning.
Not being able to explain why a specific action was taken makes accountability an issue. Had “Tay”, the chatbot that engaged in racist behavior as mentioned in the prior section, broken a law (such as issuing criminal threats), would its programmers be held accountable? Or would the twitter users who engaged in adversarial training?
In most countries, programmers are not liable for the damages that flaws in their algorithms may produce. This is important, as programmers would likely be unwilling to innovate if they were. However, with the advancement of IoT technologies, such issues may become more immediate. As flaws in algorithms result in greater damages, there is a need for clarified liability on the part of the manufacturer, operator, and the programmer. With AI, the training data, rather than the algorithm itself, may be the problem. By obscuring the reasoning behind an algorithm’s actions, AI further complicates the already difficult questioon of software liability. And as with many fields, it may well be liability that drives change.
Social and Economic Impact. It is predicted that AI technologies will bring economic changes through increases in productivity. This includes machines being able to perform new tasks, such as self-driving cars, advanced robots or smart assistants to support people in their daily lives. [19] Yet how the benefits from the technology are distributed, along with the actions taken by stakeholders, will create vastly different outcomes for labor markets and society as a whole.
For consumers, automation could mean greater efficiency and cheaper products. Artificial intelligence will also create new jobs or increase demand for certain existing ones. But it also means some current jobs may be automated in one to two decades. Some predict it could be as high as 47% of jobs in the United States. [20] Unskilled and lowpaying jobs are more likely to be automated, but AI will also impact high-skilled jobs that rely extensively on routine cognitive tasks. Depending on the net-effect, this could lead to a higher degree of structural unemployment.
Automation may also impact the division of labor on a global scale. Over the past several decades, production and services in some economic sectors has shifted from developed economies to the emerging economies, largely as a result of comparatively lower labor or material costs. These shifts have helped propel some of the world’s fastest emerging economies and supports a growing global middle class. But, with the emergence of AI technologies, these incentives could lessen. Some companies, instead of offshoring, may choose to automate some of their operations locally.
The positive and negative impacts of AI and automation on the labor market and the geographical division of labor will not be without their own challenges. For instance, if AI becomes a concentrated industry among a small number of players or within a certain geography, it could lead to greater inequality within and between societies. Inequality may also lead to technological distrust, particularly of AI technologies and of the Internet, which may be blamed for this shift.
Governance. The institutions, processes and organizations involved in the governance of AI are still in the early stages. To a great extent, the ecosystem overlaps with subjects related to Internet governance and policy. Privacy and data laws are one example.
Existing efforts from public stakeholders include the UN Expert Group on Lethal Autonomous Weapons Systems (LAWS), as well as regulations like the EU’s recent General Data Protection Regulation (GDPR) and the “right to explanation” of algorithmic decisions. [21] How such processes develop, and how similar regulations are adopted or interpreted, will have a significant impact on the technology’s continued development. Ensuring a coherent approach in the regulatory space is important, to ensure the benefits of Internet-enabled technologies, like AI, are felt in all communities.
A central focus of the current governance efforts relates to the ethical dimensions of artificial intelligence and its implementation. For example, the Institute of Electrical and Electronics Engineers (IEEE) has released a new report on Ethically Aligned Design in artificial intelligence [22], part of a broader initiative to ensure ethical considerations are incorporated in the systems design. Similarly, OpenAI, a non-profit research company in California has received more than 1 billion USD in commitments to promote research and activities aimed at supporting the safe development of AI. Other initiatives from the private sector include the “Partnership on AI”, established by Amazon, Google, Facebook, IBM, Apple and Microsoft “to advance public understanding of artificial intelligence technologies (AI) and formulate best practices on the challenges and opportunities within the field”.
Despite the complexity of the field, all stakeholders, including governments, industry and users, should have a role to play to determine the best governance approaches to AI. From market-based approaches to regulation, all stakeholders should engage in the coming years to manage the technology’s economic and social impact. Furthermore, the social impact of AI cannot be fully mitigated by governing the technology, but will require efforts to govern the impact of the technology.
Guiding Principles and Recommendations
The Internet Society has developed the following principles and recommendations in reference to what we believe are the core “abilities” [23] that underpin the value the Internet provides. While the deployment of AI in Internet based services is not new, the current trend points to AI as an increasingly important factor in the Internet’s future development and use. As such, these guiding principles and recommendations are a first attempt to guide the debate going forward. Furthermore, while this paper is focused on the specific challenges surrounding AI, the strong interdependence between its development and the expansion of the Internet of Things (IoT) demands a closer look at interoperability and security of IoT devices. [24]
Ethical Considerations in Deployment and Design
Principle: AI system designers and builders need to apply a user-centric approach to the technology. They need to consider their collective responsibility [25] in building AI systems that will not pose security risks to the Internet and Internet users.
