nderstand the basic concepts of Oracle Machine Learning.
- Machine Learning Techniques
- Algorithms
- Data Preparation
- In-Database Scoring
3.1 Machine Learning Techniques
Each machine learning technique specifies a class of problems that can be modeled and solved.
A basic understanding of machine learning techniques and algorithms is required for using Oracle Machine Learning.
Machine learning techniques fall generally into two categories: supervised and unsupervised. Notions of supervised and unsupervised learning are derived from the science of machine learning, which has been called a sub-area of artificial intelligence.
Artificial intelligence refers to the implementation and study of systems that exhibit autonomous intelligence or behavior of their own. Machine learning deals with techniques that enable devices to learn from their own performance and modify their own functioning.
The following illustration provides an idea of how to use Oracle machine learning techniques.
Figure 3-1 How to Use Machine Learning techniques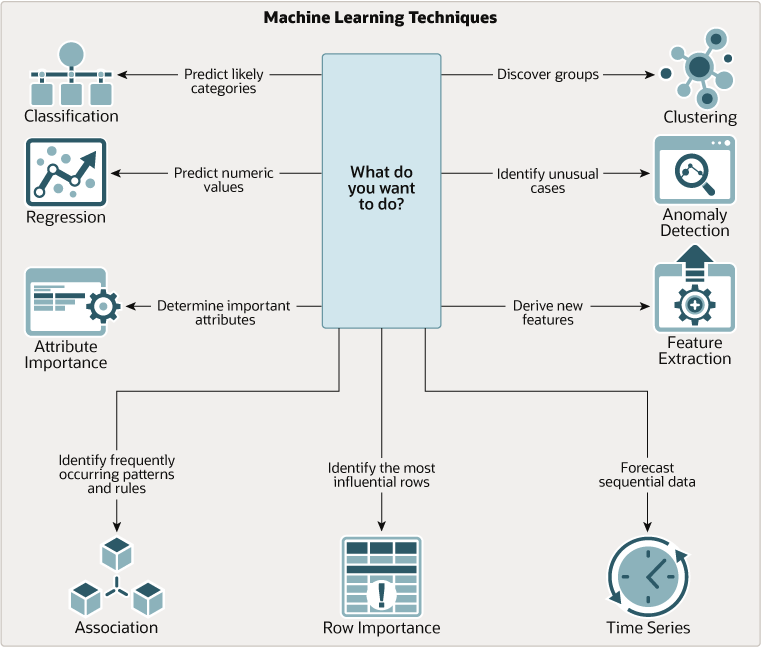
Description of “Figure 3-1 How to Use Machine Learning techniques”
Related Topics
- Algorithms
Supervised Machine Learning
Overview of supervised machine learning.
Supervised learning is also known as directed learning. The learning process is directed by a previously known dependent attribute or target. Directed Oracle Machine Learning attempts to explain the behavior of the target as a function of a set of independent attributes or predictors.
Supervised learning generally results in predictive models. This is in contrast to unsupervised learning where the goal is pattern detection.
Supervised Learning: Training
The building of a supervised model involves training, a process whereby the software analyzes many cases where the target value is already known.
In the training process, the model “learns” the logic for making the prediction. For example, a model that seeks to identify the customers who are likely to respond to a promotion must be trained by analyzing the characteristics of many customers who are known to have responded or not responded to a promotion in the past. Separate data sets are required for building (training) and testing some predictive models. The build data (training data) and test data must have the same column structure. Typically, one large table or view is split into two data sets: one for building the model, and the other for testing the model.
Supervised Learning: Testing
The process of applying the model to test data helps to determine whether the model, built on one chosen sample, is generalizable to other data. In other words, test data is used for scoring.
In particular, it helps to avoid the phenomenon of overfitting, which can occur when the logic of the model fits the build data too well and therefore has little predictive power.
Supervised Learning: Scoring
Learn about scoring in supervised learning.
Apply data, also called scoring data, is the actual population to which a model is applied. For example, you might build a model that identifies the characteristics of customers who frequently buy a certain product. To obtain a list of customers who shop at a certain store and are likely to buy a related product, you might apply the model to the customer data for that store. In this case, the store customer data is the scoring data.
Most supervised learning can be applied to a population of interest. The principal supervised machine learning techniques, classification and regression, can both be used for scoring.
Oracle Machine Learning does not support the scoring operation for attribute importance, another supervised technique. Models of this type are built on a population of interest to obtain information about that population; they cannot be applied to separate data. An attribute importance model returns and ranks the attributes that are most important in predicting a target value.
