This is an intermediate level course. You should know Python programming, have basic math knowledge, and basic concepts of machine learning before enrolling.
Description
You’re going to learn hands-on artificial neural networks with neurolab, a lesser-known and traditional Python library for artificial intelligence. This is a hands-on course and you will be working your way through with Python and Jupyter notebooks.
What you will learn:
Basic concepts of neural networks (refresher)
The perceptron
Single-layer neural network
Multi-layer neural network
Recurrent neural networks (RNN)
Optical character recognition (OCR)
Who this course is for:
This course is for you if want to learn practical machine learning
This course is also for you if you’re a machine learning professional or work in a management position and want to expand your technical knowledge in the field
If you’re a student, know some programming and want to learn about artificial neural networks with lesser know libraries, this course is also for you
How to implement an Artificial Neural Network in Python
How to do Regression
How to use Google Colab
Requirements
Deep Learning Basics
Description
Are you ready to flex your Deep Learning skills by learning how to build and implement an Artificial Neural Network using Python from scratch?
Testing your skills with practical courses is one of the best and most enjoyable ways to learn data science…and now we’re giving you that chance for FREE.
In this free course, AI expert Hadelin de Ponteves guides you through a case study that shows you how to build an ANN Regression model to predict the electrical energy output of a Combined Cycle Power Plant.
The objective is to create a data model that predicts the net hourly electrical energy output (EP) of the plant using available hourly average ambient variables.
Go hands-on with Hadelin in solving this complex, real-world Deep Learning challenge that covers everything from data preprocessing to building and training an ANN, while utilizing the Machine Learning library, Tensorflow 2.0, and Google Colab, the free, browser-based notebook environment that runs completely in the cloud. It’s a game-changing interface that will supercharge your Machine Learning toolkit.
Check out what’s in store for you when you enroll:
Part 1: Data Preprocessing
Importing the dataset
Splitting the dataset into the training set and test set
Part 2: Building an ANN
Initializing the ANN
Adding the input layer and the first hidden layer
Adding the output layer
Compiling the ANN
Part 3: Training the ANN
Training the ANN model on the training set
Predicting the results of the test set
More about Combined-Cycle Power Plants
A combined-cycle power plant is an electrical power plant in which a Gas Turbine (GT) and a Steam Turbine (ST) are used in combination to produce more electrical energy from the same fuel than that would be possible from a single cycle power plant.
The gas turbine compresses air and mixes it with a fuel heated to a very high temperature. The hot air-fuel mixture moves through the blades, making them spin. The fast-spinning gas turbine drives a generator to generate electricity. The exhaust (waste) heat escaped through the exhaust stack of the gas turbine is utilized by a Heat Recovery Steam Generator (HSRG) system to produce steam that spins a steam turbine. This steam turbine drives a generator to produce additional electricity. CCCP is assumed to produce 50% more energy than a single power plant.
Who this course is for:
Anyone interested in Machine Learning and Deep Learning
Learn about the basics of neural network models without any prior knowledge
Learn to use python to design a neural network model without any prior knowledge
Learn from top tier Data Scientists to build neural network models for production
Learn to develop your own customized neural network models
Requirements
No prior programming experience needed. You will learn directly in this class.
Description
This course is created to follow up with the AI4ALL initiatives. The course presents coding materials at a pre-college level and introduces a fundamental pipeline for a neural network model. The course is designed for the first-time learners and the audience who only want to get a taste of a machine learning project but still uncertain whether this is the career path. We will not bored you with the unnecessary component and we will directly take you through a list of topics that are fundamental for industry practitioners and researchers to design their customized neural network model. The course focuses on the Artificial Neural Network models and introduce the important building block using Tensorflow.
This instructor team is lead by Ivy League graduate students and we have had 3+ years coaching high school students. We have seen all the ups and downs. Moreover, we want to share these roadblocks with you. This course is designed for beginner students at pre-college level who just want to have a quick taste of what AI is about and efficiently build a quick Github package to showcase some technical skills. We have other longer courses for more advanced students. However, we welcome anybody to take this course!
Who this course is for:
Pre-college level students interested in neural network models
Summary: EPFL researchers have developed a novel machine-learning algorithm called CEBRA, which can predict what mice see based on decoding their neural activity.
The algorithm maps brain activity to specific frames and can predict unseen movie frames directly from brain signals alone after an initial training period.
