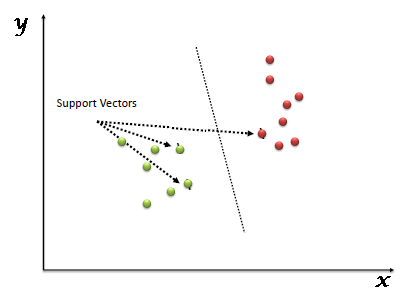
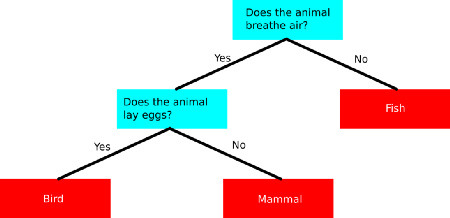
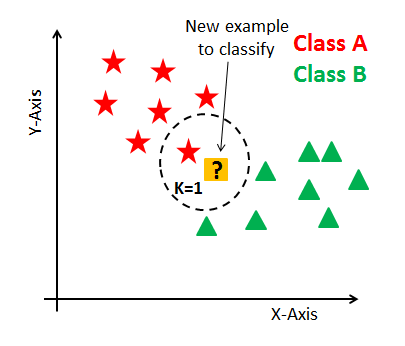
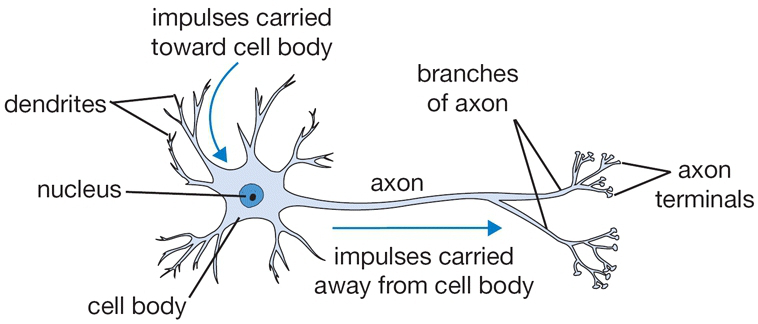
Introduction
Machine learning is a powerful tool for making predictions and finding patterns in data. However, building accurate models is not always straightforward. One of the main challenges in machine learning is finding the right balance between overfitting and underfitting.
Overfitting occurs when a model is too complex and fits too closely to the training data, resulting in poor performance on new data. Underfitting occurs when a model is too simple and fails to capture the underlying patterns in the data, also resulting in poor performance.
The Goldilocks Principle suggests that there is a “just right” level of complexity that achieves the best performance on new data.
In this article, we’ll explore the causes of overfitting and underfitting, and techniques for addressing them. We’ll also discuss the Goldilocks Principle and how it can be applied to machine learning. By finding the optimal balance between overfitting and underfitting, we can build models that generalize well to new data and make accurate predictions.
Overfitting
Overfitting occurs when a model becomes too complex and starts to memorize the training data instead of learning the underlying patterns. This can lead to the model performing well on the training data but poorly on new, unseen data.
A common example of overfitting is when a model fits the noise in the data instead of the underlying pattern. For instance, consider a dataset of housing prices where the target variable is the price of a house. One of the features in the dataset is the zip code of the house. If the model is too complex, it may start to memorize the housing prices of each zip code, including the noise in the data, instead of learning the underlying relationship between the zip code and the housing price.
Another example of overfitting is when a model is trained on a small dataset. In this case, the model may start to memorize the training data instead of learning the underlying patterns, leading to poor performance on new, unseen data.
To illustrate this, consider a model trained to classify images of cats and dogs. If the model is trained on a small dataset of only a few hundred images, it may start to memorize the training data instead of learning the underlying patterns that distinguish cats from dogs. This can lead to poor performance on new, unseen data, where the model may misclassify images of cats as dogs or vice versa.
In both of these examples, the model is too complex and is overfitting the training data, leading to poor performance on new, unseen data. In the next section, we will explore the various factors that can contribute to overfitting and techniques for addressing it.

Causes and Addressing Overfitting
Overfitting can occur due to various factors, such as the complexity of the model, the size of the dataset, and the noise in the data. Here are some techniques for addressing overfitting:
- Regularization: Regularization is a technique that adds a penalty term to the loss function of the model to prevent it from overfitting. The penalty term adds a constraint on the weights of the model, making them smaller and reducing the complexity of the model. Two common types of regularization are L1 regularization and L2 regularization.
- Early stopping: Early stopping is a technique where the training of the model is stopped when the performance on a validation set starts to degrade. This prevents the model from overfitting by finding the optimal point where the model has learned the underlying patterns but has not started to memorize the training data.
- Data augmentation: Data augmentation is a technique where new training data is generated by applying various transformations to the existing data, such as flipping or rotating images. This increases the size of the dataset and helps the model learn the underlying patterns instead of memorizing the training data.
