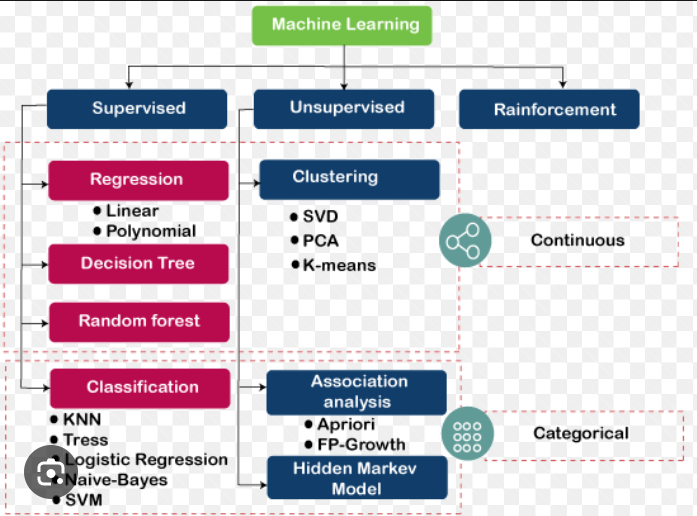
A subset of artificial intelligence, machine learning is a class of methods for automatically creating models from data. Using the relationships derived from the training dataset, these models are then able to make predictions on unseen data. Machine learning algorithms are the engine for machine learning because they turn a dataset into a model. Different types of algorithms learn differently (supervised learning, unsupervised learning, reinforcement learning) and perform different functions (classification, regression, natural language processing, and so on).
The algorithm you select depends on the type of machine learning problem you’re solving, available computing resources, and the nature of the dataset (eg: labeled vs. unlabeled). Generally, machine learning algorithms are used for classification or prediction problems. When a model is “fit” on a dataset, it learns from the data by recognizing patterns in the data.
Remember that machine learning algorithms are different machine learning models, although these terms are often used interchangeably. A model in machine learning is the output of a machine learning algorithm that has been fit on a dataset. The model represents what the algorithm has learned from the data—the rules, numbers, and other algorithm-specific data structures required to make predictions.
ML algorithms can be described using math and pseudocode (a representation of code that can be understood by a layman). Algorithmic pseudocode is a plain language description of the steps in an algorithm.
In the real world, machine learning algorithms are used on massive datasets to perform a range of prediction tasks, such as powering recommendation engines and performing spam and fraud detection, risk assessments, image and text classification, natural language processing, sentiment analysis, and so much more.
Is machine learning the right career for you? Find out if you’re eligible for Springboard’s Machine Learning Career Track.
What are the 3 Types of Machine Learning Algorithms?
Machine learning algorithms can be programmed to learn from data in different ways. The most common types of machine learning algorithms make use of supervised learning, unsupervised learning, and reinforcement learning.
1. Supervised learning
Supervised learning algorithms learn by example. The programmer provides the machine learning algorithm with a known dataset that includes desired inputs and outputs (such as input images and their corresponding labels), and the algorithm determines how to arrive at the desired output (known as “ground truth”) by identifying patterns in the training data.
The algorithm learns from these observations, makes predictions on test data, and is corrected by the programmer. In the end, the programmer picks the model or function that best describes the training data and makes the best estimation of output. Supervised learning is useful for image classification, regression, and forecasting.
2. Unsupervised learning
Unsupervised learning algorithms make predictions from untagged data, where there is no ground truth or known output. Unsupervised learning algorithms can discover hidden patterns or data groupings to analyze and cluster unlabeled datasets—making them the ideal solution for exploratory data analysis. The algorithm classifies, labels, and/or groups the data points without any human intervention.
While unsupervised learning can perform more complex data mining tasks than supervised learning algorithms, they can be more unpredictable, potentially adding categories and labels based on its interpretation of the training data. This type of algorithm whose logic can’t be explained in plain language is known as a “black box.” Unsupervised learning is useful for customer segmentation, anomaly detection in network traffic, and content recommendations.