CEBRA can also be used to predict movements of the arm in primates and to reconstruct the positions of rats as they move around an arena, suggesting potential clinical applications.
Key Facts:
Researchers from École polytechnique fédérale de Lausanne (EPFL) have developed a machine-learning algorithm called CEBRA that can learn the hidden structure in neural code to reconstruct what a mouse sees when it watches a movie or the movements of the arm in primates.
CEBRA is based on contrastive learning, a technique that enables researchers to consider neural data and behavioral labels like reward, measured movements, or sensory features such as colors or textures of images.
CEBRA’s strengths include its ability to combine data across modalities, limit nuances, and reconstruct synthetic data. The algorithm has exciting potential applications in animal behavior, gene-expression data, and neuroscience research.
Source: EPFL
Is it possible to reconstruct what someone sees based on brain signals alone? The answer is no, not yet. But EPFL researchers have made a step in that direction by introducing a new algorithm for building artificial neural network models that capture brain dynamics with an impressive degree of accuracy.
Rooted in mathematics, the novel machine learning algorithm is called CEBRA (pronounced zebra), and learns the hidden structure in the neural code.
What information the CEBRA learns from the raw neural data can be tested after training by decoding – a method that is used for brain-machine-interfaces (BMIs) – and they’ve shown they can decode from the model what a mouse sees while it watches a movie.
But CEBRA is not limited to visual cortex neurons, or even brain data. Their study also shows it can be used to predict the movements of the arm in primates, and to reconstruct the positions of rats as they freely run around an arena.
The study is published in Nature.
“This work is just one step towards the theoretically-backed algorithms that are needed in neurotechnology to enable high-performance BMIs,” says Mackenzie Mathis, EPFL’s Bertarelli Chair of Integrative Neuroscience and PI of the study.
For learning the latent (i.e., hidden) structure in the visual system of mice, CEBRA can predict unseen movie frames directly from brain signals alone after an initial training period mapping brain signals and movie features.
The data used for the video decoding was open-access through the Allen Institute in Seattle, WA. The brain signals are obtained either directly by measuring brain activity via electrode probes inserted into the visual cortex area of the mouse’s brain, or using optical probes which consist of using genetically modified mice, engineered so that activated neurons glow green.
During the training period, CEBRA learns to map the brain activity to specific frames. CEBRA performs well with less than 1% of neurons in the visual cortex, considering that, in mice, this brain area consists of roughly 0.5 million neurons.
“Concretely, CEBRA is based on contrastive learning, a technique that learns how high-dimensional data can be arranged, or embedded, in a lower-dimensional space called a latent space, so that similar data points are close together and more-different data points are further apart,” explains Mathis.
“This embedding can be used to infer hidden relationships and structure in the data. It enables researchers to jointly consider neural data and behavioral labels, including measured movements, abstract labels like “reward,” or sensory features such as colors or textures of images.”
“CEBRA excels compared to other algorithms at reconstructing synthetic data, which is critical to compare algorithms,” says Steffen Schneider, the co-first author of the paper. “Its strengths also lie in its ability to combine data across modalities, such as movie features and brain data, and it helps limit nuances, such as changes to the data that depend on how they were collected.”
“The goal of CEBRA is to uncover structure in complex systems. And, given the brain is the most complex structure in our universe, it’s the ultimate test space for CEBRA. It can also give us insight into how the brain processes information and could be a platform for discovering new principles in neuroscience by combining data across animals, and even species.” says Mathis.
“This algorithm is not limited to neuroscience research, as it can be applied to many datasets involving time or joint information, including animal behavior and gene-expression data. Thus, the potential clinical applications are exciting.”
About this machine learning research news
Author: Press Office Source: EPFL Contact: Press Office – EPFL Image: The image is credited to Neuroscience News
Original Research: Open access. “Learnable latent embeddings for joint behavioural and neural analysis” by Mackenzie Mathis et al. Nature
Abstract
Learnable latent embeddings for joint behavioural and neural analysis
Mapping behavioural actions to neural activity is a fundamental goal of neuroscience. As our ability to record large neural and behavioural data increases, there is growing interest in modelling neural dynamics during adaptive behaviours to probe neural representations.