Recommendations:
Adopt ethical standards: Adherence to the principles and standards of ethical considerations in the design of artificial intelligence [26], should guide researchers and industry going forward.
Promote ethical considerations in innovation policies: Innovation policies should require adherence to ethical standards as a pre-requisite for things like funding.
Ensure “Interpretability” of AI systems
Principle: Decisions made by an AI agent should be possible to understand, especially if those decisions have implications for public safety, or result in discriminatory practices.
Recommendations:
Ensure Human Interpretability of Algorithmic Decisions: AI systems must be designed with the minimum requirement that the designer can account for an AI agent’s behaviors. Some systems with potentially severe implications for public safety should also have the functionality to provide information in the event of an accident.
Empower Users: Providers of services that utilize AI need to incorporate the ability for the user to request and receive basic explanations as to why a decision was made.
Public Empowerment
Principle: The public’s ability to understand AI-enabled services, and how they work, is key to ensuring trust in the technology.
Recommendations:
“Algorithmic Literacy” must be a basic skill: Whether it is the curating of information in social media platforms or self-driving cars, users need to be aware and have a basic understanding of the role of algorithms and autonomous decision-making. Such skills will also be important in shaping societal norms around the use of the technology. For example, identifying decisions that may not be suitable to delegate to an AI.
Provide the public with information: While full transparency around a service’s machine learning techniques and training data is generally not advisable due to the security risk, the public should be provided with enough information to make it possible for people to question its outcomes.
Responsible Deployment
Principle: The capacity of an AI agent to act autonomously, and to adapt its behavior over time without human direction, calls for significant safety checks before deployment, and ongoing monitoring.
Recommendations:
Humans must be in control: Any autonomous system must allow for a human to interrupt an activity or shutdown the system (an “off-switch”). There may also be a need to incorporate human checks on new decision-making strategies in AI system design, especially where the risk to human life and safety is great.
Make safety a priority: Any deployment of an autonomous system should be extensively tested beforehand to ensure the AI agent’s safe interaction with its environment (digital or physical) and that it functions as intended. Autonomous systems should be monitored while in operation, and updated or corrected as needed.
Privacy is key: AI systems must be data responsible. They should use only what they need and delete it when it is no longer needed (“data minimization”). They should encrypt data in transit and at rest, and restrict access to authorized persons (“access control”). AI systems should only collect, use, share and store data in accordance with privacy and personal data laws and best practices.
Think before you act: Careful thought should be given to the instructions and data provided to AI systems. AI systems should not be trained with data that is biased, inaccurate, incomplete or misleading.
If they are connected, they must be secured: AI systems that are connected to the Internet should be secured not only for their protection, but also to protect the Internet from malfunctioning or malware-infected AI systems that could become the next-generation of botnets. High standards of device, system and network security should be applied.
Responsible disclosure: Security researchers acting in good faith should be able to responsibly test the security of AI systems without fear of prosecution or other legal action. At the same time, researchers and others who discover security vulnerabilities or other design flaws should responsibly disclose their findings to those who are in the best position to fix the problem.
Ensuring Accountability
Principle: Legal accountability has to be ensured when human agency is replaced by decisions of AI agents.
Recommendations:
Ensure legal certainty: Governments should ensure legal certainty on how existing laws and policies apply to algorithmic decision-making and the use of autonomous systems to ensure a predictable legal environment. This includes working with experts from all disciplines to identify potential gaps and run legal scenarios. Similarly, those designing and using AI should be in compliance with existing legal frameworks.
Put users first: Policymakers need to ensure that any laws applicable to AI systems and their use put users’ interests at the center. This must include the ability for users to challenge autonomous decisions that adversely affect their interests.
Assign liability up-front: Governments working with all stakeholders need to make some difficult decisions now about who will be liable in the event that something goes wrong with an AI system, and how any harm suffered will be remedied.
Social and Economic Impacts
Principle: Stakeholders should shape an environment where AI provides socio-economic opportunities for all.
Recommendations:
All stakeholders should engage in an ongoing dialogue to determine the strategies needed to seize upon artificial intelligence’s vast socio-economic opportunities for all, while mitigating its potential negative impacts. A dialogue could address related issues such as educational reform, universal income, and a review of social services.
Open Governance
Principle: The ability of various stakeholders, whether civil society, government, private sector or academia and the technical community, to inform and participate in the governance of AI is crucial for its safe deployment.
