The Internet of Things, or IoT, is an interrelated system of unique identifiers, such as a computing device or a tracking tag on an animal, that transfers data over a network without human or computer interaction.
International Data Corporation predicts that by 2025, 41.6 billion connected IoT devices will generate 79.4 zettabytes of data, which is the equivalent of almost 86 trillion gigabytes. Much of this big data will be used for machine learning, which trains models to make output predictions or inferences without the need to be explicitly programmed. In general terms, ML is the use of data to teach a computer how to answer questions correctly, most of the time.
What Is Machine Learning?
People often consider machine learning and artificial intelligence to be the same. However, the terms are not synonymous.
Artificial intelligence is the science of training machines to perform human tasks, whereas machine learning is a subset of artificial intelligence that instructs a machine how to learn.
Without machine learning, you have no AI. The ML process incorporates various machine learning algorithms that allow a system to identify patterns and make decisions without human involvement.
Although not evident on the surface, ML is responsible for many of your everyday interactions with technology. A few of the devices and applications that rely on machine learning are:
- Mobile devices
- Self-driving cars
- Google search
- Netflix movie recommendations
- Facial recognition
- Mobile check deposits
- Wearable fitness trackers and smartwatches
The world of IoT, including devices such as smart home assistants, appliances and toys, depends on machine learning algorithms to improve user experience.
Machine Learning Steps
To achieve the outputs necessary for today’s technology, data scientists must follow several steps:
- Define the problem or ask a question.
- Gather dataset.
- Data cleanup and feature engineering —Address outliers, missing values and other issues that may affect your output. Choose the essential features, represented by columns that you wish to look at through data normalization or standardization. Augment with additional columns or remove unnecessary columns.
- Choose algorithm — Supervised vs. unsupervised learning.
- Train model — Develop a model that surpasses that of a baseline.
- Evaluate model — Determine an evaluation protocol and a measure of success.
- Tune the algorithm.
- Predict and present results; retune if necessary.
Which algorithm you choose for your project will be dependent on the type of data you use. Whether it be nominal, binary, ordinal or interval, machine learning can find valuable insights.
Machine Learning Algorithms
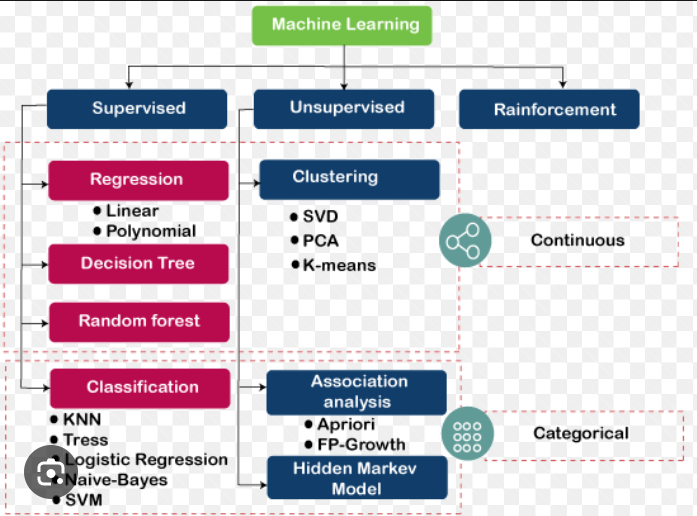
There are three main sets of machine learning algorithms: Supervised and unsupervised, including their ever-growing number of subtypes, and reinforcement learning algorithms.
Most machine learning uses supervised learning algorithms, which are indicated by the use of labeled data (such as time and weather) that entails both input (x) and output (y) variables. You, as the “teacher,” know the correct answer(s) and supervise the algorithm as it makes predictions based on the training data. If necessary, you make corrections until the algorithm achieves an adequate level of execution.
Although there are a variety of supervised machine learning algorithms, the most commonly used include:
- Linear regression
- Logistic regression
- Decision tree
- Random forest classification algorithm
Unsupervised machine learning algorithms are used for unstructured data to find common characteristics and distinct patterns in the dataset. Because this type of ML algorithm does not require prior training or labeled data, it is free to explore the structure of the information.
Similar to supervised machine learning algorithms, there are several types of unsupervised algorithms, such as kernel methods and k-means clustering.
Linear Regression
A simple variable linear regression technique is a type of ML algorithm that demonstrates how a single input-independent variable (feature variable) and an output-dependent variable work together.