In particular, although neural latent embeddings can reveal underlying correlates of behaviour, we lack nonlinear techniques that can explicitly and flexibly leverage joint behaviour and neural data to uncover neural dynamics.
Here, we fill this gap with a new encoding method, CEBRA, that jointly uses behavioural and neural data in a (supervised) hypothesis- or (self-supervised) discovery-driven manner to produce both consistent and high-performance latent spaces. We show that consistency can be used as a metric for uncovering meaningful differences, and the inferred latents can be used for decoding.
We validate its accuracy and demonstrate our tool’s utility for both calcium and electrophysiology datasets, across sensory and motor tasks and in simple or complex behaviours across species. It allows leverage of single- and multi-session datasets for hypothesis testing or can be used label free.
Lastly, we show that CEBRA can be used for the mapping of space, uncovering complex kinematic features, for the production of consistent latent spaces across two-photon and Neuropixels data, and can provide rapid, high-accuracy decoding of natural videos from visual cortex.
Machine learning is a subset of artificial intelligence (AI) in which computers learn from data and improve with experience without being explicitly programed.
Machine learning definition in detail
Machine learning is a subset of artificial intelligence (AI). It is focused on teaching computers to learn from data and to improve with experience – instead of being explicitly programmed to do so. In machine learning, algorithms are trained to find patterns and correlations in large data sets and to make the best decisions and predictions based on that analysis. Machine learning applications improve with use and become more accurate the more data they have access to.
Applications of machine learning are all around us –in our homes, our shopping carts, our entertainment media, and our healthcare.
How is machine learning related to AI?
Machine learning – and its components of deep learning and neural networks – all fit as concentric subsets of AI. AI processes data to make decisions and predictions. Machine learning algorithms allow AI to not only process that data, but to use it to learn and get smarter, without needing any additional programming. Artificial intelligence is the parent of all the machine learning subsets beneath it. Within the first subset is machine learning; within that is deep learning, and then neural networks within that.
Diagram of the relationship between AI and machine learning
What is a neural network?
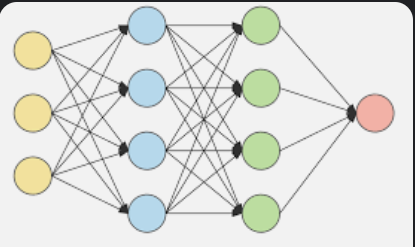
An artificial neural network (ANN) is modeled on the neurons in a biological brain. Artificial neurons are called nodes and are clustered together in multiple layers, operating in parallel. When an artificial neuron receives a numerical signal, it processes it and signals the other neurons connected to it. As in a human brain, neural reinforcement results in improved pattern recognition, expertise, and overall learning.
What is deep learning?
This kind of machine learning is called “deep” because it includes many layers of the neural network and massive volumes of complex and disparate data. To achieve deep learning, the system engages with multiple layers in the network, extracting increasingly higher-level outputs. For example, a deep learning system that is processing nature images and looking for Gloriosa daisies will – at the first layer – recognize a plant. As it moves through the neural layers, it will then identify a flower, then a daisy, and finally a Gloriosa daisy. Examples of deep learning applications include speech recognition, image classification, and pharmaceutical analysis.
How does machine learning work?
Machine learning is comprised of different types of machine learning models, using various algorithmic techniques. Depending upon the nature of the data and the desired outcome, one of four learning models can be used: supervised, unsupervised, semi-supervised, or reinforcement. Within each of those models, one or more algorithmic techniques may be applied – relative to the data sets in use and the intended results. Machine learning algorithms are basically designed to classify things, find patterns, predict outcomes, and make informed decisions. Algorithms can be used one at a time or combined to achieve the best possible accuracy when complex and more unpredictable data is involved.
How the machine learning process works
What is supervised learning?
Supervised learning is the first of four machine learning models. In supervised learning algorithms, the machine is taught by example. Supervised learning models consist of “input” and “output” data pairs, where the output is labeled with the desired value. For example, let’s say the goal is for the machine to tell the difference between daisies and pansies. One binary input data pair includes both an image of a daisy and an image of a pansy. The desired outcome for that particular pair is to pick the daisy, so it will be pre-identified as the correct outcome.
