The term machine learning was first coined in the 1950s when Artificial Intelligence pioneer Arthur Samuel built the first self-learning system for playing checkers. He noticed that the more the system played, the better it performed.
Fueled by advances in statistics and computer science, as well as better datasets and the growth of neural networks, machine learning has truly taken off in recent years.
Today, whether you realize it or not, machine learning is everywhere ‒ automated translation, image recognition, voice search technology, self-driving cars, and beyond.
In this guide, we’ll explain how machine learning works and how you can use it in your business. We’ll also introduce you to machine learning tools and show you how to get started with no-code machine learning.
Read along, skip to a section, or bookmark this post for later:
- What Is Machine Learning?
- Types of Machine Learning
- Machine Learning Use Cases
- How Machine Learning Works
- Get Started With Machine Learning Tools
What Is Machine Learning?

Machine learning (ML) is a branch of artificial intelligence (AI) that enables computers to “self-learn” from training data and improve over time, without being explicitly programmed. Machine learning algorithms are able to detect patterns in data and learn from them, in order to make their own predictions. In short, machine learning algorithms and models learn through experience.
In traditional programming, a computer engineer writes a series of directions that instruct a computer how to transform input data into a desired output. Instructions are mostly based on an IF-THEN structure: when certain conditions are met, the program executes a specific action.
Machine learning, on the other hand, is an automated process that enables machines to solve problems with little or no human input, and take actions based on past observations.
While artificial intelligence and machine learning are often used interchangeably, they are two different concepts. AI is the broader concept – machines making decisions, learning new skills, and solving problems in a similar way to humans – whereas machine learning is a subset of AI that enables intelligent systems to autonomously learn new things from data.
Instead of programming machine learning algorithms to perform tasks, you can feed them examples of labeled data (known as training data), which helps them make calculations, process data, and identify patterns automatically.
Put simply, Google’s Chief Decision Scientist describes machine learning as a fancy labeling machine. After teaching machines to label things like apples and pears, by showing them examples of fruit, eventually they will start labeling apples and pears without any help – provided they have learned from appropriate and accurate training examples.
Machine learning can be put to work on massive amounts of data and can perform much more accurately than humans. It can help you save time and money on tasks and analyses, like solving customer pain points to improve customer satisfaction, support ticket automation, and data mining from internal sources and all over the internet.
But what’s behind the machine learning process?
Types of Machine Learning
To understand how machine learning works, you’ll need to explore different machine learning methods and algorithms, which are basically sets of rules that machines use to make decisions. Below, you’ll find the five most common and most used types of machine learning:
Supervised Learning
Supervised learning algorithms and supervised learning models make predictions based on labeled training data. Each training sample includes an input and a desired output. A supervised learning algorithm analyzes this sample data and makes an inference – basically, an educated guess when determining the labels for unseen data.
This is the most common and popular approach to machine learning. It’s “supervised” because these models need to be fed manually tagged sample data to learn from. Data is labeled to tell the machine what patterns (similar words and images, data categories, etc.) it should be looking for and recognize connections with.
For example, if you want to automatically detect spam, you would need to feed a machine learning algorithm examples of emails that you want classified as spam and others that are important, and should not be considered spam.
Which brings us to our next point – the two types of supervised learning tasks: classification and regression.
Classification in supervised machine learning
There are a number of classification algorithms used in supervised learning, with Support Vector Machines (SVM) and Naive Bayes among the most common.
In classification tasks, the output value is a category with a finite number of options. For example, with this free pre-trained sentiment analysis model, you can automatically classify data as positive, negative, or neutral.
Let’s say you want to analyze customer support conversations to understand your clients’ emotions: are they happy or frustrated after contacting your customer service team? A sentiment analysis classifier can automatically tag responses for you, like in the below:
In this example, a sentiment analysis model tags a frustrating customer support experience as “Negative”.
Regression in supervised machine learning
In regression tasks, the expected result is a continuous number. This model is used to predict quantities, such as the probability an event will happen, meaning the output may have any number value within a certain range. Predicting the value of a property in a specific neighborhood or the spread of COVID19 in a particular region are examples of regression problems.
Unsupervised Learning
Unsupervised learning algorithms uncover insights and relationships in unlabeled data. In this case, models are fed input data but the desired outcomes are unknown, so they have to make inferences based on circumstantial evidence, without any guidance or training. The models are not trained with the “right answer,” so they must find patterns on their own.
One of the most common types of unsupervised learning is clustering, which consists of grouping similar data. This method is mostly used for exploratory analysis and can help you detect hidden patterns or trends.
