In recent years, the field of machine learning has made significant advances in different problem types, from image recognition to natural language processing.
However, most of these models operate on data from a single modality, such as images, text, or speech. In contrast, real-world data often comes from multiple modalities, such as images and text, video and audio, or sensor data from multiple sources.
To address this challenge, researchers have developed multimodal machine learning models that can handle data from multiple modalities, unlocking new possibilities for intelligent systems.
In this blog post, we will explore the challenges and opportunities of multimodal machine learning, and discuss the different architectures and techniques used to tackle multimodal computer vision challenges.
What is Multimodal Deep Learning?
Multimodal Deep Learning is a subset of deep learning that deals with the fusion and analysis of data from multiple modalities, such as text, images, video, audio, and sensor data. Multimodal Deep Learning combines the strengths of different modalities to create a more complete representation of the data, leading to better performance on various machine learning tasks.
Traditionally, machine learning models were designed to work on data from a single modality, such as image classification or speech recognition. However, in the real world, data often comes from multiple sources and modalities, making it more complex and difficult to analyze. Multimodal Deep Learning aims to overcome this challenge by integrating information from different modalities to generate more accurate and informative models.
What is the Goal of Multimodal Deep Learning?
The primary goal of Multimodal Deep Learning is to create a shared representation space that can effectively capture complementary information from different modalities. This shared representation can then be used to perform various tasks, such as image captioning, speech recognition, and natural language processing.
Multimodal Deep Learning models typically consist of multiple neural networks, each specialized in analyzing a particular modality. The output of these networks is then combined using various fusion techniques, such as early fusion, late fusion, or hybrid fusion, to create a joint representation of the data.
Early fusion involves concatenating the raw data from different modalities into a single input vector and feeding it to the network. Late fusion, on the other hand, involves training separate networks for each modality and then combining their outputs at a later stage. Hybrid fusion combines elements of both early and late fusion to create a more flexible and adaptable model.
How Does Multimodal Learning Work?
Multimodal deep learning models are typically composed of multiple unimodal neural networks, which process each input modality separately. For instance, an audiovisual model may have two unimodal networks, one for audio and another for visual data. This individual processing of each modality is known as encoding.
Once unimodal encoding is done, the information extracted from each modality must be integrated or fused. There are several fusion techniques available, ranging from simple concatenation to attention mechanisms. Multimodal data fusion is a critical factor for the success of these models. Finally, a “decision” network accepts the fused encoded information and is trained on the task at hand.
In general, multimodal architectures consist of three parts:
- Unimodal encoders encode individual modalities. Usually, one for each input modality.
- A fusion network that combines the features extracted from each input modality, during the encoding phase.
- A classifier that accepts the fused data and makes predictions.
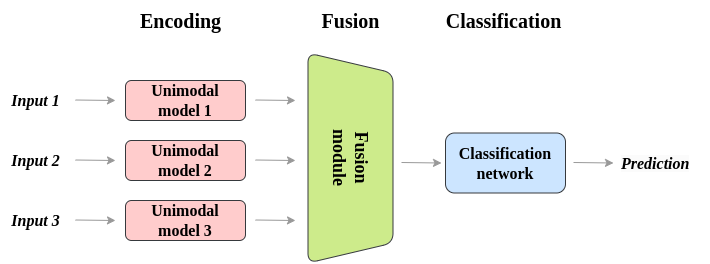
Encoding Stage
The encoder extracts features from the input data in each modality and converts them into a common representation that can be processed by subsequent layers in the model. The encoder is typically composed of several layers of neural networks that use nonlinear transformations to extract increasingly abstract features from the input data.
The input to the encoder can consist of data from multiple modalities, such as images, audio, and text, which are typically processed separately. Each modality has its own encoder that transforms the input data into a set of feature vectors. The output of each encoder is then combined into a single representation that captures the relevant information from each modality.