By way of an algorithm, the system compiles all of this training data over time and begins to determine correlative similarities, differences, and other points of logic – until it can predict the answers for daisy-or-pansy questions all by itself. It is the equivalent of giving a child a set of problems with an answer key, then asking them to show their work and explain their logic. Supervised learning models are used in many of the applications we interact with every day, such as recommendation engines for products and traffic analysis apps like Waze, which predict the fastest route at different times of day.
What is unsupervised learning?
Unsupervised learning is the second of the four machine learning models. In unsupervised learning models, there is no answer key. The machine studies the input data – much of which is unlabeled and unstructured – and begins to identify patterns and correlations, using all the relevant, accessible data. In many ways, unsupervised learning is modeled on how humans observe the world. We use intuition and experience to group things together. As we experience more and more examples of something, our ability to categorize and identify it becomes increasingly accurate. For machines, “experience” is defined by the amount of data that is input and made available. Common examples of unsupervised learning applications include facial recognition, gene sequence analysis, market research, and cybersecurity.
What is semi-supervised learning?
Semi-supervised learning is the third of four machine learning models. In a perfect world, all data would be structured and labeled before being input into a system. But since that is obviously not feasible, semi-supervised learning becomes a workable solution when vast amounts of raw, unstructured data are present. This model consists of inputting small amounts of labeled data to augment unlabeled data sets. Essentially, the labeled data acts to give a running start to the system and can considerably improve learning speed and accuracy. A semi-supervised learning algorithm instructs the machine to analyze the labeled data for correlative properties that could be applied to the unlabeled data.
As explored in depth in this MIT Press research paper, there are, however, risks associated with this model, where flaws in the labeled data get learned and replicated by the system. Companies that most successfully use semi-supervised learning ensure that best practice protocols are in place. Semi-supervised learning is used in speech and linguistic analysis, complex medical research such as protein categorization, and high-level fraud detection.
What is reinforcement learning?
Reinforcement learning is the fourth machine learning model. In supervised learning, the machine is given the answer key and learns by finding correlations among all the correct outcomes. The reinforcement learning model does not include an answer key but, rather, inputs a set of allowable actions, rules, and potential end states. When the desired goal of the algorithm is fixed or binary, machines can learn by example. But in cases where the desired outcome is mutable, the system must learn by experience and reward. In reinforcement learning models, the “reward” is numerical and is programmed into the algorithm as something the system seeks to collect.
In many ways, this model is analogous to teaching someone how to play chess. Certainly, it would be impossible to try to show them every potential move. Instead, you explain the rules and they build up their skill through practice. Rewards come in the form of not only winning the game, but also acquiring the opponent’s pieces. Applications of reinforcement learning include automated price bidding for buyers of online advertising, computer game development, and high-stakes stock market trading.
Enterprise machine learning in action
Machine learning algorithms recognize patterns and correlations, which means they are very good at analyzing their own ROI. For companies that invest in machine learning technologies, this feature allows for an almost immediate assessment of operational impact. Below is just a small sample of some of the growing areas of enterprise machine learning applications.
Recommendation engines: From 2009 to 2017, the number of U.S. households subscribing to video streaming services rose by 450%. And a 2020 article in Forbes magazine reports a further spike in video streaming usage figures of up to 70%. Recommendation engines have applications across many retail and shopping platforms, but they are definitely coming into their own with streaming music and video services.
Dynamic marketing: Generating leads and ushering them through the sales funnel requires the ability to gather and analyze as much customer data as possible. Modern consumers generate an enormous amount of varied and unstructured data – from chat transcripts to image uploads. The use of machine learning applications helps marketers understand this data – and use it to deliver personalized marketing content and real-time engagement with customers and leads.
ERP and process automation: ERP databases contain broad and disparate data sets, which may include sales performance statistics, consumer reviews, market trend reports, and supply chain management records. Machine learning algorithms can be used to find correlations and patterns in such data. Those insights can then be used to inform virtually every area of the business, including optimizing the workflows of Internet of Things (IoT) devices within the network or the best ways to automate repetitive or error-prone tasks.
Predictive maintenance: Modern supply chains and smart factories are increasingly making use of IoT devices and machines, as well as cloud connectivity across all their fleets and operations. Breakdowns and inefficiencies can result in enormous costs and disruptions. When maintenance and repair data is collected manually, it is almost impossible to predict potential problems – let alone automate processes to predict and prevent them. IoT gateway sensors can be fitted to even decades-old analog machines, delivering visibility and efficiency across the business.