Recommendations:
Promote Multistakeholder Governance: Organizations, institutions and processes related to the governance of AI need to adopt an open, transparent and inclusive approach. It should be based on four key attributes: Inclusiveness and transparency; Collective responsibility; Effective decision making and implementation and Collaboration through distributed and interoperable governance [27]
Acknowledgments
The Internet Society acknowledges the contributions of staff members, external reviewers, and Internet Society community members in developing this paper. Special acknowledgements are due to the Internet Society’s Carl Gahnberg and Ryan Polk who conducted the primary research and preparation for the paper, and Steve Olshansky who helped develop the document’s strategic direction and provided valuable input throughout the writing process.
The paper benefitted from the reviews, comments and support of a set of Internet Society staff: Constance Bommelaer, Olaf Kolkman, Konstantinos Komaitis, Ted Mooney, Andrei Robachevsky, Christine Runnegar, Nicolas Seidler, Sally Wentworth and Robin Wilton. Thanks to the Internet Society Communications team for shaping the visual aspect of this paper and promoting its release: Allesandra Desantillana, Beth Gombala, Lia Kiessling, James Wood and Dan York.
Special thanks to Walter Pienciak from the Institute of Electrical and Electronics Engineers (IEEE) for his significant contributions in his early review of the paper.
Finally, the document was immensely improved by the input of a variety of Internet Society community members. Their wide areas of expertise and fresh perspectives served to greatly strengthen the final paper.
Our ability to learn and become better at everyday activities through experience is a basic characteristic of our human nature.
When we are born we don’t really know how to do things, but day by day we learn more and more both on our own and with the help of others.
Something similar happens with machines – or computers in simpler terms – which collect enough data and information to be able to draw conclusions on their own. This is the main meaning of Machine Learning.
Machine Learning is a part of Artificial Intelligence, based on the idea that computers/machines can learn from the data they collect in order to recognize patterns and make their own decisions.
All this with little or no human intervention.
In other words, engineering algorithms are “trained” through situations and examples, where they learn and analyze data in order to make predictions about the future.
Interesting, isn’t it?
Although we will see detailed examples later in the article, it is worth mentioning one briefly to make Machine Learning fully understandable.
You may have heard of something called Sentiment Analysis. It’s about identifying the emotional tone behind words.
When we read a text online it is not always easy to know what emotion is behind it, there are tools that have been trained with data to do the job.
But how does this help?
Sentiment Analysis mainly helps companies understand the intent behind a text, a user’s Tweet, and even a video where the machine learns to “read” emotions by analyzing a person’s expressions.
Of course, the more data the machine “reads”, the more chances it has to be more accurate in its decisions.
Although we could go deeper into this part, it is a good example of Machine Learning.
How Does Machine Learning Work?
With the exponential increase in the amount of data we have nowadays, there is an urgent need for systems that can process this complex data.
This large and complex data is known as Big Data and is usually managed by Machine Learning models such as Deep Learning.
As mentioned earlier, in Machine Learning, the algorithms are fed with various data to analyse it, draw their conclusions and then keep this data to improve and be able to get more and more accurate results every time.
Almost any task can be automated with the help of machines, which is pushing more and more companies to learn what is Machine Learning and transform their processes to be done automatically, faster and more accurately.
After all, data science has become a part of our daily lives that for most companies its adoption is mandatory.
It is now worth mentioning the 2 main machine learning methods :
1) Supervised Learning
The first method is Supervised Learning.
What does it mean?
The machines are trying to draw conclusions based on past data they have collected. This process is similar to the way humans think. We use past experiences and knowledge to make better decisions in the present or even “predict” a future outcome.
A good example of Supervised Machine Learning is the personalized product recommendations that for example, Amazon suggests to each user, based on the products they have bought or simply viewed in the past.
2) Unsupervised Learning
The first method is Unsupervised Learning.
In this method, the algorithms try to identify various unknown patterns in the data without having labeled data.
For example, this method can be applied when we want to estimate the likely market size for a new product where we do not have enough data.
So, the algorithm will work with as much data as it has to group them into clusters and present them visually (K-Means Clustering).
Source: ml-science.com
Now that we’ve seen what Machine Learning is and how it works, let’s look at some examples to make it easier to understand.
Machine Learning Examples
As mentioned, in this section we’ll look at real examples of Machine Learning, some of which you’ve probably heard of.
Let’s start with the first one.
1) Facebook (Meta)
Facebook (or Meta) is a good example of a company using machine learning.
