Machine Learning in Data Science
It is a process or collection of rules or set to complete a task. It is one of the primary concepts in, or building blocks of, computer science: the basis of the design of elegant and efficient code, data processing and preparation, and software engineering.
We have the perfect professional Data Science Courses for you!
In Data Science there are mainly three algorithms are used:
- Data preparation, munging, and process algorithms
- Optimization algorithms for parameter estimation which includes Stochastic Gradient Descent, Least-Squares, Newton’s Method
- Machine learning algorithms
Machine learning is used to predict, categorize, classify, finding polarity, etc from the given datasets and concerned with minimizing the error.
It uses training data for artificial intelligence.
Since there are many algorithms like SVM Algorithm in Python, Bayes algorithm, logistic regression, etc. which will use training data to match with input data and then it will provide a conclusion with maximum accuracy.
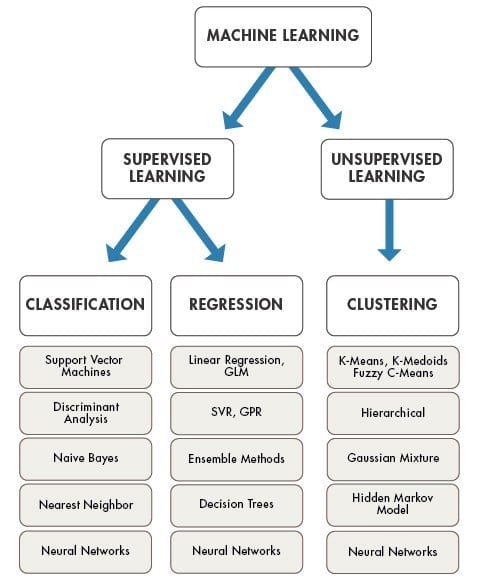
Machine learning is categorized into
The critical element of data science is Machine Learning algorithms, which are a process of a set of rules to solve a certain problem.
Some of the important data science algorithms include regression, classification and clustering techniques, decision trees and random forests, machine learning techniques like supervised, unsupervised and reinforcement learning. In addition to these, there are many algorithms that organizations develop to serve their unique needs.
- Supervised learning
It is used for the structured dataset. It analyzes the training data and generates a function that will be used for other datasets.
- Unsupervised learning
It is used for raw datasets. Its main task is to convert raw data to structured data.In today’s world, there is a huge amount of raw data in every field. Even the computer generates log files which are in the form of raw data. Therefore it’s the most important part of machine learning.
Read how our Data Science training helped Ritesh to switch his career to Data Science domain.
Watch this Data Science Course video to learn more about its concepts:
We will be using three algorithms in this course
Come to Intellipaat’s Data Science Community if you have more queries on Data Science!
- Linear Regression
It is the most well known and popular algorithm in machine learning and statistics. This model will assume a linear relationship between the input and the output variable. It is represented in the form of linear equation which has a set of inputs and a predictive output. Then it will estimate the values of coefficient used in the representation.
- k-Nearest Neighbors (k-NN)
This algorithm is used for classification problems and statistical problems as well.
Its model is to store the complete dataset. By using this algorithm, prediction is done by searching the entire training data for k instances. We can use Euclidean distance formula to determine similar input from k training data. Prediction depends on mean and median while solving for a regression problem. This algorithm mainly used for classification problem.
A Machine Learning Course will give you a better understanding of the problem.
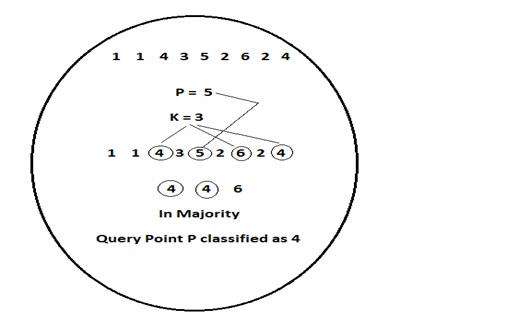
The output will be calculated from a class that has the highest frequency when solving for classification.
Check out the top Data Science Interview Questions to learn what is expected from Data Science professionals!
k-means
It is an unsupervised technique which is used for raw datasets. It is used to classify objects based on attributes into k numbers of groups. Its main aim is to partition n items into k clusters. The main idea is to define k centers, for each cluster. This centered k should be placed in such a way that the most accurate result will be obtained. This centered k plays an important role to get an accurate results.