Machine learning challenges
In his book Spurious Correlations, data scientist and Harvard graduate Tyler Vigan points out that “Not all correlations are indicative of an underlying causal connection.” To illustrate this, he includes a chart showing an apparently strong correlation between margarine consumption and the divorce rate in the state of Maine. Of course, this chart is intended to make a humorous point. However, on a more serious note, machine learning applications are vulnerable to both human and algorithmic bias and error. And due to their propensity to learn and adapt, errors and spurious correlations can quickly propagate and pollute outcomes across the neural network.
An additional challenge comes from machine learning models, where the algorithm and its output are so complex that they cannot be explained or understood by humans. This is called a “black box” model and it puts companies at risk when they find themselves unable to determine how and why an algorithm arrived at a particular conclusion or decision.
Fortunately, as the complexity of data sets and machine learning algorithms increases, so do the tools and resources available to manage risk. The best companies are working to eliminate error and bias by establishing robust and up-to-date AI governance guidelines and best practice protocols.
Machine learning FAQs
What’s the difference between AI and machine learning?
Machine learning is a subset of AI and cannot exist without it. AI uses and processes data to make decisions and predictions – it is the brain of a computer-based system and is the “intelligence” exhibited by machines. Machine learning algorithms within the AI, as well as other AI-powered apps, allow the system to not only process that data, but to use it to execute tasks, make predictions, learn, and get smarter, without needing any additional programming. They give the AI something goal-oriented to do with all that intelligence and data.
Can machine learning be added to an existing system?
Yes, but it should be approached as a business-wide endeavor, not just an IT upgrade. The companies that have the best results with digital transformation projects take an unflinching assessment of their existing resources and skill sets and ensure they have the right foundational systems in place before getting started.
Data science versus machine learning
Relative to machine learning, data science is a subset; it focuses on statistics and algorithms, uses regression and classification techniques, and interprets and communicates results. Machine learning focuses on programming, automation, scaling, and incorporating and warehousing results.
Data mining versus neural networks
Machine learning looks at patterns and correlations; it learns from them and optimizes itself as it goes. Data mining is used as an information source for machine learning. Data mining techniques employ complex algorithms themselves and can help to provide better organized data sets for the machine learning application to use.
Deep learning versus neural networks
The connected neurons with an artificial neural network are called nodes, which are connected and clustered in layers. When a node receives a numerical signal, it then signals other relevant neurons, which operate in parallel. Deep learning uses the neural network and is “deep” because it uses very large volumes of data and engages with multiple layers in the neural network simultaneously.
Machine learning versus statistics
Machine learning is the amalgam of several learning models, techniques, and technologies, which may include statistics. Statistics itself focuses on using data to make predictions and create models for analysis.
Here’s the easiest takeaway for understanding the difference between deep learning and machine learning: All deep learning is machine learning, but not all machine learning is deep learning.
Understanding the latest advancements in artificial intelligence (AI) can seem overwhelming, but if it’s learning the basics that you’re interested in, you can boil many AI innovations down to two concepts: machine learning and deep learning.
Examples of machine learning and deep learning are everywhere. It’s what makes self-driving cars a reality, how Netflix knows which show you’ll want to watch next, and how Facebook recognizes whose face is in a photo.
Machine learning and deep learning often seem like interchangeable buzzwords, but there are differences between them. So, what exactly are these two concepts that dominate conversations about AI, and how are they different? Read on to find out.
Deep learning vs. machine learning
The first step in understanding the difference between machine learning and deep learning is to recognize that deep learning is machine learning.
More specifically, deep learning is considered an evolution of machine learning. It uses a programmable neural network that enables machines to make accurate decisions without help from humans.
But for starters, let’s first define machine learning.
What is machine learning?
Machine learning definition: An application of artificial intelligence that includes algorithms that parse data, learn from that data, and then apply what they’ve learned to make informed decisions.
How does machine learning work?
An easy example of a machine learning algorithm is an on-demand music streaming service. For the service to make a decision about which new songs or artists to recommend to a listener, machine learning algorithms associate the listener’s preferences with other listeners who have similar musical tastes. This technique, which is often simply touted as AI, is used in many services that offer automated recommendations.