For example, the marketing team of an e-commerce company could use clustering to improve customer segmentation. Given a set of income and spending data, a machine learning model can identify groups of customers with similar behaviors.
Segmentation allows marketers to tailor strategies for each key market. They might offer promotions and discounts for low-income customers that are high spenders on the site, as a way to reward loyalty and improve retention.
Semi-Supervised Learning
In semi-supervised learning, training data is split into two. A small amount of labeled data and a larger set of unlabeled data.
In this case, the model uses labeled data as an input to make inferences about the unlabeled data, providing more accurate results than regular supervised-learning models.
This approach is gaining popularity, especially for tasks involving large datasets such as image classification. Semi-supervised learning doesn’t require a large number of labeled data, so it’s faster to set up, more cost-effective than supervised learning methods, and ideal for businesses that receive huge amounts of data.
Reinforcement Learning
Reinforcement learning (RL) is concerned with how a software agent (or computer program) ought to act in a situation to maximize the reward. In short, reinforced machine learning models attempt to determine the best possible path they should take in a given situation. They do this through trial and error. Since there is no training data, machines learn from their own mistakes and choose the actions that lead to the best solution or maximum reward.
This machine learning method is mostly used in robotics and gaming. Video games demonstrate a clear relationship between actions and results, and can measure success by keeping score. Therefore, they’re a great way to improve reinforcement learning algorithms.
Deep Learning (DL)
Deep learning models can be supervised, semi-supervised, or unsupervised (or a combination of any or all of the three). They’re advanced machine learning algorithms used by tech giants, like Google, Microsoft, and Amazon to run entire systems and power things, like self driving cars and smart assistants.
Deep learning is based on Artificial Neural Networks (ANN), a type of computer system that emulates the way the human brain works. Deep learning algorithms or neural networks are built with multiple layers of interconnected neurons, allowing multiple systems to work together simultaneously, and step-by-step.
When a model receives input data ‒ which could be image, text, video, or audio ‒ and is asked to perform a task (for example, text classification with machine learning), the data passes through every layer, enabling the model to learn progressively. It’s kind of like a human brain that evolves with age and experience!
Deep learning is common in image recognition, speech recognition, and Natural Language Processing (NLP). Deep learning models usually perform better than other machine learning algorithms for complex problems and massive sets of data. However, they generally require millions upon millions of pieces of training data, so it takes quite a lot of time to train them.
How Machine Learning Works

In order to understand how machine learning works, first you need to know what a “tag” is. To train image recognition, for example, you would “tag” photos of dogs, cats, horses, etc., with the appropriate animal name. This is also called data labeling.