More common is the multivariable linear regression algorithm, which determines the relationship between multiple input variables and an output variable. Regression models are intended to be used with real values such as integers or floating-point values (quantities, amounts and sizes).
Advantages: Quick to model. Simple to understand. Useful for smaller datasets that aren’t overly complicated.
Disadvantages: Difficult to design for nonlinear data. Tends to be ineffectual when working with highly complex data.
Logistic Regression
An alternative regression machine learning algorithm is the logistic model. This technique is designed for binary classification problems, as indicated by two possible outcomes that are affected by one or more explanatory variables.
Simple to interpret and versatile in its uses, logistic regression is ideal for applications where interpretability and inference are vital, such as fraud detection.
Advantages: Easy to implement and interpret. Suited well for a linearly separable dataset.
Disadvantages: An excessive amount of data creates a complex model that can lead to overfitting in high-dimensional datasets (number of features is higher than observations). Logistic regression assumes linearity between the dependent and independent variables.
Decision Trees
This class of powerful machine learning algorithms is capable of achieving high levels of accuracy and is highly interpretable. Knowledge learned by a decision tree algorithm is expressed as a hierarchical structure, or “tree,” complete with various nodes and branches.
Each decision node represents a question about the data, and the branches that stem from a node represent possible answers. A secondary type of node, which is less certain in its responses, is a chance node. An end node is indicated at the end of the decision-making process.
Decision tree machine learning algorithms can be used to solve both classification and regression problems, often referred to as CART. A decision tree technique is useful at identifying trends.
Advantages: Easy to explain. Does not require normalization or scaling of data.
Disadvantages: Can lead to overfitting. Affected by noise (distortions in the information can cause the algorithm to miss patterns in the data). Not suitable for large datasets.
Random Forest
A random forest machine learning algorithmExternal link:open_in_new is considered an ensemble method because it is a collection of hundreds and sometimes thousands of decision trees. The model increases predictive power by combining the decisions of each decision tree to find an answer. The random forest algorithm learns how to classify unlabeled data by using labeled data.
The random forest technique is simple, highly accurate and widely used by engineers.
Advantages: Applicable for both regression and classification problems. Efficient on large datasets. Works well with missing data.
Disadvantages: Not easily interpretable. Can cause overfitting if noise is detected. Slower than other models at creating predictions.
Neural Networks
This subset of machine learning is inspired by the neural networks within the human brain. A neural network machine learning algorithm is built with artificial neurons spread throughout three or more layers, which provides the observer with a greater amount of data in a more detailed and distinct way.
Because of these several layers and the fact that the process is human-like, the neural network machine learning algorithm is regarded as deep learning. Real-world applications include Apple’s Face ID, and it is the power behind GoogLeNetExternal link:open_in_new and Google search engine results.
Neural networks can be utilized for regression problems and are ideal for dealing with high-dimensional issues like speech and object recognition.
Advantages: Provides better results with an extensive amount of data. Able to work with incomplete information. Parallel processing ability.
Disadvantages: Requires much more data than other machine learning algorithms. The method has a “black box” nature, which means we do not know how or why the model came up with a particular output. Computationally expensive.
Kernel Methods
Kernel methodsExternal link:open_in_new are a group of supervised or unsupervised machine learning algorithms used for pattern analysis. They locate and examine general types of relations, such as rankings, clusters or classifications in datasets, and separate the data points between two categories. The most popular kernel method application is the support vector machine (SVM).
Kernel functions work in graphs, text, images, vectors and sequential data. They can help turn any linear model into a nonlinear model when instance-based learning is needed.
Advantages: Effective in high-dimensional spaces. Unlikely to overfit. Versatile. Useful in data mining.
Disadvantages: Complex, which requires a high amount of memory. Does not scale well to larger datasets. Random forest is typically preferred over SVMs.
K-Means Clustering
The simple k-means clustering technique is one of the most popular unsupervised machine learning algorithms. Its objective is to place (n) observations into a number of clusters (k). Each group contains observations, or data points, that have similar features, while k serves as the prototype of each. The purpose of this technique is to minimize within-cluster variances.
Fields that utilize this type of machine learning algorithm include data mining, marketing, science, city planning and insurance.
Advantages: Relatively simple to implement. Adapts to new examples. Scales to large datasets.
Disadvantages: Sensitivity to scale. Can only be used with numeric data. You must determine the number of clusters. Lacks consistency.