3. Reinforcement learning
Reinforcement learning algorithms follow a regimented learning process of trial-and-error. The algorithm is provided with a set of actions, parameters, and values—similar to the types of constraints players face in a game. The algorithm then tries to explore different options and possibilities within these predefined rules—a strategy for “winning” the game, if you will—while monitoring and evaluating the results to come up with the best solution to the problem.
To program the algorithm to do what you want, the AI gets rewards or punishments for actions it performs as signals for positive and negative behavior via an action-reward feedback loop. The algorithm’s goal is to find a suitable action model that will maximize the total reward. The algorithm learns from past mistakes (punishments) and adapts its approach to the situation to achieve the best possible result. Reinforcement learning is used in autonomous vehicles, recommendation engines, game development, robotics, and more.
14 Machine Learning Algorithms—And How They Work
Here are the most common types of supervised, unsupervised, and reinforcement learning algorithms.
1. Linear Regression
Linear regression algorithms are a type of supervised learning algorithm that performs a regression task and are one of the most popular and well understood algorithms in the field of data science. Regression analysis is a type of predictive modeling that discovers the relationship between an input and the target variable. The most basic type of regression is linear regression, which shows the strength of the correlation between two variables, and whether that correlation is positive or negative.
The hypothesis function for regression equations is: hθ = θ + θ1x
In statistics, regression predicts a dependent variable (y) based on a given independent variable (x). The type of regression technique used depends on the number of independent variables and the type of relationship between the dependent and independent variables. In linear regression, there is only one independent variable and a linear relationship between the independent (x-axis) and dependent (y-axis) variable. Based on the given data points, the model attempts to plot a line that best describes the relationship between two variables. Regression algorithms predict the output values based on input features from data fed into the system.
What is it used for?
Today, regression models are used in financial forecasting, trend analysis, and time-series predictions.
2. Logistic Regression
Logistic regression algorithms are the go-to for binary classification problems. There are two types of logistic regression: binary (eg: Does an input belong to the default class? Yes/No) and multilinear (Does the input image contain a dog? A cat? A sheep?). The algorithm maps predicted values to probabilities using the Sigmoid function, an S-shaped curve also known as the logistic function. The function maps any real value onto another value between 0 and 1, which expresses the probability that an input belongs to the default class. Inputs are combined linearly using weights or coefficient values to predict an output value (y). The best coefficients result in a model that predicts a value very close to one for the default class and very close to zero for the other class.
For example, if we are modeling people’s sex as male or female from their height, then the first class could be male and the logistic regression model could be written as the probability of male given a person’s height, or:
P(sex=male|height) or P(X)=P(Y=1|X)
The probability prediction must be transformed into a binary value (0 or 1) in order to make a probability prediction.
What is it used for?
Logistic regression models are used for spam detection, fraud detection, and tumor image classification
3. Decision Tree
Decision trees are a type of supervised machine learning algorithm used for classification and regression problems in machine learning. With a flowchart-like structure, decision trees represent a sequential list of questions or features contained within a node. Each node branches into a subsequent node, with a final leaf node representing a class label (a decision taken after computing all features). In a decision tree, different features have different importance (represented by weights or percentages), and the relationships between them can be viewed easily. The paths from root to leaf represent classification rules. Decision trees come in two types: classification trees (yes/no types) or regression trees (continuous data types, such as a numerical value).
In decision analysis, a decision tree can be used to visually represent decisions and decision-making. When it comes to structured or tabular data, decision trees are considered the best method for model fitting.
What is it used for?
Decision tree algorithms are used for evaluating loan applications, risk assessments, fraud detection, and medical diagnosis.
4. Support Vector Machine (SVM)
Support Vector Machine is a supervised machine learning algorithm used for classification and regression problems. The purpose of SVM is to find a hyperplane in an N-dimensional space (where N equals the number of features) that classifies the input data into distinct groups. The hyperplane represents a decision boundary, whereby the data points that fall on either side of it belong to a distinct class based on their shared similarities. Consequently, the objective of an SVM is to find a hyperplane that has the maximum margin (the maximum distance between data points of either class), in order to draw this distinction. SVM takes the data as an input, transforms it using a technique called the kernel tricks, and finds an optimal boundary (hyperplane) between the data points.