When working with machine learning text analysis, you would feed a text analysis model with text training data, then tag it, depending on what kind of analysis you’re doing. If you’re working with sentiment analysis, you would feed the model with customer feedback, for example, and train the model by tagging each comment as Positive, Neutral, and Negative.
Take a look at the diagram below:

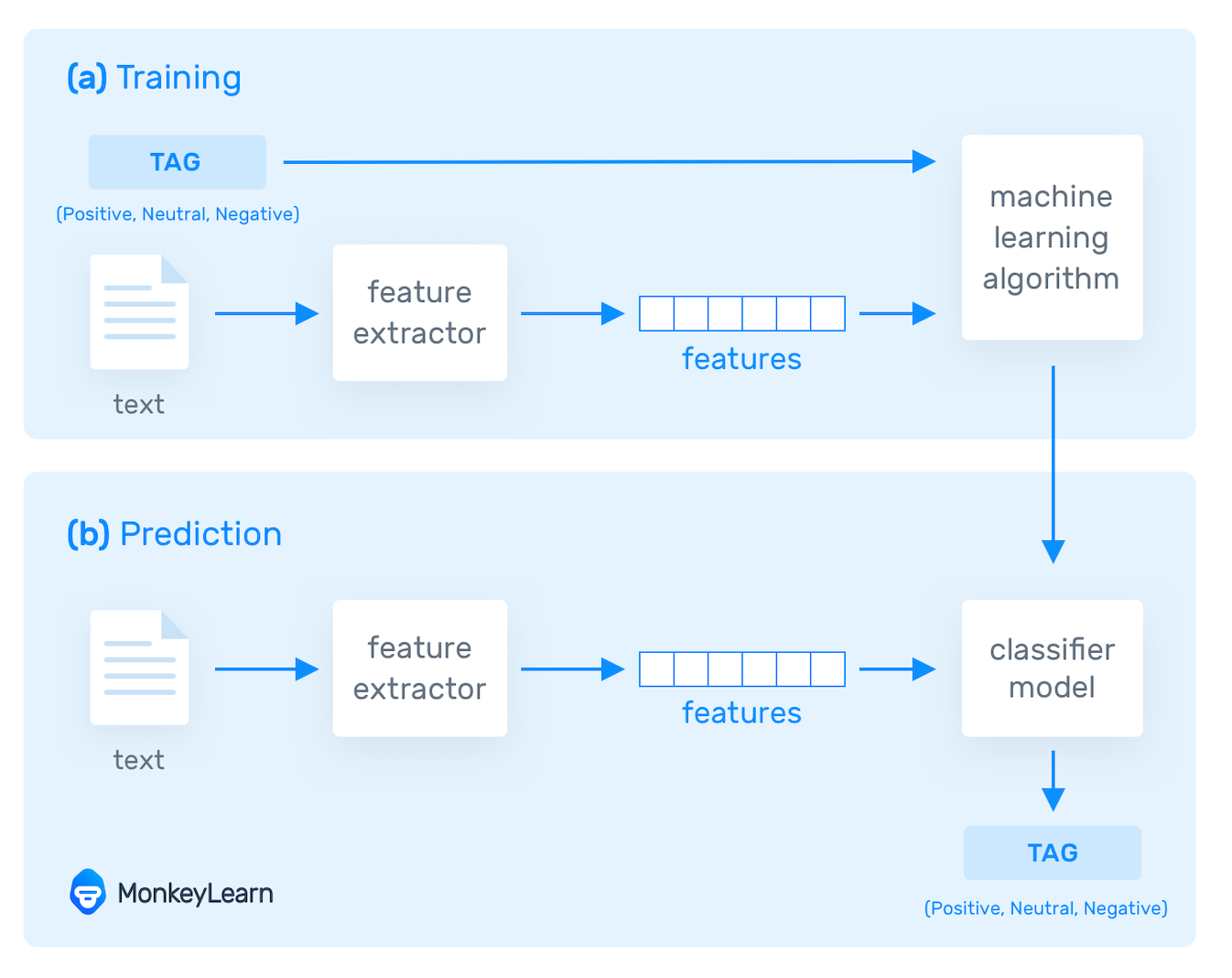
At its most simplistic, the machine learning process involves three steps:
- Feed a machine learning model training input data. In our case, this could be customer comments from social media or customer service data.
- Tag training data with a desired output. In this case, tell your sentiment analysis model whether each comment or piece of data is Positive, Neutral, or Negative. The model transforms the training data into text vectors – numbers that represent data features.
- Test your model by feeding it testing (or unseen) data. Algorithms are trained to associate feature vectors with tags based on manually tagged samples, then learn to make predictions when processing unseen data.
If your new model performs to your standards and criteria after testing it, it’s ready to be put to work on all kinds of new data. If it’s not performing accurately, you’ll need to keep training. Furthermore, as human language and industry-specific language morphs and changes, you may need to continually train your model with new information.
Machine Learning Use Cases

Machine learning applications and use cases are nearly endless, especially as we begin to work from home more (or have hybrid offices), become more tied to our smartphones, and use machine learning-guided technology to get around.
Machine learning in finance, healthcare, hospitality, government, and beyond, is already in regular use. Businesses are beginning to see the benefits of using machine learning tools to improve their processes, gain valuable insights from unstructured data, and automate tasks that would otherwise require hours of tedious, manual work (which usually produces much less accurate results).
For example, UberEats uses machine learning to estimate optimum times for drivers to pick up food orders, while Spotify leverages machine learning to offer personalized content and personalized marketing. And Dell uses machine learning text analysis to save hundreds of hours analyzing thousands of employee surveys to listen to the voice of employee (VoE) and improve employee satisfaction.
How do you think Google Maps predicts peaks in traffic and Netflix creates personalized movie recommendations, even informs the creation of new content ? By using machine learning, of course.
There are many different applications of machine learning, which can benefit your business in countless ways. You’ll just need to define a strategy to help you decide the best way to implement machine learning into your existing processes. In the meantime, here are some common machine learning use cases and applications that might spark some ideas:
- Social Media Monitoring
- Customer Service & Customer Satisfaction
- Image Recognition
- Virtual Assistants
- Product Recommendations
- Stock Market Trading
- Medical Diagnosis
Social Media Monitoring
Using machine learning you can monitor mentions of your brand on social media and immediately identify if customers require urgent attention. By detecting mentions from angry customers, in real-time, you can automatically tag customer feedback and respond right away. You might also want to analyze customer support interactions on social media and gauge customer satisfaction (CSAT), to see how well your team is performing.