In particular, Facebook has applied artificial intelligence to its infrastructure so that various companies can create chatbots that talk to users on their own.
A user can ask a question and the system will answer it automatically, without human intervention.
In the image above you can see a Gatwick Airport chatbot where visitors can ask and get information about their flight, available restaurants, shops and more.
All this has been made possible by the application of machine learning!
Let’s move on to the next example.
2) Apple
Apple undoubtedly needs no introduction, as it is one of the world’s largest technology companies.
What you may not know is that Apple has applied AI and Machine Learning, particularly in 2 cases.
The first case is Siri. Siri is the digital voice assistant that receives data from us in audio form and performs various commands, such as answering questions or even calling someone.
The second case is face recognition. A technology that recognizes a person by “seeing” their face, after collecting various data on facial features and structure.
Thanks to the development of AI, machine learning, and Deep Learning, face recognition technologies are growing rapidly!
Let’s have a look at another example before summarizing.
3) Netflix
The reason Netflix is on this list is similar to the reason we mentioned Amazon earlier, as they do a great job of recommending movies/series to users.
Netflix collects data from what each user watches on the platform to draw conclusions about their preferences and suggest relevant things they are likely to be interested in.
This is an excellent example of a Machine Learning application that you have surely experienced yourself if you use the service.
As you can see, we experience the effects of machine learning daily, even if we don’t realize it.
That’s what’s so impressive about data science that so many companies and professionals are rushing to train in it.
Healthcare is an industry that is constantly evolving. New technologies and treatments are being developed all the time, which can make it difficult for healthcare professionals to keep up. In recent years, machine learning in healthcare has become one of the most popular buzzwords. But what is machine learning in healthcare exactly? Why is machine learning so important for patient data? And what are some of the benefits of machine learning in healthcare?
What is Machine Learning?
Machine learning is a specific type of artificial intelligence that allows systems to learn from data and detect patterns without much human intervention. Instead of being told what to do, computers that use machine learning are shown patterns and data which then allows them to reach their own conclusions.
Machine learning algorithms have a variety of functions, like helping to filter email, identify objects in images and analyze large volumes of increasingly complex data sets. Computers use machine learning systems to automatically go through emails and find spam, as well as recognize things in pictures and process big data.
Machine learning in healthcare is a growing field of research in precision medicine with many potential applications. As patient data becomes more readily available, machine learning in healthcare will become increasingly important to healthcare professionals and health systems for extracting meaning from medical information.
Why is Machine Learning Important for Healthcare Organizations?
For the healthcare industry, machine learning algorithms are particularly valuable because they can help us make sense of the massive amounts of healthcare data that is generated every day within electronic health records. Using machine learning in healthcare like machine learning algorithms can help us find patterns and insights in medical data that would be impossible to find manually.
As machine learning in healthcare gains widespread adoption, healthcare providers have an opportunity to take a more predictive approach to precision medicine that creates a more unified system with improved care delivery, better patient outcomes and more efficient patient-based processes.
The most common use cases for machine learning in healthcare among healthcare professionals are automating medical billing, clinical decision support and the development of clinical practice guidelines within health systems. There are many notable high-level examples of machine learning and healthcare concepts being applied in science and medicine. At MD Anderson, data scientists have developed the first deep learning in healthcare algorithm using machine learning to predict acute toxicities in patients receiving radiation therapy for head and neck cancers. In clinical workflows, the medical data generated by deep learning in healthcare can identify complex patterns automatically, and offer a primary care provider clinical decision support at the point of care within the electronic health record.
Large volumes of unstructured healthcare data for machine learning represent almost 80% of the information held or “locked” in electronic health record systems. These are not data elements but relevant data documents or text files with patient information, which in the past could not be analyzed by healthcare machine learning but required a human to read through the medical records.
Human language, or “natural language,” is very complex, lacking uniformity and incorporates an enormous amount of ambiguity, jargon, and vagueness. In order to convert these documents into more useful and analyzable data, machine learning in healthcare often relies on artificial intelligence like natural language processing programs. Most deep learning in healthcare applications that use natural language processing require some form of healthcare data for machine learning.
What Are the Benefits for Healthcare Providers and Patient Data?
As you can see, there are a wide range of potential uses for machine learning technologies in healthcare from improving patient data, medical research, diagnosis and treatment, to reducing costs and making patient safety more efficient. Here’s a list of just some of the benefits machine learning applications in healthcare can bring healthcare professionals in the healthcare industry:
Improving diagnosis
Machine learning in healthcare can be used by medical professionals to develop better diagnostic tools to analyze medical images. For example, a machine learning algorithm can be used in medical imaging (such as X-rays or MRI scans) using pattern recognition to look for patterns that indicate a particular disease. This type of machine learning algorithm could potentially help doctors make quicker, more accurate diagnoses leading to improved patient outcomes.