One popular approach for combining the outputs of the individual encoders is to concatenate them into a single vector. Another approach is to use attention mechanisms to weigh the contributions of each modality based on their relevance to the task at hand.
The overall goal of the encoder is to capture the underlying structure and relationships between the input data from multiple modalities, enabling the model to make more accurate predictions or generate new outputs based on this multimodal input.
Fusion Module
The fusion module combines information from different modalities (e.g., text, image, audio) into a single representation that can be used for downstream tasks such as classification, regression, or generation. The fusion module can take various forms depending on the specific architecture and task at hand
One common approach is to use a weighted sum of the modalities’ features, where the weights are learned during training. Another approach is to concatenate the modalities’ features and pass them through a neural network to learn a joint representation.
In some cases, attention mechanisms can be used to learn which modality should be attended to at each time step.
Regardless of the specific implementation, the goal of the fusion module is to capture the complementary information from different modalities and create a more robust and informative representation for the downstream task. This is especially important in applications such as video analysis, where combining visual and audio cues can greatly improve performance.
Classification
The classification module takes the joint representation generated by the fusion module and uses it to make a prediction or decision. The specific architecture and approach used in the classification module can vary depending on the task and type of data being processed.
In many cases, the classification module takes the form of a neural network, where the joint representation is passed through one or more fully connected layers before the final prediction is made. These layers can include non-linear activation functions, dropout, and other techniques to help prevent overfitting and improve generalization performance.
The output of the classification module depends on the specific task at hand. For example, in a multimodal sentiment analysis task, the output will be a binary decision indicating whether the text and image input is positive or negative. In a multimodal image captioning task, the output might be a sentence describing the content of the image.
The classification module is typically trained using a supervised learning approach, where the input modalities and their corresponding labels or targets are used to optimize the parameters of the model. This optimization is often done using gradient-based optimization methods such as stochastic gradient descent or its variants.
In review, the classification module plays a critical role in multimodal deep learning by taking the joint representation generated by the fusion module and using it to make an informed decision or prediction.
Multimodal Learning in Computer Vision
In recent years, multimodal learning has emerged as a promising approach to tackle complex computer vision tasks by combining information from multiple modalities such as images, text, and speech.
This approach has enabled significant progress in several areas, including:
- Visual question answering;
- Text-to-image generation, and;
- Natural language for visual reasoning.
In this section, we will explore how multimodal learning models have revolutionized computer vision and made it possible to achieve impressive results in challenging tasks that previously seemed impossible. Specifically, we will dive into the workings of three popular uses of multimodal architectures in the computer vision field: Visual Question Answering (VQA), Text-to-Image Generation, and Natural Language for Visual Reasoning (NLVR).
Visual Question Answering (VQA)
Visual Question Answering (VQA) involves answering questions based on visual input, such as images or videos, using natural language. VQA is a challenging task that requires a deep understanding of both computer vision and natural language processing.
In recent years, VQA has seen significant progress due to the use of deep learning techniques and architectures, particularly the Transformer architecture. The Transformer architecture was originally introduced for language processing tasks and has shown great success in VQA.
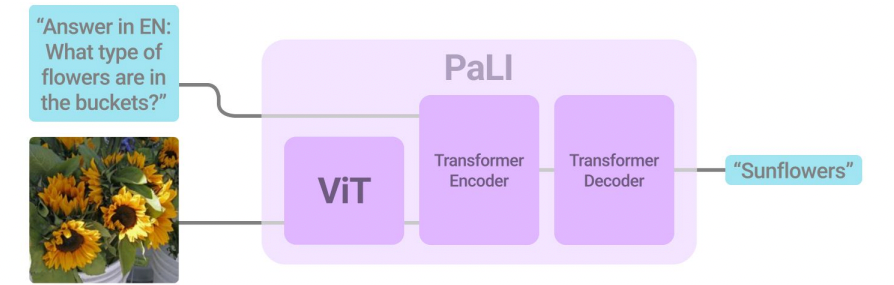
One of the most successful models for VQA is the PaLI (Pathways Language and Image model) model developed by Google Research in 2022. PaLI architecture uses an encoder-decoder Transformer model, with a large-capacity ViT component for image processing.