Natural Language Processing gives machines the ability to break down spoken or written language much like a human would, to process “natural” language, so machine learning can handle text from practically any source.
Customer Service & Customer Satisfaction
Machine learning allows you to integrate powerful text analysis tools with customer support tools, so you can analyze your emails, live chats, and all manner of internal data on the go. You can use machine learning to tag support tickets and route them to the correct teams or auto-respond to common queries so you never leave a customer in the cold.
Furthermore, using machine learning to set up a voice of customer (VoC) program and a customer feedback loop will ensure that you follow the customer journey from start to finish to improve the customer experience (CX), decrease customer churn, and, ultimately, increase your profits.
Image Recognition
Image recognition is helping companies identify and classify images. For example, facial recognition technology is being used as a form of identification, from unlocking phones to making payments.
Self-driving cars also use image recognition to perceive space and obstacles. For example, they can learn to recognize stop signs, identify intersections, and make decisions based on what they see.
Virtual Assistants
Virtual assistants, like Siri, Alexa, Google Now, all make use of machine learning to automatically process and answer voice requests. They quickly scan information, remember related queries, learn from previous interactions, and send commands to other apps, so they can collect information and deliver the most effective answer.
Customer support teams are already using virtual assistants to handle phone calls, automatically route support tickets, to the correct teams, and speed up interactions with customers via computer-generated responses.
Product Recommendations
Association rule-learning is a machine learning technique that can be used to analyze purchasing habits at the supermarket or on e-commerce sites. It works by searching for relationships between variables and finding common associations in transactions (products that consumers usually buy together). This data is then used for product placement strategies and similar product recommendations.
Associated rules can also be useful to plan a marketing campaign or analyze web usage.
Stock Market Trading
Machine learning algorithms can be trained to identify trading opportunities, by recognizing patterns and behaviors in historical data. Humans are often driven by emotions when it comes to making investments, so sentiment analysis with machine learning can play a huge role in identifying good and bad investing opportunities, with no human bias, whatsoever. They can even save time and allow traders more time away from their screens by automating tasks.
Medical Diagnosis
The ability of machines to find patterns in complex data is shaping the present and future. Take machine learning initiatives during the COVID-19 outbreak, for instance. AI tools have helped predict how the virus will spread over time, and shaped how we control it. It’s also helped diagnose patients by analyzing lung CTs and detecting fevers using facial recognition, and identified patients at a higher risk of developing serious respiratory disease.
Machine learning is driving innovation in many fields, and every day we’re seeing new interesting use cases emerge. In business, the overall benefits of machine learning include:
- It’s cost-effective and scalable. You only need to train a machine learning model once, and you can scale up or down depending on how much data you receive.
- Performs more accurately than humans. Machine learning models are trained with a certain amount of labeled data and will use it to make predictions on unseen data. Based on this data, machines define a set of rules that they apply to all datasets, helping them provide consistent and accurate results. No need to worry about human error or innate bias. And you can train the tools to the needs and criteria of your business.
- Works in real-time, 24/7. Machine learning models can automatically analyze data in real-time, allowing you to immediately detect negative opinions or urgent tickets and take action.
Get Started With Machine Learning Tools

When you’re ready to get started with machine learning tools it comes down to the Build vs. Buy Debate. If you have a data science and computer engineering background or are prepared to hire whole teams of coders and computer scientists, building your own with open-source libraries can produce great results. Building your own tools, however, can take months or years and cost in the tens of thousands.
Using SaaS or MLaaS (Machine Learning as a Service) tools, on the other hand, is much cheaper because you only pay what you use. They can also be implemented right away and new platforms and techniques make SaaS tools just as powerful, scalable, customizable, and accurate as building your own.
Whether you choose to build or buy you machine learning tools, here are some of the best of each:
Top SaaS Machine Learning Tools
Some of the best SaaS machine learning tools on the market:
- MonkeyLearn
- BigML
- IBM Watson
- Google Cloud ML
MonkeyLearn
MonkeyLearn is a powerful SaaS machine learning platform with a suite of text analysis tools to get real-time insights and powerful results, so you can make data-driven decisions from all manner of text data: customer service interactions, social media comments, online reviews, emails, live chats, and more.