Developing new treatments / drug discovery / clinical trials
A deep learning model can also be used by healthcare organizations and pharmaceutical companies to identify relevant information in data that could lead to drug discovery, the development of new drugs by pharmaceutical companies and new treatments for diseases. For example, machine learning in healthcare could be used to analyze data and medical research from clinical trials to find previously unknown side-effects of drugs. This type of healthcare machine learning in clinical trials could help to improve patient care, drug discovery, and the safety and effectiveness of medical procedures.
Reducing costs
Machine learning technologies can be used by healthcare organizations to improve the efficiency of healthcare, which could lead to cost savings. For example, machine learning in healthcare could be used to develop better algorithms for managing patient records or scheduling appointments. This type of machine learning could potentially help to reduce the amount of time and resources that are wasted on repetitive tasks in the healthcare system.
Improving care
Machine learning in healthcare can also be used by medical professionals to improve the quality of patient care. For example, deep learning algorithms could be used by the healthcare industry to develop systems that proactively monitor patients and provide alerts to medical devices or electronic health records when there are changes in their condition. This type of data collection machine learning could help to ensure that patients receive the right care at the right time.
Machine learning applications in healthcare are already having a positive impact, and the potential of machine learning to deliver care is still in the early stages of being realized. In the future, machine learning in healthcare will become increasingly important as we strive to make sense of ever-growing clinical data sets.
At ForeSee Medical, machine learning medical data consists of training our AI-powered risk adjustment software to analyze the speech patterns of our physician end users and determine context (hypothetical, negation) of important medical terms. Our robust negation engine can identify not only key terms, but also all four negation types: hypothetical (could be, differential), negative (denies), history (history of) and family history (mom, wife) are the four important negation types. With over 500 negation terms our machine learning technology is able to achieve accuracy rates that are greater than 97%.
Additionally, our proprietary medical algorithms use machine learning to process and analyze your clinical practice data and notes. This is a dynamic set of machine learned algorithms that play a key role in data collection and are always being reviewed and improved upon by our clinical informatics team. Within our clinical algorithms we’ve developed unique uses of machine learning in healthcare such as proprietary concepts, terms and our own medical dictionary. The ForeSee Medical Disease Detector’s natural language processing engine extracts your clinical data and notes, it’s then analyzed by our clinical rules and machine learning algorithms. Natural language processing performance is constantly improving for better outcomes because we continuously feed our “machine” patient healthcare data for machine learning that makes our natural language processing performance more precise.
But not everything is done by artificial intelligence systems or artificial intelligence technologies like machine learning. The data for machine learning in healthcare has to be prepared in such a way that the computer can more easily find patterns and inferences. This statistical technique is usually done by humans that tag elements of the dataset for data quality which is called an annotation over the input. Our team of clinical experts are performing this function as well as analyzing results, writing new rules and improving machine learning performance. However, in order for the machine learning applications in healthcare to learn efficiently and effectively, the annotation done on the patient data must be accurate, and relevant to our task of extracting key concepts with proper context.
ForeSee Medical and its team of clinicians are using machine learning and healthcare data to power our proprietary rules and language processing intelligence with the ultimate goal of superior disease detection. This is the critical driving force behind precision medicine and properly documenting your patients’ HCC risk adjustment coding at the point of care – getting you the accurate reimbursements you deserve.
Within the last decade, the terms artificial intelligence (AI) and machine learning (ML) have become buzzwords that are often used interchangeably. While AI and ML are inextricably linked and share similar characteristics, they are not the same thing. Rather, ML is a major subset of AI.
AI and ML technologies are all around us, from the digital voice assistants in our living rooms to the recommendations you see on Netflix.
Investing in technologies and people to defend financial institutions
39UnmuteAdvanced SettingsFullscreenPauseUp Next
Investing in technologies and people to defend financial institutions
Rebuilding cybersecurity threat detection and response
Identifying and mitigating the most critical security risks
Becoming Secure by Design
Optimizing security strategies during an acute talent shortage
Internal threats that create external attack opportunities and how to combat them
Despite AI and ML penetrating several human domains, there’s still much confusion and ambiguity regarding their similarities, differences and primary applications.
Here’s a more in-depth look into artificial intelligence vs. machine learning, the different types, and how the two revolutionary technologies compare to one another.