Oracle Machine Learning supports the supervised machine learning techniques described in the following table:
Table 3-1 Oracle Machine Learning Supervised Techniques
| Technique | Description | Sample Problem |
|---|---|---|
| Attribute Importance | Identifies the attributes that are most important in predicting a target attribute | Given customer response to an affinity card program, find the most significant predictors |
| Classification | Assigns items to discrete classes and predicts the class to which an item belongs | Given demographic data about a set of customers, predict customer response to an affinity card program |
| Regression | Approximates and forecasts continuous values | Given demographic and purchasing data about a set of customers, predict customers’ age |
Unsupervised Machine Learning
Overview of unsupervised machine learning.
Unsupervised learning is non-directed. There is no distinction between dependent and independent attributes. There is no previously-known result to guide the algorithm in building the model.
Unsupervised learning can be used for descriptive purposes. It can also be used to make predictions.
Unsupervised Learning: Scoring
Introduces unsupervised learning, supported scoring operations, and unsupervised machine learning techniques.
Although unsupervised machine learning does not specify a target, most unsupervised learning can be applied to a population of interest. For example, clustering models use descriptive machine learning techniques, but they can be applied to classify cases according to their cluster assignments. Anomaly Detection, although unsupervised, is typically used to predict whether a data point is typical among a set of cases.
Oracle Machine Learning supports the scoring operation for Clustering and Feature Extraction, both unsupervised machine learning techniques. Oracle Machine Learning does not support the scoring operation for Association Rules, another unsupervised function. Association models are built on a population of interest to obtain information about that population; they cannot be applied to separate data. An association model returns rules that explain how items or events are associated with each other. The association rules are returned with statistics that can be used to rank them according to their probability.
OML supports the unsupervised techniques described in the following table:
Table 3-2 Oracle Machine Learning Unsupervised Techniques
Related Topics
- Machine Learning Techniques
- In-Database Scoring
3.2 Algorithms
An algorithm is a mathematical procedure for solving a specific kind of problem. For some machine learning techniques, you can choose among several algorithms.
Each algorithm produces a specific type of model, with different characteristics. Some machine learning problems can best be solved by using more than one algorithm in combination. For example, you might first use a feature extraction model to create an optimized set of predictors, then a classification model to make a prediction on the results.
3.2.1 Oracle Machine Learning Supervised Algorithms
Oracle Machine Learning for SQL (OML4SQL) supports the supervised machine learning algorithms described in the following table.
Table 3-3 Oracle Machine Learning Algorithms for Supervised techniques
3.2.2 Oracle Machine Learning Unsupervised Algorithms
Oracle Machine Learning for SQL (OML4SQL) supports the unsupervised machine learning algorithms described in the following table.
Table 3-4 Oracle Machine Learning Algorithms for Unsupervised Techniques
Related Topics
- Algorithms
Data Preparation
Preparing the data is a valuable step in solving machine learning problems.
The quality of a model depends to a large extent on the quality of the data used to build (train) it. Much of the time spent in any given machine learning project is devoted to data preparation. The data must be carefully inspected, cleansed, and transformed, and algorithm-appropriate data preparation methods must be applied.
The process of data preparation is further complicated by the fact that any data to which a model is applied, whether for testing or for scoring, must undergo the same transformations as the data used to train the model.
Oracle Machine Learning for SQL Simplifies Data Preparation
Learn about various features of Oracle Machine Learning for SQL for data preparation.
OML4SQL offers several features that significantly simplify the process of data preparation:
- Embedded data preparation: The transformations used in training the model are embedded in the model and automatically run whenever the model is applied to new data. If you specify transformations for the model, you only have to specify them once.
- Automatic Data Preparation (ADP): Oracle Machine Learning for SQL supports an automated data preparation mode. When ADP is active, Oracle Machine Learning for SQL automatically performs the data transformations required by the algorithm. The transformation instructions are embedded in the model along with any user-specified transformation instructions.
- Automatic management of missing values and sparse data: Oracle Machine Learning for SQL uses consistent methodology across machine learning algorithms to handle sparsity and missing values.
- Transparency: Oracle Machine Learning for SQL provides model details, which are a view of the attributes that are internal to the model. This insight into the inner details of the model is possible because of reverse transformations, which map the transformed attribute values to a form that can be interpreted by a user. Where possible, attribute values are reversed to the original column values. Reverse transformations are also applied to the target of a supervised model, thus the results of scoring are in the same units as the units of the original target.
- Tools for custom data preparation: Oracle Machine Learning for SQL provides many common transformation routines in the
DBMS_DATA_MINING_TRANSFORMPL/SQL package. You can use these routines, or develop your own routines in SQL, or both. The SQL language is well suited for implementing transformations in the database. You can use custom transformation instructions along with ADP or instead of ADP.
Case Data
Learn the importance of case data in machine learning.
Most machine learning algorithms act on single-record case data, where the information for each case is stored in a separate row. The data attributes for the cases are stored in the columns.
