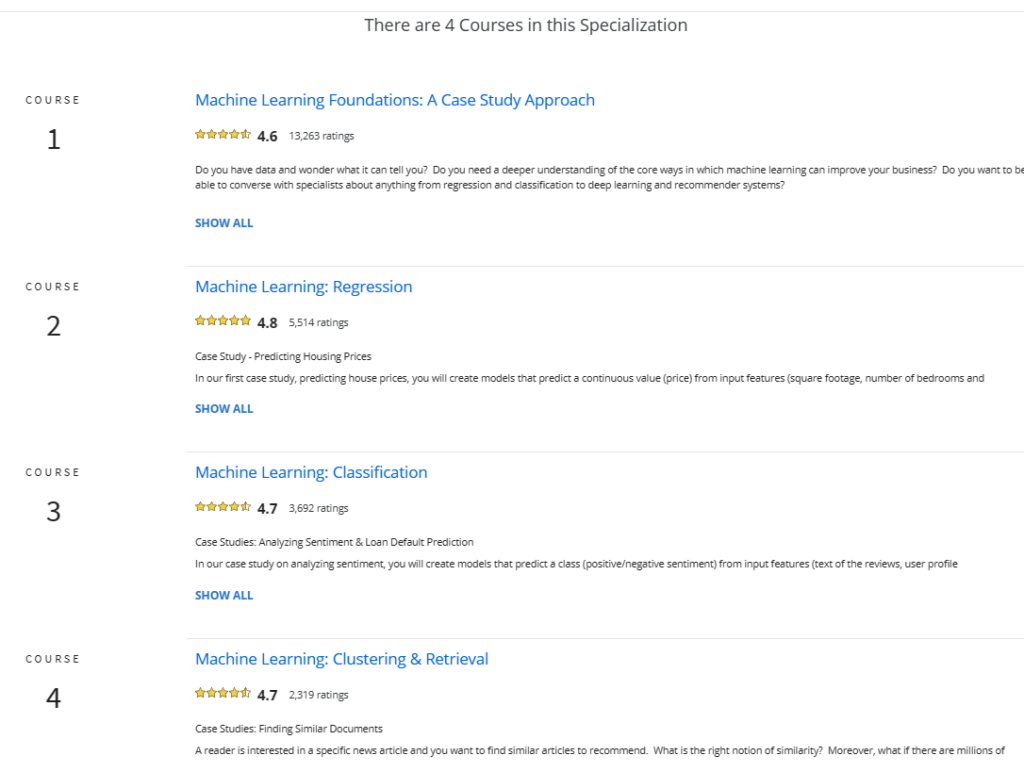
SKILLS YOU WILL GAIN
- Data Clustering Algorithms
- Machine Learning
- Classification Algorithms
- Decision Tree
- Python Programming
- Machine Learning Concepts
- Deep Learning
- Linear Regression
- Ridge Regression
- Lasso (Statistics)
- Regression Analysis
- Logistic Regression
About this Specialization
This Specialization from leading researchers at the University of Washington introduces you to the exciting, high-demand field of Machine Learning. Through a series of practical case studies, you will gain applied experience in major areas of Machine Learning including Prediction, Classification, Clustering, and Information Retrieval. You will learn to analyze large and complex datasets, create systems that adapt and improve over time, and build intelligent applications that can make predictions from data.
Applied Learning Project
Learners will implement and apply predictive, classification, clustering, and information retrieval machine learning algorithms to real datasets throughout each course in the specialization. They will walk away with applied machine learning and Python programming experience.
How the Specialization Works
Take Courses
A Coursera Specialization is a series of courses that helps you master a skill. To begin, enroll in the Specialization directly, or review its courses and choose the one you’d like to start with. When you subscribe to a course that is part of a Specialization, you’re automatically subscribed to the full Specialization. It’s okay to complete just one course — you can pause your learning or end your subscription at any time. Visit your learner dashboard to track your course enrollments and your progress.
Hands-on Project
Every Specialization includes a hands-on project. You’ll need to successfully finish the project(s) to complete the Specialization and earn your certificate. If the Specialization includes a separate course for the hands-on project, you’ll need to finish each of the other courses before you can start it.
Earn a Certificate
When you finish every course and complete the hands-on project, you’ll earn a Certificate that you can share with prospective employers and your professional network.