What is artificial intelligence (AI)?
AI is defined as computer technology that imitate(s) a human’s ability to solve problems and make connections based on insight, understanding and intuition.
The field of AI rose to prominence in the 1950s. However, mentions of artificial beings with intelligence can be identified earlier throughout various disciplines like ancient philosophy, Greek mythology and fiction stories.
One notable project in the 20th century, the Turing Test, is often referred to when referencing AI’s history. Alan Turing, also referred to as “the father of AI,” created the test and is best known for creating a code-breaking computer that helped the Allies in World War II understand secret messages being sent by the German military.
The Turing Test, is used to determine if a machine is capable of thinking like a human being. A computer can only pass the Turing Test if it responds to questions with answers that are indistinguishable from human responses.
Three key capabilities of a computer system powered by AI include intentionality, intelligence and adaptability. AI systems use mathematics and logic to accomplish tasks, often encompassing large amounts of data, that otherwise wouldn’t be practical or possible.
Common AI applications
Modern AI is used by many technology companies and their customers. Some of the most common AI applications today include:
Advanced web search engines (Google)
Self-driving cars (Tesla)
Personalized recommendations (Netflix, YouTube)
Personal assistants (Amazon Alexa, Siri)
One example of AI that stole the spotlight was in 2011, when IBM’s Watson, an AI-powered supercomputer, participated on the popular TV game show Jeopardy! Watson shook the tech industry to its core after beating two former champions, Ken Jennings and Brad Rutter.
Outside of game show use, many industries have adopted AI applications to improve their operations, from manufacturers deploying robotics to insurance companies improving their assessment of risk.
Also read: How AI is changing the way we learn languages
Types of AI
AI is often divided into two categories: narrow AI and general AI.
Narrow AI: Many modern AI applications are considered narrow AI, built to complete defined, specific tasks. For example, a chatbot on a business’s website is an example of narrow AI. Another example is an automatic translation service, such as Google Translate. Self-driving cars are another application of this.
General AI: General AI differs from narrow AI because it also incorporates machine learning (ML) systems for various purposes. It can learn more quickly than humans and complete intellectual and performance tasks better.
Regardless of if an AI is categorized as narrow or general, modern AI is still somewhat limited. It cannot communicate exactly like humans, but it can mimic emotions. However, AI cannot truly have or “feel” emotions like a person can.
What is machine learning (ML)?
Machine learning (ML) is considered a subset of AI, whereby a set of algorithms builds models based on sample data, also called training data.
The main purpose of an ML model is to make accurate predictions or decisions based on historical data. ML solutions use vast amounts of semi-structured and structured data to make forecasts and predictions with a high level of accuracy.
In 1959, Arthur Samuel, a pioneer in AI and computer gaming, defined ML as a field of study that enables computers to continuously learn without being explicitly programmed.
An ML model exposed to new data continuously learns, adapts and develops on its own. Many businesses are investing in ML solutions because they assist them with decision-making, forecasting future trends, learning more about their customers and gaining other valuable insights.
Types of ML
There are three main types of ML: supervised, unsupervised and reinforcement learning. A data scientist or other ML practitioner will use a specific version based on what they want to predict. Here’s what each type of ML entails:
Supervised ML: In this type of ML, data scientists will feed an ML model labeled training data. They will also define specific variables they want the algorithm to assess to identify correlations. In supervised learning, the input and output of information are specified.
Unsupervised ML: In unsupervised ML, algorithms train on unlabeled data, and the ML will scan through them to identify any meaningful connections. The unlabeled data and ML outputs are predetermined.
Reinforcement learning: Reinforcement learning involves data scientists training ML to complete a multistep process with a predefined set of rules to follow. Practitioners program ML algorithms to complete a task and will provide it with positive or negative feedback on its performance.
Common ML applications
Major companies like Netflix, Amazon, Facebook, Google and Uber have ML a central part of their business operations. ML can be applied in many ways, including via:
Email filtering
Speech recognition
Computer vision (CV)
Spam/fraud detection
Predictive maintenance
Malware threat detection
Business process automation (BPA)
Another way ML is used is to power digital navigation systems. For example, Apple and Google Maps apps on a smartphone use ML to inspect traffic, organize user-reported incidents like accidents or construction, and find the driver an optimal route for traveling. ML is becoming so ubiquitous that it even plays a role in determining a user’s social media feeds.
AI vs. ML: 3 key similarities
AI and ML do share similar characteristics and are closely related. ML is a subset of AI, which essentially means it is an advanced technique for realizing it. ML is sometimes described as the current state-of-the-art version of AI.