The dimension of the hyperplane depends on the number of features. If the number of input features is two, the hyperplane is just a line. However, if the number of features is three, the hyperplane becomes a two-dimensional plane. Support vectors are the data points closest to the hyperplane and influence the position and orientation of the hyperplane. We compute the distance (margin) between the hyperplane and the support vectors. Again, the goal is to maximize the margin. The hyperplane with the maximum margin between the data points of either class is the optimal hyperplane. SVM is considered a black box as the decisions and complex data transformations are very difficult to interpret.

What is it used for?
SVM is used for facial recognition, handwriting recognition, image classification, text categorization, and more.
5. Naive Bayes
Naive Bayes is a probabilistic classification algorithm based on the Bayes Theorem in statistics and probability theory. While this algorithm is used for a variety of classification tasks, it works especially well for natural language processing. The Bayes Theorem is a simple mathematical formula for calculating conditional probabilities. Conditional probability is the measure of the probability of an event given that another event has occurred. Essentially, the formula tells you how often A happens given B, expressed as P(A|B), or vice versa.
The fundamental Naive Bayes assumption is that each feature makes an independent and equal contribution to the outcome. For example, the condition of a fruit being red, round, and 2-4 inches in diameter are features that must all be present for it to be classified as an apple, but the algorithm perceives each feature as distinct. If given a sentence—for example, “the sky is blue”—the algorithm will interpret the individual words and not the entire sentence, even though words that stand next to each other in a sentence influence the meaning of the sentence. Hence why the algorithm is referred to as “naive.” Even though the independence assumption is generally incorrect in real-world situations, the Naive Bayes classifier is useful for large datasets because it works extremely fast relative to other classification algorithms, and has been known to outperform even highly sophisticated classification methods.
What is it used for?
Naive Bayes is used for image classification, document classification (eg: classifying texts into different languages, genres, or topics through the presence of keywords), and sentiment analysis (calculating the probability of a sentence or paragraph being positive or negative).
6. K-Nearest Neighbors (KNN)
K-nearest neighbors is a supervised machine learning algorithm used to solve classification and regression problems. The algorithm assumes that similar data points exist in close proximity. KNN captures the idea of similarity by calculating the straight-line distance (AKA the Euclidean distance) between points on a graph. The algorithm then tries to establish nonlinear boundaries for each class, similar to an SVM. In KNN classification, an object is assigned to the class most common amongst its ‘k’ nearest neighbors, where k is a user-defined constant. Increasing k (up to a point) results in more stable predictions due to majority voting/averaging, and the algorithm is thus more likely to make accurate predictions. When k=1, the object is simply assigned to the class of its single nearest neighbor. Increasing k is akin to casting a wider fishing net, where the average is computed from a larger, more representative sample of “fish.” In KNN regression, the output is the property value for the object—meaning the value of all the average values of the K-nearest neighbors.
It is useful to assign weights to the contributions of the neighbors so that the nearest neighbors contribute more to the average than distant ones. This also prevents bias when the class distribution is skewed. Samples of a more prevalent class tend to dominate the prediction of a new example because they tend to be common among the k-nearest neighbors due to their large number.
KNN works by finding the distances between a query and all the examples in the data, selecting the specified number of examples (k) closest to the query, then voting for the most frequent label (in the case of classification) or averaging the labels (in the case of regression).
What is it used for?
KNN is used in recommender systems, such as products on Amazon, movies on Netflix, and videos on YouTube.
7. K-Means
K-means is a method of vector quantization that aims to separate n observations into k clusters. Unlike KNN, K-Means is used to find groups that have not been explicitly labeled in the data. Clustering is one of the most common exploratory data analysis techniques because it can be used to find out what groups exist or to identify unknown groups from complex datasets. Clustering is the process of identifying non-overlapping subgroups (clusters) within the data such that the data points in the same cluster are very similar, while the data points in other clusters are very different (i.e. far apart according to Euclidean distance or correlation-based distance). The objective of K-means is to group similar data points together and discover underlying patterns.