Text-to-Image Generation
In text-to-image generation, a machine learning model is trained to generate images based on textual descriptions. The goal is to create a system that can understand natural language and use that understanding to generate visual content that accurately represents the meaning of the input text.https://www.youtube.com/embed/LM8dil6n5h8?feature=oembed
The two most recent and successful models are DALL-E and Stable Diffusion.
DALL-E is a text-to-image generation model developed by OpenAI, which uses a combination of a transformer-based language model and a generative neural network architecture. The model takes in a textual description and generates an image that satisfies the description. DALL-E can generate a wide variety of complex and creative images, such as a snail made of harps and a collage of a red tree kangaroo in a field of daisies.
One of the key innovations in DALL-E is the use of a discrete latent space, which allows the model to learn a more structured and controllable representation of the generated images. DALL-E is trained on a large dataset of image-text pairs, and the model is optimized using a variant of the VAE loss function called the Gumbel-Softmax trick.
The Stable Diffusion architecture is a recent technique for generating high-quality images based on text prompts. Stable Diffusion uses a diffusion process, which involves iteratively adding noise to an initial image and then progressively removing the noise.

By controlling the level of noise and the number of iterations, Stable Diffusion can generate diverse and high-quality images that match the input text prompt.
The key innovation in Stable Diffusion is the use of a diffusion process that allows for stable and diverse image generation. In addition, diffusion uses a contrastive loss function to encourage the generated images to be diverse and distinct from each other. Diffusion has achieved impressive results in text-to-image generation, and it can generate high-quality images that closely match the input text prompts.
Natural Language for Visual Reasoning (NLVR)
Natural Language for Visual Reasoning (NLVR) aims to evaluate the ability of models to understand and reason about natural language descriptions of visual scenes. In this task, a model is given a textual description of a scene and two corresponding images, one of which is consistent with the description and the other not. The objective of the model is to identify the correct image that matches the given textual description.
NLVR requires the model to understand complex linguistic structures and reason about visual information to make the correct decision. The task involves a variety of challenges, such as understanding spatial relations, recognizing objects and their properties, and understanding the semantics of natural language.
The current state-of-the-art on the NLVR task is reached by BEiT-3. It is a transformer-based model that has been pre-trained on large-scale datasets of natural images and texts, such as ImageNet and Conceptual Captions.
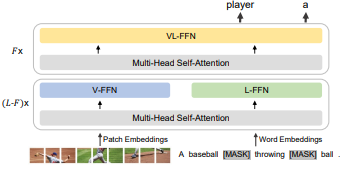
BEiT-3 is designed to handle both natural language and visual information and is capable of reasoning about complex linguistic structures and visual scenes.
The architecture of BEiT-3 is similar to that of other transformer-based models, such as BERT and GPT, but with some modifications to handle visual data. The model consists of an encoder and a decoder, where the encoder takes in both the visual and textual inputs and the decoder produces the output.
Challenges Building Multimodal Model Architectures
Multimodal Deep Learning has revolutionized the way we approach complex data analysis tasks, such as image and speech recognition. However, working with data from multiple modalities poses unique challenges that must be addressed to achieve optimal performance.
In this section, we will discuss some of the key challenges associated with Multimodal Deep Learning.
Alignment
Alignment is the process of ensuring that data from different modalities are synchronized or aligned in time, space, or any other relevant dimension. The lack of alignment between modalities can lead to inconsistent or incomplete representations, which can negatively impact the performance of the model.
Alignment can be particularly challenging in scenarios where the modalities are acquired at different times or from different sources. A prime example of a situation where alignment is a difficult challenge to solve is in video analysis. Aligning the audio with the visual information can be challenging due to the latency introduced by the data acquisition process. Similarly, in speech recognition, aligning the audio with the corresponding transcription can be difficult due to variations in speaking rates, accents, and background noise.