1. Continuously evolving
AI and ML are both on a path to becoming some of the most disruptive and transformative technologies to date. Some experts say AI and ML developments will have even more of a significant impact on human life than fire or electricity.
The AI market size is anticipated to reach around $1,394.3 billion by 2029, according to a report from Fortune Business Insights. As more companies and consumers find value in AI-powered solutions and products, the market will grow, and more investments will be made in AI. The same goes for ML — research suggests the market will hit $209.91 billion by 2029.
2. Offering myriad benefits
Another significant quality AI and ML share is the wide range of benefits they offer to companies and individuals. AI and ML solutions help companies achieve operational excellence, improve employee productivity, overcome labor shortages and accomplish tasks never done before.
There are a few other benefits that are expected to come from AI and ML, including:
Improved natural language processing (NLP), another field of AI
Developing the Metaverse
Enhanced cybersecurity
Hyperautomation
Low-code or no-code technologies
Emerging creativity in machines
AI and ML are already influencing businesses of all sizes and types, and the broader societal expectations are high. Investing in and adopting AI and ML is expected to bolster the economy, lead to fiercer competition, create a more tech-savvy workforce and inspire innovation in future generations.
3. Leveraging Big Data
Without data, AI and ML would not be where they are today. AI systems rely on large datasets, in addition to iterative processing algorithms, to function properly.
ML models only work when supplied with various types of semi-structured and structured data. Harnessing the power of Big Data lies at the core of both ML and AI more broadly.
Because AI and ML thrive on data, ensuring its quality is a top priority for many companies. For example, if an ML model receives poor-quality information, the outputs will reflect that.
Consider this scenario: Law enforcement agencies nationwide use ML solutions for predictive policing. However, reports of police forces using biased training data for ML purposes have come to light, which some say is inevitably perpetuating inequalities in the criminal justice system.
This is only one example, but it shows how much of an impact data quality has on the functioning of AI and ML.
Also read: What is unstructured data in AI?
AI vs. ML: 3 key differences
Even with the similarities listed above, AI and ML have differences that suggest they should not be used interchangeably. One way to keep the two straight is to remember that all types of ML are considered AI, but not all kinds of AI are ML.
1. Scope
AI is an all-encompassing term that describes a machine that incorporates some level of human intelligence. It’s considered a broad concept and is sometimes loosely defined, whereas ML is a more specific notion with a limited scope.
Practitioners in the AI field develop intelligent systems that can perform various complex tasks like a human. On the other hand, ML researchers will spend time teaching machines to accomplish a specific job and provide accurate outputs.
Due to this primary difference, it’s fair to say that professionals using AI or ML may utilize different elements of data and computer science for their projects.
2. Success vs. accuracy
Another difference between AI and ML solutions is that AI aims to increase the chances of success, whereas ML seeks to boost accuracy and identify patterns. Success is not as relevant in ML as it is in AI applications.
It’s also understood that AI aims to find the optimal solution for its users. ML is used more often to find a solution, optimal or not. This is a subtle difference, but further illustrates the idea that ML and AI are not the same.
In ML, there is a concept called the ‘accuracy paradox,’ in which ML models may achieve a high accuracy value, but can give practitioners a false premise because the dataset could be highly imbalanced.
3. Unique outcomes
AI is a much broader concept than ML and can be applied in ways that will help the user achieve a desired outcome. AI also employs methods of logic, mathematics and reasoning to accomplish its tasks, whereas ML can only learn, adapt or self-correct when it’s introduced to new data. In a sense, ML has more constrained capabilities than AI.
ML models can only reach a predetermined outcome, but AI focuses more on creating an intelligent system to accomplish more than just one result.
It can be perplexing, and the differences between AI and ML are subtle. Suppose a business trained ML to forecast future sales. It would only be capable of making predictions based on the data used to teach it.
However, a business could invest in AI to accomplish various tasks. For example, Google uses AI for several reasons, such as to improve its search engine, incorporate AI into its products and create equal access to AI for the general public.
Identifying the differences between AI and ML
Much of the progress we’ve seen in recent years regarding AI and ML is expected to continue. ML has helped fuel innovation in the field of AI.
AI and ML are highly complex topics that some people find difficult to comprehend.
Despite their mystifying natures, AI and ML have quickly become invaluable tools for businesses and consumers, and the latest developments in AI and ML may transform the way we live.
The “race starts today” in search, said Microsoft CEO Satya Nadella at a special event today at Microsoft headquarters in Redmond, Washington. “We’re going to move fast,” he added, as the company announced a reimagined Bing search engine, Edge web browser and chat powered by OpenAI’s ChatGPT and generative AI.