Just connect your data and use one of the pre-trained machine learning models to start analyzing it. You can even build your own no-code machine learning models in a few simple steps, and integrate them with the apps you use every day, like Zendesk, Google Sheets and more.


MonkeyLearn is scalable to handle any amount of data – from just a few hundred surveys, to hundreds of thousands of comments from all over the web – to get real-world results from your data with techniques, like topic analysis, sentiment analysis, text extraction, and more.
And you can take your analysis even further with MonkeyLearn Studio to combine your analyses to work together. It’s a seamless process to take you from data collection to analysis to striking visualization in a single, easy-to-use dashboard.
Take a look at this MonkeyLearn Studio aspect-based sentiment analysis of online reviews of Zoom:

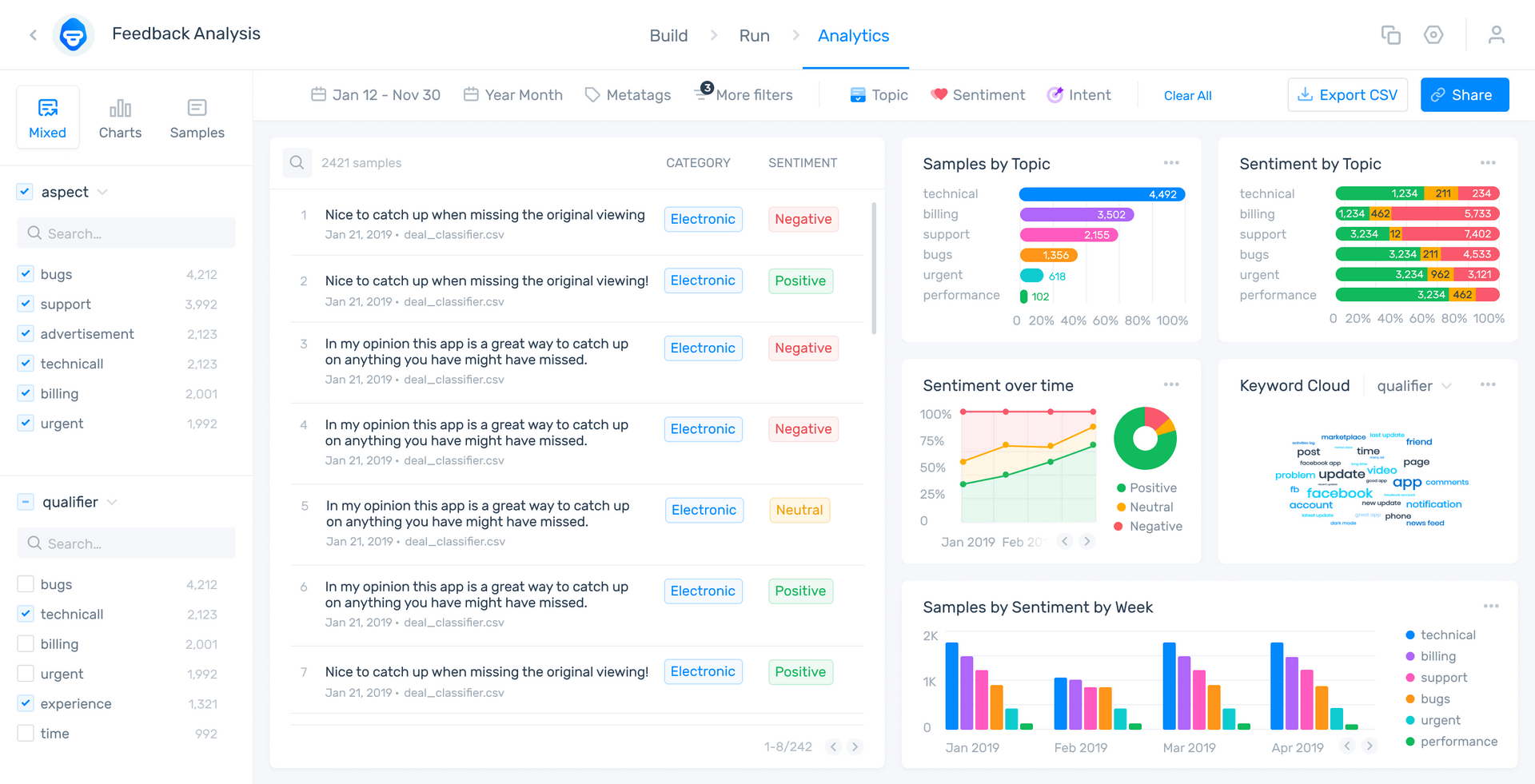
Aspect-based sentiment analysis first categorizes the customer opinions by “aspect” (topic or subject): Usability, Reliability, Pricing, etc. Each comment is then sentiment analyzed to show whether it’s Positive, Negative, or Neutral. This allows you to see which aspects of your business are particularly positive and which are negative.