Machine learning involves a lot of complex math and coding that, at the end of the day, serves the same mechanical function that a flashlight, car, or computer screen does. When we say something is capable of “machine learning,” it means it performs a function with the data given to it and gets progressively better over time. It’s like if you had a flashlight that turned on whenever you said, “It’s dark;” it would recognize different phrases containing the word “dark.”
Machine learning fuels all sorts of automated tasks that span across multiple industries, from data security firms that hunt down malware to finance professionals who want alerts for favorable trades. The AI algorithms are programmed to constantly learn in a way that simulates a virtual personal assistant—something they do quite well.
The way machines can learn new tricks gets really interesting (and exciting) when we start talking about deep learning and deep neural networks.
What is deep learning?
Deep learning definition: A subfield of machine learning that structures algorithms in layers to create an “artificial neural network” that can learn and make intelligent decisions on its own.
How does deep learning work?
A deep learning model is designed to continually analyze data with a logical structure similar to how a human would draw conclusions. To complete this analysis, deep learning applications use a layered structure of algorithms called an artificial neural network. The design of an artificial neural network is inspired by the biological network of neurons in the human brain, leading to a learning system that’s far more capable than that of standard machine learning models.
It’s a tricky prospect to ensure that a deep learning model doesn’t draw incorrect conclusions—like other examples of AI, it requires lots of training to get the learning processes correct. But when it works as it’s intended, functional deep learning is often received as a scientific marvel that many consider to be the backbone of true artificial intelligence.
A strong example of deep learning is Google’s AlphaGo. Google created a computer program with its own neural network that learned to play the abstract board game Go, which is known for requiring sharp intellect and intuition. By playing against professional Go players, AlphaGo’s deep learning model learned how to play at a level never seen before in AI and did so without being told when it should make a specific move (as a standard machine learning model would require).
It caused quite a stir when AlphaGo defeated multiple world-renowned “masters” of the game—not only could a machine grasp the complex techniques and abstract aspects of the game, it was also becoming one of the greatest players. It was a battle of human intelligence and artificial intelligence, and the latter came out on top.
For more practical use cases, imagine an image recognition app that can identify a type of flower or species of bird based on a photo. That image classification is powered by a deep neural network. Deep learning also guides speech recognition and translation and literally drives self-driving cars.
The difference between machine learning and deep learning
In practical terms, deep learning is just a subset of machine learning. In fact, deep learning is machine learning and functions in a similar way (hence why the terms are sometimes loosely interchanged). However, its capabilities are different.
While basic machine learning models do become progressively better at performing their specific functions as they take in new data, they still need some human intervention. If an AI algorithm returns an inaccurate prediction, then an engineer has to step in and make adjustments. With a deep learning model, an algorithm can determine whether or not a prediction is accurate through its own neural network—no human help is required.
Let’s go back to the flashlight example: It could be programmed to turn on when it recognizes the audible cue of someone saying the word “dark.” As it continues learning, it might eventually perform that task when it hears any phrase containing that particular word. But if the flashlight had a deep learning model, it could figure out that it should turn on with the cues “I can’t see” or “The light switch won’t work,” perhaps in tandem with a light sensor.
A deep learning model is able to learn through its own method of computing—a technique that makes it seem like it has its own brain.
To recap, the key differences between machine learning and deep learning are:
Machine learning uses algorithms to parse data, learn from that data, and make informed decisions based on what it has learned.
Deep learning structures algorithms in layers to create an “artificial neural network” that can learn and make intelligent decisions on its own.
Deep learning is a subset of machine learning. While both fall under the broad category of artificial intelligence, deep learning is what powers the most human-like AI.
What are the different types of machine learning?
To dive a bit deeper into the weeds, let’s look at the three main types of machine learning and how they differ from one another.
1. Supervised learning
As you might have guessed from the name, this subset of machine learning requires the most supervision. A computer is given training data and a model for responding to data.
As new data is fed to the computer, a data scientist “supervises” the process by confirming the computer’s accurate responses and correcting the computer’s inaccurate responses.
For example, imagine a programmer is trying to “teach” a computer how to tell the difference between dogs and cats. They would feed the computer model a set of labeled data; in this case, pictures of cats and dogs that are clearly identified. Over time, the model would start recognizing patterns—like that cats have long whiskers or that dogs can smile. Then, the programmer would start feeding the computer unlabeled data (unidentified photos) and test the model on its ability to accurately identify dogs and cats.