The target number, k, refers to the number of centroids you need in the dataset. A centroid represents the center of the cluster—the arithmetic mean of every data point that belongs to that cluster. The algorithm attempts to minimize the sum of the squared distance between data points and the centroid.
Clustering can be done based on subgroups or features. Since clustering algorithms use distance-based measurements to determine the similarity between data points, it’s best to standardize the data to have a mean of zero and a standard deviation of one. In most datasets, the features have different units of measurement (eg: height vs. weight), so these units must be standardized.
What is it used for?
K-means is used for market segmentation when we try to find customers that are similar to each in terms of behavior/attributes, image recognition, and document clustering.
8. Random Forest
Random forest is a supervised learning algorithm used for classification, regression, and other tasks. The algorithm consists of a multitude of decision trees—known as a “forest”—which have been trained with the bagging method. The general idea of the bagging method is that a combination of learning models increases the accuracy of the overall result. This method is known as ensemble learning, a technique that combines many classifiers to provide solutions to complex problems. Random forest builds multiple decision trees and merges their outputs (predictions) by taking the mean or average of all the outputs to obtain a more stable and accurate prediction.
In every random forest, a subset of features is selected randomly at each node’s splitting point, where the randomized feature selection reduces bias. Consequently, random forest overcomes the limitations of the decision tree algorithm by reducing overfitting of datasets and increasing precision.
9. Dimensionality reduction
Dimensionality reduction algorithms are used for feature selection and feature extraction. In machine learning classification problems, there are often too many variables that form the basis of a classification. These variables are called features. The higher the number of features, the harder it is to make predictions from the training set. Oftentimes, most of these features are correlated, hence redundant. For example, if 95% of observations were for 35-year-old women, then age and gender variables can be eliminated without losing too much information. Some features have nothing to do with the target variable; others might be correlated to the target variable but have no causal relationship to it.
If redundancies aren’t eliminated, models will try to map any feature included in the dataset to the target variable even if there is no relationship between them, which leads to imprecision.
Dimensionality reduction is the process of reducing the number of random variables under consideration and instead of obtaining a set of principal variables. In machine learning, dimensionality refers to the number of features in your dataset. When there’s an insufficient number of observations for each feature, the algorithm may struggle to train models effectively because the model doesn’t have enough samples for each feature. This is known as the “curse of dimensionality” and is especially relevant for clustering algorithms that rely on distance calculations.
Feature selection refers to filtering irrelevant or redundant features from your dataset, while feature extraction involves compressing near-identical features into a lower-dimensional space.
What is it used for?
Dimensionality reduction is a necessary procedure when working with large datasets because it results in data compression, hence reduced storage space and computing power.
10. Gradient boosting algorithms
Gradient boosting algorithms are another example of ensemble learning, where weak prediction models are combined to create a more powerful new model. Boosting is a method for creating an ensemble. It starts by fitting an initial model, such as a tree or linear regression, to the data. Then a second model is created to predict the cases where the first model performs poorly. This process is repeated many times, where each subsequent model attempts to correct the shortcomings of the combined boosted ensemble of all previous models.
A weak model refers to one whose performance is slightly better than random chance. Gradient boosting is one of the most powerful algorithms in the field of machine learning. It refers to a family of machine learning algorithms that convert weak learners into stronger models in an iterative process.
The term ‘gradient boosting’ refers to the use of a gradient descent algorithm to minimize the loss when adding new models. Target outcomes for each case are set based on the gradient of the error with respect to the prediction. XGBoost
11. XGBoost
XGBoost is a decision tree algorithm that uses a gradient boosting framework. Developed as a research project at the University of Washington, XGBoost is the most popular gradient boosting R package and has been widely used in cutting-edge industry applications and Kaggle competitions. XGBoost, which stands for “Extreme Gradient Boosting,” is an optimized distributed gradient boosting library designed to be more efficient, flexible, and portable than gradient boosted decision trees. Features of XGBoost include regularized learning, which helps to smooth the final learned weights to avoid model overfitting. Also, the tree ensemble cannot be optimized using traditional optimization methods such as Euclidean space (the distance measure that determines accuracy in classification models), so the model is trained in an additive manner.