Several techniques have been proposed to address the alignment challenge in multimodal machine learning models. For instance, temporal alignment methods can be used to align the data in time by estimating the time offset between modalities. Spatial alignment methods can be used to align data in space by identifying corresponding points or features in different modalities.
Additionally, deep learning techniques, such as attention mechanisms, can be used to automatically align the data during the model training process. However, each alignment technique has its strengths and limitations, and the choice of alignment method depends on the specific problem and the characteristics of the data.
Co-learning
Co-learning involves jointly learning from multiple modalities to improve the performance of the model. In co-learning, the model learns from the correlations and dependencies between the different modalities, which can lead to a more robust and accurate representation of the underlying data.
Co-learning requires designing models that can handle the heterogeneity and variability of the data from different modalities, while also identifying the relevant information that can be shared across modalities. This is challenging. Additionally, co-learning can lead to the problem of negative transfer, where learning from one modality negatively impacts the performance of the model on another modality.
To address the co-learning challenge in multimodal machine learning models, several techniques have been proposed. One approach is to use joint representation learning methods, such as deep canonical correlation analysis (DCCA) or cross-modal deep metric learning (CDML), which aim to learn a shared representation that captures the correlations between the modalities. Another approach is to use attention mechanisms that can dynamically allocate the model’s resources to the most informative modalities or features.
Co-learning is still an active research area in multimodal machine learning, and there are many open questions and challenges to be addressed, such as how to handle missing modalities or how to incorporate prior knowledge into the learning process.
Translation
Translation involves converting the data from one modality or language to another. For example, translating speech to text, text to speech, or image to text.
Multimodal machine learning models that require translation must take into account the differences in the structure, syntax, and semantics between the source and target languages or modalities. Additionally, they must be able to handle the variability in the input data, such as different accents or dialects, and adapt to the context of the input.
There are several approaches to address the translation challenge in multimodal machine learning models. One common approach is to use neural machine translation (NMT) models, which have shown great success in translating text from one language to another. NMT models can also be used to translate speech to text or vice versa by training on paired audio-text data. Another approach is to use multimodal models that can learn to map data from one modality to another, such as image-to-text or speech-to-text translation.
However, translating between modalities or languages is a challenging task. The performance of the translation models heavily depends on the quality and size of the training data, the complexity of the task, and the availability of computing resources.
Fusion
Fusion involves combining information from different modalities to make a decision or prediction. There are different ways to fuse data, including early fusion, late fusion, and hybrid fusion.
Early fusion involves combining the raw data from different modalities at the input level. This approach requires aligning and pre-processing the data, which can be challenging due to differences in data formats, resolutions, and sizes.
Late fusion, on the other hand, involves processing each modality separately and then combining the outputs at a later stage. This approach can be more robust to differences in data formats and modalities, but it can also lead to the loss of important information.
Hybrid fusion is a combination of both early and late fusion approaches, where some modalities are fused at the input level, while others are fused at a later stage.
Choosing the appropriate fusion method is critical to the success of a multimodal machine learning model. The fusion method must be tailored to the specific problem and the characteristics of the data. Additionally, the fusion method must be designed to preserve the most relevant information from each modality and avoid the introduction of noise or irrelevant information.
Conclusion
Multimodal Deep Learning is an exciting and rapidly evolving field that holds great potential for advancing computer vision and other areas of artificial intelligence.
Through the integration of multiple modalities, including visual, textual, and auditory information, multimodal learning allows machines to perceive and interpret the world around them in ways that were once only possible for humans.
In this post, we highlighted three key applications of multimodal learning in computer vision: Visual Question Answering, Text-to-Image Generation, and Natural Language for Visual Reasoning.
While there are challenges associated with multimodal learning, including the need for large amounts of training data and the difficulty of fusing information from multiple modalities, recent advances in deep learning models have led to significant improvements in performance across a range of tasks.