2. Unsupervised learning
Supervised learning involves giving the model all the “correct answers” (labeled data) as a way of teaching it how to identify unlabeled data. It’s like telling someone to read through a bird guide and then using flashcards to test if they’ve learned how to identify different species on their own.
By contrast, unsupervised learning entails feeding the computer only unlabeled data, then letting the model identify the patterns on its own. This machine learning method is usually used in cases where it’s unclear what the results will look like, so you need the computer to dig through the hidden layers of data and cluster (or group) data together based on the similarities or differences.
For example, say your business wants to analyze data to identify customer segments. But you don’t know what segments exist yet. You’ll have to feed the unlabeled input data into the unsupervised learning model so it can act as its own classifier of customer segments.
3. Reinforcement learning
The reinforcement learning method is a trial-and-error approach that allows a model to learn using feedback from its own actions. The computer receives “positive feedback” when it correctly understands or classifies data and “negative feedback” when it fails. By “rewarding” good behavior and “punishing” bad behavior, this learning method reinforces the former. (And it differentiates reinforcement learning from supervised learning, in which a data scientist simply confirms or corrects the model rather than rewarding or punishing it.)
Reinforcement learning is used to help machines master complex tasks that come with massive datasets, such as driving a car. Through lots of trial and error, the program learns how to make a series of decisions, which is necessary for many multi-step processes.
What are the different types of deep-learning algorithms?
Machine learning can enable computers to achieve remarkable tasks, but they still fall short of replicating human intelligence. Deep neural networks, on the other hand, are modeled after the human brain, representing an even more sophisticated level of artificial intelligence.
There are several different types of deep-learning algorithms. We’ll examine the most popular models.
Convolutional neural networks
Convolutional neural networks (CNNs) are algorithms specifically designed for image processing and object detection. The “convolution” is a unique process of filtering through an image to assess every element within it.
CNNs are often used to power computer vision, a field of AI that teaches machines how to process the visual world. Facial recognition technology is a common use of computer vision.
Recurrent neural networks
Recurrent neural networks (RNNs) have built-in feedback loops that allow the algorithms to “remember” past data points. RNNs can use this memory of past events to inform their understanding of current events or even predict the future.
A deep neural network can “think” better when it has this level of context. For example, a maps app powered by an RNN can “remember” when traffic tends to get worse. It can then use this knowledge to recommend an alternate route when you’re about to get caught in rush-hour traffic.
Data as the fuel of the future
With the massive amount of new data being produced by the current “Big Data Era,” we’re bound to see innovations that we can’t even imagine yet. According to data science experts, some of these breakthroughs will likely be deep learning applications.
Andrew Ng, former chief scientist of China’s major search engine Baidu and one of the leaders of the Google Brain Project, shared a great analogy for deep learning models with Wired:
“I think AI is akin to building a rocket ship—you need a huge engine and a lot of fuel,” he told Wired journalist Caleb Garling. “If you have a large engine and a tiny amount of fuel, you won’t make it to orbit. If you have a tiny engine and a ton of fuel, you can’t even lift off. To build a rocket, you need a huge engine and a lot of fuel. The analogy to deep learning is that the rocket engine is the deep learning models and the fuel is the huge amounts of data we can feed to these algorithms.”
What machine learning and deep learning mean for customer service
Many of today’s AI applications in customer service utilize machine learning algorithms. They’re used to drive self-service, increase agent productivity, and make workflows more reliable.
The data fed into those algorithms comes from a constant flux of incoming customer queries, including relevant context into the issues that buyers are facing. Aggregating all that information into an AI application, in turn, leads to quicker and more accurate predictions. This has made artificial intelligence an exciting prospect for many businesses, with industry leaders speculating that the most practical use cases for business-related AI will be for customer service.
For example, machine learning and deep learning are both used to power natural language processing (NLP), a branch of computer science that allows computers to comprehend text and speech. In the CX world, Amazon Alexa and Apple’s Siri are two good examples of “virtual agents” that can use speech recognition to answer a consumer’s questions.
AI-powered customer service bots also use the same learning methods to respond to typed text. A great real-world example is Zendesk’s Advanced bots. Which are enhanced bots for messaging and email that leverage the most extensive database of customer intents, specific to CX teams in your industry for more personalized and accurate responses, higher agent productivity, and faster setup.