Other techniques, like intent classification are especially useful for incoming emails or social media inquiries to automatically show why the customer is writing. Also, at the bottom right you can see word clouds that show the most used and most important words and phrases by sentiment.
MonkeyLearn pricing.
BigML
The goal of BigML is to connect all of your company’s data streams and internal processes to simplify collaboration and analysis results across the organization. They specialize in industries, like aerospace, automotive, energy, entertainment, financial services, food, healthcare, IoT, pharmaceutical, transportation, telecommunications, and more, so many of their tools are ready to go, right out of the box.
You can use pre-trained models or train your own with classification and regression and time series forecasting.
BigML pricing
IBM Watson
IBM Watson is a machine learning juggernaut, offering adaptability to most industries and the ability to build to huge scale across any cloud.
Watson Speech-to-Text is one of the industry standards for converting real-time spoken language to text, and Watson Language Translator is one of the best text translation tools on the market.
Watson Studio is great for data preparation and analysis and can be customized to almost any field, and their Natural Language Classifier makes building advanced SaaS analysis models easy.
See products page for pricing.
Google Cloud ML
Google Cloud ML is a SaaS analysis solution for image and text that connects easily to all of Google’s tools: Gmail, Google Sheets, Google Slides, Google Docs, and more.
Google AutoML Natural Language is one of the most advanced text analysis tools on the market, and AutoML Vision allows you to automate the training of custom image analysis models for some of the best accuracy, regardless of your needs.
Google Cloud AI and ML pricing
Top Open Source Libraries for Machine Learning
Open source machine learning libraries offer collections of pre-made models and components that developers can use to build their own applications, instead of having to code from scratch. They are free, flexible, and can be customized to meet specific needs.
Some of the most popular open-source libraries for machine learning include:
- Scikit-learn
- PyTorch
- Kaggle
- NLTK
- TensorFlow
Scikit-learn
Scikit-learn is a popular Python library and a great option for those who are just starting out with machine learning. Why? It’s easy to use, robust, and very well documented. You can use this library for tasks such as classification, clustering, and regression, among others.
PyTorch
Developed by Facebook, PyTorch is an open source machine learning library based on the Torch library with a focus on deep learning. It’s used for computer vision and natural language processing, and is much better at debugging than some of its competitors. If you want to start out with PyTorch, there are easy-to-follow tutorials for both beginners and advanced coders. Known for its flexibility and speed, it’s ideal if you need a quick solution.
Kaggle
Launched over a decade ago (and acquired by Google in 2017), Kaggle has a learning-by-doing philosophy, and it’s renowned for its competitions in which participants create models to solve real problems. Check out this online machine learning course in Python, which will have you building your first model in next to no time.
NLTK
The Natural Language Toolkit (NLTK) is possibly the best known Python library for working with natural language processing. It can be used for keyword search, tokenization and classification, voice recognition and more. With a heavy focus on research and education, you’ll find plenty of resources, including data sets, pre-trained models, and a textbook to help you get started.
TensorFlow
An open-source Python library developed by Google for internal use and then released under an open license, with tons of resources, tutorials, and tools to help you hone your machine learning skills. Suitable for both beginners and experts, this user-friendly platform has all you need to build and train machine learning models (including a library of pre-trained models). Tensorflow is more powerful than other libraries and focuses on deep learning, making it perfect for complex projects with large-scale data. However, it may take time and skills to master. Like with most open-source tools, it has a strong community and some tutorials to help you get started.
Final Note

Monkeylearn is an easy-to-use SaaS platform that allows you to create machine learning models to perform text analysis tasks like topic classification, sentiment analysis, keyword extraction, and more.
MonkeyLearn offers simple integrations with tools you already use, like Zendesk, Freshdesk, SurveyMonkey, Google Apps, Zapier, Rapidminer, and more, to streamline processes, save time, and increase internal (and external) communication.
Take a look at the MonkeyLearn Studio public dashboard to see how easy it is to use all of your text analysis tools from a single, striking dashboard. Play around and search data by date, category, and more.
Ready to take your first steps with MonkeyLearn’s low-code, no code solution?
Request a demo and start creating value from your data.