When the data is organized in transactions, the data for one case (one transaction) is stored in many rows. An example of transactional data is market basket data. With the single exception of Association Rules, which can operate on native transactional data, Oracle Machine Learning for SQL algorithms require single-record case organization.
Nested Data
Learn how nested columns are treated in Oracle Machine Learning for SQL.
OML4SQL supports attributes in nested columns. A transactional table can be cast as a nested column and included in a table of single-record case data. Similarly, star schemas can be cast as nested columns. With nested data transformations, Oracle Machine Learning for SQL can effectively mine data originating from multiple sources and configurations.
Text Data
Prepare and transform unstructured text data for machine learning.
Oracle Machine Learning for SQL interprets CLOB columns and long VARCHAR2 columns automatically as unstructured text. Additionally, you can specify columns of short VARCHAR2, CHAR, BLOB, and BFILE as unstructured text. Unstructured text includes data items such as web pages, document libraries, Power Point presentations, product specifications, emails, comment fields in reports, and call center notes.
OML4SQL uses Oracle Text utilities and term weighting strategies to transform unstructured text for analysis. In text transformation, text terms are extracted and given numeric values in a text index. The text transformation process is configurable for the model and for individual attributes. Once transformed, the text can by mined with a OML4SQL algorithm.
Related Topics
- Prepare the Data
- Machine Learning Operations on Unstructured Text
In-Database Scoring
Scoring is the application of a machine learning algorithm to new data. In Oracle Machine Learning for SQL scoring engine and the data both reside within the database.
In traditional machine learning, models are built using specialized software on a remote system and deployed to another system for scoring. This is a cumbersome, error-prone process open to security violations and difficulties in data synchronization.
With OML4SQL, scoring is simple and secure. The scoring engine and the data both reside within the database. Scoring is an extension to the SQL language, so the results of machine learning can easily be incorporated into applications and reporting systems.
Parallel Execution and Ease of Administration
All Oracle Machine Learning for SQL scoring routines support parallel execution for scoring large data sets.
In-database scoring provides performance advantages. All Oracle Machine Learning for SQL scoring routines support parallel execution, which significantly reduces the time required for executing complex queries and scoring large data sets.
In-database machine learning minimizes the IT effort needed to support OML4SQL initiatives. Using standard database techniques, models can easily be refreshed (re-created) on more recent data and redeployed. The deployment is immediate since the scoring query remains the same; only the underlying model is replaced in the database.
Related Topics
- Oracle Database VLDB and Partitioning Guide
SQL Functions for Model Apply and Dynamic Scoring
In Oracle Machine Learning for SQL, scoring is performed by SQL language functions. Understand the different ways of scoring using SQL functions.
The functions perform prediction, clustering, and feature extraction. The functions can be invoked in two different ways: By applying a machine learning model object (Example 3-1), or by executing an analytic clause that computes the machine learning analysis dynamically and applies it to the data (Example 3-2). Dynamic scoring, which eliminates the need for a model, can supplement, or even replace, the more traditional methodology described in “The Machine Learning Process”.
In Example 3-1, the PREDICTION_PROBABILITY function applies the model svmc_sh_clas_sample, created in Example 2-1, to score the data in mining_data_apply_v. The function returns the ten customers in Italy who are most likely to use an affinity card.
In Example 3-2, the functions PREDICTION and PREDICTION_PROBABILITY use the analytic syntax (the OVER () clause) to dynamically score the data in mining_data_apply_v. The query returns the customers who currently do not have an affinity card with the probability that they are likely to use.
Example 3-1 Applying a Oracle Machine Learning for SQL Model to Score Data
CopySELECT cust_id FROM
(SELECT cust_id,
rank() over (order by PREDICTION_PROBABILITY(svmc_sh_clas_sample, 1
USING *) DESC, cust_id) rnk
FROM mining_data_apply_v
WHERE country_name = 'Italy')
WHERE rnk <= 10
ORDER BY rnk;
CUST_ID
----------
101445
100179
100662
100733
100554
100081
100344
100324
100185
101345
Example 3-2 Executing an Analytic Function to Score Data
CopySELECT cust_id, pred_prob FROM
(SELECT cust_id, affinity_card,
PREDICTION(FOR TO_CHAR(affinity_card) USING *) OVER () pred_card,
PREDICTION_PROBABILITY(FOR TO_CHAR(affinity_card),1 USING *) OVER () pred_prob
FROM mining_data_build_v)
WHERE affinity_card = 0
AND pred_card = 1
ORDER BY pred_prob DESC;
CUST_ID PRED_PROB
---------- ---------
102434 .96
102365 .96
102330 .96
101733 .95
102615 .94
102686 .94
102749 .93
.
.
.
101656 .51
Related Topics
- Oracle Database SQL Language Reference
- Oracle Machine Learning for SQL User’s Guide