- Dropout: Dropout is a technique where random nodes in the model are temporarily removed during training. This prevents the model from relying too much on any single node or feature, forcing it to learn more robust features that generalize well to new, unseen data.
In summary, overfitting can occur due to various factors, such as the complexity of the model and the size of the dataset. Regularization, early stopping, data augmentation, and dropout are some techniques for addressing overfitting and building machine learning models that can generalize well to new, unseen data.
Underfitting
Underfitting occurs when a model is too simple and is unable to capture the underlying patterns in the data. This can lead to poor performance on both the training data and new, unseen data.
A common example of underfitting is when a linear model is used to fit a non-linear relationship between the features and the target variable. In this case, the linear model may not be able to capture the non-linear relationship, leading to poor performance on both the training data and new, unseen data.
Another example of underfitting is when a model is not trained for long enough. In this case, the model may not have enough time to learn the underlying patterns in the data, leading to poor performance on both the training data and new, unseen data.
To illustrate this, consider a model trained to predict the price of a house based on the number of bedrooms and bathrooms. If the model is too simple, it may only consider the number of bedrooms and bathrooms and ignore other important features, such as the location of the house and the size of the lot. This can lead to poor performance on both the training data and new, unseen data.
In summary, underfitting occurs when a model is too simple and is unable to capture the underlying patterns in the data. This can lead to poor performance on both the training data and new, unseen data. In the next section, we will explore the various factors that can contribute to underfitting and techniques for addressing it.
Causes and Addressing Underfitting
Underfitting can occur due to various factors, such as the simplicity of the model, the lack of relevant features, and insufficient training. Here are some techniques for addressing underfitting:
- Increasing model complexity: If a model is too simple and is unable to capture the underlying patterns in the data, one approach is to increase the complexity of the model. This can be done by adding more layers or nodes to a neural network, increasing the polynomial degree of a regression model, or using a more complex algorithm.
- Adding relevant features: If a model is unable to capture the underlying patterns in the data due to a lack of relevant features, one approach is to add additional features to the dataset. This can be done by collecting more data or engineering new features from existing data.
- Increasing training time: If a model is unable to capture the underlying patterns in the data due to insufficient training, one approach is to increase the training time. This can be done by training the model for longer or using more training data.
- Ensemble methods: Ensemble methods are a technique where multiple models are trained on the same dataset and their predictions are combined to make a final prediction. This can help address underfitting by combining the strengths of multiple models to capture the underlying patterns in the data.
In summary, underfitting can occur due to various factors, such as the simplicity of the model, the lack of relevant features, and insufficient training. Increasing model complexity, adding relevant features, increasing training time, and ensemble methods are some techniques for addressing underfitting and building machine learning models that can capture the underlying patterns in the data.
Balancing Overfitting and Underfitting
The goal of building a machine learning model is to find the right balance between overfitting and underfitting. This balance is known as the bias-variance tradeoff.
Bias refers to the error that is introduced by approximating a real-world problem with a simpler model. High bias models are typically simple models that underfit the data.
Variance refers to the error that is introduced by the model’s sensitivity to small fluctuations in the training data. High variance models are typically complex models that overfit the data.
A good model should have low bias and low variance. This means that the model should capture the underlying patterns in the data without being overly sensitive to noise or small fluctuations in the data.
To find the right balance between overfitting and underfitting, it is important to tune the model’s hyperparameters. Hyperparameters are parameters that are not learned during training, but are set by the user before training. Examples of hyperparameters include the learning rate, the number of hidden layers in a neural network, and the regularization strength.
One common approach to balancing overfitting and underfitting is to use a validation set. A validation set is a portion of the training data that is set aside for testing the model during training. By evaluating the model’s performance on the validation set, the user can adjust the hyperparameters to find the right balance between overfitting and underfitting.
Another approach to balancing overfitting and underfitting is to use regularization. Regularization is a technique that penalizes large weights in the model, which can help prevent overfitting. Common forms of regularization include L1 and L2 regularization, which add a penalty term to the loss function to encourage the model to have smaller weights.
In summary, balancing overfitting and underfitting is a critical part of building machine learning models that can capture the underlying patterns in the data. Tuning the model’s hyperparameters, using a validation set, and regularization are some techniques for finding the right balance between overfitting and underfitting.
Conclusion
In this article, we explored the concepts of overfitting and underfitting in machine learning. Overfitting occurs when a model is overly complex and captures noise in the training data, while underfitting occurs when a model is too simple and fails to capture the underlying patterns in the data.
We discussed the causes of overfitting and underfitting and presented several techniques for addressing these issues, including regularization, early stopping, and increasing the complexity of the model.
Finding the right balance between overfitting and underfitting is a critical part of building machine learning models that can generalize to new data. Tuning the model’s hyperparameters and using a validation set can help find this balance.
Ultimately, the success of a machine learning model depends on its ability to accurately predict on new data. By understanding the concepts of overfitting and underfitting, and how to address them, we can build models that are more accurate and effective in solving real-world problems.