As an open-source implementation tool, XGBoost belongs to a broader collection of tools under the Distributed (Deep) Machine Learning Community on GitHub.
What is it used for?
According to the researchers who came up with it, the most important factor about the XGBoost is its scalability and speed, with a system that runs more than 10x faster than existing popular solutions on a single machine while enabling data scientists to process hundreds of millions of examples on a standard desktop computer.
12. GBM (Gradient Boosting Machine)
Gradient Boosting Machine is the original gradient boosting framework for decision trees introduced in 2001 by Jerome H. Friedman, a professor of statistics at Stanford University. Also known as MART (Multiple Additive Regression Trees) and GBRT (Gradient Boosted Regression Trees). GBM identifies weak learners by using gradients in the loss function (y=ax+b+e, where e is the error term). The loss function measures how good a model’s coefficients are at fitting the underlying data. Put more simply, the loss function indicates the difference between true values and predicted values.
13. LightGBM
Another free and open-source gradient boosting framework for decision tree algorithms, LightGBM was initially developed by Microsoft. LightGBM has many of the same advantages as XGBoost, including sparse organization, parallel training (training different layers of a model on different GPUs to reduce training time), multiple loss functions, regularization (a technique used for tuning the function) , and early stopping.
The main difference between XGBoost and LightGBM lies in the construction of the decision trees. LightGBM does not grow a tree row by row as most other implementations do. Instead, it chooses the leaf (terminal node) it believes will yield the largest decrease in loss (which is the main objective of gradient boosting). Comparison experiments on public datasets show that LightGBM can outperform existing boosting frameworks such as XGBoost on both efficiency and accuracy, with lower memory consumption.
14. CatBoost
Yet another open-source gradient boosting library for decision trees, CatBoost was developed by researchers and engineers at Yandex, a Russian-Dutch internet company. The library is used for search, recommendation systems, personal assistants, self-driving cars, weather prediction, and many other tasks at Yandex and other companies.
Cloudflare, a web security company, used the CatBoost algorithm to build a machine learning model that would counteract credential stuffing bots—cyberattacks that attempt to log into and take over a user’s account by assaulting password forms with previously stolen credentials. CatBoost provides great results with default parameters, so there is no need to spend too much time on parameter tuning. You can also use non-numeric factors instead of having to pre-process your data and turn it into numbers.
What Are the Best Machine Learning Algorithms?
Machine learning enables businesses to analyze massive datasets to gain insights about their customers, make forecasts about future events, and provide a personalized customer experience. Fundamentally, machine learning extracts meaningful insights from raw data to solve complex business problems. However, no one machine learning algorithm works best for every problem—hence the concept of the “no free lunch” theorem in supervised machine learning. Predictive analytics is the most common type of machine learning, which involves the mapping Y=f(x) to make predictions of Y for new X. Linear regression is widely used for predicting sales revenue, setting prices, and analyzing risk in the financial and insurance sectors.
The “best” algorithms to use varies widely by industry, depending on the nature of the business problem and the type of data available. For example, image recognition is becoming increasingly prevalent in healthcare for its usefulness in medical diagnostics, such as classifying an MRI of a brain tumor as benign or malignant—an example of a binary classification problem that can be solved using logistic regression. Meanwhile, retailers use a range of machine learning algorithms from simple linear regression to Naive Bayes to improve inventory control using predictive analytics, perform sentiment analysis to predict the likelihood of customer churn, and using K-means clustering for customer segmentation.
Meanwhile, the financial and insurance industries use decision trees and corresponding gradient boosting libraries such as XGBoost, CatBoost, and GBM to evaluate loan and mortgage applications, detect fraud, and perform risk assessments before entering new markets. While some algorithms are used more than others in certain industries, every type of algorithm has a significant role to play in developing machine learning models that are more accurate and less prone to bias.