The new Bing for the desktop is available on limited preview. And Microsoft says it is launching a mobile version in a few weeks. There will be no cost to use the new Bing, but ads will be there from the start, according to Yusuf Mehdi, corporate vice president and consumer chief marketing officer at Microsoft.
OpenAI CEO Sam Altman joined on stage at the event: “I think it’s the beginning of a new era,” he told the audience, adding that he wants to get AI into the hands of more people, which is why OpenAI partnered with Microsoft — starting with Azure and now Bing.
Microsoft announced new ‘AI-powered copilot’ experience
At the center of a new “AI-powered copilot” experience is a new Bing search engine and Edge web browser, said Mehdi.
Bing is running on a new, next-generation language model called Prometheus, he said, one more powerful than ChatGPT and one customizable for search (NOTE: So far, neither Microsoft nor OpenAI have referred to this more-advanced ChatGPT as the long-awaited GPT-4).
The Prometheus model, Mehdi said, offers several advances, including improvements in relevancy of answers, annotating answers with specific web links, getting more up-to-date information and improving geolocation, and increasing the safety of queries.
As a result, there have already been steady improvements on the Bing algorithm, he said. A few weeks ago, Microsoft applied AI to its core search index and saw the “largest jump in relevancy” over the past two decades.
Microsoft says it is ‘clear-eyed’ about unintended consequences of tech
In an introduction, Nadella said that, for Microsoft, these announcements are about being “clear-eyed” about the unintended consequences of technology, pointing to the company’s release of responsible AI principles back in 2016.
AI prompting, he explained, comes from human beings — Microsoft, he said, wants to take the design of AI products as a “first-class construct” and build that into our products. But that is insufficient, he added — the key is building AI that’s “more in line with human values and social preferences.”
Sarah Bird, Microsoft’s responsible AI lead, took the stage to emphasize that with technology this powerful, “I know we have a responsibility to ensure that it’s developed properly.” Fortunately, she added, at Microsoft “we’re not starting from scratch. We’ve been working on this for years. We’re also not new to working with generative AI.”
New Microsoft Bing experience
According to a Microsoft blog post, the new Bing experience is a culmination of four technical breakthroughs:
Next-generation OpenAI model. We’re excited to announce the new Bing is running on a new, next-generation OpenAI large language model that is more powerful than ChatGPT and customized specifically for search. It takes key learnings and advancements from ChatGPT and GPT-3.5 – and it is even faster, more accurate and more capable.
Microsoft Prometheus model. We have developed a proprietary way of working with the OpenAI model that allows us to best leverage its power. We call this collection of capabilities and techniques the Prometheus model. This combination gives you more relevant, timely and targeted results, with improved safety.
Applying AI to core search algorithm. We’ve also applied the AI model to our core Bing search ranking engine, which led to the largest jump in relevance in two decades. With this AI model, even basic search queries are more accurate and more relevant.
New user experience. We’re reimagining how you interact with search, browser and chat by pulling them into a unified experience. This will unlock a completely new way to interact with the web.
Announcements come as Google and Microsoft offer dueling debuts this week
The announcements come after Google and Microsoft, in separate surprise announcements, confirmed dueling generative AI debuts this week.
Yesterday, Google unveiled a new ChatGPT-like chatbot named Bard, as it races to catch up in the wake of ChatGPT’s massive viral success (growing faster than TikTok, apparently). In a blog post, CEO Sundar Pichai said that Bard is now open to “trusted testers,” with plans to make it available to the public “in the coming weeks.”
In addition, the company announced a streaming event called Live from Paris focused on “Search, Maps and beyond,” to be livestreamed on YouTube at 8:30 am ET on February 8th. According to the description: “We’re reimagining how people search for, explore and interact with information, making it more natural and intuitive than ever before to find what you need.”
It was only ten weeks ago that OpenAI launched what it simply described as an “early demo”; a part of the GPT-3.5 series — an interactive, conversational model whose dialogue format “makes it possible for ChatGPT to answer follow-up questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.”
ChatGPT quickly caught the imagination — and feverish excitement — of both the AI community and the general public.
Since then, the tool’s possibilities — as well as its limitations and hidden dangers — have been well established. Rumors around Microsoft’s efforts to integrate ChatGPT into its Bing search engine, as well as productivity tools like PowerPoint and Outlook, have circulated for weeks. And any hints of slowing down its development were quickly dashed when Microsoft announced its plans to invest billions more into OpenAI on January 23.